Timage: A Generative Text-in-Image Paradigm for Fine-Tuning Vision-Language Models
Pith reviewed 2026-06-26 17:50 UTC · model grok-4.3
The pith
Placing the query text as a typeset overlay on the image lets a 7B vision-language model surpass larger systems on spatial tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
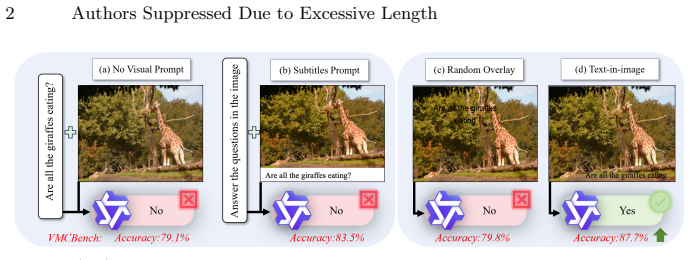
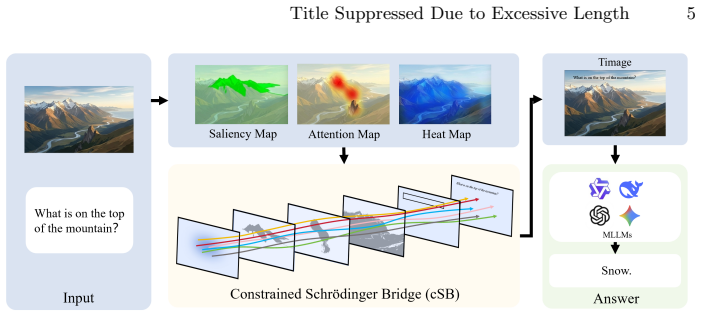
Timage recasts multimodal understanding as an input alignment problem solved by drawing the query as a typeset overlay on the image. Placement and appearance are produced by a Constrained Schrödinger Bridge that factorizes layout into Region Search, which transports noise to query-aligned zones under an occlusion barrier, and Appearance Shaping, which sizes glyphs via an ink-budget regularizer. The resulting overlay functions as an explicit attention beacon that channels focus along spatial semantics. On the VMCBench suite this enables a 7B backbone to overtake far larger proprietary systems and parameter-tuned baselines.
What carries the argument
The Constrained Schrödinger Bridge (cSB), an entropic optimal-transport sampler that produces the text overlay through coupled Region Search and Appearance Shaping stages.
If this is right
- Input-level reconstruction provides an architecture-neutral way to strengthen spatial reasoning in vision-language models.
- A 7B model with Timage can exceed the spatial performance of much larger proprietary systems.
- The method avoids the competence erosion that accompanies weight rewiring or verbose prompt engineering.
- Deliberate overlay placement supplies the geometric anchor that textual queries lack.
- The two-stage transport process balances query alignment against protection of foreground content and text legibility.
Where Pith is reading between the lines
- The approach may generalize to other tasks requiring precise visual grounding, such as object counting or diagram interpretation.
- Similar input reconstruction techniques could be tested on video or 3D data to create temporal or volumetric anchors.
- If the overlay reliably channels attention, it might reduce reliance on attention-map supervision during fine-tuning.
- Applying the same generative overlay process to non-text elements like arrows or highlights could further test the beacon mechanism.
Load-bearing premise
The text overlay generated by the Constrained Schrödinger Bridge reliably serves as an explicit attention beacon that directs focus to spatial semantics without eroding the backbone's general competence.
What would settle it
Measure performance of the 7B backbone on VMCBench both with the generated Timage overlay and with the overlay removed or replaced by random text; the central claim fails if gains disappear or reverse.
Figures

read the original abstract
Multimodal Large Language Models (MLLMs) often lose track of the right image regions during fine-grained spatial reasoning, because a textual query rarely carries any explicit geometric anchor into the pixel domain. Prevailing remedies either rewire the model's weights or pad the prompt with verbose instructions, yet neither reliably pins the language to the correct visual coordinates without eroding the backbone's general competence. We introduce Timage, a paradigm that recasts multimodal understanding as an alignment problem solved at the input: the query is drawn, as a typeset overlay, onto the image itself. The placement and appearance of this overlay are produced by a Constrained Schr\"odinger Bridge (cSB), an entropic optimal-transport sampler that factorizes layout synthesis into two coupled stochastic stages. The first stage, Region Search, transports noise toward query-aligned image zones while obeying a hard occlusion barrier that protects salient foreground content; the second stage, Appearance Shaping, sizes the glyphs through an ``ink-budget'' regularizer so that the rendered text stays legible and visually balanced. The resulting overlay behaves as an explicit attention beacon that channels the model's focus along spatial semantics. On the VMCBench suite, Timage paired with a modest 7B backbone clearly overtakes far larger proprietary systems as well as parameter-tuned baselines. The study positions deliberate input reconstruction as a powerful, architecture-neutral lever for strengthening multimodal reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Timage, a generative text-in-image paradigm that recasts multimodal understanding as an input-level alignment problem. A Constrained Schrödinger Bridge (cSB) factorizes overlay synthesis into a Region Search stage (transporting noise to query-aligned zones under an occlusion barrier) and an Appearance Shaping stage (glyph sizing via an ink-budget regularizer). The resulting typeset overlay is asserted to function as an explicit attention beacon that channels model focus along spatial semantics without eroding backbone competence. On the VMCBench suite the method is reported to allow a 7B backbone to outperform both larger proprietary systems and parameter-tuned baselines.
Significance. If the empirical claims and mechanistic attribution are substantiated, the work would be significant as an architecture-neutral input-reconstruction technique that avoids weight rewiring or verbose prompting while delivering measurable gains on spatial-reasoning benchmarks.
major comments (2)
- [Abstract] Abstract: the central claim that Timage with a 7B backbone 'clearly overtakes far larger proprietary systems' on VMCBench supplies no experimental details, baselines, error bars, dataset splits, or ablation results, rendering the empirical contribution unverifiable from the provided evidence.
- [Abstract] Abstract (positioning effect): the assertion that the cSB overlay 'behaves as an explicit attention beacon' is unsupported by any attention-map comparison, random/fixed-placement ablation, or controlled removal of the occlusion barrier or ink-budget term; without these the performance edge cannot be attributed to the claimed spatial-semantics mechanism rather than simple text presence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below and will make targeted revisions to improve verifiability and mechanistic attribution while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Timage with a 7B backbone 'clearly overtakes far larger proprietary systems' on VMCBench supplies no experimental details, baselines, error bars, dataset splits, or ablation results, rendering the empirical contribution unverifiable from the provided evidence.
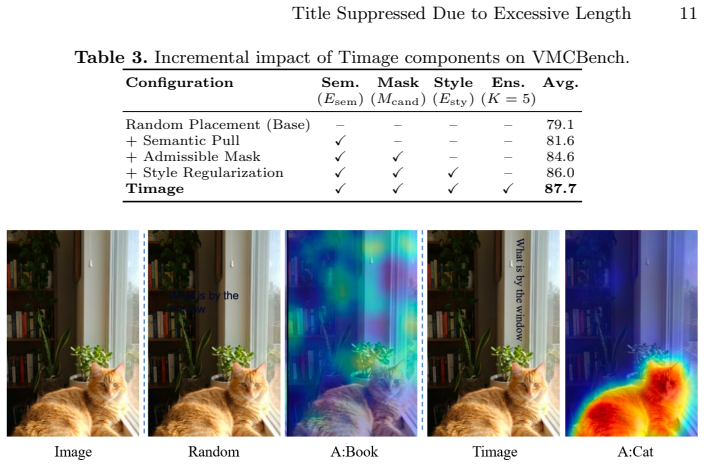
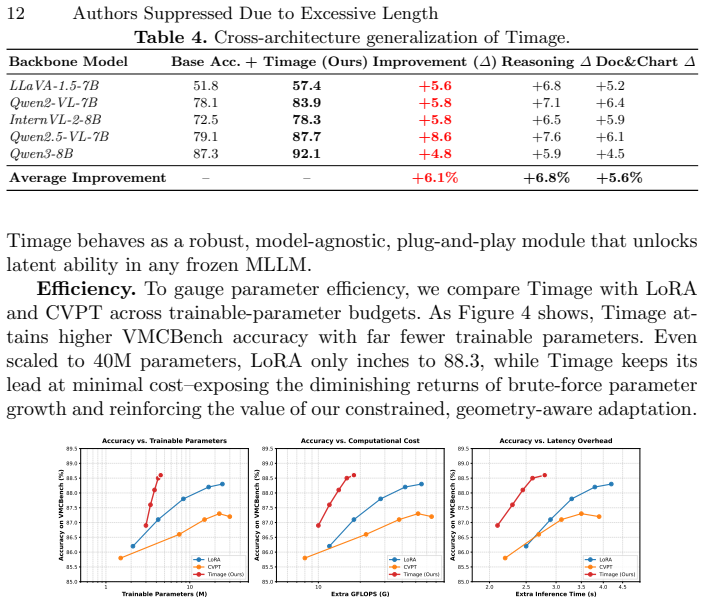
Authors: The full manuscript reports these details in Section 4 (Experiments), including comparisons against GPT-4V, Claude-3, and parameter-tuned 13B/34B baselines, with error bars over 5 seeds on the standard VMCBench train/val/test splits and ablations in Table 3. To address the abstract's self-contained nature, we will revise it to briefly name the primary baselines and note that full results with statistical significance are in the main text. This is a partial revision due to abstract length constraints. revision: partial
-
Referee: [Abstract] Abstract (positioning effect): the assertion that the cSB overlay 'behaves as an explicit attention beacon' is unsupported by any attention-map comparison, random/fixed-placement ablation, or controlled removal of the occlusion barrier or ink-budget term; without these the performance edge cannot be attributed to the claimed spatial-semantics mechanism rather than simple text presence.
Authors: The manuscript contains attention-map comparisons (Figure 5), random/fixed-placement controls, and ablations ablating the occlusion barrier and ink-budget term (Table 3 and Section 4.3), which show that removing either component degrades spatial reasoning gains. We will revise the abstract wording from 'behaves as' to 'is designed to function as, with supporting evidence in Section 4' to better link the claim to the empirical studies. revision: yes
Circularity Check
No circularity: cSB overlay generation is an independent generative process applied to inputs
full rationale
The paper introduces Timage as an input-level alignment method that uses a Constrained Schrödinger Bridge (cSB) to synthesize text overlays via Region Search and Appearance Shaping stages, then feeds the result to an unmodified backbone. No equations, fitted parameters, or self-citations are shown reducing the claimed VMCBench gains or the 'attention beacon' effect to quantities defined by the method's own outputs or prior author work. The derivation chain remains self-contained against external benchmarks, with performance presented as an empirical outcome of the generative process rather than a definitional or fitted tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Entropic optimal-transport principles underlying the Schrödinger Bridge sampler
invented entities (3)
-
Constrained Schrödinger Bridge (cSB)
no independent evidence
-
Region Search stage
no independent evidence
-
Appearance Shaping stage
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Agiza, A., Neseem, M., Reda, S.: Mtlora: Low-rank adaptation approach for ef- ficient multi-task learning. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16196–16205 (2024)
2024
-
[2]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Bengio, Y., L´ eonard, N., Courville, A.: Estimating or propagating gradi- ents through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[3]
In: International Conference on Machine Learning
Chen, M., Radford, A., Child, R., Wu, J., Jun, H., Luan, D., Sutskever, I.: Gener- ative pretraining from pixels. In: International Conference on Machine Learning. pp. 1691–1703. PMLR (2020)
2020
-
[4]
arXiv preprint arXiv:2205.08534 (2022)
Chen, Z., Duan, Y., Wang, W., He, J., Lu, T., Dai, J., Qiao, Y.: Vision transformer adapter for dense predictions. arXiv preprint arXiv:2205.08534 (2022)
-
[5]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Das, R., Dukler, Y., Ravichandran, A., Swaminathan, A.: Learning expressive prompting with residuals for vision transformers. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3366–3377 (2023)
2023
-
[6]
Nature Machine Intelligence5(3), 220–235 (2023)
Ding, N., Qin, Y., Yang, G., Wei, F., Yang, Z., Su, Y., Hu, S., Chen, Y., Chan, C.M., Chen, W., et al.: Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence5(3), 220–235 (2023)
2023
-
[7]
Advances in Neural Information Processing Systems33, 6637–6647 (2020)
Du, Y., Li, S., Mordatch, I.: Compositional visual generation with energy based models. Advances in Neural Information Processing Systems33, 6637–6647 (2020)
2020
-
[8]
In: IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 12873–12883 (2021)
2021
-
[9]
In: International Con- ference on Learning Representations (2025)
Fang, Z., Hsu, D., Lee, G.H., Lee, G.H.: Neuralized markov random field for interaction-aware stochastic human trajectory prediction. In: International Con- ference on Learning Representations (2025)
2025
-
[10]
Advances in Neural Information Processing Systems36, 70757–70798 (2023)
Feng, G., Zhang, B., Gu, Y., Ye, H., He, D., Wang, L.: Towards revealing the mystery behind chain of thought: a theoretical perspective. Advances in Neural Information Processing Systems36, 70757–70798 (2023)
2023
-
[11]
International journal of computer vision132(2), 581–595 (2024)
Gao, P., Geng, S., Zhang, R., Ma, T., Fang, R., Zhang, Y., Li, H., Qiao, Y.: Clip- adapter: Better vision-language models with feature adapters. International journal of computer vision132(2), 581–595 (2024)
2024
-
[12]
arXiv preprint arXiv:2210.04831 (2022)
Gao, Y., Shi, X., Zhu, Y., Wang, H., Tang, Z., Zhou, X., Li, M., Metaxas, D.N.: Visual prompt tuning for test-time domain adaptation. arXiv preprint arXiv:2210.04831 (2022)
-
[13]
The Journal of Chemical Physics 113(1), 297–306 (2000)
Gillespie, D.T.: The chemical langevin equation. The Journal of Chemical Physics 113(1), 297–306 (2000)
2000
-
[14]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gu, T., Chen, G., Li, J., Lin, C., Rao, Y., Zhou, J., Lu, J.: Stochastic trajec- tory prediction via motion indeterminacy diffusion. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17113–17122 (2022) 14 Authors Suppressed Due to Excessive Length
2022
-
[15]
In: International Conference on Machine Learning (2024)
Gushchin, N., Kholkin, S., Burnaev, E., Korotin, A.: Light and optimal schr¨ odinger bridge matching. In: International Conference on Machine Learning (2024)
2024
-
[16]
Advances in Neural Information Processing Systems 37, 89612–89651 (2024)
Gushchin, N., Selikhanovych, D., Kholkin, S., Burnaev, E., Korotin, A.: Adversarial schr¨ odinger bridge matching. Advances in Neural Information Processing Systems 37, 89612–89651 (2024)
2024
-
[17]
arXiv preprint arXiv:2307.13770 (2023)
Han, C., Wang, Q., Cui, Y., Cao, Z., Wang, W., Qi, S., Liu, D.: Eˆ 2vpt: An effective and efficient approach for visual prompt tuning. arXiv preprint arXiv:2307.13770 (2023)
-
[18]
Han, Z., Gao, C., Liu, J., Zhang, J., Zhang, S.Q.: Parameter-efficient fine-tuning for large models: A comprehensive survey (2024),https://arxiv.org/abs/2403. 14608
2024
-
[19]
International Confer- ence on Learning Representations1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. International Confer- ence on Learning Representations1(2), 3 (2022)
2022
-
[20]
In: Conference on Empirical Methods in Natural Language Pro- cessing
Hu, Z., Wang, L., Lan, Y., Xu, W., Lim, E.P., Bing, L., Xu, X., Poria, S., Lee, R.: Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models. In: Conference on Empirical Methods in Natural Language Pro- cessing. pp. 5254–5276 (2023)
2023
-
[21]
In: IEEE/CVF International Conference on Computer Vision
Huang, L., Mao, J., Yi, J., Tao, Z., Wang, Y.: Cvpt: Cross visual prompt tuning. In: IEEE/CVF International Conference on Computer Vision. pp. 848–858 (2025)
2025
-
[22]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Q., Dong, X., Chen, D., Zhang, W., Wang, F., Hua, G., Yu, N.: Diversity- aware meta visual prompting. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10878–10887 (2023)
2023
-
[23]
In: European conference on computer vision
Jia, M., Tang, L., Chen, B.C., Cardie, C., Belongie, S., Hariharan, B., Lim, S.N.: Visual prompt tuning. In: European conference on computer vision. pp. 709–727. Springer (2022)
2022
-
[24]
Denoising Diffusion Probabilistic Models
JonathanHo, A., Abbeel, P.: Denoising diffusion probabilistic models. arXiv preprint arXiv:2006.11239 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[25]
arXiv preprint arXiv:2305.15086 (2023)
Kim, B., Kwon, G., Kim, K., Ye, J.C.: Unpaired image-to-image translation via neural schr¨ odinger bridge. arXiv preprint arXiv:2305.15086 (2023)
-
[26]
arXiv preprint arXiv:2411.14863 (2024)
Kim, J., Kim, B., Ye, J.C.: Latent schrodinger bridge: Prompting latent diffu- sion for fast unpaired image-to-image translation. arXiv preprint arXiv:2411.14863 (2024)
-
[27]
In: International Conference on Learning Representations
Kim, J.H., Kim, S., Moon, S., Kim, H., Woo, J., Kim, W.Y.: Discrete diffusion schr¨ odinger bridge matching for graph transformation. In: International Conference on Learning Representations. pp. 82925–82971 (2025)
2025
-
[28]
In: IEEE/CVF International Conference on Computer Vision
Kodaira, A., Xu, C., Hazama, T., Yoshimoto, T., Ohno, K., Mitsuhori, S., Sugano, S., Cho, H., Liu, Z., Tomizuka, M., et al.: Streamdiffusion: A pipeline-level solution for real-time interactive generation. In: IEEE/CVF International Conference on Computer Vision. pp. 12371–12380 (2025)
2025
-
[29]
arXiv preprint arXiv:2509.17609 (2025)
Li, C., Chen, Z., Wang, L., Zhu, J.: Audio super-resolution with latent bridge models. arXiv preprint arXiv:2509.17609 (2025)
-
[30]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liang, Y.S., Li, W.J.: Inflora: Interference-free low-rank adaptation for continual learning. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23638–23647 (2024)
2024
-
[31]
arXiv preprint arXiv:2302.05872 (2023)
Liu, G.H., Vahdat, A., Huang, D.A., Theodorou, E.A., Nie, W., Anandkumar, A.: I2SB: Image-to-Image Schr¨ odinger Bridge. arXiv preprint arXiv:2302.05872 (2023)
-
[32]
In: Forty-first International Conference on Machine Learning (2024) Title Suppressed Due to Excessive Length 15
Liu, S.Y., Wang, C.Y., Yin, H., Molchanov, P., Wang, Y.C.F., Cheng, K.T., Chen, M.H.: Dora: Weight-decomposed low-rank adaptation. In: Forty-first International Conference on Machine Learning (2024) Title Suppressed Due to Excessive Length 15
2024
-
[33]
Advances in Neural Information Processing Systems35, 5775–5787 (2022)
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in Neural Information Processing Systems35, 5775–5787 (2022)
2022
-
[34]
arXiv preprint arXiv:2311.05556 , year=
Luo, S., Tan, Y., Patil, S., Gu, D., Von Platen, P., Passos, A., Huang, L., Li, J., Zhao, H.: Lcm-lora: A universal stable-diffusion acceleration module. arXiv preprint arXiv:2311.05556 (2023)
-
[35]
Advances in Neural Infor- mation Processing Systems29(2016)
Van den Oord, A., Kalchbrenner, N., Espeholt, L., Vinyals, O., Graves, A., et al.: Conditional image generation with pixelcnn decoders. Advances in Neural Infor- mation Processing Systems29(2016)
2016
-
[36]
Journal of Difference Equa- tions and Applications22(1), 75–98 (2016)
Pierret, F.: A non-standard-euler–maruyama scheme. Journal of Difference Equa- tions and Applications22(1), 75–98 (2016)
2016
-
[37]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Conference
Qiu, X., Yang, M., Ma, X., Li, F., Liang, D., Luo, G., Wang, W., Wang, K., Li, S.: Finding local diffusion schrodinger bridge using kolmogorov-arnold network. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Conference. pp. 23227–23236 (2025)
2025
-
[38]
Advances in Neural Information Processing Systems32(2019)
Razavi, A., Van den Oord, A., Vinyals, O.: Generating diverse high-fidelity images with vq-vae-2. Advances in Neural Information Processing Systems32(2019)
2019
-
[39]
In: International Conference on Machine Learning
Reed, S., Oord, A., Kalchbrenner, N., Colmenarejo, S.G., Wang, Z., Chen, Y., Belov, D., Freitas, N.: Parallel multiscale autoregressive density estimation. In: International Conference on Machine Learning. pp. 2912–2921 (2017)
2017
-
[40]
In: Conference on Computer Vision and Pattern Recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Conference on Computer Vision and Pattern Recognition. pp. 10684–10695 (2022)
2022
-
[41]
Advances in neural information processing systems36, 62183–62223 (2023)
Shi, Y., De Bortoli, V., Campbell, A., Doucet, A.: Diffusion schr¨ odinger bridge matching. Advances in neural information processing systems36, 62183–62223 (2023)
2023
-
[42]
Advances in Neural Information Processing Systems36, 4263–4276 (2023)
Shih, A., Belkhale, S., Ermon, S., Sadigh, D., Anari, N.: Parallel sampling of dif- fusion models. Advances in Neural Information Processing Systems36, 4263–4276 (2023)
2023
-
[43]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sohn, K., Chang, H., Lezama, J., Polania, L., Zhang, H., Hao, Y., Essa, I., Jiang, L.: Visual prompt tuning for generative transfer learning. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19840–19851 (2023)
2023
-
[44]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[45]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[46]
arXiv preprint arXiv:2203.08382 (2022)
Su, X., Song, J., Meng, C., Ermon, S.: Dual diffusion implicit bridges for image- to-image translation. arXiv preprint arXiv:2203.08382 (2022)
-
[47]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sung, Y.L., Cho, J., Bansal, M.: Vl-adapter: Parameter-efficient transfer learning for vision-and-language tasks. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5227–5237 (2022)
2022
-
[48]
arXiv preprint arXiv:2403.14623 (2024)
Tang, Z., Hang, T., Gu, S., Chen, D., Guo, B.: Simplified diffusion schr\” odinger bridge. arXiv preprint arXiv:2403.14623 (2024)
-
[49]
Advances in neural informa- tion processing systems37, 84839–84865 (2024)
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: Scalable image generation via next-scale prediction. Advances in neural informa- tion processing systems37, 84839–84865 (2024)
2024
-
[50]
Advances in neural information processing systems30(2017)
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. Advances in neural information processing systems30(2017)
2017
-
[51]
Advances in Neural Information Processing Systems37, 54905–54931 (2024) 16 Authors Suppressed Due to Excessive Length
Wang, S., Yu, L., Li, J.: Lora-ga: Low-rank adaptation with gradient approxima- tion. Advances in Neural Information Processing Systems37, 54905–54931 (2024) 16 Authors Suppressed Due to Excessive Length
2024
-
[52]
arXiv preprint arXiv:2508.01678 (2025)
Wang, Z., Wang, Y., Cai, Y.: Cure or poison? embedding instructions visually alters hallucination in vision-language models. arXiv preprint arXiv:2508.01678 (2025)
-
[53]
Advances in Neural Information Processing Systems35, 24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems35, 24824–24837 (2022)
2022
-
[54]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2026)
Xu, L., Xie, H., Qin, S.J., Tao, X., Wang, F.L.: Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment. IEEE Transactions on Pattern Analysis and Machine Intelligence (2026)
2026
-
[55]
Vector-quantized Image Modeling with Improved VQGAN
Yu, J., Li, X., Koh, J.Y., Zhang, H., Pang, R., Qin, J., Ku, A., Xu, Y., Baldridge, J., Wu, Y.: Vector-quantized image modeling with improved vqgan. arXiv preprint arXiv:2110.04627 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[56]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Yu, J., Xu, Y., Koh, J.Y., Luong, T., Baid, G., Wang, Z., Vasudevan, V., Ku, A., Yang, Y., Ayan, B.K., et al.: Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.107892(3), 5 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[57]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zanella, M., Ben Ayed, I.: Low-rank few-shot adaptation of vision-language mod- els. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1593–1603 (2024)
2024
-
[58]
arXiv preprint arXiv:2111.03930 (2021)
Zhang, R., Fang, R., Zhang, W., Gao, P., Li, K., Dai, J., Qiao, Y., Li, H.: Tip-adapter: Training-free clip-adapter for better vision-language modeling. arXiv preprint arXiv:2111.03930 (2021)
-
[59]
Advances in Neural Information Processing Systems37, 333–356 (2024)
Zhang, X., Du, C., Pang, T., Liu, Q., Gao, W., Lin, M.: Chain of preference optimization: Improving chain-of-thought reasoning in llms. Advances in Neural Information Processing Systems37, 333–356 (2024)
2024
-
[60]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Conference
Zhang, Y., Su, Y., Liu, Y., Wang, X., Burgess, J., Sui, E., Wang, C., Aklilu, J., Lozano, A., Wei, A., et al.: Automated generation of challenging multiple- choice questions for vision language model evaluation. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Conference. pp. 29580–29590 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.