Clusters are All You Need: Pre-Training the Tsetlin Machine with Semantic Clusters from Language Models for Interpretability
Pith reviewed 2026-06-26 17:57 UTC · model grok-4.3
The pith
Semantic clusters from language models pre-train Tsetlin Machines to reach BERT-level accuracy on text tasks while staying interpretable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
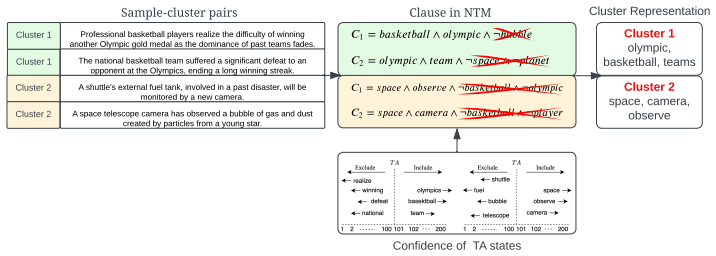
Grouping text samples into semantically coherent clusters with K-means or Top2Vec on language-model representations, then pre-training a non-negated Tsetlin Machine on the resulting cluster-sample pairs with enhanced Type I feedback, lets the machine learn interpretable semantic keywords that transfer to and improve performance on downstream text-classification tasks.
What carries the argument
Semantic cluster pre-training of a non-negated Tsetlin Machine via enhanced Type I feedback on cluster-sample pairs extracted from language-model representations.
If this is right
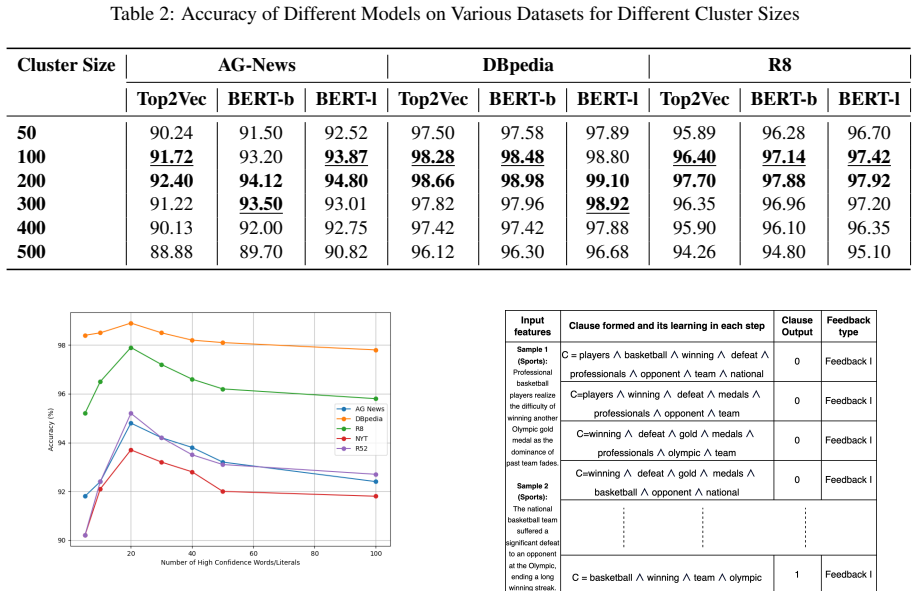
- The pre-trained TM substantially outperforms both vanilla TMs and those that rely on static word embeddings.
- Performance becomes competitive with BERT across the five evaluated datasets.
- The TM retains full clause-based interpretability after pre-training and fine-tuning.
- Semantic keywords learned in pre-training transfer to improve downstream task accuracy.
- No embedding vectors are required at any stage.
Where Pith is reading between the lines
- The same clustering-plus-feedback pattern could be tested on sequence labeling or generation tasks that currently lack interpretable alternatives.
- Replacing K-means or Top2Vec with other clustering algorithms might change how much semantic signal reaches the TM.
- The approach opens a route to pre-train other clause-based or rule-based models on language-model outputs without direct embedding transfer.
- If the clusters prove stable across different language models, the method could reduce dependence on any single pre-trained encoder.
Load-bearing premise
Semantic clusters produced by K-means or Top2Vec on language-model representations contain transferable information that can be injected into a Tsetlin Machine through enhanced Type I feedback without any embedding vectors.
What would settle it
On a held-out dataset, a TM pre-trained this way shows no accuracy gain over a vanilla TM or drops below BERT-level performance while retaining clause interpretability.
Figures

read the original abstract
Pre-trained language models such as BERT achieve strong text classification performance but lack transparency, limiting their use in high-stakes settings. The Tsetlin Machine (TM) offers fully interpretable, clause-based reasoning but captures little semantic information, and prior attempts to bridge the two rely on static word embeddings that miss contextual meaning. We propose a semantic pre-training framework that transfers knowledge from a pre-trained language model into a TM without using embeddings. Text samples are grouped into semantically coherent clusters with K-means or Top2Vec, and the resulting cluster-sample pairs pre-train a non-negated TM with enhanced Type I feedback. The TM thereby learns interpretable semantic keywords that are fine-tuned on downstream tasks. Across five datasets, our method substantially outperforms vanilla and embedding-based TMs and reaches performance competitive with BERT while remaining interpretable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a semantic pre-training framework for Tsetlin Machines that extracts clusters from language-model representations using K-means or Top2Vec, then uses the resulting cluster-sample pairs to pre-train a non-negated TM via enhanced Type I feedback. The TM learns interpretable semantic keywords that are subsequently fine-tuned on downstream classification tasks. The authors report that the method substantially outperforms vanilla and embedding-based TMs and reaches performance competitive with BERT across five datasets while preserving clause-based interpretability.
Significance. If the claimed transfer of semantic information holds and is shown to be robust, the work would provide a concrete route to interpretable models that close much of the performance gap with opaque pre-trained LMs, directly addressing a key limitation of Tsetlin Machines in high-stakes text classification.
major comments (2)
- [Method (pre-training procedure)] The mapping from cluster membership to enhanced Type I feedback is not specified. The abstract states that cluster-sample pairs pre-train the TM, yet no equations, pseudocode, or procedure in the method description shows how cluster labels determine literal reinforcement or feedback polarity. Without this, performance gains cannot be attributed to semantic transfer rather than generic supervised pre-training on cluster IDs.
- [Experiments and Results] The claim of competitiveness with BERT rests on results across five datasets, but no tables, ablation studies, statistical significance tests, or implementation details are provided to verify that the reported gains are supported by the data or that the enhanced feedback is the causal factor.
minor comments (2)
- [Method] Clarify whether the TM remains strictly non-negated throughout pre-training and fine-tuning, and how this interacts with the cluster-based supervision.
- [Background / Method] Provide the exact definition of 'enhanced Type I feedback' and contrast it with standard TM feedback to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to improve clarity and experimental rigor.
read point-by-point responses
-
Referee: [Method (pre-training procedure)] The mapping from cluster membership to enhanced Type I feedback is not specified. The abstract states that cluster-sample pairs pre-train the TM, yet no equations, pseudocode, or procedure in the method description shows how cluster labels determine literal reinforcement or feedback polarity. Without this, performance gains cannot be attributed to semantic transfer rather than generic supervised pre-training on cluster IDs.
Authors: We agree that the mapping requires explicit specification. The revised manuscript will add a dedicated subsection with equations and pseudocode showing how cluster labels determine feedback polarity and literal reinforcement during pre-training. This will clarify the mechanism of semantic transfer from the language-model clusters. revision: yes
-
Referee: [Experiments and Results] The claim of competitiveness with BERT rests on results across five datasets, but no tables, ablation studies, statistical significance tests, or implementation details are provided to verify that the reported gains are supported by the data or that the enhanced feedback is the causal factor.
Authors: We acknowledge the need for expanded experimental reporting. The revision will include full result tables, ablation studies isolating the enhanced feedback, statistical significance tests, and implementation details to substantiate the performance claims and the contribution of the pre-training step. revision: yes
Circularity Check
No significant circularity in cluster-based TM pre-training
full rationale
The described framework derives TM pre-training from externally generated semantic clusters (K-means or Top2Vec on LM representations) and applies enhanced Type I feedback to learn keywords before downstream fine-tuning. No equations, self-citations, or procedures are presented that reduce performance claims to a fitted parameter defined by the same data or that make the transfer equivalent to its inputs by construction. The directional transfer from separate LM to TM remains independent of the target classification results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption K-means or Top2Vec clustering on language-model representations yields semantically coherent groups suitable for TM pre-training
Reference graph
Works this paper leans on
-
[1]
North American Chapter of the Association for Computational Linguistics , year=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. North American Chapter of the Association for Computational Linguistics , year=
-
[2]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=. J. Mach. Learn. Res. , year=
-
[3]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and W...
2020
-
[4]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Guu, Kelvin and Lee, Kenton and Tung, Zora and Pasupat, Panupong and Chang, Ming-Wei , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
2020
-
[5]
ArXiv , year=
Fine-tune BERT for Extractive Summarization , author=. ArXiv , year=
-
[6]
Entity, Relation, and Event Extraction with Contextualized Span Representations
Wadden, David and Wennberg, Ulme and Luan, Yi and Hajishirzi, Hannaneh. Entity, Relation, and Event Extraction with Contextualized Span Representations. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1585
-
[7]
Zhu, Jinhua and Xia, Yingce and Wu, Lijun and He, Di and Qin, Tao and Zhou, Wengang and Li, Houqiang and Liu, Tie-Yan , booktitle =
-
[8]
BlackboxNLP@EMNLP , year=
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding , author=. BlackboxNLP@EMNLP , year=
-
[9]
, title =
Wang, Alex and Pruksachatkun, Yada and Nangia, Nikita and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R. , title =. Proceedings of the 33rd International Conference on Neural Information Processing Systems , articleno =. 2019 , publisher =
2019
-
[10]
A ttention is not E xplanation
Jain, Sarthak and Wallace, Byron C. A ttention is not E xplanation. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1357
-
[11]
Nature Machine Intelligence , year=
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead , author=. Nature Machine Intelligence , year=
-
[12]
Transparency Helps Reveal When Language Models Learn Meaning
Wu, Zhaofeng and Merrill, William and Peng, Hao and Beltagy, Iz and Smith, Noah A. Transparency Helps Reveal When Language Models Learn Meaning. Transactions of the Association for Computational Linguistics. 2023
2023
-
[13]
2022 , url=
Interpretable Machine Learning , author=. 2022 , url=
2022
-
[14]
Darshana and Abouzeid, Ahmed A
Abeyrathna, K. Darshana and Abouzeid, Ahmed A. O. and Bhattarai, Bimal and Giri, Charul and Glimsdal, Sondre and Granmo, Ole-Christoffer and Jiao, Lei and Saha, Rupsa and Sharma, Jivitesh and Tunheim, Svein A. and Zhang, Xuan , title =. 2023 , booktitle =
2023
-
[15]
Enhancing Interpretable Clauses Semantically using Pretrained Word Representation
Yadav, Rohan Kumar and Jiao, Lei and Granmo, Ole-Christoffer and Goodwin, Morten. Enhancing Interpretable Clauses Semantically using Pretrained Word Representation. Proceedings of the Fourth BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP. 2021
2021
-
[16]
ArXiv , year=
The Tsetlin Machine - A Game Theoretic Bandit Driven Approach to Optimal Pattern Recognition with Propositional Logic , author=. ArXiv , year=
-
[17]
Explainable Tsetlin Machine Framework for Fake News Detection with Credibility Score Assessment
Bhattarai, Bimal and Granmo, Ole-Christoffer and Jiao, Lei. Explainable Tsetlin Machine Framework for Fake News Detection with Credibility Score Assessment. Proceedings of the Thirteenth Language Resources and Evaluation Conference. 2022
2022
-
[18]
AAAI Conference on Artificial Intelligence , year=
Human-Level Interpretable Learning for Aspect-Based Sentiment Analysis , author=. AAAI Conference on Artificial Intelligence , year=
-
[19]
IEEE Access , year=
Using the Tsetlin Machine to Learn Human-Interpretable Rules for High-Accuracy Text Categorization With Medical Applications , author=. IEEE Access , year=
-
[20]
2022 International Symposium on the Tsetlin Machine (ISTM) , year=
Interpretable Text Classification in Legal Contract Documents using Tsetlin Machines , author=. 2022 International Symposium on the Tsetlin Machine (ISTM) , year=
2022
-
[21]
ArXiv , year=
Top2Vec: Distributed Representations of Topics , author=. ArXiv , year=
-
[22]
2008 , organization =
Evan Sandhaus , title =. 2008 , organization =
2008
-
[23]
Proceedings of The Web Conference 2020 , year=
Discriminative Topic Mining via Category-Name Guided Text Embedding , author=. Proceedings of The Web Conference 2020 , year=
2020
-
[24]
Neural Information Processing Systems , year=
Character-level Convolutional Networks for Text Classification , author=. Neural Information Processing Systems , year=
-
[25]
Semantic Web , year=
DBpedia - A large-scale, multilingual knowledge base extracted from Wikipedia , author=. Semantic Web , year=
-
[26]
A statistical interpretation of term specificity and its application in retrieval , author=. J. Documentation , year=
-
[27]
Neural Computation , year=
Long Short-Term Memory , author=. Neural Computation , year=
-
[28]
Bag of Tricks for Efficient Text Classification
Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Mikolov, Tomas. Bag of Tricks for Efficient Text Classification. Proceedings of the 15th Conference of the E uropean Chapter of the Association for Computational Linguistics: Volume 2, Short Papers. 2017
2017
-
[29]
China National Conference on Chinese Computational Linguistics , year=
How to Fine-Tune BERT for Text Classification? , author=. China National Conference on Chinese Computational Linguistics , year=
-
[30]
Label-Guided Learning for Item Categorization in e-Commerce
Chen, Lei and Miyake, Hirokazu. Label-Guided Learning for Item Categorization in e-Commerce. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Papers. 2021
2021
-
[31]
IEEE Access , year=
Extending the Tsetlin Machine With Integer-Weighted Clauses for Increased Interpretability , author=. IEEE Access , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.