PreUnlearn: Auditing Collateral Knowledge Damage Before Large Language Model Unlearning
Pith reviewed 2026-06-27 00:18 UTC · model grok-4.3
The pith
Interaction features between forget sets and evaluation sets can predict collateral damage from LLM unlearning before any model updates occur.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
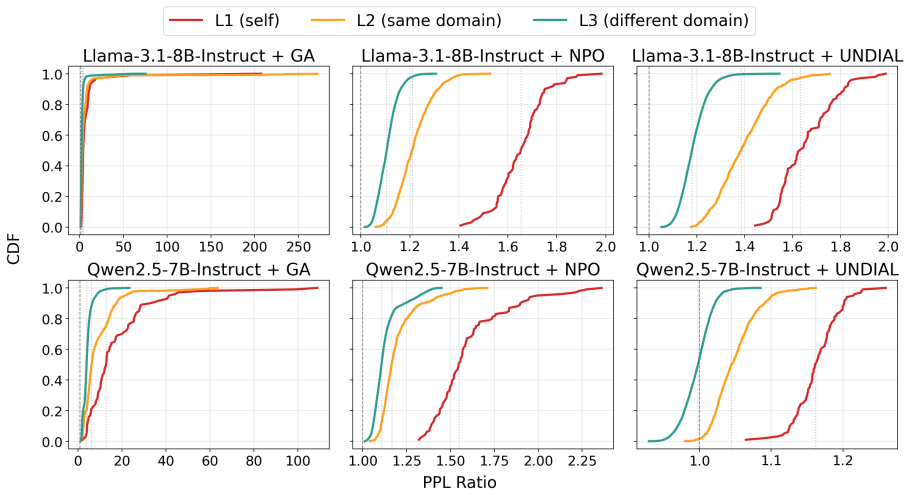
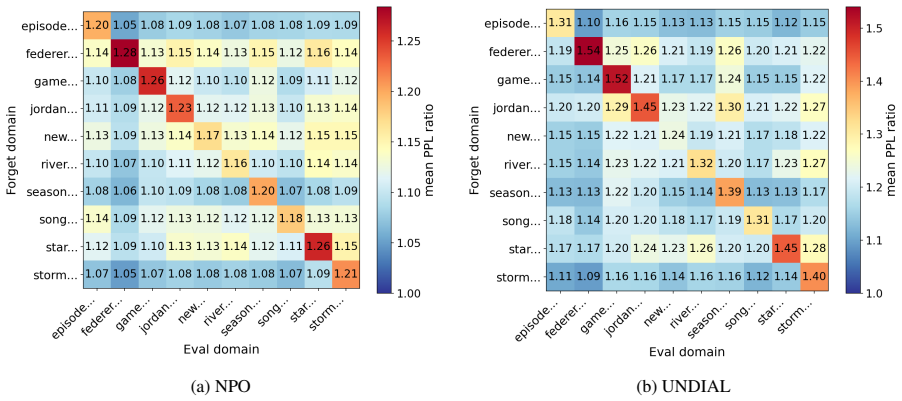
We find a consistent decay pattern: collateral damage is strongest near the forget set, weakens with semantic distance, but does not disappear at domain boundaries. Interaction features between the forget set and evaluation set provide the strongest signals, suggesting that collateral damage is partly reflected in data geometry before model updates occur.
What carries the argument
Forget-set auditing as a pre-unlearning prediction task that extracts interaction features between the forget set and evaluation sets to forecast downstream collateral damage.
If this is right
- Unlearning runs can be screened in advance by computing interaction features to identify those likely to cause high collateral damage.
- Semantic distance from the forget set can be used to anticipate how far damage will propagate.
- Evaluation sets can be chosen or adjusted based on their geometric interaction with the forget set to reduce unexpected effects.
- Unlearning procedures can incorporate pre-checks on data geometry to improve overall reliability.
Where Pith is reading between the lines
- The same interaction-based auditing might be tested on other model-editing operations such as targeted fine-tuning or knowledge editing.
- Incorporating these features directly into unlearning algorithms could be explored as a way to adjust the forget process dynamically.
- Similar pre-auditing could apply to safety interventions that modify model behavior without full retraining.
Load-bearing premise
Collateral damage patterns observed after unlearning can be reliably predicted in advance from static data features alone without performing any model update or training.
What would settle it
Running actual unlearning on a range of forget sets and finding that the strength of interaction features shows no correlation with the measured collateral damage on evaluation sets after the updates.
Figures



read the original abstract
Machine unlearning for large language models (LLMs) aims to remove specified knowledge while preserving the rest of the model's capabilities. However, the boundary between knowledge to forget and knowledge to retain is often unclear, since related and even distant information may be entangled in the model. In this paper, we study LLM unlearning from a data-centric perspective and measure how unlearning effects propagate from the forget set to same-domain and distant-domain knowledge. We find a consistent decay pattern: collateral damage is strongest near the forget set, weakens with semantic distance, but does not disappear at domain boundaries. We further ask whether such damage can be audited before unlearning is executed. We formulate forget-set auditing as a pre-unlearning prediction task and analyze which data features are most predictive of downstream damage. Our results show that interaction features between the forget set and evaluation set provide the strongest signals, suggesting that collateral damage is partly reflected in data geometry before model updates occur. These findings position forget-set auditing as an early warning tool for identifying risky unlearning runs and designing more reliable unlearning procedures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies collateral damage during LLM unlearning from a data-centric perspective. It reports a consistent decay pattern where damage is strongest near the forget set, weakens with semantic distance, and persists across domain boundaries. It then frames forget-set auditing as a pre-unlearning prediction task and claims that interaction features between the forget set and evaluation sets are the strongest predictors of downstream damage, implying that such damage is partly encoded in static data geometry before any model update occurs.
Significance. If the predictive relationship can be shown to hold prospectively on unseen forget/evaluation pairs without access to post-unlearning outcomes, the work would offer a practical early-warning tool for unlearning safety and could inform more robust unlearning design. The data-geometry angle is a useful complement to existing model-update analyses.
major comments (2)
- [Experimental setup / prediction task formulation] The central claim that interaction features enable pre-unlearning prediction of collateral damage is load-bearing for the contribution. The manuscript must demonstrate that feature selection, regression fitting, or importance ranking was performed without using the observed post-unlearning damage values as supervision; otherwise the reported predictive strength is retrospective rather than prospective. This directly affects whether the results support an 'early warning' capability (see abstract and the forget-set auditing formulation).
- [Results on predictive signals] The decay pattern and feature-predictiveness results require explicit held-out evaluation: the interaction features must be tested on forget/evaluation pairs that were never used to compute or select those features. Without such separation, the analysis risks circularity between the geometry used to define evaluation sets and the geometry used to predict damage on those sets.
minor comments (2)
- [Abstract] The abstract states the main findings but provides no information on datasets, unlearning methods, evaluation metrics, or statistical controls; these details are essential for assessing reproducibility even in a data-centric study.
- [Methods] Notation for 'interaction features' and 'semantic distance' should be defined precisely (e.g., via explicit formulas or embedding-based metrics) to allow independent replication.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on the prospective nature of the prediction task. We address both major comments below and will revise the manuscript to provide the requested demonstrations of held-out, pre-unlearning prediction.
read point-by-point responses
-
Referee: [Experimental setup / prediction task formulation] The central claim that interaction features enable pre-unlearning prediction of collateral damage is load-bearing for the contribution. The manuscript must demonstrate that feature selection, regression fitting, or importance ranking was performed without using the observed post-unlearning damage values as supervision; otherwise the reported predictive strength is retrospective rather than prospective. This directly affects whether the results support an 'early warning' capability (see abstract and the forget-set auditing formulation).
Authors: We agree that a fully prospective formulation requires training the predictive model without access to post-unlearning damage on the evaluation pairs used for testing. The interaction features themselves are computed exclusively from static data geometry before any unlearning occurs. In the revision we will add an explicit cross-validation protocol: a regression model will be fit on a training partition of forget/evaluation pairs (using their post-unlearning damage only for supervision within that partition) and evaluated on completely disjoint held-out pairs whose damage values are never seen during feature selection or model fitting. This change will be documented in a new subsection on prospective auditing. revision: yes
-
Referee: [Results on predictive signals] The decay pattern and feature-predictiveness results require explicit held-out evaluation: the interaction features must be tested on forget/evaluation pairs that were never used to compute or select those features. Without such separation, the analysis risks circularity between the geometry used to define evaluation sets and the geometry used to predict damage on those sets.
Authors: We acknowledge the risk of circularity when the same data geometry informs both set construction and prediction. The revised manuscript will partition all evaluation sets into disjoint training and test groups for the prediction experiments. Feature selection, importance ranking, and regression fitting will be performed only on the training partition; all reported predictive metrics (including R² and feature rankings) will be computed exclusively on the held-out test pairs. This separation will be added to the experimental setup and results sections. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and text describe an empirical analysis that computes static data features (including interaction features) from forget and evaluation sets, then reports their correlation strength with observed collateral damage after unlearning runs. No equations, sections, or methodological descriptions are supplied that reduce the reported 'strongest signals' or 'pre-unlearning prediction' to a fitted parameter or self-referential definition of the damage labels themselves. The central claim remains an observational finding about data geometry rather than a tautological renaming or post-hoc fit presented as prospective prediction. No self-citation load-bearing steps or uniqueness theorems are invoked in the given material. The derivation is therefore self-contained against external benchmarks of damage measurement.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2022 , eprint=
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. 2022 , eprint=
2022
-
[2]
2021 , eprint=
Measuring Massive Multitask Language Understanding , author=. 2021 , eprint=
2021
-
[3]
2024 , eprint=
A Curious Case of Searching for the Correlation between Training Data and Adversarial Robustness of Transformer Textual Models , author=. 2024 , eprint=
2024
-
[4]
2025 , eprint=
Probing Knowledge Holes in Unlearned LLMs , author=. 2025 , eprint=
2025
-
[5]
2025 , url=
Dorna, Vineeth and Mekala, Anmol and Zhao, Wenlong and McCallum, Andrew and Lipton, Zachary C and Kolter, J Zico and Maini, Pratyush , journal=. 2025 , url=
2025
-
[6]
2024 , eprint=
TOFU: A Task of Fictitious Unlearning for LLMs , author=. 2024 , eprint=
2024
-
[7]
Smith and Chiyuan Zhang , year=
Weijia Shi and Jaechan Lee and Yangsibo Huang and Sadhika Malladi and Jieyu Zhao and Ari Holtzman and Daogao Liu and Luke Zettlemoyer and Noah A. Smith and Chiyuan Zhang , year=. 2407.06460 , archivePrefix=
-
[8]
2024 , eprint=
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning , author=. 2024 , eprint=
2024
-
[9]
2024 , eprint=
RWKU: Benchmarking Real-World Knowledge Unlearning for Large Language Models , author=. 2024 , eprint=
2024
-
[10]
Jang, Joel and Yoon, Dongkeun and Yang, Sohee and Cha, Sungmin and Lee, Moontae and Logeswaran, Lajanugen and Seo, Minjoon. Knowledge Unlearning for Mitigating Privacy Risks in Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.805
-
[11]
2024 , eprint=
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning , author=. 2024 , eprint=
2024
-
[12]
2023 , eprint=
Locating and Editing Factual Associations in GPT , author=. 2023 , eprint=
2023
-
[13]
2022 , eprint=
Memory-Based Model Editing at Scale , author=. 2022 , eprint=
2022
-
[14]
2020 , eprint=
Understanding Black-box Predictions via Influence Functions , author=. 2020 , eprint=
2020
-
[15]
2023 , eprint=
Who's Harry Potter? Approximate Unlearning in LLMs , author=. 2023 , eprint=
2023
-
[16]
2023 , eprint=
Studying Large Language Model Generalization with Influence Functions , author=. 2023 , eprint=
2023
-
[17]
2022 , eprint=
Datamodels: Predicting Predictions from Training Data , author=. 2022 , eprint=
2022
-
[18]
2020 , eprint=
PyHessian: Neural Networks Through the Lens of the Hessian , author=. 2020 , eprint=
2020
-
[19]
2022 , eprint=
Unrolling SGD: Understanding Factors Influencing Machine Unlearning , author=. 2022 , eprint=
2022
-
[20]
2023 , eprint=
Towards Unbounded Machine Unlearning , author=. 2023 , eprint=
2023
-
[21]
2016 , eprint=
Pointer Sentinel Mixture Models , author=. 2016 , eprint=
2016
-
[22]
doi:10.18653/V1/2021.FINDINGS-ACL.188 , url =
Wang, Wenhui and Bao, Hangbo and Huang, Shaohan and Dong, Li and Wei, Furu. M ini LM v2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.188
-
[23]
Campello, Ricardo J. G. B. and Moulavi, Davoud and Zimek, Arthur and Sander, J\". Hierarchical Density Estimates for Data Clustering, Visualization, and Outlier Detection , year =. ACM Trans. Knowl. Discov. Data , month = jul, articleno =. doi:10.1145/2733381 , abstract =
-
[24]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[25]
2024 , eprint=
Gemma: Open Models Based on Gemini Research and Technology , author=. 2024 , eprint=
2024
-
[26]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[27]
UNDIAL : Self-Distillation with Adjusted Logits for Robust Unlearning in Large Language Models
Dong, Yijiang River and Lin, Hongzhou and Belkin, Mikhail and Huerta, Ramon and Vuli \'c , Ivan. UNDIAL : Self-Distillation with Adjusted Logits for Robust Unlearning in Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: L...
-
[28]
2025 , eprint=
A Comprehensive Survey of Machine Unlearning Techniques for Large Language Models , author=. 2025 , eprint=
2025
-
[29]
A Survey of Machine Unlearning
Nguyen, Thanh Tam and Huynh, Thanh Trung and Ren, Zhao and Nguyen, Phi Le and Liew, Alan Wee-Chung and Yin, Hongzhi and Nguyen, Quoc Viet Hung , title =. ACM Trans. Intell. Syst. Technol. , month = sep, articleno =. 2025 , issue_date =. doi:10.1145/3749987 , abstract =
-
[30]
2025 , eprint=
Benchmarking Vision Language Model Unlearning via Fictitious Facial Identity Dataset , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.