ReMP: Low-Downtime Runtime Model-Parallelism Reconfiguration for LLM Serving
Pith reviewed 2026-06-26 19:30 UTC · model grok-4.3
The pith
ReMP enables LLM serving systems to switch tensor and pipeline parallelism topologies at runtime in 1-7 seconds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReMP supports dynamic adjustment of model parallelism topology through decoupling the topology from runtime state, a two-dimensional KV cache migration mechanism to preserve reusable cache states after TP/PP changes, and end-to-end online reconfiguration, completing most topology switches within 1-7 seconds on models ranging from 7B to 70B parameters.
What carries the argument
two-dimensional KV cache migration mechanism that preserves reusable cache states after TP/PP changes
If this is right
- Topology switches complete in 1-7 seconds instead of minutes of service interruption.
- Speedups of tens to over a hundred times compared with the restart approach.
- Better TTFT, TPOT, and output throughput than any static configuration when workloads change over time.
Where Pith is reading between the lines
- Serving clusters could adjust parallelism on the fly to match shifting request sizes without user-visible pauses.
- The same migration logic might extend to other stateful components such as optimizer states in training.
- Cloud operators could use runtime reconfiguration to pack more models onto hardware during low-load periods.
Load-bearing premise
The two-dimensional KV cache migration successfully preserves reusable cache states after arbitrary TP/PP changes without introducing correctness errors or prohibitive migration overhead.
What would settle it
A measured topology switch on a 70B model that either corrupts KV cache contents (producing wrong outputs) or requires more than 10 seconds of downtime.
Figures
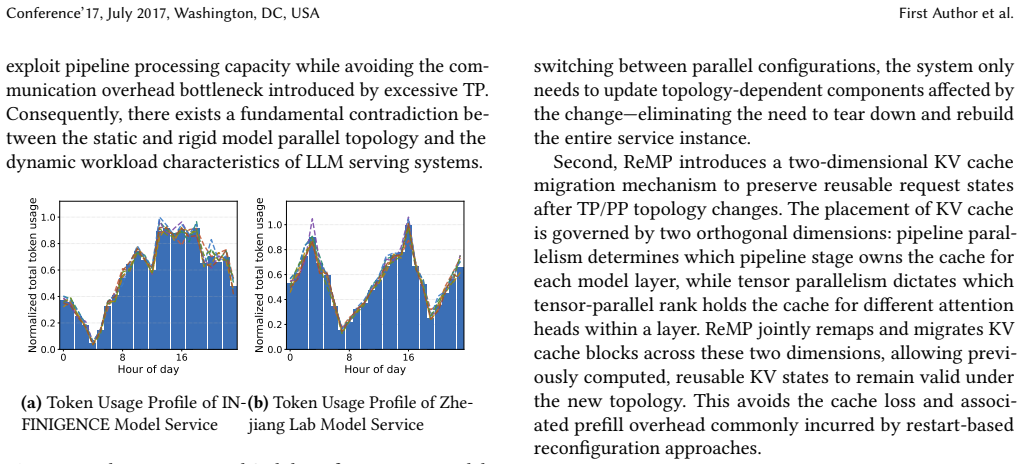
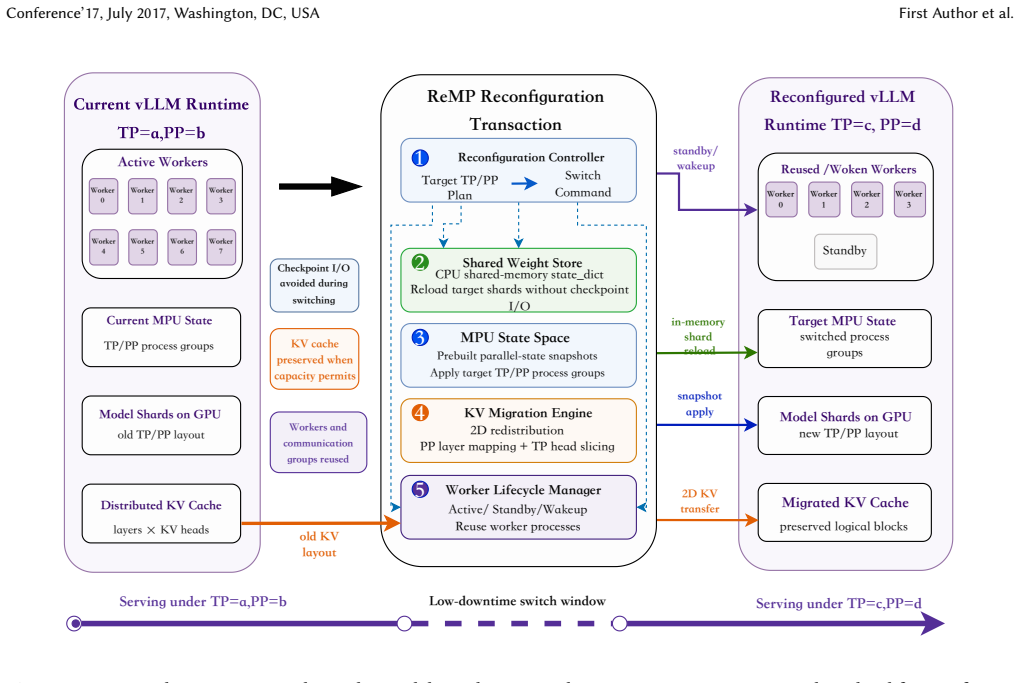
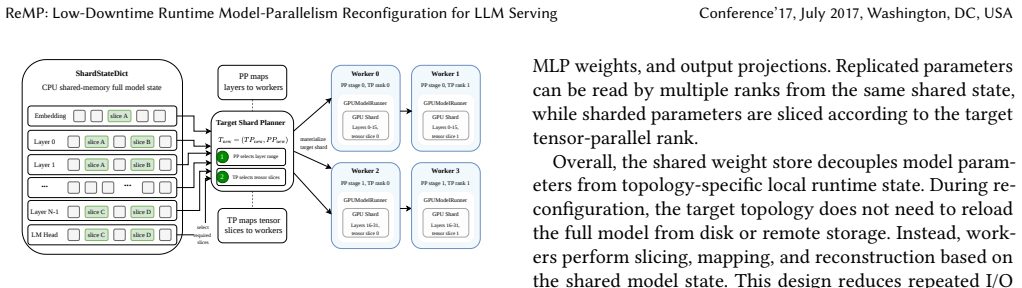
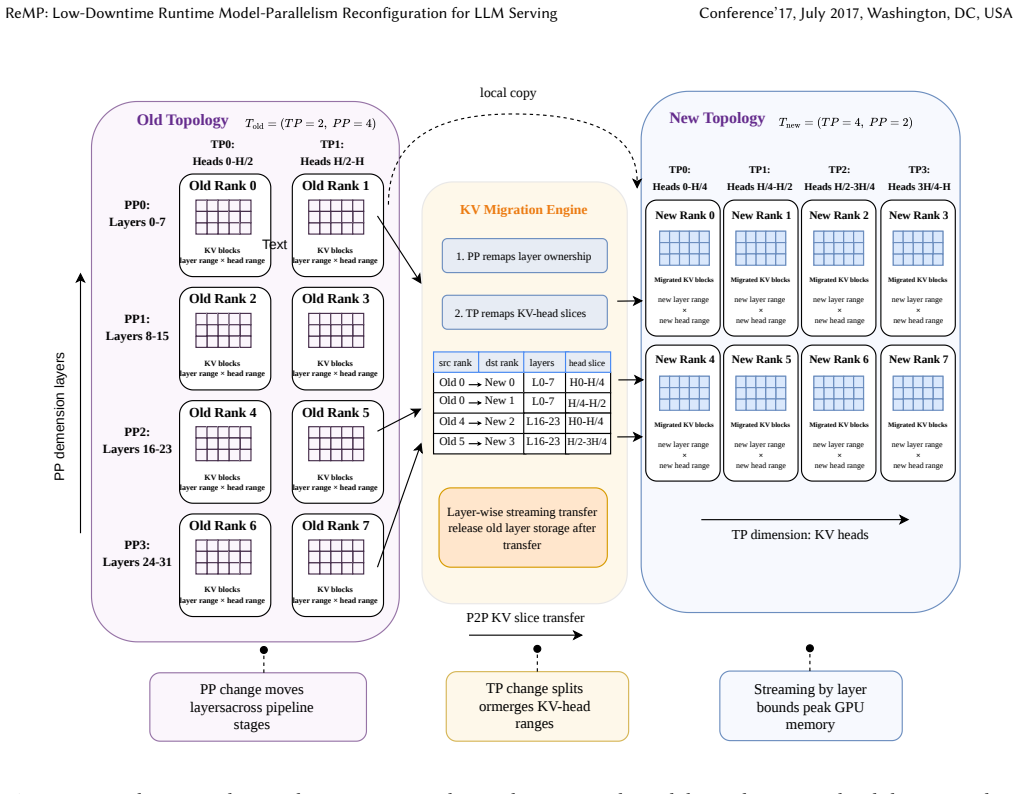
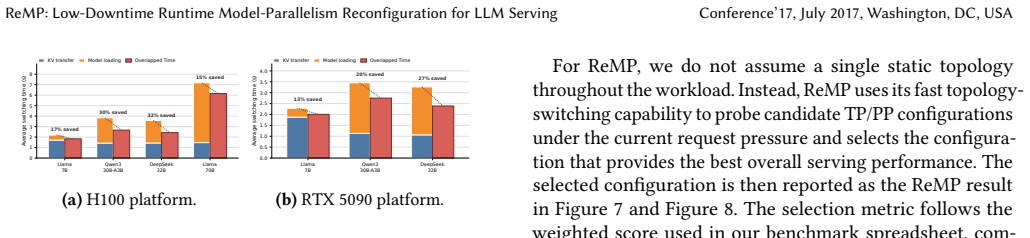
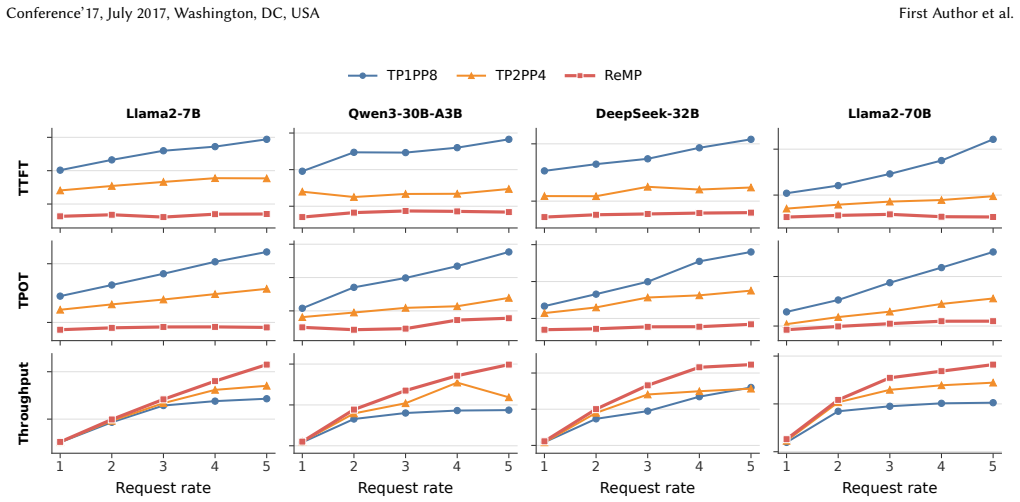
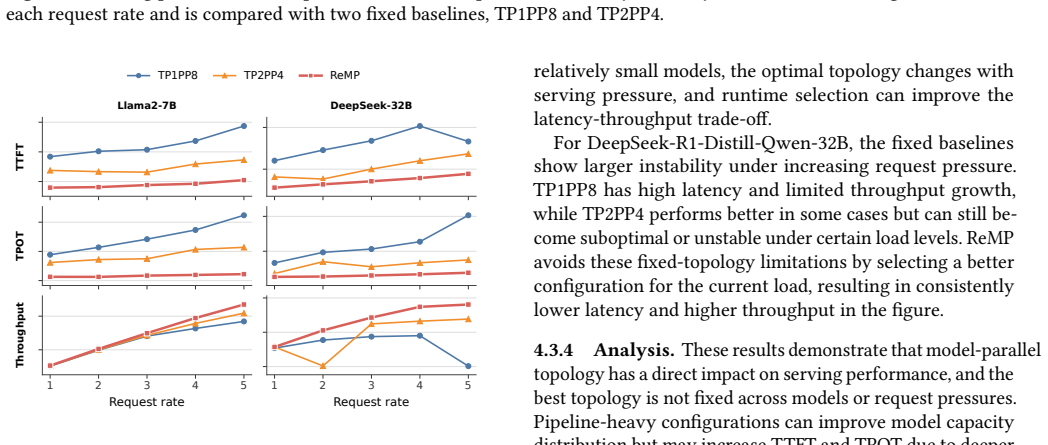
read the original abstract
Current large language model (LLM) inference systems universally deploy ultra-large-scale models using a combination of Tensor Parallelism (TP) and Pipeline Parallelism (PP). However, existing systems treat the model parallelism topology as a static configuration that cannot be flexibly adjusted at runtime. This rigid design creates a fundamental contradiction with the dynamically changing inference workloads in real-world scenarios. State-of-the-art systems lack online reconfiguration capabilities and can only switch configurations by restarting the service, resulting in several minutes of service interruption, KV cache loss, and prohibitive recomputation overhead. To address this problem, this paper presents ReMP, a runtime model parallelism reconfiguration framework that supports low downtime. ReMP achieves dynamic adjustment through three key techniques: (1) decoupling the model parallelism topology from runtime state to avoid full service reconstruction; (2) designing a two-dimensional KV cache migration mechanism to preserve reusable cache states after TP/PP changes; and (3) implementing end-to-end online reconfiguration. Experiments demonstrate that ReMP can complete most topology switches within 1-7 seconds on models ranging from 7B to 70B parameters, achieving speedups of tens to over a hundred times compared to the restart approach. Moreover, ReMP significantly outperforms fixed configurations under dynamic workloads, delivering superior performance in terms of TTFT, TPOT, and output throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ReMP, a runtime model-parallelism reconfiguration framework for LLM serving systems that use tensor parallelism (TP) and pipeline parallelism (PP). It claims to enable low-downtime dynamic adjustment of parallelism topology via three techniques: decoupling topology from runtime state, a two-dimensional KV cache migration mechanism to preserve reusable states after TP/PP changes, and end-to-end online reconfiguration. Experiments are said to show most topology switches complete in 1-7 seconds on 7B-70B models (tens to >100x speedup vs. restart), plus superior TTFT/TPOT/throughput under dynamic workloads compared to fixed configurations.
Significance. If the central claims hold with rigorous validation, the work would address a practical limitation in production LLM serving by allowing online adaptation to changing workloads without minutes-long interruptions or full KV cache loss. The engineering focus on preserving cache state during arbitrary reconfigurations could be impactful for efficiency in variable-load environments, provided the migration overhead and correctness are demonstrated at scale.
major comments (2)
- [Abstract (key technique 2) and associated system description] The two-dimensional KV cache migration mechanism is load-bearing for the 1-7s latency claim and the assertion that reusable cache states are preserved after arbitrary TP/PP changes. The manuscript provides no mapping algorithm, handling for partial sequences or in-flight requests, per-layer migration time measurements, or edge-case analysis (e.g., non-power-of-two TP factors or hidden-dimension scaling), making it impossible to assess whether migration cost remains inside the reported window or introduces correctness errors.
- [Experiments section (implied by abstract claims)] The experimental claims of speedups and workload-adaptive gains rest on unreported details: no workload traces, baselines (e.g., specific restart implementations or prior reconfiguration systems), error bars, ablation studies on the three techniques, or hardware/setup description are supplied, so the quantitative results (1-7s, tens-to-100x) cannot be evaluated for reproducibility or generality across model sizes.
minor comments (1)
- [Abstract] The abstract states results for 'models ranging from 7B to 70B parameters' but does not specify exact model architectures or layer counts used in the timing measurements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on ReMP. The comments identify areas where expanded technical detail and experimental transparency will strengthen the manuscript. We address each point below and will incorporate the requested information in a major revision.
read point-by-point responses
-
Referee: [Abstract (key technique 2) and associated system description] The two-dimensional KV cache migration mechanism is load-bearing for the 1-7s latency claim and the assertion that reusable cache states are preserved after arbitrary TP/PP changes. The manuscript provides no mapping algorithm, handling for partial sequences or in-flight requests, per-layer migration time measurements, or edge-case analysis (e.g., non-power-of-two TP factors or hidden-dimension scaling), making it impossible to assess whether migration cost remains inside the reported window or introduces correctness errors.
Authors: We agree that the current description of the two-dimensional KV cache migration requires additional explicit detail for full evaluation. In the revised manuscript we will add: (1) the complete mapping algorithm with pseudocode in Section 4.2, (2) explicit handling of partial sequences and in-flight requests (reconfiguration completes the current batch before migration begins and queues new requests), (3) per-layer migration latency breakdowns measured on 7B–70B models, and (4) edge-case analysis covering non-power-of-two TP degrees and hidden-dimension scaling. These additions will be placed in the main text and a new appendix. revision: yes
-
Referee: [Experiments section (implied by abstract claims)] The experimental claims of speedups and workload-adaptive gains rest on unreported details: no workload traces, baselines (e.g., specific restart implementations or prior reconfiguration systems), error bars, ablation studies on the three techniques, or hardware/setup description are supplied, so the quantitative results (1-7s, tens-to-100x) cannot be evaluated for reproducibility or generality across model sizes.
Authors: We acknowledge that the submitted manuscript omitted several experimental details required for reproducibility. The revised version will include: (1) the exact workload traces (both synthetic and production-derived), (2) precise baseline implementations (restart procedure and any prior systems), (3) error bars on all reported figures, (4) ablation studies isolating each of the three core techniques, and (5) complete hardware and software configuration (GPU cluster, interconnect, software versions). A dedicated reproducibility subsection will also be added. revision: yes
Circularity Check
No circularity; engineering claims rest on implementation and reported measurements
full rationale
The paper describes a runtime reconfiguration system for LLM serving using three techniques: decoupling topology from state, a two-dimensional KV cache migration mechanism, and end-to-end online reconfiguration. Central performance claims (1-7s switches, speedups vs restart) are presented as outcomes of experiments on 7B-70B models rather than derived from equations or fitted parameters. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear; the KV cache migration is an implemented mechanism whose correctness and overhead are asserted via the system design and measurements, not reduced to prior inputs by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gulavani, and Ramachandran Ramjee
Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Imple- mentation (OSDI 24). USENIX Association
2024
-
[2]
Reza Yazdani Aminabadi, Samyam Rajbhandari, Minjia Zhang, Am- mar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Jeff Rasley, Shaden Smith, Olatunji Ruwase, and Yuxiong He. 2022. DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale. InProceedings of the International Conference for High Perfor- mance Computing, Network...
2022
-
[3]
Xu Bai, Muhammed Tawfiqul Islam, Chen Wang, and Adel N. Toosi
-
[4]
PipeLive: Efficient Live In-place Pipeline Parallelism Reconfig- uration for Dynamic LLM Serving.arXiv preprint arXiv:2604.12171 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Lequn Chen, Zihao Ye, Yongji Wu, Danyang Zhuo, Luis Ceze, and Arvind Krishnamurthy. 2024. Punica: Multi-Tenant LoRA Serving. In Proceedings of Machine Learning and Systems
2024
-
[6]
Connor Holmes, Masahiro Tanaka, Michael Wyatt, Ammar Ahmad Awan, Jeff Rasley, Samyam Rajbhandari, Reza Yazdani Aminabadi, Heyang Qin, Arash Bakhtiari, Lev Kurilenko, and Yuxiong He. 2024. DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference.arXiv preprint arXiv:2401.08671(2024)
-
[7]
Hugging Face. 2023. Text Generation Inference.https://github.com/ huggingface/text-generation-inference
2023
-
[8]
Gonzalez, Hao Zhang, and Ion Sto- ica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Sto- ica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles. 611–626
2023
-
[9]
Gonzalez, and Ion Stoica
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). USENIX Association, 663–679
2023
-
[10]
Xupeng Miao, Chunan Shi, Jiangfei Duan, Xiaoli Xi, Dahua Lin, Bin Cui, and Zhihao Jia. 2024. SpotServe: Serving Generative Large Language Models on Preemptible Instances. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems
2024
-
[11]
ModelTC. 2023. LightLLM: A Lightweight and High-Performance Large Language Model Service Framework.https://github.com/ ModelTC/lightllm
2023
-
[12]
NVIDIA. 2021. FasterTransformer: Faster Transformer Infer- ence with FasterTransformer and Triton Inference Server. https://developer.nvidia.com/blog/fastertransformer-faster- transformer-inference-with-nvidia-triton-inference-server/
2021
-
[13]
NVIDIA. 2023. TensorRT-LLM: A TensorRT Toolbox for Opti- mized Large Language Model Inference.https://github.com/NVIDIA/ TensorRT-LLM
2023
-
[14]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. InProceedings of the 51st Annual International Symposium on Computer Architecture
2024
-
[15]
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ramachandran Ramjee, and Ashish Panwar. 2025. vAttention: Dynamic Memory Manage- ment for Serving LLMs without PagedAttention. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems
2025
-
[16]
Rui Qin, Ziqian Li, Weiran He, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. A KVCache-centric Architecture for Serving LLM Chatbot. In23rd USENIX Conference on File and Storage Technologies (FAST 25). USENIX Association
2025
-
[17]
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang
-
[18]
InProceedings of the 40th Interna- tional Conference on Machine Learning
FlexGen: High-Throughput Generative Inference of Large Lan- guage Models with a Single GPU. InProceedings of the 40th Interna- tional Conference on Machine Learning. 31094–31116
-
[19]
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. 2024. Llumnix: Dynamic Scheduling for Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association
2024
-
[20]
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, and Xin Jin. 2023. Fast Distributed Inference Serving for Large Language Models.arXiv preprint arXiv:2305.05920(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. ORCA: A Distributed Serving System for Transformer-Based Generative Models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Association, 521–538
2022
-
[22]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: Efficient Execution of Structured Language Model Programs. InThe Thirty-eighth Annual Conference on Neural Information Processing Sys- tems
2024
-
[23]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-Optimized Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.