Recognition: unknown
PipeLive: Efficient Live In-place Pipeline Parallelism Reconfiguration for Dynamic LLM Serving
Pith reviewed 2026-05-10 16:29 UTC · model grok-4.3
The pith
PipeLive enables live in-place pipeline parallelism reconfiguration for LLMs by redesigning KV cache layout and using incremental state patching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PipeLive enables live in-place PP reconfiguration through a redesigned KV cache layout co-designed with an extension to PageAttention for unified live KV resizing, together with an incremental KV patching mechanism that synchronizes states between source and target configurations and identifies a safe switch point, allowing reconfiguration with minimal disruption to ongoing inference.
What carries the argument
Incremental KV patching mechanism that synchronizes KV states between source and target configurations while locating a safe switch point.
Load-bearing premise
The incremental KV patching can reliably locate a safe switch point and preserve KV consistency without introducing errors or large overhead while states continue to evolve during live execution.
What would settle it
A dynamic serving trace in which KV states desynchronize during a live switch, producing incorrect output tokens or a crash, or in which measured reconfiguration time stays above 10 ms.
Figures











read the original abstract
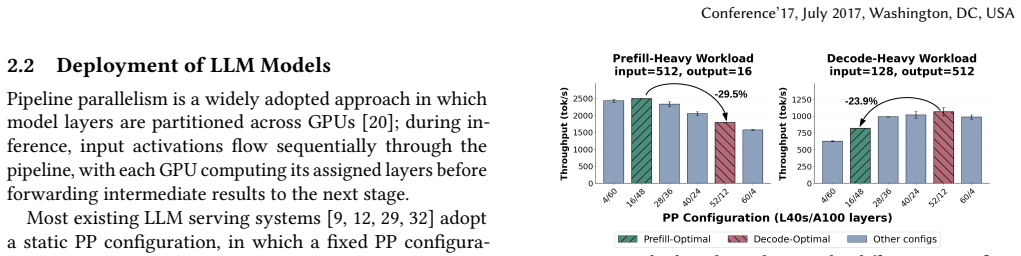
Pipeline parallelism (PP) is widely used to partition layers of large language models (LLMs) across GPUs, enabling scalable inference for large models. However, existing systems rely on static PP configurations that fail to adapt to dynamic settings, such as serverless platforms and heterogeneous GPU environments. Reconfiguring PP by stopping and redeploying service incurs prohibitive downtime, so reconfiguration must instead proceed live and in place, without interrupting inference. However, live in-place PP reconfiguration is fundamentally challenging. GPUs are already saturated with model weights and KV cache, leaving little room for new layer placements and necessitating KV cache resizing, at odds with systems like vLLM that preallocate for throughput. Moreover, maintaining KV consistency during execution is difficult: stop-and-copy introduces large pauses, while background synchronization risks inconsistency as states evolve. We present PipeLive, which enables live in-place PP reconfiguration with minimal disruption. PipeLive introduces a redesigned KV cache layout together with a co-designed extension to PageAttention, forming a unified mechanism for live KV resizing. It further adopts an incremental KV patching mechanism, inspired by live virtual machine migration, to synchronize KV states between source and target configurations and identify a safe switch point. PipeLive achieves a 2.5X reduction in time-to-first-token (TTFT) without KV cache overflow compared to disabling KV resizing. Furthermore, compared to a variant without KV patching, it reduces reconfiguration overhead from seconds to under 10ms, and improves TTFT and time-per-output-token (TPOT) by up to 54.7% and 14.7%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PipeLive, a system enabling live in-place pipeline parallelism (PP) reconfiguration for dynamic LLM serving without interrupting inference. It introduces a redesigned KV cache layout co-designed with an extension to PageAttention for live KV resizing, plus an incremental KV patching mechanism (inspired by VM migration) to synchronize states between source and target PP configurations and locate a safe switch point. Empirical claims include a 2.5X TTFT reduction without KV cache overflow versus disabling resizing, reconfiguration overhead reduced from seconds to under 10 ms versus a no-patching variant, and TTFT/TPOT improvements of up to 54.7% and 14.7%.
Significance. If the central claims hold under realistic workloads, this would be a meaningful systems contribution for serverless and heterogeneous-GPU LLM serving, where static PP configurations are inadequate. The work supplies concrete end-to-end measurements of TTFT, TPOT, and reconfiguration latency on actual hardware, which strengthens the practical relevance of the live-reconfiguration approach.
major comments (2)
- [Section describing incremental KV patching (mechanism and safe-switch logic)] The description of the incremental KV patching mechanism does not specify any verification protocol (e.g., checksums on KV blocks, output-token determinism checks, or bounded generation windows) for confirming KV equivalence at the switch point while new tokens continue to be generated. This is load-bearing for the sub-10 ms overhead and “no inconsistency” claims, because any lag in detecting a safe point risks either using stale KV entries or an implicit stall.
- [Evaluation section (performance figures and tables)] Evaluation results report 2.5X TTFT reduction and 54.7 % / 14.7 % improvements without error bars, number of runs, or data-exclusion criteria. Because the central performance assertions rest on these unreviewed implementation measurements, the absence of statistical detail prevents independent assessment of whether the gains are robust or sensitive to particular workloads or hardware configurations.
minor comments (1)
- [KV cache redesign subsection] Notation for the extended PageAttention data structures and the new KV cache layout could be clarified with an explicit diagram or pseudocode listing the additional fields introduced for live resizing.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our paper. We address each of the major comments in detail below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Section describing incremental KV patching (mechanism and safe-switch logic)] The description of the incremental KV patching mechanism does not specify any verification protocol (e.g., checksums on KV blocks, output-token determinism checks, or bounded generation windows) for confirming KV equivalence at the switch point while new tokens continue to be generated. This is load-bearing for the sub-10 ms overhead and “no inconsistency” claims, because any lag in detecting a safe point risks either using stale KV entries or an implicit stall.
Authors: We appreciate the referee pointing out the need for more detail on the verification of KV equivalence. Upon review, the original manuscript describes the high-level mechanism but does not elaborate on the low-level verification steps. In the revised manuscript, we will add a detailed explanation of the safe-switch logic. The incremental patching uses per-block sequence numbers that are updated atomically with each patch. The target configuration tracks the maximum sequence number received for each KV block. A safe switch point is declared when the target's maximum sequence number matches the source's current generation point (i.e., the last token generated), and no new tokens have been produced in the interim window of 1-2 tokens to bound any potential lag. This design ensures equivalence without expensive checksums, as the sequence numbers guarantee that all prior KV states have been patched. We will include pseudocode and a timing diagram in the revision to clarify this process. revision: yes
-
Referee: [Evaluation section (performance figures and tables)] Evaluation results report 2.5X TTFT reduction and 54.7 % / 14.7 % improvements without error bars, number of runs, or data-exclusion criteria. Because the central performance assertions rest on these unreviewed implementation measurements, the absence of statistical detail prevents independent assessment of whether the gains are robust or sensitive to particular workloads or hardware configurations.
Authors: The referee is correct that additional statistical information would improve the evaluation. We will revise the evaluation section to report that all results are averaged over 10 independent runs, with error bars showing the standard deviation. We will also specify the data collection criteria: experiments were run on a fixed set of 5 representative workloads (including ShareGPT and synthetic traces), with no data points excluded. The hardware setup (8x A100 GPUs) and software versions will be detailed in a new reproducibility subsection. While the observed variance was low (<5% in most cases) due to the deterministic nature of the controlled testbed, we agree that reporting these details allows for better assessment of robustness. revision: yes
Circularity Check
No significant circularity; empirical systems evaluation only
full rationale
The paper describes an engineering system (PipeLive) for live PP reconfiguration using KV cache redesign, PageAttention extension, and incremental patching inspired by VM migration. All central claims (2.5X TTFT reduction, <10ms overhead, 54.7% TTFT and 14.7% TPOT gains) are presented as direct experimental measurements on a prototype, not as quantities derived from equations or parameters fitted within the same work. No self-referential equations, fitted-input predictions, or load-bearing self-citations appear in the provided text. The KV patching mechanism is an implementation choice whose correctness is asserted via runtime behavior and benchmarks rather than reduced to prior self-citations or definitions. This is a standard non-circular systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gulavani, Ramachandran Ramjee, and Alexey Tu- manov
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Ramachandran Ramjee, and Alexey Tu- manov. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
2024
-
[2]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language Models are Few-Shot Learners. (2020)
2020
-
[3]
Christopher Clark, Keir Fraser, Steven Hand, Jacob Gorm Hansen, Eric Jul, Christian Limpach, Ian Pratt, and Andrew Warfield. 2005. Live Migration of Virtual Machines. InProceedings of the 2nd Conference on Symposium on Networked Systems Design & Implementation (NSDI)
2005
-
[4]
Tri Dao. 2024. FlashAttention-2: Faster Attention with Better Paral- lelism and Work Partitioning. InInternational Conference on Learning Representations (ICLR)
2024
-
[5]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[6]
InAdvances in Neural Information Processing Systems (NeurIPS)
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InAdvances in Neural Information Processing Systems (NeurIPS)
-
[7]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. ServerlessLLM: Low- Latency Serverless Inference for Large Language Models. InProceed- ings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24)
2024
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Vaughan, et al. 2024. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [9]
-
[10]
Yiyuan He, Minxian Xu, Jingfeng Wu, Wanyi Zheng, Kejiang Ye, Chengzhong Xu, Walid Gaaloul, Michael Sheng, Qi Yu, and Sami Yangui. 2025. UELLM: A Unified and Efficient Approach for Large Language Model Inference Serving. InInternational Conference on Service-Oriented Computing (ICSOC)
2025
-
[11]
Zixuan Hu, Siyuan Shen, Tommaso Bonato, Sylvain Jeaugey, and Torsten Hoefler. 2025. Demystifying NCCL: An In-Depth Analysis of GPU Communication Protocols and Algorithms. InProceedings of the 39th IEEE International Parallel and Distributed Processing Symposium (IPDPS)
2025
-
[12]
Le, Yonghui Wu, and Zhifeng Chen
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, and Zhifeng Chen. 2019. GPipe: Efficient Training of Giant Neural Networks Using Pipeline Parallelism. InAdvances in Neural Information Processing Systems (NeurIPS)
2019
-
[13]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[14]
InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23)
Efficient Memory Management for Large Language Model Serv- ing with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23)
-
[15]
Yanying Lin, Shijie Peng, Chengzhi Lu, Chengzhong Xu, and Kejiang Ye. 2025. FlexPipe: Adapting Dynamic LLM Serving Through Inflight Pipeline Refactoring in Fragmented Serverless Clusters.arXiv preprint arXiv:2510.11938(2025)
work page internal anchor Pith review arXiv 2025
- [16]
-
[17]
Zizhao Mo, Jianxiong Liao, Huanle Xu, Zhi Zhou, and Chengzhong Xu
-
[18]
InProceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis (SC)
Hetis: Serving LLMs in Heterogeneous GPU Clusters with Fine- grained and Dynamic Parallelism. InProceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis (SC)
-
[19]
Devanur, Gregory R
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R. Devanur, Gregory R. Ganger, Phillip B. Gibbons, and Matei Zaharia. 2019. PipeDream: Generalized Pipeline Parallelism for DNN Training. InProceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP ’19)
2019
-
[20]
OpenAI. 2023. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ramachandran Ramjee, and Ashish Panwar. 2024. vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles (SOSP)
2024
-
[22]
Ruoyu Qin, Zheming Li, Weiran He, Junda Cui, Fangcheng Ren, Mingx- ing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Moon- cake: Trading More Storage for Less Computation — A KVCache- Centric Architecture for Serving LLM Chatbot. In23rd USENIX Con- ference on File and Storage Technologies (FAST 25)
2025
-
[23]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2020. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv preprint arXiv:1909.08053(2020)
work page internal anchor Pith review arXiv 2020
-
[24]
Qidong Su, Wei Zhao, Xin Li, Muralidhar Andoorveedu, Chenhao Jiang, Zhanda Zhu, Kevin Song, Christina Giannoula, and Gennady Pekhimenko. 2025. Seesaw: High-throughput LLM Inference via Model Re-sharding. InProceedings of Machine Learning and Systems (MLSys). 13 Conference’17, July 2017, Washington, DC, USA Xu BAI, Muhammed Tawfiqul Islam, Chen Wang, and A...
2025
-
[25]
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. 2024. Llumnix: Dynamic Scheduling for Large Language Model Serving. InProceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24)
2024
-
[26]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie- Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. LLaMA: Open and Efficient Foundation Language Models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is All You Need. (2017)
2017
-
[28]
Marcel Wagenländer, Guo Li, Bo Zhao, Luo Mai, and Peter Pietzuch
-
[29]
InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles (SOSP)
Tenplex: Dynamic Parallelism for Deep Learning Using Paral- lelizable Tensor Collections. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles (SOSP)
- [30]
-
[31]
Hongxin Xu, Tianyu Guo, and Xianwei Zhang. [n. d.]. DynaPipe: Dynamic Layer Redistribution for Efficient Serving of LLMs with Pipeline Parallelism. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[32]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, et al. 2025. Qwen3 Technical Report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’22)
2022
-
[34]
Zhihang Yuan, Yuzhang Shang, Yang Zhou, Zhen Dong, Zhe Zhou, Chenhao Xue, Bingzhe Wu, Zhikai Li, Qingyi Gu, Yong Jae Lee, Yan Yan, Beidi Chen, Guangyu Sun, and Kurt Keutzer. 2024. LLM Inference Unveiled: Survey and Roofline Model Insights
2024
-
[35]
Xing, Joseph E
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. 2022. Alpa: Au- tomating Inter- and Intra-Operator Parallelism for Distributed Deep Learning. (2022)
2022
-
[36]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: Efficient Execution of Structured Language Model Programs. InAd- vances in Neural Information Processing Systems (NeurIPS)
2024
-
[37]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. InProceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24). 14
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.