Addressing Detail Bottlenecks in Latent Diffusion for RGB-to-SWIR Image Translation
Pith reviewed 2026-06-26 18:38 UTC · model grok-4.3
The pith
Source-conditioned skip connections and a learnable guidance encoder preserve fine details lost in latent diffusion for RGB-to-SWIR translation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
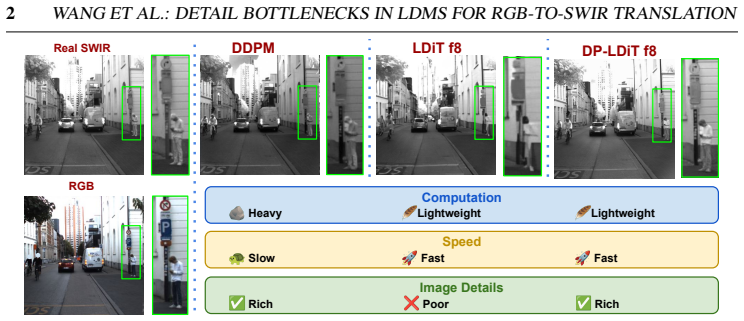
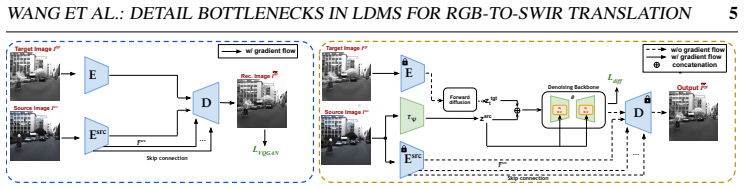
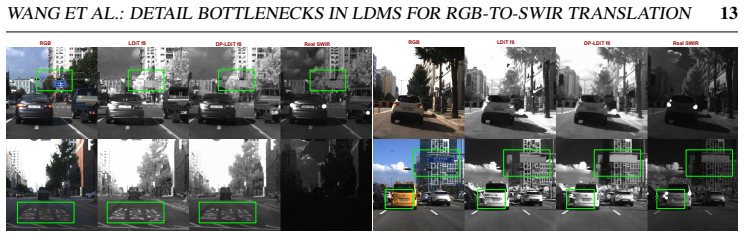
The autoencoder compression and naive conditioning downsampling are the primary causes of detail loss in latent diffusion models; the Source-Conditioned Autoencoder with skip connections from the high-resolution source plus the Learnable Guidance Encoder that supplies a learned conditioning signal mitigate both bottlenecks and restore performance on perception tasks.
What carries the argument
Source-Conditioned Autoencoder (SCAE) that injects high-resolution source features via skip connections into the decoder, combined with Learnable Guidance Encoder (LGE) that replaces naive downsampling of the conditioning signal.
If this is right
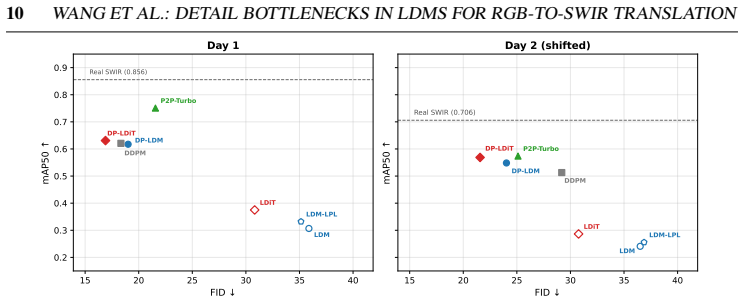
- Detection mAP rises up to 2x over the latent diffusion baseline, with up to 3.4x improvement on small objects under 32 squared pixels.
- State-of-the-art FID scores are reached on the RGB-to-SWIR driving-scene task.
- Performance gains transfer zero-shot to the public RASMD benchmark.
- FID and detection mAP are poorly correlated, requiring evaluation on both axes.
Where Pith is reading between the lines
- The same conditioning and skip-connection pattern may reduce detail loss in other latent-diffusion translation tasks where small-object detection matters.
- Releasing the annotated test data, checkpoints, and code enables direct checks of whether the gains hold on additional backbones or scenes.
- The poor FID-detection correlation suggests that future translation papers should report both metrics rather than FID alone.
Load-bearing premise
The two bottlenecks are the main causes of detail loss and the proposed fixes mitigate them without creating new artifacts or distribution shifts that would reduce detection accuracy.
What would settle it
Retraining the same backbones on the same RGB-to-SWIR data but removing the SCAE skip connections and LGE, then measuring detection mAP on the released test set, would show whether the reported gains disappear.
Figures


read the original abstract
Latent diffusion models (LDMs) enable efficient image-to-image translation but discard fine spatial details during compression, degrading downstream perception tasks. We identify two bottlenecks: the autoencoder, which loses spatial information, and the conditioning pathway, which further degrades the source signal through naive downsampling. We propose two lightweight, backbone-agnostic fixes: a Source-Conditioned Autoencoder (SCAE) that injects high-resolution source features into the decoder via skip connections, and a Learnable Guidance Encoder (LGE) that replaces naive downsampling with a learned conditioning signal. Evaluated on RGB-to-SWIR translation for driving scenes with two denoiser backbones (U-Net and DiT), our approach improves detection mAP by up to 2x over the latent diffusion baseline, with up to 3.4x gains on small objects (COCO-small, <32^2 px^2), while achieving state-of-the-art FID. We further show that FID and detection performance are poorly correlated, motivating multi-axis evaluation. Results generalise zero-shot to the public RASMD benchmark. We will publicly release test data with annotations, all checkpoints, and training code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies two detail-loss bottlenecks in latent diffusion models for RGB-to-SWIR image translation—the autoencoder's spatial compression and naive downsampling in the conditioning path—and introduces SCAE (skip connections from high-res source features) and LGE (learned conditioning encoder) as lightweight, backbone-agnostic remedies. Using U-Net and DiT denoisers on driving-scene data, it reports up to 2× detection mAP gains (3.4× on COCO-small objects), state-of-the-art FID, poor FID-detection correlation, and zero-shot generalization to the RASMD benchmark, with plans to release code, checkpoints, and annotated test data.
Significance. If the mAP improvements can be attributed specifically to bottleneck mitigation rather than capacity increases, the work would meaningfully advance detail-preserving I2I translation for perception-critical applications such as autonomous driving. The backbone-agnostic design, multi-metric evaluation emphasis, and commitment to full reproducibility (code, checkpoints, data) are concrete strengths that would facilitate adoption and follow-up research.
major comments (2)
- [Experiments section] Experiments section (results tables and ablations): No parameter or FLOP counts are reported for the SCAE+LGE variants versus the standard LDM baseline, and no capacity-matched control (e.g., widening the baseline conditioning pathway to equal parameter count) is provided. This directly undermines attribution of the 2×/3.4× mAP gains to the identified bottlenecks rather than added model capacity.
- [§3 (Method)] §3 (Method) and downstream evaluation: The claim that SCAE and LGE 'fully mitigate' the bottlenecks without introducing new artifacts or distribution shifts is not supported by any analysis of feature statistics, reconstruction error on small objects, or controlled ablations separating SCAE from LGE; the detection mAP results therefore cannot securely confirm the weakest assumption.
minor comments (2)
- [Abstract] Abstract: The phrase 'lightweight' is used without supporting parameter counts; this should be quantified or removed.
- [Abstract] The future-tense statement about public release of code and data should be updated to present tense if the artifacts are already available at submission time.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the attribution of gains and the strength of supporting analyses. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments section] Experiments section (results tables and ablations): No parameter or FLOP counts are reported for the SCAE+LGE variants versus the standard LDM baseline, and no capacity-matched control (e.g., widening the baseline conditioning pathway to equal parameter count) is provided. This directly undermines attribution of the 2×/3.4× mAP gains to the identified bottlenecks rather than added model capacity.
Authors: We agree that the absence of parameter/FLOP counts and a capacity-matched control weakens the attribution argument. Although the manuscript describes SCAE and LGE as lightweight (SCAE reuses existing high-res features via skips; LGE is a compact learned encoder replacing naive downsampling), explicit quantification is needed. In revision we will report parameter counts and FLOPs for all variants (baseline, SCAE, LGE, combined) and add a capacity-matched baseline by widening the conditioning pathway to match total parameters. revision: yes
-
Referee: [§3 (Method)] §3 (Method) and downstream evaluation: The claim that SCAE and LGE 'fully mitigate' the bottlenecks without introducing new artifacts or distribution shifts is not supported by any analysis of feature statistics, reconstruction error on small objects, or controlled ablations separating SCAE from LGE; the detection mAP results therefore cannot securely confirm the weakest assumption.
Authors: The manuscript positions SCAE and LGE as remedies rather than claiming they 'fully mitigate' without any side effects; however, we accept that stronger evidence is required. We will add (i) separate ablations isolating SCAE versus LGE, (ii) per-object-size reconstruction error on the autoencoder outputs, and (iii) basic feature-statistic comparisons (mean/variance of latent activations) between baseline and proposed models. These will be included in the revised §3 and experiments. revision: yes
Circularity Check
No circularity: empirical architectural claims rest on external benchmarks
full rationale
The paper proposes two architectural modifications (SCAE skip connections and LGE) to address identified bottlenecks in latent diffusion models for RGB-to-SWIR translation. All load-bearing claims are empirical performance deltas (mAP gains, FID scores) measured against standard LDM baselines on COCO and RASMD benchmarks. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted parameters or self-referential definitions. The central results are externally falsifiable via the released code, checkpoints, and test data; no self-citation chain or ansatz smuggling supports the core argument. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lizard: A Large -Scale Dataset for Colonic Nuclear Instance Segmentation and Classification,
Masoomeh Aslahishahri, Kevin G. Stanley, Hema Duddu, Steve Shirtliffe, Sally Vail, Kirstin Bett, Curtis Pozniak, and Ian Stavness. From RGB to NIR: Pre- dicting of near infrared reflectance from visible spectrum aerial images of crops . In2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), pages 1312–1322, Los Alamitos, CA, USA, O...
-
[2]
Boosting latent diffusion with perceptual objectives
Tariq Berrada, Pietro Astolfi, Melissa Hall, Marton Havasi, Yohann Benchetrit, Adriana Romero-Soriano, Karteek Alahari, Michal Drozdzal, and Jakob Verbeek. Boosting latent diffusion with perceptual objectives. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[3]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alex Nichol. Diffusion models beat GANs on image synthesis. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[4]
Taming transformers for high- resolution image synthesis
Patrick Esser, Robin Rombach, and Björn Ommer. Taming transformers for high- resolution image synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12873–12883, 2021
2021
-
[5]
Springer Nature Switzerland, Cham, 2026
Lore Goetschalckx, Kaili Wang, Siri Willems, and Tom De Schepper.Generative Artificial Intelligence to Tackle Visual Data Accessibility Challenges, pages 105–135. Springer Nature Switzerland, Cham, 2026. doi: 10.1007/978-3-032-10561-5_6
-
[6]
GANs trained by a two time-scale update rule converge to a local Nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[7]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), pages 6840–6851, 2020
2020
-
[8]
Multimodal unsupervised image-to-image translation
Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz. Multimodal unsupervised image-to-image translation. InEuropean Conference on Computer Vision (ECCV), 2018
2018
-
[9]
Image-to-image trans- lation with conditional adversarial networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image trans- lation with conditional adversarial networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5967–5976, 2017. 16W ANG ET AL.: DETAIL BOTTLENECKS IN LDMS FOR RGB-TO-SWIR TRANSLA TION
2017
-
[10]
Rethinking FID: Towards a better evaluation metric for image generation
Sadeep Jayasumana, Srikumar Ramalingam, Andreas Veit, Daniel Glasner, Ayan Chakrabarti, and Sanjiv Kumar. Rethinking FID: Towards a better evaluation metric for image generation. InProceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 9307–9315, 2024
2024
-
[11]
Pix2next: Leveraging vision foundation models for RGB to NIR image transla- tion.Technologies, 13(4):154, 2025
Youngwan Jin, Incheol Park, Hanbin Song, Hyeongjin Ju, Yagiz Nalcakan, and Shiho Kim. Pix2next: Leveraging vision foundation models for RGB to NIR image transla- tion.Technologies, 13(4):154, 2025
2025
-
[12]
Youngwan Jin, Michal Kovac, Yagiz Nalcakan, Incheol Park, Sanghyeop Yeo, Hyeongjin Ju, and Shiho Kim. Rasmd: Rgb and swir multispectral driving dataset for robust perception in adverse conditions.Information Fusion, 128:103872, 2026. ISSN 1566-2535. doi: https://doi.org/10.1016/j.inffus.2025.103872. URLhttps://www. sciencedirect.com/science/article/pii/S1...
-
[13]
Ultralytics yolo26, 2026
Glenn Jocher and Jing Qiu. Ultralytics yolo26, 2026. URLhttps://github. com/ultralytics/ultralytics
2026
-
[14]
ThermalGAN: Multimodal color-to-thermal image translation for person re-identification in multispectral dataset
Vladimir V Kniaz, Vladimir A Knyaz, Ji ˇrí Hlad˚ uvka, Walter G Kropatsch, and Vladimir Mizginov. ThermalGAN: Multimodal color-to-thermal image translation for person re-identification in multispectral dataset. InComputer Vision – ECCV 2018 Workshops, pages 606–624, 2019
2018
-
[15]
Edge-guided multi-domain RGB-to-TIR image translation for training vision tasks with challenging labels
Dong-Guw Lee, Myung-Hwan Jeon, Younggun Cho, and Ayoung Kim. Edge-guided multi-domain RGB-to-TIR image translation for training vision tasks with challenging labels. InProceedings of the IEEE International Conference on Robotics and Automa- tion (ICRA), pages 8291–8298, 2023
2023
-
[16]
BBDM: Image-to-image translation with Brownian bridge diffusion models
Bo Li, Kaitao Xue, Bin Liu, and Yu-Kun Lai. BBDM: Image-to-image translation with Brownian bridge diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1952–1961, 2023
1952
-
[17]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ra- manan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzer- land, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014
2014
-
[18]
InfraGAN: A GAN architecture to transfer visible images to infrared domain.Pattern Recognition Letters, 155:69–76, 2022
Mehmet Akif Özkano ˘glu and Sedat Ozer. InfraGAN: A GAN architecture to transfer visible images to infrared domain.Pattern Recognition Letters, 155:69–76, 2022
2022
-
[19]
One-step im- age translation with text-to-image models.arXiv preprint arXiv:2403.12036, 2024
Gaurav Parmar, Taesung Park, Srinivasa Narasimhan, and Jun-Yan Zhu. One-step im- age translation with text-to-image models.arXiv preprint arXiv:2403.12036, 2024
arXiv 2024
-
[20]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[21]
Nicolas Pinchon, Olivier Cassignol, Adrien Nicolas, Frédéric Bernardin, Patrick Leduc, Jean-Philippe Tarel, Roland Brémond, Emmanuel Bercier, and Johann Brunet. All-weather vision for automotive safety: Which spectral band? In Jörg Dubbert, Beate Müller, and Gereon Meyer, editors,Advanced Microsystems for Automotive Ap- plications 2018, pages 3–15, Cham, ...
2018
-
[22]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Om- mer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[23]
U-Net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer- Assisted Intervention (MICCAI), pages 234–241, 2015
2015
-
[24]
Lee, Jonathan Ho, Tim Sal- imans, David J
Chitwan Saharia, William Chan, Huiwen Chang, Chris A. Lee, Jonathan Ho, Tim Sal- imans, David J. Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. InACM SIGGRAPH 2022 Conference Proceedings, 2022
2022
-
[25]
Adversarial diffusion distillation, 2023
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation, 2023. URLhttps://arxiv.org/abs/2311.17042
arXiv 2023
-
[26]
Denoising diffusion implicit mod- els
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit mod- els. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[27]
Score-based generative modeling through stochastic differen- tial equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Er- mon, and Ben Poole. Score-based generative modeling through stochastic differen- tial equations. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=PxTIG12RRHS
2021
-
[28]
Increasing the diversity in RGB-to-thermal image translation for automotive applications
Kaili Wang, Leonardo Ravaglia, Roberto Longo, Lore Goetschalckx, David Van Hamme, Julie Moeyersoms, Ben Stoffelen, and Tom De Schepper. Increasing the diversity in RGB-to-thermal image translation for automotive applications. InPro- ceedings of the 2024 IEEE Sensors Conference, pages 1–4, 2024
2024
-
[29]
High-resolution image synthesis and semantic manipulation with condi- tional GANs
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with condi- tional GANs. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 8798–8807, 2018
2018
-
[30]
Diffusion-4k: Ultra-high-resolution image synthesis with latent diffusion models
Jinjin Zhang, Qiuyu Huang, Junjie Liu, Xiefan Guo, and Di Huang. Diffusion-4k: Ultra-high-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[31]
Adding conditional control to text- to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text- to-image diffusion models. InIEEE International Conference on Computer Vision (ICCV), 2023
2023
-
[32]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 586–595, 2018
2018
-
[33]
Unpaired image-to- image translation using cycle-consistent adversarial networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to- image translation using cycle-consistent adversarial networks. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2223–2232, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.