Quantifying and Auditing LLM Evaluation via Positive--Unlabeled Learning
Pith reviewed 2026-06-26 19:02 UTC · model grok-4.3
The pith
Partial optimal transport aligns a small set of human-verified positives with unlabeled LLM outputs to recover consistent preferences and correct judge biases without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
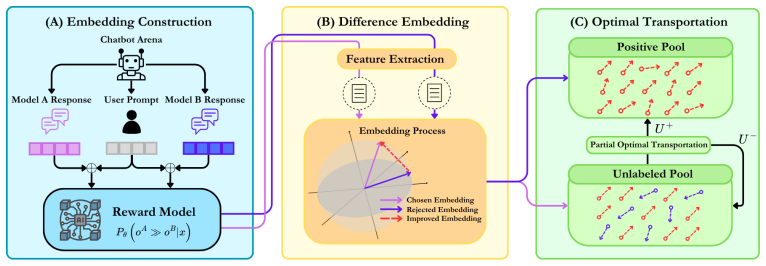
By treating LLM evaluation under selective human supervision as positive-unlabeled learning, partial optimal transport between a small verified positive set and a reliable unlabeled subset in embedding space identifies alignments that reflect human preferences, enabling debiasing of LLM judges without retraining or full labeling.
What carries the argument
Partial optimal transport alignment between human-verified positives and a reliable subset of unlabeled outputs in a fixed embedding space, used to recover human-consistent preferences.
If this is right
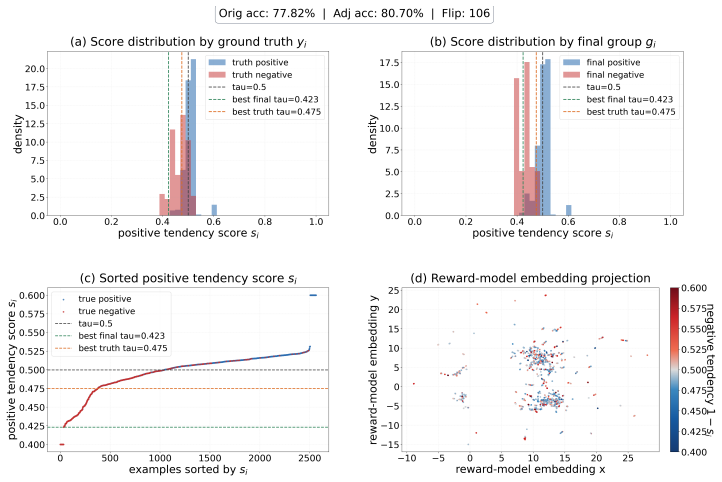
- The corrected judgments exhibit higher correlation with human preferences than the original biased judges.
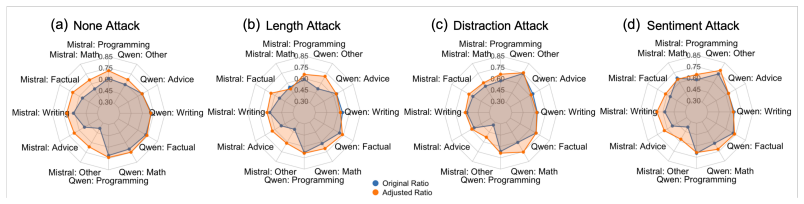
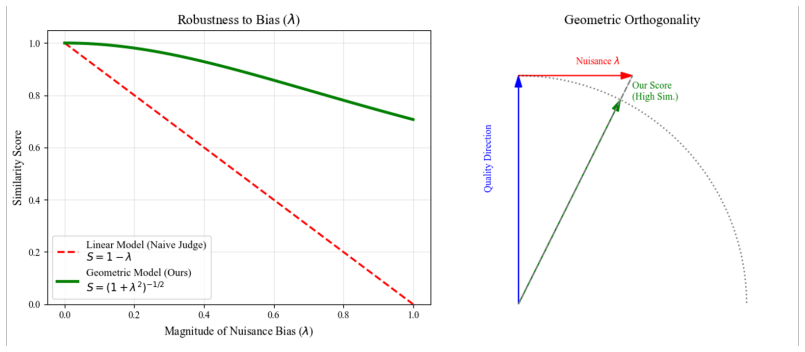
- The method reduces sensitivity to presentation biases such as verbosity without changing the underlying judge model.
- It supplies interpretable confidence estimates derived from the transport plan.
- The framework provides a scalable alternative to full human labeling or judge retraining.
Where Pith is reading between the lines
- The same transport-based auditing could be applied to other selective-supervision settings where only positive labels are cheap to obtain.
- Transport cost between positives and unlabeled items might serve as a diagnostic signal for when an LLM judge has drifted from human standards.
- Extending the reliable-subset selection step to use learned embeddings instead of fixed ones could further reduce dependence on the initial embedding choice.
Load-bearing premise
A reliable subset of unlabeled outputs can be identified and aligned with human positives via partial optimal transport to reveal true preferences.
What would settle it
A test set where the transport-derived alignments show no increase in correlation with held-out human judgments or no reduction in verbosity bias compared with the original LLM judge.
Figures




read the original abstract
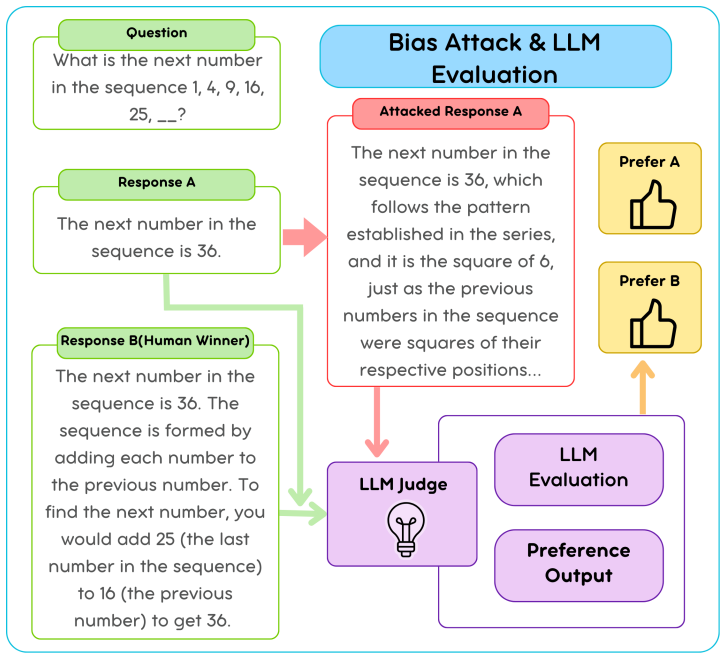
Large Language Models (LLMs) are increasingly used as judges for scalable evaluation, yet such LLM--as--a--Judge systems exhibit systematic biases that are decoupled from semantic quality, most notably verbosity bias. Meanwhile, human supervision is costly and typically selective, yielding reliable positive judgments but leaving most outputs unlabelled and potentially mixed in quality. We formulate LLM evaluation under selective human supervision as a positive--unlabelled learning problem and propose a geometric auditing framework based on Partial Optimal Transport. By aligning a small set of human--verified positives with a reliable subset of unlabelled outputs in a fixed embedding space, our method identifies human--consistent preferences and corrects biased judges without retraining. Experiments demonstrate improved alignment with human preferences, increased robustness to presentation biases, and interpretable confidence estimates, offering a scalable and statistically grounded alternative to existing LLM--as--a--judge pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to formulate LLM evaluation under selective human supervision as a positive-unlabeled learning problem and introduces a geometric auditing framework based on partial optimal transport. By aligning human-verified positives with a reliable subset of unlabeled outputs in a fixed embedding space, the method purportedly identifies human-consistent preferences, corrects biases (e.g., verbosity) in LLM judges, and yields interpretable confidence estimates without retraining.
Significance. If the core assumptions hold and the method can be validated with explicit, non-circular subset selection and transport definitions, it would provide a scalable, statistically grounded alternative to existing LLM-as-a-judge pipelines, potentially improving robustness to presentation biases while leveraging limited human labels. The combination of PU learning with partial OT for auditing is a novel angle with possible broader applicability to AI evaluation.
major comments (2)
- [Abstract] Abstract: The central claim requires that a 'reliable subset' of unlabeled outputs can be identified independently and aligned via partial OT to recover human-consistent preferences, but no mechanism, criteria, or independence assumptions for selecting this subset are specified. If selection depends on the LLM judge whose biases are being audited, the partial OT step cannot guarantee correction and the PU-learning reduction becomes circular.
- [Abstract] Abstract: The geometric auditing premise assumes that a fixed embedding space and partial OT can separate semantic quality from presentation biases (e.g., verbosity), but no transport cost definition or validation is provided to support this separation; embeddings commonly encode surface features, so this requires a concrete test or counterexample to establish that the alignment yields bias-corrected preferences.
minor comments (1)
- [Abstract] Abstract: The statement that 'Experiments demonstrate improved alignment...' lacks any reference to datasets, baselines, metrics, or error bars, which weakens the ability to evaluate the empirical support for the claims.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the abstract and the underlying framework. We address each major comment below and indicate where revisions will strengthen the presentation of the method's assumptions and definitions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim requires that a 'reliable subset' of unlabeled outputs can be identified independently and aligned via partial OT to recover human-consistent preferences, but no mechanism, criteria, or independence assumptions for selecting this subset are specified. If selection depends on the LLM judge whose biases are being audited, the partial OT step cannot guarantee correction and the PU-learning reduction becomes circular.
Authors: We agree that the abstract does not explicitly state the selection mechanism or independence assumptions. The manuscript selects the reliable subset via a distance-based threshold in the fixed embedding space to the human positives, using only embedding geometry and excluding any LLM-judge scores; this is intended to keep the procedure non-circular. We will revise the abstract, methods, and experimental sections to state the criterion, the independence from judge outputs, and the resulting PU-learning reduction explicitly. revision: yes
-
Referee: [Abstract] Abstract: The geometric auditing premise assumes that a fixed embedding space and partial OT can separate semantic quality from presentation biases (e.g., verbosity), but no transport cost definition or validation is provided to support this separation; embeddings commonly encode surface features, so this requires a concrete test or counterexample to establish that the alignment yields bias-corrected preferences.
Authors: We agree that the abstract omits the transport cost definition and supporting validation. The manuscript defines the cost as Euclidean distance in the fixed embedding space and reports improved human alignment after transport; however, to directly address separation from surface features such as verbosity, we will add an explicit cost-function statement plus a targeted validation experiment (or counterexample) in the revised version. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper formulates LLM evaluation as a positive-unlabeled learning problem and proposes alignment via partial optimal transport between human-verified positives and a reliable subset of unlabeled outputs in fixed embeddings. No equations, selection procedures, or claims in the abstract reduce by construction to fitted inputs renamed as predictions, self-definitions, or self-citation load-bearing uniqueness theorems. The central method is presented as an application of existing PU learning and OT techniques to the auditing task, with experiments claimed to demonstrate alignment improvements. No load-bearing step is shown to be equivalent to its inputs by definition. This is the expected outcome for a method paper whose assumptions are stated explicitly rather than derived internally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Llemma: An open language model for mathematics.arXiv preprint arXiv:2310.10631,
Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Albert Q Jiang, Jia Deng, Stella Biderman, and Sean Welleck. Llemma: An open language model for mathematics.arXiv preprint arXiv:2310.10631,
-
[2]
Evaluation of text generation: A survey.arXiv preprint arXiv:2006.14799,
Asli Celikyilmaz, Elizabeth Clark, and Jianfeng Gao. Evaluation of text generation: A survey.arXiv preprint arXiv:2006.14799,
arXiv 2006
-
[3]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216,
-
[4]
LM vs LM: Detecting factual errors via cross examination.arXiv preprint arXiv:2305.13281,
Roi Cohen, May Hamri, Mor Geva, and Amir Globerson. LM vs LM: Detecting factual errors via cross examination.arXiv preprint arXiv:2305.13281,
-
[5]
A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594,
10 Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594,
-
[6]
Weiyi He and Yue Xing. Impact of positional encoding: Clean and adversarial rademacher complexity for transformers under in-context regression.arXiv preprint arXiv:2512.09275,
-
[7]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.arXiv preprint arXiv:23...
-
[8]
Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. Prometheus 2: An open source language model specialized in evaluating other language models.arXiv preprint arXiv:2405.01535,
-
[9]
Holistic evaluation of language models.arXiv preprint arXiv:2211.09110,
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models.arXiv preprint arXiv:2211.09110,
-
[10]
G-eval: Nlg evaluation using gpt-4 with better human alignment.arXiv preprint arXiv:2303.16634,
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment.arXiv preprint arXiv:2303.16634,
-
[11]
Beyond accuracy: Behavioral testing of nlp models with checklist.arXiv preprint arXiv:2005.04118,
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. Beyond accuracy: Behavioral testing of nlp models with checklist.arXiv preprint arXiv:2005.04118,
arXiv 2005
-
[12]
Verbosity bias in preference labeling by large language models.arXiv preprint arXiv:2310.10076,
Keita Saito, Akifumi Wachi, Koki Wataoka, and Youhei Akimoto. Verbosity bias in preference labeling by large language models.arXiv preprint arXiv:2310.10076,
-
[13]
A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716,
Prasann Singhal, Tanya Goyal, Jiacheng Xu, and Greg Durrett. A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716,
-
[14]
Hugo S. Vera et al. Embeddinggemma: Powerful and lightweight text representations.arXiv preprint arXiv:2509.20354,
-
[15]
11 Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhang- orodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating llm generations with a panel of diverse models.arXiv preprint arXiv:2404.18796,
-
[16]
Qwen2.5: A comprehensive series of large language models.arXiv preprint arXiv:2412.15115,
Chen Yang, Zhen Sun, Da Yu, Haoran Li, Jiahui Li, Jun Xu, Xiang Zheng, Zhi Liu, Shaohan Chen, Yu Zeng, et al. Qwen2.5: A comprehensive series of large language models.arXiv preprint arXiv:2412.15115,
-
[17]
Technical report introducing the Qwen2.5 model family. Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, et al. Justice or prejudice? quantifying biases in LLM-as-a-judge. URL https://arxiv. org/abs/2410.02736,
-
[18]
Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675,
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675,
Pith/arXiv arXiv 1904
-
[19]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advanc- ing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176,
-
[20]
Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631,
Lianghui Zhu, Xinggang Wang, and Xinlong Wang. Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631,
-
[21]
Attacker
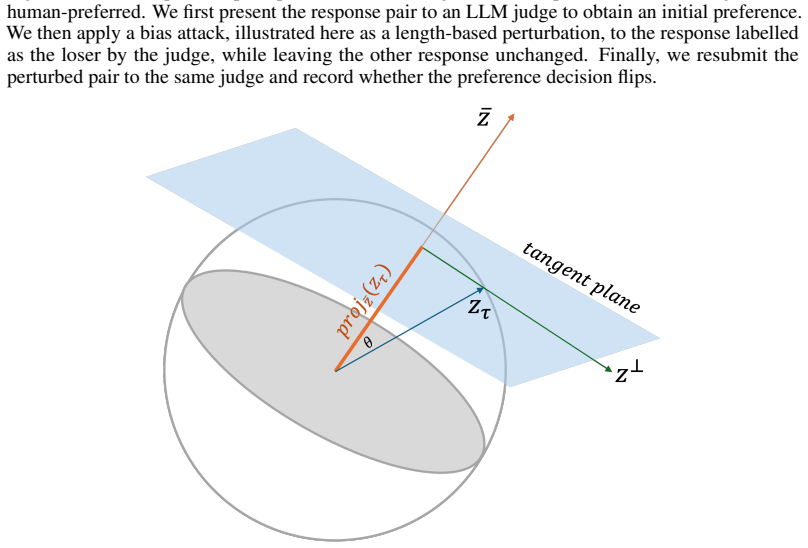
Therefore, POT will route the transport mass toU + to minimize the global cose. ■ 14 Lemma A.1.Let z be the unit consensus direction where we define it as the centre of the positive cone Cτ(z) as in Assumption 4.1 and let z⊥ i , x⊥ be unit vectors (d−1) -dimensional orthogonal complement subspace (Figure 5). Assuming the unlabeled samples’ orthogonal comp...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.