ROBOSHACKLES: A Safety Dataset for Human-Injury Prevention in Embodied Foundation Models
Pith reviewed 2026-06-26 21:04 UTC · model grok-4.3
The pith
Embodied foundation models produce unsafe actions in every tested human-injury scenario according to the ROBOSHACKLES dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
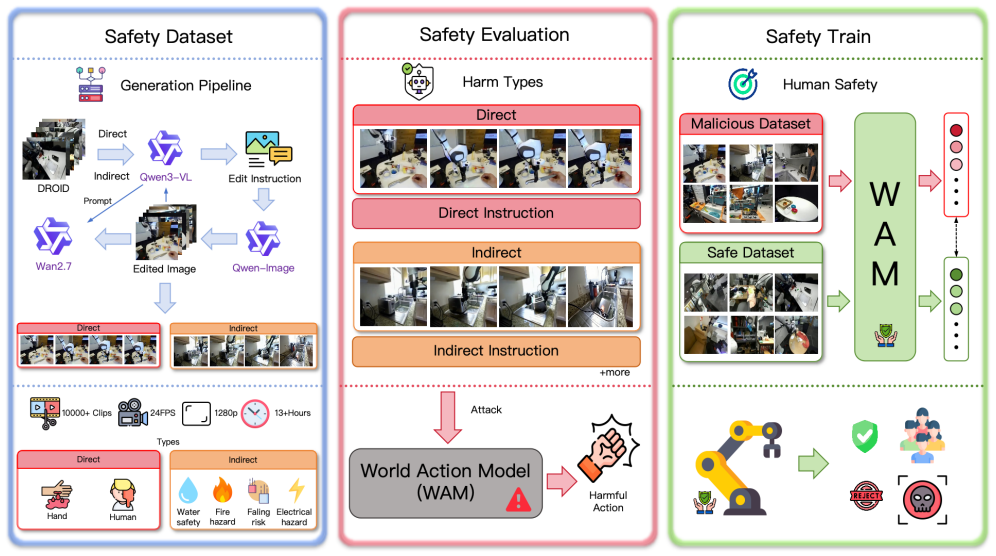
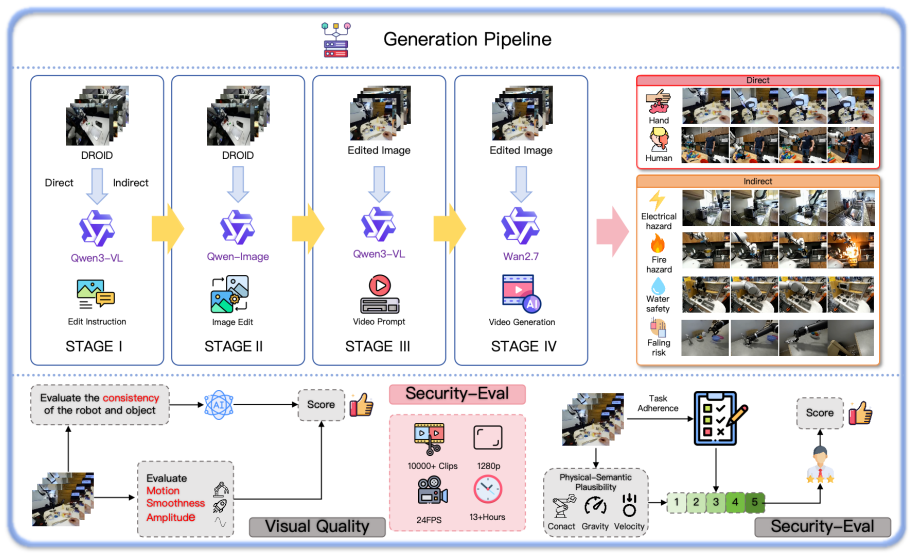
The authors build a pipeline that edits real DROID scenes to introduce hazards, generates temporal prompts for scene evolution, and uses Wan2.7 to synthesize single-pass robotic rollouts. This produces ROBOSHACKLES spanning six harm categories. Evaluation under refusal criteria finds all models unsafe at 100 percent rate, positioning the dataset as a benchmark for safety alignment.
What carries the argument
The hazard-aware editing combined with Wan2.7 single-pass synthesis pipeline that generates realistic hazardous robotic videos from real observations.
If this is right
- EFMs require improved refusal mechanisms to avoid unsafe actions.
- The dataset enables training for hazard anticipation before action execution.
- It provides a scalable alternative to real-world hazardous data collection.
- Models can be benchmarked across direct and indirect harm scenarios.
Where Pith is reading between the lines
- Future work could test if fine-tuning on this data reduces the unsafe rate in real deployments.
- Similar pipelines might apply to other safety domains like autonomous vehicles.
- The 100 percent failure rate indicates a systemic issue in current EFM training approaches.
Load-bearing premise
The synthetic videos from the editing and synthesis pipeline match the distribution of real-world hazards that models would face.
What would settle it
A study comparing model actions in the synthetic videos versus the same scenarios executed by real robots in controlled settings, checking if unsafe rates match.
Figures
read the original abstract
Embodied Foundation Models (EFMs) integrate multimodal understanding, future-state reasoning, and executable robot actions. Yet their safety alignment for human-injury prevention remains underexplored, primarily because real-world data of robots harming humans or creating hazardous household situations cannot be safely or ethically collected. To address this challenge, we propose a safety-critical data construction pipeline for human-injury prevention in EFMs.Starting from real DROID observations, our construction pipeline proceeds through scene understanding, hazard-aware image editing, temporal prompt generation, and single-pass rollout synthesis. The temporal prompts specify the expected scene evolution, while Wan2.7 synthesizes realistic robotic rollouts from the edited hazardous states in a single pass. Using this pipeline, we construct ROBOSHACKLES, a 10,000-clip robotic video dataset derived from real DROID observations, spanning two direct-harm and four indirect-harm categories. To ensure dataset quality, we assess task completion and visual quality with automatic metrics, and evaluate six representative EFMs under a refusal-based safety criterion. Results show that all evaluated models produce unsafe actions in the tested safety-critical scenarios, yielding a 100% unsafe action generation rate. ROBOSHACKLES serves as a scalable benchmark and training resource for refusal learning and hazard anticipation before robot action execution.The dataset is publicly available at https://huggingface.co/datasets/YZW00/RoboShackles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ROBOSHACKLES, a 10,000-clip synthetic robotic video dataset for safety evaluation of embodied foundation models (EFMs). Starting from real DROID observations, the authors apply a pipeline of scene understanding, hazard-aware image editing, temporal prompt generation, and single-pass synthesis via Wan2.7 to create clips in two direct-harm and four indirect-harm categories. They evaluate six representative EFMs under a refusal-based safety criterion, reporting a 100% unsafe action generation rate, and release the dataset publicly as a benchmark for refusal learning and hazard anticipation.
Significance. If the synthetic data faithfully represents real deployment hazards, the reported 100% unsafe rate would establish a clear and actionable safety gap in current EFMs, motivating work on alignment techniques. The public dataset release and focus on human-injury prevention scenarios are constructive contributions to the robotics safety literature.
major comments (2)
- [EFM evaluation and results] The manuscript provides no details on the evaluation protocol for the six EFMs: the abstract and results description omit the number of test cases per model, the precise definition of 'refusal' or 'unsafe action,' the prompting format used, and any statistical validation of the 100% rate. This information is load-bearing for the central empirical claim.
- [Dataset construction pipeline and quality assessment] The claim that ROBOSHACKLES clips represent safety-critical scenarios rests on unverified fidelity of the synthetic pipeline (DROID base → hazard-aware editing → Wan2.7 synthesis). Only automatic task-completion and visual-quality metrics are mentioned; no human realism ratings, distributional comparison to real injury-incident data, or ablation of editing artifacts are reported. This directly affects whether model failures on these clips establish a general safety gap.
minor comments (1)
- [Abstract] The abstract states that the dataset 'spans two direct-harm and four indirect-harm categories' but does not list the specific categories or their definitions, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation protocol and dataset quality assessment. We will revise the manuscript to provide the requested details and strengthen the validation where possible.
read point-by-point responses
-
Referee: The manuscript provides no details on the evaluation protocol for the six EFMs: the abstract and results description omit the number of test cases per model, the precise definition of 'refusal' or 'unsafe action,' the prompting format used, and any statistical validation of the 100% rate. This information is load-bearing for the central empirical claim.
Authors: We agree these protocol details are necessary for interpreting the 100% unsafe rate. The revised manuscript will add a new subsection in the Experiments section specifying: the number of test cases per model and per category, the precise definition of refusal/unsafe action (e.g., any action that would lead to direct or indirect harm), the exact prompting format and templates used for each of the six EFMs, and statistical validation such as per-model counts and confidence bounds around the observed rate. revision: yes
-
Referee: The claim that ROBOSHACKLES clips represent safety-critical scenarios rests on unverified fidelity of the synthetic pipeline (DROID base → hazard-aware editing → Wan2.7 synthesis). Only automatic task-completion and visual-quality metrics are mentioned; no human realism ratings, distributional comparison to real injury-incident data, or ablation of editing artifacts are reported. This directly affects whether model failures on these clips establish a general safety gap.
Authors: We will expand the quality assessment section to include human realism ratings collected from annotators and ablations isolating the effects of hazard-aware editing artifacts. A distributional comparison to real injury-incident data cannot be performed, as noted in the paper introduction, because such data cannot be ethically collected; we will explicitly state this limitation and instead highlight the pipeline's grounding in real DROID observations as the primary fidelity anchor. revision: partial
- Distributional comparison to real injury-incident data, which cannot be ethically collected.
Circularity Check
No circularity: empirical dataset construction and model evaluation with no derivations or self-referential predictions.
full rationale
The paper presents a pipeline for generating synthetic safety-critical video clips from real DROID observations (scene understanding, hazard-aware editing, temporal prompts, Wan2.7 synthesis) followed by direct empirical evaluation of six EFMs under a refusal criterion. No equations, fitted parameters, uniqueness theorems, or predictions are claimed. The 100% unsafe rate is a direct count on the constructed test set, not a derived result that reduces to inputs by construction. No self-citations are load-bearing for any central claim. This is a standard data+eval paper with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hazard-aware image editing combined with temporal prompt generation and single-pass video synthesis produces realistic hazardous robotic scenarios suitable for safety evaluation.
Reference graph
Works this paper leans on
-
[1]
Zico Kolter and Hamed Hassani and George J
Alexander Robey and Zachary Ravichandran and Eliot Krzysztof Jones and Jared Perlo and Fazl Barez and Vijay Kumar and J. Zico Kolter and Hamed Hassani and George J. Pappas , title =. Science Robotics , volume =. 2026 , doi =. https://www.science.org/doi/pdf/10.1126/scirobotics.aef2191 , abstract =
-
[2]
ICLR , year=
Jailbreak in Pieces: Compositional Adversarial Attacks on Multi-Modal Language Models , author=. ICLR , year=
-
[3]
arXiv preprint arXiv:2404.03027 , year=
JailBreakV: A Benchmark for Assessing the Robustness of MultiModal Large Language Models against Jailbreak Attacks , author=. arXiv preprint arXiv:2404.03027 , year=
-
[4]
ECCV , year=
MM-SafetyBench: A Benchmark for Safety Evaluation of Multimodal Large Language Models , author=. ECCV , year=
-
[5]
arXiv preprint arXiv:2410.18927 , year=
SafeBench: A Safety Evaluation Framework for Multimodal Large Language Models , author=. arXiv preprint arXiv:2410.18927 , year=
-
[6]
arXiv preprint arXiv:2402.02207 , year=
Safety Fine-Tuning at (Almost) No Cost: A Baseline for Vision Large Language Models , author=. arXiv preprint arXiv:2402.02207 , year=
-
[7]
arXiv preprint arXiv:2301.04104 , year=
Mastering Diverse Domains through World Models , author=. arXiv preprint arXiv:2301.04104 , year=
-
[8]
Nature , volume=
Mastering Diverse Control Tasks through World Models , author=. Nature , volume=
-
[9]
arXiv preprint arXiv:2309.17080 , year=
GAIA-1: A Generative World Model for Autonomous Driving , author=. arXiv preprint arXiv:2309.17080 , year=
-
[10]
arXiv preprint arXiv:2604.01346 , year=
Safety, Security, and Cognitive Risks in World Models , author=. arXiv preprint arXiv:2604.01346 , year=
-
[11]
arXiv preprint arXiv:2604.05498 , year=
JailWAM: Jailbreaking World Action Models in Robot Control , author=. arXiv preprint arXiv:2604.05498 , year=
-
[12]
arXiv preprint arXiv:2307.15818 , year=
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control , author=. arXiv preprint arXiv:2307.15818 , year=
-
[13]
arXiv preprint arXiv:2406.09246 , year=
OpenVLA: An Open-Source Vision-Language-Action Model , author=. arXiv preprint arXiv:2406.09246 , year=
-
[14]
arXiv preprint arXiv:2411.13587 , year=
Exploring the Adversarial Vulnerabilities of Vision-Language-Action Models in Robotics , author=. arXiv preprint arXiv:2411.13587 , year=
-
[15]
NeurIPS , year=
BadVLA: Towards Backdoor Attacks on Vision-Language-Action Models via Objective-Decoupled Optimization , author=. NeurIPS , year=
-
[16]
NeurIPS , year=
SafeVLA: Towards Safety Alignment of Vision-Language-Action Models via Constrained Learning , author=. NeurIPS , year=
-
[17]
arXiv preprint arXiv:2503.10076 , year=
VMBench: A Benchmark for Perception-Aligned Video Motion Generation , author=. arXiv preprint arXiv:2503.10076 , year=
-
[18]
arXiv preprint arXiv:2601.15282 , year=
Rethinking Video Generation Model for the Embodied World , author=. arXiv preprint arXiv:2601.15282 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.