Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness
Pith reviewed 2026-06-26 21:13 UTC · model grok-4.3
The pith
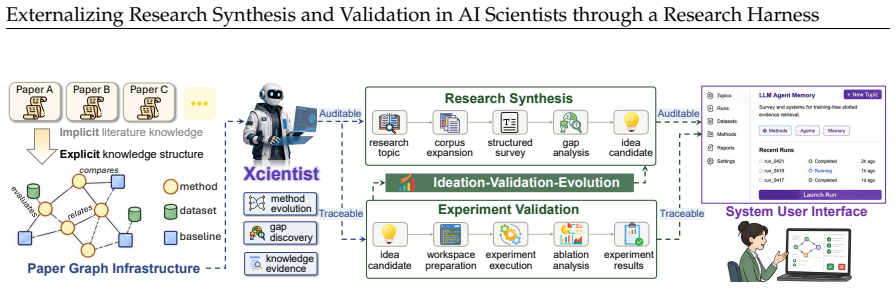
Xcientist externalizes research synthesis into persistent artifacts to preserve traceable trajectories from problem to validation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Xcientist organizes literature evidence, idea states, implementation plans, ablation records and repair traces as persistent research artifacts so that generated mechanisms can be grounded, executed, tested and revised without losing their evidential basis, thereby preserving traceable trajectories from problem formulation to mechanism design, validation and bounded revision across the three domains.
What carries the argument
Xcientist, the research harness that externalizes research synthesis and experimental validation into inspectable, contract-governed processes using persistent research artifacts.
If this is right
- AI scientists can be evaluated not only by final artifacts but by whether synthesis and validation processes remain attributable and inspectable.
- Generated mechanisms stay grounded in an evidential basis through testing and bounded revision.
- Claim drift is treated as a preventable failure mode rather than an inevitable one.
- Research workflows become contract-governed so that every step from evidence to revision stays linked.
Where Pith is reading between the lines
- The same artifact-organization approach could be applied to other automated discovery pipelines beyond the three domains tested.
- Persistent artifacts might raise the bar for reproducibility standards in any AI-assisted research.
- Harness-style externalization could reduce hidden drift in multi-agent AI systems where several models collaborate on a single claim.
- If the harness works, human reviewers could audit the full trajectory instead of only the final paper or code.
Load-bearing premise
Organizing literature evidence, idea states, implementation plans, ablation records and repair traces as persistent research artifacts will reliably prevent claim drift without the harness itself introducing new untraceable elements or implementation failures.
What would settle it
A run of Xcientist on one of the three domains in which the final runnable artifact no longer supports the mechanism that was originally claimed, or in which the harness output itself contains steps that cannot be traced back to the stored artifacts.
Figures






read the original abstract
AI systems can increasingly automate scientific workflows, but the reasoning that links prior evidence, generated ideas, experiments and final claims often remains implicit inside model inference. Here we introduce Xcientist, a research harness that externalizes research synthesis and experimental validation into inspectable, contract-governed processes. Xcientist organizes literature evidence, idea states, implementation plans, ablation records and repair traces as persistent research artifacts, so that generated mechanisms can be grounded, executed, tested and revised without losing their evidential basis. We identify claim drift as a failure mode of automated research, where runnable artifacts no longer support the mechanism originally claimed. Across training-free memory systems, graph-structured traffic forecasting and multi-scale physics-informed neural networks, Xcientist preserves traceable trajectories from problem formulation to mechanism design, validation and bounded revision. These results suggest that AI scientists should be evaluated not only by their final artifacts, but by whether their synthesis and validation processes remain attributable, inspectable and scientifically accountable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Xcientist, a research harness that externalizes research synthesis and validation for AI scientists into inspectable, contract-governed processes. Literature evidence, idea states, implementation plans, ablation records and repair traces are organized as persistent artifacts so that generated mechanisms remain grounded in their evidential basis. The central claim is that this organization prevents claim drift (where runnable artifacts no longer support the originally claimed mechanism) and preserves traceable trajectories from problem formulation through mechanism design, validation and bounded revision. The approach is illustrated across three domains: training-free memory systems, graph-structured traffic forecasting, and multi-scale physics-informed neural networks.
Significance. If the result holds, the work could meaningfully advance evaluation criteria for AI scientists by shifting emphasis from final artifacts alone to the inspectability and accountability of the underlying synthesis and validation processes. The explicit identification of claim drift as a failure mode is a constructive contribution that highlights a previously implicit risk in automated research workflows.
major comments (2)
- [Abstract] Abstract: the assertion that Xcientist 'preserves traceable trajectories' across the three domains is presented without any quantitative metrics, error analysis, ablation studies or implementation details, which is load-bearing for the central claim that artifact organization reliably blocks claim drift.
- [Harness description (throughout)] Harness description (throughout): no section addresses whether the harness implementation and contract governance themselves remain fully traceable or could silently drop, rewrite or obscure artifact links; this directly engages the weakest assumption that organization alone suffices for reliability.
minor comments (2)
- [Abstract] The abstract is lengthy and repeats the list of artifact types; condensing it would improve readability.
- [Introduction] Notation for 'claim drift' and 'traceable trajectories' is introduced informally; a short formal definition or operational criteria would aid clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of evidence presentation and underlying assumptions. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that Xcientist 'preserves traceable trajectories' across the three domains is presented without any quantitative metrics, error analysis, ablation studies or implementation details, which is load-bearing for the central claim that artifact organization reliably blocks claim drift.
Authors: The manuscript's core contribution is a conceptual framework for externalizing research processes via persistent artifacts, with claim drift identified as a failure mode. The three domains serve as illustrative case studies demonstrating explicit artifact linking and traceability, rather than as a quantitative evaluation. We agree the abstract phrasing implies broader empirical support than is provided. We will revise the abstract to clarify that traceability is shown through the organization of artifacts in the described examples. revision: yes
-
Referee: [Harness description (throughout)] Harness description (throughout): no section addresses whether the harness implementation and contract governance themselves remain fully traceable or could silently drop, rewrite or obscure artifact links; this directly engages the weakest assumption that organization alone suffices for reliability.
Authors: The manuscript assumes faithful implementation of the contract-governed harness but does not examine meta-level failure modes such as link corruption or rewriting within the harness itself. This is a substantive point about the scope of the reliability claim. We will add a dedicated subsection addressing the assumptions regarding harness implementation and outlining potential safeguards for maintaining artifact integrity at the meta level. revision: yes
Circularity Check
No circularity: architecture proposal with no derivations or self-referential reductions
full rationale
The paper introduces Xcientist as a system architecture for externalizing research processes into persistent artifacts. No equations, fitted parameters, predictions, or derivation chains are described. The central claim concerns the design and application of the harness across domains and does not reduce to its inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are present. This matches the default expectation of a self-contained system description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Exploring the role of large language models in the scientific method: from hypothesis to discovery,
A. Ghafarollahi and M. J. Buehler, “Exploring the role of large language models in the scientific method: from hypothesis to discovery,”Nature Reviews Bioengineering, 2025
2025
-
[2]
From automation to autonomy: A survey on large language models in scientific discovery,
T. Zheng, Z. Deng, H. T. Tsanget al., “From automation to autonomy: A survey on large language models in scientific discovery,”Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025), 2025
2025
-
[3]
Scibench: Evaluating college-level scientific problem-solving abilities of large language models,
X. Wang, Z. Hu, P . Luet al., “Scibench: Evaluating college-level scientific problem-solving abilities of large language models,”Proceedings of the 41st International Conference on Machine Learning (ICML 2024), 2024
2024
-
[4]
Moba: multifaceted memory-enhanced adaptive planning for efficient mobile task automation,
Z. Zhu, H. Tang, Y. Liet al., “Moba: multifaceted memory-enhanced adaptive planning for efficient mobile task automation,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (System Demonstrations), 2025, pp. 535–549. 19 Externalizing Research Synthesis ...
2025
-
[5]
Towards end-to-end automation of ai research,
C. Lu, C. Lu, R. T. Langeet al., “Towards end-to-end automation of ai research,”Nature, vol. 651, no. 8107, pp. 914–919, 2026
2026
-
[6]
The AI scientist-v2: Workshop-level automated scientific discovery via agentic tree search,
Y. Yamada, R. T. Lange, C. Luet al., “The AI scientist-v2: Workshop-level automated scientific discovery via agentic tree search,”arXiv preprint arXiv:2504.08066, 2025
Pith/arXiv arXiv 2025
-
[7]
Evoscientist: Towards multi-agent evolving ai scientists for end-to-end scientific discovery,
Y. Lyu, X. Zhang, X. Yiet al., “Evoscientist: Towards multi-agent evolving ai scientists for end-to-end scientific discovery,”arXiv preprint arXiv:2603.08127, 2026
arXiv 2026
-
[8]
Position: Falsify, don’t just discover – AI generated discoveries are NOT born scientific,
Z. Liu, K. Liu, Y. Zhuet al., “Position: Falsify, don’t just discover – AI generated discoveries are NOT born scientific,”Proceedings of the 42nd International Conference on Machine Learning (ICML 2025 Position Paper Track), 2025
2025
-
[9]
Safescientist: Toward risk-aware scientific discoveries by LLM agents,
K. Zhu, J. Zhang, Z. Qiet al., “Safescientist: Toward risk-aware scientific discoveries by LLM agents,”arXiv preprint arXiv:2505.23559, 2025
arXiv 2025
-
[10]
Researchagent: Iterative research idea generation over scientific literature with large language models,
J. Baek, S. K. Jauhar, S. Cucerzanet al., “Researchagent: Iterative research idea generation over scientific literature with large language models,”Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL 2025), 2025
2025
-
[11]
Research hypothesis generation over scientific knowledge graphs,
A. Borrego, D. Dessí, D. Ayalaet al., “Research hypothesis generation over scientific knowledge graphs,” Knowledge-Based Systems, vol. 315, p. 113280, 2025
2025
-
[12]
GoAI: Enhancing AI students’ learning paths and idea generation via graph of AI ideas,
Y. Weng, Q. Sun, M. Zhuet al., “GoAI: Enhancing AI students’ learning paths and idea generation via graph of AI ideas,”arXiv preprint arXiv:2503.08549, 2025
arXiv 2025
-
[13]
Literature meets data: A synergistic approach to hypothesis generation,
H. Liu, Y. Zhou, M. Liet al., “Literature meets data: A synergistic approach to hypothesis generation,” Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025), 2025
2025
-
[14]
Agent contracts: A formal framework for resource-bounded autonomous AI systems,
Q. Ye and J. Tan, “Agent contracts: A formal framework for resource-bounded autonomous AI systems,” arXiv preprint arXiv:2601.08815, 2025
arXiv 2025
-
[15]
Deepscientist: Advancing frontier-pushing scientific findings progressively,
Y. Weng, M. Zhu, Q. Xieet al., “Deepscientist: Advancing frontier-pushing scientific findings progressively,” arXiv preprint arXiv:2509.26603, 2025
arXiv 2025
-
[16]
Ai-researcher: Autonomous scientific innovation,
J. Tang, L. Xia, Z. Liet al., “Ai-researcher: Autonomous scientific innovation,”Advances in Neural Information Processing Systems, vol. 38, pp. 9481–9520, 2026
2026
-
[17]
Toward autonomous long-horizon engineering for ml research,
G. Chen, J. Chen, L. Chenet al., “Toward autonomous long-horizon engineering for ml research,”arXiv preprint arXiv:2604.13018, 2026
Pith/arXiv arXiv 2026
-
[18]
Internagent-1.5: A unified agentic framework for long-horizon autonomous scientific discovery,
S. Feng, R. Ma, X. Yanet al., “Internagent-1.5: A unified agentic framework for long-horizon autonomous scientific discovery,”arXiv preprint arXiv:2602.08990, 2026
arXiv 2026
-
[19]
Aris: Autonomous research via adversarial multi-agent collaboration,
R. Yang, Y. Li, and S. Li, “Aris: Autonomous research via adversarial multi-agent collaboration,”arXiv preprint arXiv:2605.03042, 2026
Pith/arXiv arXiv 2026
-
[20]
Alphaevolve: A coding agent for scientific and algorithmic discovery,
A. Novikov, N. V ˜u, M. Eisenbergeret al., “Alphaevolve: A coding agent for scientific and algorithmic discovery,”arXiv preprint arXiv:2506.13131, 2025
Pith/arXiv arXiv 2025
-
[21]
Graph wavenet for deep spatial-temporal graph modeling,
Z. Wu, S. Pan, G. Longet al., “Graph wavenet for deep spatial-temporal graph modeling,” inProceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, 2019, pp. 1907–1913
2019
-
[22]
Spatial-temporal identity: A simple yet effective baseline for multivariate time series forecasting,
Z. Shao, Z. Zhang, F. Wanget al., “Spatial-temporal identity: A simple yet effective baseline for multivariate time series forecasting,” inProceedings of the 31st ACM international conference on information & knowledge management, 2022, pp. 4454–4458
2022
-
[23]
Spatio-temporal adaptive embedding makes vanilla transformer sota for traffic forecasting,
H. Liu, Z. Dong, R. Jianget al., “Spatio-temporal adaptive embedding makes vanilla transformer sota for traffic forecasting,” inProceedings of the 32nd ACM international conference on information and knowledge management, 2023, pp. 4125–4129
2023
-
[24]
A-mem: Agentic memory for llm agents,
W. Xu, Z. Liang, K. Meiet al., “A-mem: Agentic memory for llm agents,”Advances in Neural Information Processing Systems, vol. 38, pp. 17 577–17 604, 2026. 20 Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness
2026
-
[25]
Diffusion convolutional recurrent neural network: Data-driven traffic forecasting,
Y. Li, R. Yu, C. Shahabiet al., “Diffusion convolutional recurrent neural network: Data-driven traffic forecasting,”arXiv preprint arXiv:1707.01926, 2017
Pith/arXiv arXiv 2017
-
[26]
Pinnacle: A comprehensive benchmark of physics-informed neural networks for solving pdes,
Z. Hao, J. Yao, C. Suet al., “Pinnacle: A comprehensive benchmark of physics-informed neural networks for solving pdes,”Advances in Neural Information Processing Systems, vol. 37, pp. 76 721–76 774, 2024
2024
-
[27]
A practical pinn framework for multi-scale problems with multi-magnitude loss terms,
Y. Wang, Y. Yao, J. Guoet al., “A practical pinn framework for multi-scale problems with multi-magnitude loss terms,”Journal of Computational Physics, vol. 510, p. 113112, 2024
2024
-
[28]
On the eigenvector bias of fourier feature networks: From regression to solving multi-scale pdes with physics-informed neural networks,
S. Wang, H. Wang, and P . Perdikaris, “On the eigenvector bias of fourier feature networks: From regression to solving multi-scale pdes with physics-informed neural networks,”Computer Methods in Applied Mechanics and Engineering, vol. 384, p. 113938, 2021
2021
-
[29]
The semantic scholar open data platform,
R. Kinney, C. Anastasiades, R. Authuret al., “The semantic scholar open data platform,”arXiv preprint arXiv:2301.10140, 2023
arXiv 2023
-
[30]
Mineru: An open-source solution for precise document content extraction,
B. Wang, C. Xu, X. Zhaoet al., “Mineru: An open-source solution for precise document content extraction,” arXiv preprint arXiv:2409.18839, 2024
Pith/arXiv arXiv 2024
-
[31]
Deepsurvey: Enhancing analytical depth and citation reliability in automated survey generation,
Z. Yang, D. Ma, H. Liet al., “Deepsurvey: Enhancing analytical depth and citation reliability in automated survey generation,”arXiv preprint arXiv:2605.29522, 2026
Pith/arXiv arXiv 2026
-
[32]
Autosurvey: Large language models can automatically write surveys,
Y. Wang, Q. Guo, W. Yaoet al., “Autosurvey: Large language models can automatically write surveys,” Advances in neural information processing systems, vol. 37, pp. 115 119–115 145, 2024
2024
-
[33]
Deep literature survey automation with an iterative workflow,
H. Zhang, H. Cui, Y. Wanget al., “Deep literature survey automation with an iterative workflow,”arXiv preprint arXiv:2510.21900, 2025
arXiv 2025
-
[34]
M.-A. Nguye, M.-D. Nguyen, K. H. Danget al., “Surveyg: A multi-agent llm framework with hierarchical citation graph for automated survey generation,”arXiv preprint arXiv:2510.07733, 2025
arXiv 2025
-
[35]
Surveygen-i: Consistent scientific survey generation with evolving plans and memory-guided writing,
J. Chen, Z. Yang, Y. Shenet al., “Surveygen-i: Consistent scientific survey generation with evolving plans and memory-guided writing,” inProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, 2025, pp. 3687–3714
2025
-
[36]
Surge: A benchmark and evaluation framework for scientific survey generation,
W. Su, A. Xie, Q. Aiet al., “Surge: A benchmark and evaluation framework for scientific survey generation,” arXiv preprint arXiv:2508.15658, 2025
Pith/arXiv arXiv 2025
-
[37]
Scisage: A multi-agent framework for high-quality scientific survey generation,
X. Shi, Q. Kou, Y. Liet al., “Scisage: A multi-agent framework for high-quality scientific survey generation,” ArXiv, vol. abs/2506.12689, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:279402998
arXiv 2025
-
[38]
Surveylens: A research discipline-aware benchmark for automatic survey generation,
B. Guo, Z. Wen, J. Guet al., “Surveylens: A research discipline-aware benchmark for automatic survey generation,”arXiv preprint arXiv:2602.11238, 2026
Pith/arXiv arXiv 2026
-
[39]
Surveybench: Can llm (-agents) write academic surveys that align with reader needs?
Z. Sun, X. Zhu, X. Zhouet al., “Surveybench: Can llm (-agents) write academic surveys that align with reader needs?”arXiv preprint arXiv:2510.03120, 2025
arXiv 2025
-
[40]
Deepsurvey-bench: Evaluating academic value of automatically generated scientific survey,
G.-B. Zhang, D.-Y. Liu, D.-Y. Wuet al., “Deepsurvey-bench: Evaluating academic value of automatically generated scientific survey,”arXiv preprint arXiv:2601.15307, 2026
arXiv 2026
-
[41]
Recurrentgpt: Interactive generation of (arbitrarily) long text,
W. Zhou, Y. E. Jiang, P . Cuiet al., “Recurrentgpt: Interactive generation of (arbitrarily) long text,”ArXiv, vol. abs/2305.13304, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:258832617
arXiv 2023
-
[42]
Agentic autosurvey: Let llms survey llms,
Y. Liu, Y. Wu, D. Zhanget al., “Agentic autosurvey: Let llms survey llms,”ArXiv, vol. abs/2509.18661, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:281495800
arXiv 2025
-
[43]
Dynamic cheatsheet: Test-time learning with adaptive memory,
M. Suzgun, M. Yuksekgonul, F. Bianchiet al., “Dynamic cheatsheet: Test-time learning with adaptive memory,” inProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), 2026, pp. 7080–7106
2026
-
[44]
Tame: A trustworthy test-time evolution of agent memory with systematic benchmarking,
Y. Cheng, J. Zhou, Y. Huet al., “Tame: A trustworthy test-time evolution of agent memory with systematic benchmarking,”arXiv preprint arXiv:2602.03224, 2026. 21 Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness
Pith/arXiv arXiv 2026
-
[45]
S. Forouzandeh, W. Peng, P . Moradiet al., “Learning hierarchical procedural memory for llm agents through bayesian selection and contrastive refinement,”arXiv preprint arXiv:2512.18950, 2025
arXiv 2025
-
[46]
A survey on the memory mechanism of large language model-based agents,
Z. Zhang, Q. Dai, X. Boet al., “A survey on the memory mechanism of large language model-based agents,” ACM Transactions on Information Systems, vol. 43, no. 6, pp. 1–47, 2025
2025
-
[47]
Kvcomm: Online cross-context kv-cache communication for efficient llm-based multi-agent systems,
H. Ye, Z. Gao, M. Maet al., “Kvcomm: Online cross-context kv-cache communication for efficient llm-based multi-agent systems,”Advances in Neural Information Processing Systems, vol. 38, pp. 17 882–17 928, 2026
2026
-
[48]
Agentauditor: Human-level safety and security evaluation for llm agents,
H. Luo, S. Dai, C. Niet al., “Agentauditor: Human-level safety and security evaluation for llm agents,” Advances in Neural Information Processing Systems, vol. 38, pp. 43 241–43 298, 2026
2026
-
[49]
A-memguard: A proactive defense framework for llm-based agent memory,
Q. Wei, T. Yang, Y. Wanget al., “A-memguard: A proactive defense framework for llm-based agent memory,” arXiv preprint arXiv:2510.02373, 2025
arXiv 2025
-
[50]
Trinityguard: A unified framework for safeguarding multi-agent systems,
K. Wang, B. Zeng, Z. Weiet al., “Trinityguard: A unified framework for safeguarding multi-agent systems,” arXiv preprint arXiv:2603.15408, 2026
arXiv 2026
-
[51]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinathet al., “Reflexion: Language agents with verbal reinforcement learning,” Advances in neural information processing systems, vol. 36, pp. 8634–8652, 2023
2023
-
[52]
Analogagent: Self-improving analog circuit design automation with llm agents,
Z. Bao, Z. Lin, J. Wanget al., “Analogagent: Self-improving analog circuit design automation with llm agents,” arXiv preprint arXiv:2603.23910, 2026
arXiv 2026
-
[53]
Automanual: Constructing instruction manuals by llm agents via interactive environmental learning,
M. Chen, Y. Li, Y. Yanget al., “Automanual: Constructing instruction manuals by llm agents via interactive environmental learning,”Advances in Neural Information Processing Systems, vol. 37, pp. 589–631, 2024
2024
-
[54]
Pruning minimal reasoning graphs for efficient retrieval-augmented generation,
N. Wang, K. Zhu, D. Y. Yeeet al., “Pruning minimal reasoning graphs for efficient retrieval-augmented generation,”arXiv preprint arXiv:2602.04926, 2026
arXiv 2026
-
[55]
Buzz: Beehive-structured sparse kv cache with segmented heavy hitters for efficient llm inference,
J. Zhao, Z. Fang, S. Liet al., “Buzz: Beehive-structured sparse kv cache with segmented heavy hitters for efficient llm inference,”ACM Transactions on Intelligent Systems and Technology, 2024
2024
-
[56]
Walk wisely on graph: Knowledge graph reasoning with dual agents via efficient guidance-exploration,
Z. Wang, B. Wang, H. Jinget al., “Walk wisely on graph: Knowledge graph reasoning with dual agents via efficient guidance-exploration,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 12, 2025, pp. 12 818–12 826
2025
-
[57]
Mapagent: Trajectory-constructed memory-augmented planning for mobile task automation,
Y. Kong, D. Shi, G. Yanget al., “Mapagent: Trajectory-constructed memory-augmented planning for mobile task automation,”arXiv preprint arXiv:2507.21953, 2025
arXiv 2025
-
[58]
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents,
Z. Tan, J. Yan, I.-H. Hsuet al., “In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 8416–8439
2025
-
[59]
Cogmem: A cognitive memory architecture for sustained multi-turn reasoning in large language models,
Y. Zhang, J. Hu, M. Draset al., “Cogmem: A cognitive memory architecture for sustained multi-turn reasoning in large language models,”arXiv preprint arXiv:2512.14118, 2025
arXiv 2025
-
[60]
Cortex: Achieving {Low-Latency},{Cost-Efficient} remote data access for {LLM} via {Semantic-Aware} knowledge caching,
C. Ruan, C. Bi, K. Zhenget al., “Cortex: Achieving {Low-Latency},{Cost-Efficient} remote data access for {LLM} via {Semantic-Aware} knowledge caching,” in23rd USENIX Symposium on Networked Systems Design and Implementation (NSDI 26), 2026, pp. 2407–2421
2026
-
[61]
Knowing you don’t know: Learning when to continue search in multi-round rag through self-practicing,
D. Yang, L. Zeng, J. Raoet al., “Knowing you don’t know: Learning when to continue search in multi-round rag through self-practicing,” inProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2025, pp. 1305–1315
2025
-
[62]
Dynamic quality-latency aware routing for llm inference in wireless edge-device networks,
R. Bao, N. Xue, Y. Sunet al., “Dynamic quality-latency aware routing for llm inference in wireless edge-device networks,” in2025 IEEE/CIC International Conference on Communications in China (ICCC Workshops). IEEE, 2025, pp. 1–6
2025
-
[63]
Evaluating very long-term conversational memory of llm agents,
A. Maharana, D.-H. Lee, S. Tulyakovet al., “Evaluating very long-term conversational memory of llm agents,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 13 851–13 870. 22 Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness Appendix A XCI...
2024
-
[64]
Describe prerequisites, trade-offs, design choices, or potential defects
Insight must provide independent analysis beyond summary. Describe prerequisites, trade-offs, design choices, or potential defects
-
[65]
Do not paraphrase or fabricate
Quote must be verbatim text from the original paper. Do not paraphrase or fabricate
-
[66]
Summary must be a concise factual description
-
[67]
PRIORITY: RECALL
Keywords must capture representative concepts for retrieval and filtering. PRIORITY: RECALL. Extract all relevant cores, components, problems, innovations, limitations, and future work. Core versus component: - A core contribution is the largest top-level contribution that is not contained by another entity and can stand alone. - A component is a module, ...
-
[68]
Propose a small set of high-value questions involving relationships among multiple papers, such as comparisons, shared assumptions, conflicting claims, technical lineage, unresolved gaps, or future directions
-
[69]
Answer each question by synthesizing evidence across the related papers
-
[70]
Grounding constraints: 59 Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness - Cite only papers supplied in the input
Produce cross-cluster analysis that identifies patterns, differences, connections, unresolved issues, and research gaps. Grounding constraints: 59 Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness - Cite only papers supplied in the input. - Use exact paper-title citations. - Do not repeat the input verbatim. - Pre...
-
[71]
60 Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness
Map survey-led method clusters and summarize their assumptions, training signals, and operating constraints. 60 Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness
-
[72]
Extract unresolved mechanism bottlenecks from the survey, then identify evaluation blind spots that prevent clean measurement
-
[73]
Produce one search-ready root idea that applies the smallest meaningful repair while preserving the main method axis
-
[74]
Specify only the validation tools needed to falsify the proposed repair. Output strict JSON containing: - key_methods, field_consensus, existing_problems, evaluation_gaps; - preserve_current_idea decision; - grounded mature idea and refinement scope; - exactly one root_idea with contribution, method, risks, target defects, rationale, and evidence anchors;...
-
[75]
Target at least one explicit defect
-
[76]
Explain why the selected operator repairs the defect without feature dumping, unfair comparisons, hidden failure modes, or resource violations
-
[77]
Provide a structured idea payload containing title, abstract, core contribution, method, experiments, risks, and tags
-
[78]
Reference the memory snippets actually used
-
[79]
Introduce a concrete algorithmic intervention. Instrumentation-only ideas are invalid unless 61 Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness they support a substantive mechanism change
-
[80]
Sharpen a scientific thesis, repair a weak assumption, propose a stronger principle, or reframe the parent idea on the same method axis
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.