GraphPO: Graph-based Policy Optimization for Reasoning Models
Pith reviewed 2026-06-26 20:43 UTC · model grok-4.3
The pith
GraphPO represents reasoning rollouts as directed acyclic graphs to merge equivalent paths and improve policy optimization in reinforcement learning with verifiable rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that modeling reasoning rollouts as a directed acyclic graph, with semantic states as nodes and reasoning steps as edges, allows merging of semantically equivalent paths. This merging enables sharing of suffixes across paths, reallocates computational budget to diverse exploration, and supports assigning efficiency advantages to incoming edges and correctness advantages to outgoing edges. Theory establishes that this reduces variance in advantage estimation and improves overall reasoning efficiency. Experiments across multiple large language models and benchmarks demonstrate consistent improvements over chain- and tree-based baselines under fixed token or response bu
What carries the argument
The directed acyclic graph structure for rollouts, where nodes summarize semantic states from paths and edges represent reasoning steps, which enables equivalence class merging.
If this is right
- Advantage estimation variance is reduced compared to independent or tree-structured sampling.
- Reasoning efficiency is enhanced through reallocation of budget away from redundant expansions.
- Process supervision can be derived from outcome rewards via the graph structure.
- Performance improves on reasoning and agentic search tasks with the same computational budget.
- Equivalent paths can share suffixes, enabling more diverse exploration.
Where Pith is reading between the lines
- This graph merging technique might apply to other domains involving sequential reasoning or planning where semantic equivalence can be detected.
- If semantic summarization proves robust, it could lead to more scalable training of reasoning models by maximizing the diversity of explored paths.
- Connections to graph-based search algorithms in AI planning could be explored to further optimize the merging process.
- The variance reduction might compound with other variance-reduction techniques in RL.
Load-bearing premise
The method assumes that semantic states summarized from reasoning paths can be identified accurately enough to merge paths without errors or loss of important distinctions.
What would settle it
A controlled test where paths that are actually distinct are incorrectly merged, resulting in lower performance than tree-based methods, or where variance does not decrease as predicted.
Figures

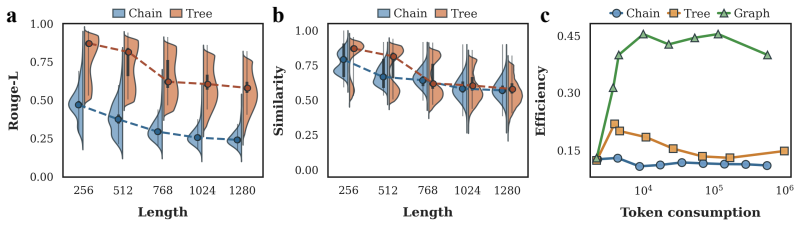
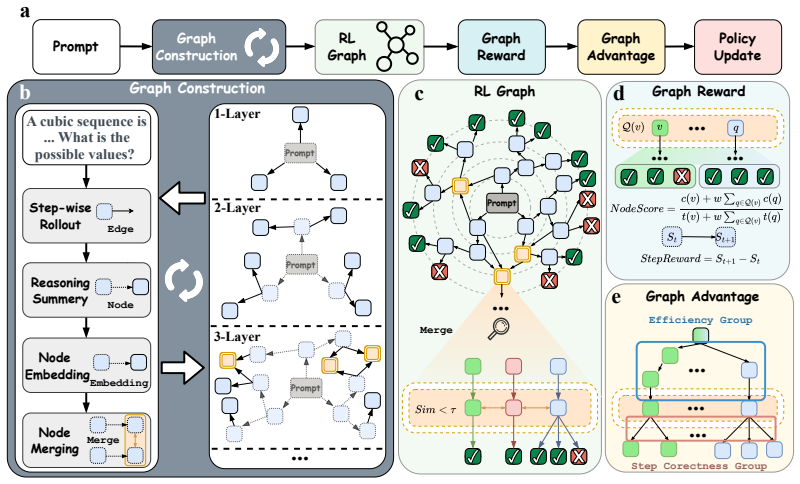
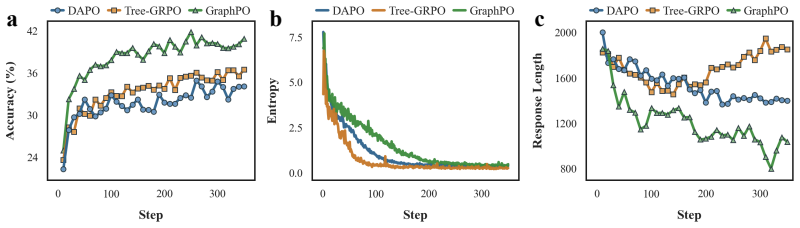
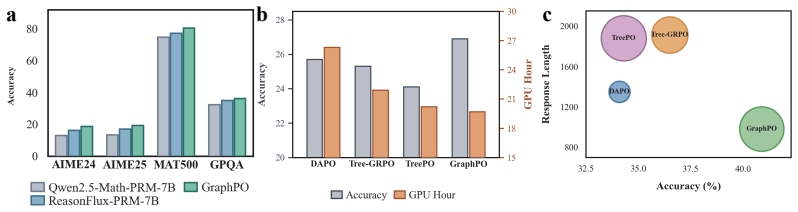

read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has become a standard paradigm for enhancing the capability of large reasoning models. RLVR typically samples responses independently and optimizes the policy using from final answers. This paradigm has two limitations. First, independently responses often contain similar intermediate reasoning steps, causing redundant exploration and wasted computation. Second, sparse final-answer rewards make it hard to identify useful steps. Tree-based methods partly address this problem by sharing prefixes and comparing branches from the same prefix to provide fine-grained signals. However, tree branches are still expanded independently. When different branches reach similar reasoning states, they cannot share information and repeat similar exploration. Moreover, tree-based methods ignore such dispersion and only perform local comparisons within separate branches, which can lead to higher variance in advantage estimation. To address this challenge, we propose GraphPO (Graph-based Policy Optimization), a novel RL framework that represents rollouts as a directed acyclic graph, with reasoning steps as edges and semantic states summarized from the reasoning paths as nodes. GraphPO merges semantically equivalent reasoning paths into equivalence classes, allowing them to share suffixes and reallocating budget away from redundant expansions to diverse exploration. Furthermore, we assign efficiency advantages to incoming edges and correctness advantages to outgoing edges, thereby improving inference efficiency while deriving process supervision from outcome. Theory shows that GraphPO reduces advantage-estimation variance and enhances reasoning efficiency. Experiments on three LLMs across reasoning and agentic search benchmarks show that GraphPO consistently outperforms chain- and tree-based baselines with the same token budgets or response budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GraphPO, a graph-based policy optimization framework for RLVR in large reasoning models. It represents rollouts as a DAG with reasoning steps as edges and semantic states (summarized from paths) as nodes, merging semantically equivalent paths into equivalence classes to share suffixes, reallocate budget from redundant expansions, and assign efficiency advantages to incoming edges plus correctness advantages to outgoing edges. Theory claims variance reduction in advantage estimation; experiments on three LLMs across reasoning and agentic benchmarks report consistent outperformance versus chain- and tree-based baselines under fixed token or response budgets.
Significance. If the equivalence-class merging proves reliable, the approach could improve sample efficiency in reasoning by eliminating redundant exploration across similar states and deriving process-level signals from outcome rewards, addressing a clear limitation of both independent sampling and tree-structured methods. The split-advantage construction and claimed variance reduction are novel extensions worth exploring if the core assumption holds.
major comments (3)
- [Abstract, §3] Abstract and §3 (Graph Construction): the mechanism for summarizing semantic states from reasoning paths, the similarity metric, and any error tolerance or validation for equivalence-class merging are not specified. This is load-bearing for the variance-reduction claim, because over-merging would propagate incorrect shared suffixes and corrupt advantage estimates while under-merging would retain the redundancy the method is designed to eliminate.
- [§4] §4 (Theoretical Analysis): the variance-reduction proof assumes that merged nodes correctly represent identical states; without a stated bound on summarization error or an empirical validation of merge accuracy, the derivation does not establish that the claimed reduction holds under realistic summarization noise.
- [§5] §5 (Experiments): reported gains are stated without error bars, statistical significance tests, or ablation on the summarizer itself; it is therefore impossible to determine whether observed improvements are attributable to the graph structure or to implementation details of the (unspecified) state summarizer.
minor comments (1)
- [§3] Notation for incoming versus outgoing advantages should be introduced with an explicit diagram or equation reference in the method section to avoid ambiguity when reading the advantage-assignment paragraph.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We agree that the state summarization details, theoretical assumptions, and experimental rigor require clarification to substantiate the core claims. We will revise the manuscript to address each point.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Graph Construction): the mechanism for summarizing semantic states from reasoning paths, the similarity metric, and any error tolerance or validation for equivalence-class merging are not specified. This is load-bearing for the variance-reduction claim, because over-merging would propagate incorrect shared suffixes and corrupt advantage estimates while under-merging would retain the redundancy the method is designed to eliminate.
Authors: We agree these implementation details are essential. In the revised manuscript we will expand §3 to specify the summarizer: a fixed sentence embedding model with cosine similarity threshold of 0.85 for merging, plus an empirical validation on a held-out set of 500 paths showing 93% merge accuracy against human annotations. This directly supports the equivalence-class assumption and variance-reduction claim. revision: yes
-
Referee: [§4] §4 (Theoretical Analysis): the variance-reduction proof assumes that merged nodes correctly represent identical states; without a stated bound on summarization error or an empirical validation of merge accuracy, the derivation does not establish that the claimed reduction holds under realistic summarization noise.
Authors: The proof in §4 is derived under the assumption of accurate merging. We will revise §4 to state this assumption explicitly, add a brief error-propagation bound showing that advantage variance remains lower than tree baselines when merge error <8%, and cross-reference the new empirical merge-accuracy results from §3. revision: yes
-
Referee: [§5] §5 (Experiments): reported gains are stated without error bars, statistical significance tests, or ablation on the summarizer itself; it is therefore impossible to determine whether observed improvements are attributable to the graph structure or to implementation details of the (unspecified) state summarizer.
Authors: We will update §5 to report standard deviations over five random seeds, include paired t-test p-values (all reported gains p<0.05), and add an ablation that disables merging while keeping the same summarizer to isolate the graph structure contribution. revision: yes
Circularity Check
No significant circularity in GraphPO derivation chain
full rationale
The paper introduces GraphPO as a new DAG representation for RLVR rollouts, with nodes as summarized semantic states, merging of equivalent paths, and split advantage assignment (efficiency to incoming edges, correctness to outgoing). No equations or steps in the provided abstract reduce by construction to fitted inputs, self-citations, or prior ansatzes from the same authors. The variance-reduction theory and efficiency claims are derived from the proposed graph structure itself rather than renaming or re-fitting existing results. The semantic summarization step is presented as a design choice whose correctness is an empirical assumption, not a definitional loop. This is a standard case of an independent methodological contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[2]
Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
Pith/arXiv arXiv 2025
-
[3]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[4]
Troll: Trust regions improve reinforcement learning for large language models.The Fourteenth International Conference on Learning Representations, 2026
Philipp Becker, Niklas Freymuth, Serge Thilges, Fabian Otto, and Gerhard Neumann. Troll: Trust regions improve reinforcement learning for large language models.The Fourteenth International Conference on Learning Representations, 2026
2026
-
[5]
Geometric-mean policy optimization.The Fourteenth International Conference on Learning Representations, 2026
Yuzhong Zhao, Yue Liu, Junpeng Liu, Jingye Chen, Xun Wu, Yaru Hao, Tengchao Lv, Shaohan Huang, Lei Cui, Qixiang Ye, et al. Geometric-mean policy optimization.The Fourteenth International Conference on Learning Representations, 2026
2026
-
[6]
Dapo: An open-source llm reinforcement learning system at scale.The Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.The Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[7]
Vineppo: Refining credit assignment in rl training of llms.Forty-Second International Conference on Machine Learning, 2025
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. Vineppo: Refining credit assignment in rl training of llms.Forty-Second International Conference on Machine Learning, 2025
2025
-
[8]
Rewarding progress: Scaling automated process verifiers for llm reasoning
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. Rewarding progress: Scaling automated process verifiers for llm reasoning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[9]
Treerpo: Tree relative policy optimization.arXiv preprint arXiv:2506.05183, 2025
Zhicheng Yang, Zhijiang Guo, Yinya Huang, Xiaodan Liang, Yiwei Wang, and Jing Tang. Treerpo: Tree relative policy optimization.arXiv preprint arXiv:2506.05183, 2025
arXiv 2025
-
[10]
Pros: Towards compute-efficient rlvr via rollout prefix reuse
Baizhou Huang and Xiaojun Wan. Pros: Towards compute-efficient rlvr via rollout prefix reuse. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[11]
Let’s verify math questions step by step
Chengyu Shen, Zhen Hao Wong, Runming He, Hao Liang, Meiyi Qiang, Zimo Meng, Zhengyang Zhao, Bohan Zeng, Zhengzhou Zhu, Bin Cui, et al. Let’s verify math questions step by step. InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 2770–2781, 2026. 10
2026
-
[12]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
2024
-
[13]
The lessons of developing process reward models in mathematical reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10495–10516, 2025
2025
-
[14]
Alphamath almost zero: process supervision without process.Advances in Neural Information Processing Systems, 37:27689– 27724, 2024
Guoxin Chen, Minpeng Liao, Chengxi Li, and Kai Fan. Alphamath almost zero: process supervision without process.Advances in Neural Information Processing Systems, 37:27689– 27724, 2024
2024
-
[15]
Mutual rea- soning makes smaller llms stronger problem-solver
Zhenting Qi, MA Mingyuan, Jiahang Xu, Li Lyna Zhang, Fan Yang, and Mao Yang. Mutual rea- soning makes smaller llms stronger problem-solver. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[16]
Process reinforcement through implicit rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, et al. Process reinforcement through implicit rewards. The Fourteenth International Conference on Learning Representations, 2026
2026
-
[17]
Group-in-group policy optimization for llm agent training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[18]
Treepo: Enhancing policy efficacy and inference efficiency with tree modeling.OpenReview preprint, 2025
LI Yizhi, Qingshui Gu, Zhoufutu Wen, Ziniu Li, Ruibin Yuan, Tianshun Xing, Shuyue Guo, Tianyu Zheng, Xingwei Qu, Wangchunshu Zhou, et al. Treepo: Enhancing policy efficacy and inference efficiency with tree modeling.OpenReview preprint, 2025
2025
-
[19]
Tree search for llm agent reinforcement learning.The Fourteenth International Conference on Learning Representations, 2026
Yuxiang Ji, Ziyu Ma, Yong Wang, Guanhua Chen, Xiangxiang Chu, and Liaoni Wu. Tree search for llm agent reinforcement learning.The Fourteenth International Conference on Learning Representations, 2026
2026
-
[20]
Scheduling your llm reinforcement learning with reasoning trees.The Fourteenth International Conference on Learning Representations, 2026
Hong Wang, Zhezheng Hao, Jian Luo, Chenxing Wei, Yao Shu, Lei Liu, Qiang Lin, Hande Dong, and Jiawei Chen. Scheduling your llm reinforcement learning with reasoning trees.The Fourteenth International Conference on Learning Representations, 2026
2026
-
[21]
Treerl: Llm reinforce- ment learning with on-policy tree search
Zhenyu Hou, Ziniu Hu, Yujiang Li, Rui Lu, Jie Tang, and Yuxiao Dong. Treerl: Llm reinforce- ment learning with on-policy tree search. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12355–12369, 2025
2025
-
[22]
Segment policy optimization: Effective segment-level credit assignment in rl for large language models
Yiran Guo, Lijie Xu, Jie Liu, Ye Dan, and Shuang Qiu. Segment policy optimization: Effective segment-level credit assignment in rl for large language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[23]
Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs
Xumeng Wen, Zihan Liu, Shun Zheng, Shengyu Ye, Zhirong Wu, Yang Wang, Zhijian Xu, Xiao Liang, Junjie Li, Ziming Miao, Jiang Bian, and Mao Yang. Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[24]
Reasonflux-prm: Trajectory-aware prms for long chain-of-thought reasoning in llms
Jiaru Zou, Ling Yang, Jingwen Gu, Jiahao Qiu, Ke Shen, Jingrui He, and Mengdi Wang. Reasonflux-prm: Trajectory-aware prms for long chain-of-thought reasoning in llms. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[25]
Trust, but verify: A self-verification approach to reinforcement learning with verifiable rewards
Xiaoyuan Liu, Tian Liang, Zhiwei He, Jiahao Xu, Wenxuan Wang, Pinjia He, Zhaopeng Tu, Haitao Mi, and Dong Yu. Trust, but verify: A self-verification approach to reinforcement learning with verifiable rewards. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[26]
Self-aligned reward: Towards effective and efficient reasoners
Peixuan Han, Adit Krishnan, Gerald Friedland, Jiaxuan You, and Luyang Kong. Self-aligned reward: Towards effective and efficient reasoners. InThe Fourteenth International Conference on Learning Representations, 2026. 11
2026
-
[27]
Lookahead Tree- Based Rollouts for Enhanced Trajectory-Level Exploration in Reinforcement Learning with Verifiable Rewards
Shangyu Xing, Siyuan Wang, Chenyuan Yang, Xinyu Dai, and Xiang Ren. Lookahead Tree- Based Rollouts for Enhanced Trajectory-Level Exploration in Reinforcement Learning with Verifiable Rewards. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[28]
Monte carlo planning with large language model for text- based game agents
Zijing Shi, Meng Fang, and Ling Chen. Monte carlo planning with large language model for text- based game agents. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[29]
Tree-opo: Off-policy monte carlo tree- guided advantage optimization for multistep reasoning
Bingning Huang, Tu Nguyen, and Matthieu Zimmer. Tree-opo: Off-policy monte carlo tree- guided advantage optimization for multistep reasoning. InMATH-AI: The 5th Workshop on Mathematical Reasoning and AI at NeurIPS, 2025
2025
-
[30]
Qwen2.5 technical report.ArXiv, abs/2412.15115, 2024
Qwen An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxin Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin,...
Pith/arXiv arXiv 2024
-
[31]
Sfr-embedding-2: Advanced text embedding with multi-stage training, 2024.URL https://huggingface
Rui Meng, Ye Liu, Shafiq Rayhan Joty, Caiming Xiong, Yingbo Zhou, and Semih Yavuz. Sfr-embedding-2: Advanced text embedding with multi-stage training, 2024.URL https://huggingface. co/Salesforce/SFR-Embedding-2_R, 2024
2024
-
[32]
Mirb: Mathematical information retrieval benchmark
Haocheng Ju and Bin Dong. Mirb: Mathematical information retrieval benchmark. In2nd AI for Math Workshop@ ICML 2025, 2025
2025
-
[33]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021
2021
-
[34]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
Pith/arXiv arXiv 2024
-
[35]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004
2004
-
[36]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
Pith/arXiv arXiv 2021
-
[37]
Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023
Pith/arXiv arXiv 2023
-
[38]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[39]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[40]
Webwalker: Benchmarking llms in web traversal
Jialong Wu, Wenbiao Yin, Yong Jiang, Zhenglin Wang, Zekun Xi, Runnan Fang, Linhai Zhang, Yulan He, Deyu Zhou, Pengjun Xie, et al. Webwalker: Benchmarking llms in web traversal. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10290–10305, 2025
2025
-
[41]
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516, 2025. 12
Pith/arXiv arXiv 2025
-
[42]
Kaiyuan Chen, Yixin Ren, Yang Liu, Xiaobo Hu, Haotong Tian, Tianbao Xie, Fangfu Liu, Haoye Zhang, Hongzhang Liu, Yuan Gong, et al. xbench: Tracking agents productivity scaling with profession-aligned real-world evaluations.arXiv preprint arXiv:2506.13651, 2025
arXiv 2025
-
[43]
React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
Pith/arXiv arXiv 2022
-
[44]
Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
Pith/arXiv arXiv 2024
-
[45]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[46]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Za- mani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
Pith/arXiv arXiv 2025
-
[47]
Jiaxuan Gao, Wei Fu, Minyang Xie, Shusheng Xu, Chuyi He, Zhiyu Mei, Banghua Zhu, and Yi Wu. Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl.arXiv preprint arXiv:2508.07976, 2025
arXiv 2025
-
[48]
self-emergent process supervision
Jialong Wu, Baixuan Li, Runnan Fang, Wenbiao Yin, Liwen Zhang, Zhengwei Tao, Dingchu Zhang, Zekun Xi, Gang Fu, Yong Jiang, et al. Webdancer: Towards autonomous information seeking agency.arXiv preprint arXiv:2505.22648, 2025. 13 APPENDIX A Algorithm We present the complete procedure of GraphPO in Algorithm S.1, which integrates the three stages introduced...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.