Hierarchical Multi-Modal Retrieval for Knowledge-Grounded News Image Captioning
Pith reviewed 2026-06-26 21:32 UTC · model grok-4.3
The pith
A hierarchical multi-modal retrieval system supplies external article knowledge so vision and language models can add event context and significance to news image captions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
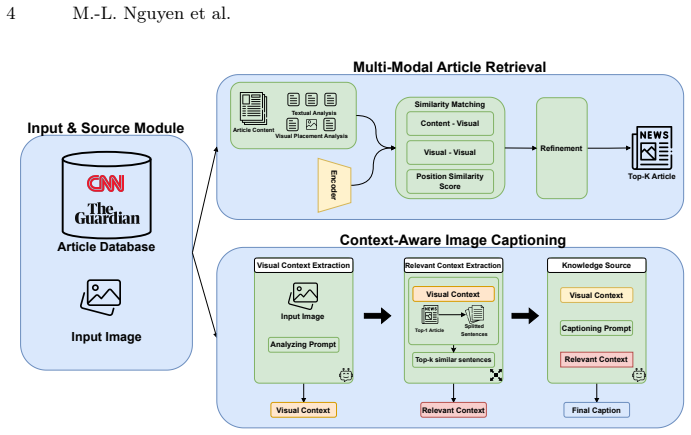
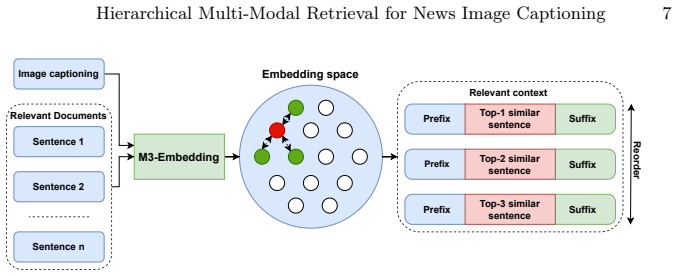
A hierarchical multi-modal article retrieval mechanism that moves beyond monolithic text entities, incorporating structure-aware features including weighted textual components and visual placement patterns along with multi-faceted similarity computations, followed by contextual relevance refinement, supplies the knowledge base that lets a VLM generate an initial image description, segments relevant article information, and enables an LLM to produce comprehensive captions with deeper insights such as object attributes, event context, and underlying significance.
What carries the argument
The hierarchical multi-modal article retrieval mechanism that evaluates article structure-aware features (weighted headlines, body sections, visual placement) and multi-faceted similarities (content-visual, visual-visual, discourse positioning) before refinement.
If this is right
- Captions gain details on object attributes, event context, and significance not observable from the image alone.
- The VLM description step allows targeted segmentation of relevant knowledge from long articles.
- LLM integration of retrieved knowledge produces more contextually detailed outputs than vision-only methods.
- The pipeline achieves competitive ranking in a real-world news image captioning challenge.
Where Pith is reading between the lines
- If retrieval quality is high the method could generalize to other visual grounding tasks that require external facts.
- Error propagation from inaccurate articles remains a risk that would require separate verification layers.
- The structure-aware retrieval could be tested on non-news domains such as scientific figures or historical photos.
Load-bearing premise
Retrieved articles contain accurate, non-contradictory knowledge that the LLM integrates without introducing factual errors or hallucinations.
What would settle it
Generate captions using deliberately contradictory or false retrieved articles and measure the rate of factual errors in the output compared to runs with verified articles.
Figures

read the original abstract
Traditional image captioning methods often struggle to generate comprehensive, context-rich descriptions, especially for details not directly observable from visual cues. To overcome this, we propose a novel retrieval-augmented image captioning framework that generates captions with deeper insights, such as object attributes, event context, and underlying significance, by leveraging external knowledge. Our approach features a hierarchical multi-modal article retrieval mechanism that moves beyond monolithic text entities. This retrieval considers article structure-aware features, including weighted textual components (e.g., headlines, body sections) and visual placement patterns, alongside multi-faceted similarity computations (content--visual, visual--visual, and discourse positioning). A subsequent contextual relevance refinement stage further enhances the retrieved information. The retrieved articles then serve as the knowledge base for caption generation: first, a VLM generates a concise image description; second, we segment relevant information from the retrieved articles based on this description; and finally, an LLM utilizes both the description and extracted knowledge to generate a comprehensive, contextually detailed caption. We participated in the ACM Multimedia EVENTA 2025 Challenge and achieved 5th place with an overall score of 0.2824 on the private test set of the OpenEvent-V1 dataset. Source code is publicly released at https://github.com/mf0212/EVENTA-Challange.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical multi-modal retrieval-augmented framework for knowledge-grounded news image captioning. It retrieves articles using structure-aware features (weighted textual components such as headlines and body sections, visual placement patterns) and multi-faceted similarity computations (content-visual, visual-visual, discourse positioning), applies contextual relevance refinement, then uses a VLM to generate an image description, segments relevant spans from the retrieved articles, and feeds both to an LLM for detailed caption generation. The system placed 5th in the ACM Multimedia EVENTA 2025 Challenge with a score of 0.2824 on the private test set of OpenEvent-V1, and the source code is publicly released.
Significance. If the retrieval components demonstrably improve caption quality, the work could advance retrieval-augmented captioning by incorporating external knowledge for attributes, event context, and significance. The public code release is a clear strength supporting reproducibility. However, the significance is constrained by the lack of internal validation showing that the proposed mechanisms contribute beyond the external leaderboard result.
major comments (2)
- [Abstract] Abstract: the central claim that the framework generates captions with 'deeper insights' rests solely on the reported challenge ranking of 0.2824; no ablation studies, baseline comparisons, or quantitative metrics are provided to show that the hierarchical retrieval, multi-faceted similarities, or contextual refinement improve caption quality over simpler retrieval or non-retrieval baselines.
- [Abstract] Abstract (caption generation pipeline): the approach segments relevant information from retrieved articles based on the VLM description and passes it to the LLM without any described verification, contradiction detection, confidence filtering, or source attribution; this assumption is load-bearing for the claim of reliable 'deeper insights' given that news articles can contain errors or conflicting accounts.
minor comments (2)
- [Abstract] The weighting scheme for textual components (headlines, body sections) and the exact formulation of the multi-faceted similarity computations are not specified, hindering reproducibility even with the released code.
- Consider adding a diagram of the full pipeline (retrieval o refinement o VLM description o segmentation o LLM) to improve clarity of the multi-stage process.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below, agreeing that additional evidence and discussion are warranted to support the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the framework generates captions with 'deeper insights' rests solely on the reported challenge ranking of 0.2824; no ablation studies, baseline comparisons, or quantitative metrics are provided to show that the hierarchical retrieval, multi-faceted similarities, or contextual refinement improve caption quality over simpler retrieval or non-retrieval baselines.
Authors: We agree that the abstract relies primarily on the challenge leaderboard result (5th place, 0.2824 on private test) as evidence for improved caption quality. The manuscript was prepared for the EVENTA 2025 Challenge, where external ranking on OpenEvent-V1 serves as the main benchmark. To strengthen the submission, the revised manuscript will include ablation studies on the challenge validation split, comparing the full hierarchical multi-modal retrieval against simpler text-only retrieval and non-retrieval baselines, reporting metrics such as CIDEr and human preference scores where feasible. revision: yes
-
Referee: [Abstract] Abstract (caption generation pipeline): the approach segments relevant information from retrieved articles based on the VLM description and passes it to the LLM without any described verification, contradiction detection, confidence filtering, or source attribution; this assumption is load-bearing for the claim of reliable 'deeper insights' given that news articles can contain errors or conflicting accounts.
Authors: The referee correctly notes the absence of verification mechanisms in the segmentation and LLM input stage. This is a genuine limitation of the current pipeline, as news sources can include inaccuracies. In revision we will insert a dedicated Limitations subsection that acknowledges the risk of propagating unverified content, discusses the assumption's impact on the 'deeper insights' claim, and outlines future work on cross-source consistency checks and attribution. Claims in the abstract and conclusion will be tempered accordingly. revision: yes
Circularity Check
Applied system description with external leaderboard evaluation exhibits no circularity
full rationale
The manuscript presents an engineering pipeline (hierarchical retrieval, VLM description, article segmentation, LLM captioning) whose performance is measured on the external OpenEvent-V1 private test set via the EVENTA 2025 Challenge leaderboard. No equations, parameter fits, or self-referential predictions appear in the provided text; the central claim is a composite system whose outputs are not forced by construction from its own inputs. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL): Human Language Technologies, Volume 1 (Long and Short Papers). pp. 4171–4186 (Jun 2019)
2019
-
[2]
In:Raedt,L.D.(ed.)ProceedingsoftheThirty-FirstInternationalJointConference on Artificial Intelligence, IJCAI-22
Du, Y., Liu, Z., Li, J., Zhao, W.X.: A survey of vision-language pre-trained models. In:Raedt,L.D.(ed.)ProceedingsoftheThirty-FirstInternationalJointConference on Artificial Intelligence, IJCAI-22. pp. 5436–5443 (7 2022), survey Track
2022
-
[3]
In: Proceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing (EMNLP)
Hessel, J., Holtzman, A., Forbes, M., Choi, Y.: Clipscore: A reference-free evalua- tion metric for image captioning. In: Proceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing (EMNLP). pp. 7514–7528 (2021)
2021
-
[4]
In: Proceedings of the 31st ACM International Conference on Multimedia (MM ’23)
Ji, W., Wei, Y., Zheng, Z., Fei, H., Chua, T.S.: Deep multimodal learning for information retrieval. In: Proceedings of the 31st ACM International Conference on Multimedia (MM ’23). pp. 9739–9741 (2023) Hierarchical Multi-Modal Retrieval for News Image Captioning 13
2023
-
[5]
In: Advances in Neural Information Processing Systems (NeurIPS) (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., Kiela, D.: Retrieval-augmented generation for knowledge-intensive NLP tasks. In: Advances in Neural Information Processing Systems (NeurIPS) (2020)
2020
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, J., Vo, D.M., Sugimoto, A., Nakayama, H.: Evcap: Retrieval-augmented im- age captioning with external visual-name memory for open-world comprehension. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 20086–20096 (Jun 2024)
2024
-
[7]
Li, W., Li, J., Ramos, R., Tang, R., Elliott, D.: Understanding retrieval robustness for retrieval-augmented image captioning (2024), preprint at https://arxiv.org/ abs/2406.02265
arXiv 2024
-
[8]
In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T
Lin, T., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: Common objects in context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) Computer Vision – ECCV 2014. Lecture Notes in Computer Science, vol. 8693, pp. 740–755 (2014)
2014
-
[9]
Muennighoff, N., Autry, L., Wang, Q., Neyshabur, B., Rajani, N., Ren, X.: M3- embedding: A purely text-based embedding model for multilingual, multi-task re- trieval (2024)
2024
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
Ngo, B.H., Nguyen, D.T., Do-Tran, N., Pham Huy, T.P., An, M., Nguyen, T., Nguyen, H.L., Dinh, V., Dinh, V.: Comprehensive visual features and pseudo la- beling for robust natural language-based vehicle retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. pp. 5409–5418 (2023)
2023
-
[11]
In: Proceedings of the ACM International Conference on Multimedia (ACM MM) (2025)
Nguyen, H., Nguyen, P., Tran, T., Nguyen, M., Nguyen, T.V., Tran, M., Le, T.: Openevents v1: Large-scale benchmark dataset for multimodal event grounding. In: Proceedings of the ACM International Conference on Multimedia (ACM MM) (2025)
2025
-
[12]
In: Working Notes Proceedings of the MediaEval 2023 Workshop
Nguyen, T., Nguyen-Huu, H., Le, T., Tran, H., Le-Tran, Q., Ngo, H., An, M., Dinh, Q.: Multimodal fusion in newsimages 2023: Evaluating translators, keyphrase ex- traction, and CLIP pre-training. In: Working Notes Proceedings of the MediaEval 2023 Workshop. CEUR Workshop Proceedings, vol. 3658 (2024)
2023
-
[13]
In: International Conference on Machine Learning (ICML)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning (ICML). pp. 8748–8763. PMLR (2021)
2021
-
[14]
In: Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL)
Ramos, R., Elliott, D., Martins, B.: Retrieval-augmented image captioning. In: Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL). pp. 3666–3681 (May 2023)
2023
-
[15]
In: CBMI
Sarto, S., Cornia, M., Baraldi, L., Cucchiara, R.: Retrieval-augmented transformer for image captioning. In: CBMI. pp. 1–7 (2022)
2022
-
[16]
In: Proceedings of the ACM International Conference on Multimedia (ACM MM) (2025)
Tran, T., Nguyen, M., Tran, M., Nguyen, T.V., Do, T., Ly, D., Huynh, V., Le, K., Tran, M., Le, T.: Event-enriched image analysis grand challenge at ACM multi- media 2025. In: Proceedings of the ACM International Conference on Multimedia (ACM MM) (2025)
2025
-
[17]
Wu, H., Zhong, Z., Sun, X.: Dir: Retrieval-augmented image captioning with com- prehensive understanding (2024), preprint at https://arxiv.org/abs/2412.01115
arXiv 2024
-
[18]
In: Proceedings of the 31st ACM International Conference on Multimedia (MM ’23) (2023)
Yang, S., Zhou, Y., Wang, Y., Wu, Y., Zhu, L., Zheng, Z.: Towards unified text- based person retrieval: A large-scale multi-attribute and language search bench- mark. In: Proceedings of the 31st ACM International Conference on Multimedia (MM ’23) (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.