Low-Energy Reduced RISC-V Instruction Subset Processor for Tsetlin Machine Inference at the Edge
Pith reviewed 2026-06-26 18:15 UTC · model grok-4.3
The pith
A reduced-instruction RISC-V processor for Tsetlin Machine inference achieves 29.7 times lower energy use while matching or beating binarized neural network accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By profiling instructions on TM inference programs and then pruning the instruction set plus datapath simplifications, the authors produce a smaller RV32IM-derived core that retains full programmability for Tsetlin Machine workloads while delivering the reported accuracy, speed, and energy gains over both a baseline RV32IM core and BNN implementations.
What carries the argument
The reduced instruction subset processor obtained by instruction profiling followed by datapath and control-path simplifications tailored to TM bitwise operations and finite-state automata.
If this is right
- TM inference becomes feasible on a fully programmable core without tight host coupling or microcode.
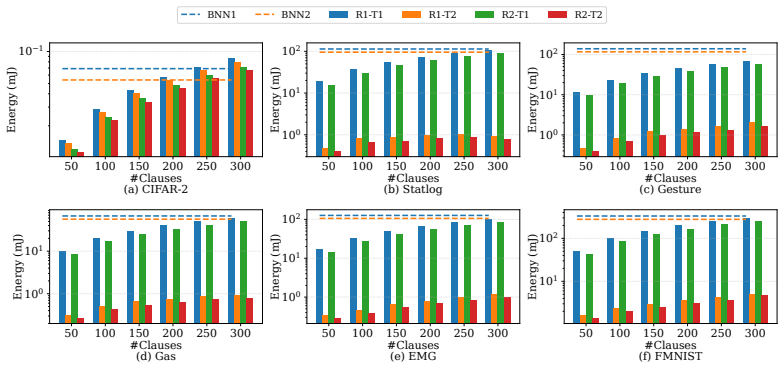
- Energy for edge TM deployments falls by an average factor of 29.7 while accuracy stays comparable to or higher than BNN baselines.
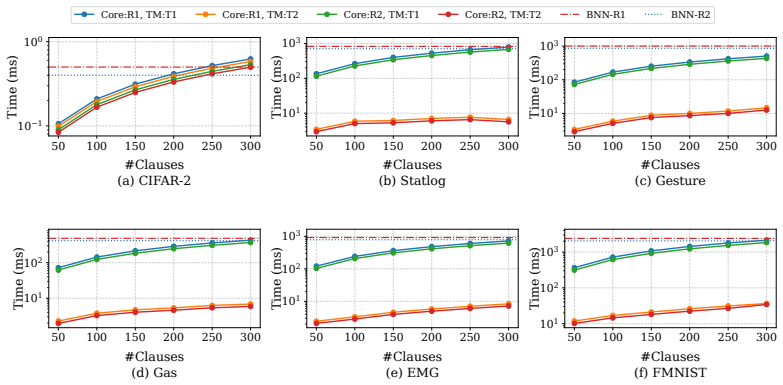
- Execution time for the same TM tasks drops by up to 98 percent across the evaluated datasets.
- The same profiling-plus-simplification flow can be repeated for other logic-based or automata-driven ML models.
Where Pith is reading between the lines
- The reduced core could serve as a template for adding TM-specific custom instructions inside a standard RISC-V toolchain without losing compatibility.
- Energy savings observed on simulation may translate to real silicon only after accounting for memory access patterns that were not re-profiled.
- Designers of other edge processors might apply the same subset-reduction method to workloads dominated by bitwise logic rather than arithmetic.
Load-bearing premise
Instruction profiling on the chosen datasets fully captures every TM inference program that will ever run, and the resulting simplifications preserve functional correctness and accuracy without needing extra host code or microcode.
What would settle it
Execute a Tsetlin Machine program on the reduced core that exercises an instruction removed during profiling and observe whether accuracy drops or the program fails to complete.
Figures




read the original abstract
Tsetlin Machine (TM) is a logic-based machine learning approach that relies on simple bitwise operations and finite-state automata, which makes it attractive for edge AI deployments. Recent work has focused on co-processor and accelerator designs based on Tsetlin Machines (TMs). Although these designs achieve high performance, they typically depend on tightly coupled interfaces, microcode-style programming, and external host processors, limiting flexibility and ease of programming. In this work, we present a domain-specific RISC-V microprocessor architecture and design flow tailored for TM inference. Leveraging the modular structure of RISC-V, we design a reduced instruction subset processor that retains programmability while targeting improved performance and lower energy consumption for TM workloads. Instruction profiling is employed to guide instruction reduction, followed by datapath and control path simplifications tailored to TM inference. Both the baseline RV32IM core and the proposed reduced core are evaluated across multiple datasets and compared with Binarized Neural Networks (BNNs), which serve as a hardware-efficient baseline due to their reliance on bitwise operations during inference. Results show that TM achieves comparable or higher accuracy (e.g., up to 88.18% on CIFAR-2 compared to 60.0% for BNN) while reducing execution time by up to 98% across multiple datasets. Furthermore, the proposed design achieves an average $29.7\times$ reduction in energy consumption, demonstrating its effectiveness for programmable and efficient edge AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a domain-specific reduced RISC-V processor for Tsetlin Machine (TM) inference at the edge. Instruction profiling on TM workloads guides pruning of the RV32IM subset, followed by datapath and control-path simplifications. The design retains programmability and is evaluated against a baseline RV32IM core and Binarized Neural Network (BNN) baselines across multiple datasets, claiming up to 98% execution-time reduction, average 29.7× energy reduction, and accuracy that is comparable or higher than BNNs (e.g., 88.18% vs. 60.0% on CIFAR-2).
Significance. If the reduced core produces functionally equivalent results, the work supplies a programmable, low-energy alternative to tightly coupled TM accelerators or microcode-based co-processors. The direct head-to-head comparisons with both a standard RV32IM core and BNNs on several datasets provide a concrete basis for assessing the claimed efficiency gains.
major comments (1)
- [Design flow / instruction reduction and evaluation sections] The headline accuracy and energy claims rest on the assumption that the profiling-driven instruction subset and datapath simplifications produce bit-equivalent clause and automaton outputs for every valid TM inference program. The manuscript does not describe an exhaustive test suite, formal equivalence check, or coverage argument showing that omitted instructions, addressing modes, or control interactions never arise outside the profiled datasets; without this, the reported 88.18% CIFAR-2 accuracy and 29.7× energy figure cannot be treated as verified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point-by-point below, providing clarification on our verification approach and committing to revisions where appropriate.
read point-by-point responses
-
Referee: [Design flow / instruction reduction and evaluation sections] The headline accuracy and energy claims rest on the assumption that the profiling-driven instruction subset and datapath simplifications produce bit-equivalent clause and automaton outputs for every valid TM inference program. The manuscript does not describe an exhaustive test suite, formal equivalence check, or coverage argument showing that omitted instructions, addressing modes, or control interactions never arise outside the profiled datasets; without this, the reported 88.18% CIFAR-2 accuracy and 29.7× energy figure cannot be treated as verified.
Authors: We acknowledge this is a valid concern for ensuring the claims are robust. Our instruction reduction was derived from dynamic profiling of TM inference workloads across all evaluated datasets (including CIFAR-2), which showed that TM clause evaluation and automaton updates exclusively use a narrow set of RV32IM operations: bitwise AND/XOR, comparisons, and limited arithmetic for state transitions. The TM algorithm's structure (deterministic bitwise clause computation and finite-state updates) inherently excludes many instructions such as multiplication, division, and complex addressing modes. To strengthen the manuscript, we will revise the design flow and evaluation sections to: (1) explicitly list all pruned instructions with profiling coverage metrics, (2) report results from executing the reduced core on additional TM programs generated with varied hyperparameters and random seeds not used in initial profiling, and (3) provide a coverage argument based on the TM inference pseudocode demonstrating that no omitted instructions or control paths can be reached in valid programs. These additions will support the bit-equivalence assumption without requiring formal methods. revision: yes
Circularity Check
No circularity; results from direct simulation on profiled workloads with external baselines
full rationale
The paper's core flow (profiling RV32IM instructions on TM datasets, pruning the subset, simplifying datapath/control, then measuring execution time/energy/accuracy on the same datasets vs. BNN baselines) contains no equations, fitted parameters renamed as predictions, or self-citation chains that reduce any headline claim to its inputs by construction. All reported numbers (e.g., 98% time reduction, 29.7× energy reduction, accuracy figures) are presented as outcomes of explicit implementation/simulation, not derived quantities. This is the normal case of a domain-specific hardware design evaluated against external references.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RISC-V ISA modularity allows safe removal of unused instructions for a target workload without breaking TM inference correctness.
Reference graph
Works this paper leans on
-
[1]
Hardware Accelerator for MobileViT Vision Transformer with Reconfigurable Computation,
S.-F. Hsiao, T.-H. Chao, Y .-C. Yuan, and K.-C. Chen, “Hardware Accelerator for MobileViT Vision Transformer with Reconfigurable Computation,” inProc. of the ISCAS, 2024, pp. 1–4
2024
-
[2]
Tsetlin Machine-Based Image Classification FPGA Accelerator With On-Device Training,
S. A. Tunheim, L. Jiao, R. Shafik, A. Yakovlev, and O.-C. Granmo, “Tsetlin Machine-Based Image Classification FPGA Accelerator With On-Device Training,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 72, no. 2, pp. 830–843, 2025
2025
-
[3]
1.1 The Deep Learning Revolution and its Implications for Computer Architecture and Chip Design,
J. Dean, “1.1 The Deep Learning Revolution and its Implications for Computer Architecture and Chip Design,” inProc. of the ISSCC, 2024, pp. 8–14
2024
-
[4]
Fast and Compact Tsetlin Machine Inference on CPUs Using Instruction-Level Optimization,
Y . Zeng, S. Duan, R. Shafik, and A. Yakovlev, “Fast and Compact Tsetlin Machine Inference on CPUs Using Instruction-Level Optimization,” in Proc. of the ISTM, 2025, pp. 44–47
2025
-
[5]
RISC-V Instruction Set Architecture Extensions: A Survey,
E. Cui, T. Li, and Q. Wei, “RISC-V Instruction Set Architecture Extensions: A Survey,”IEEE Access, vol. 11, pp. 24 696–24 711, 2023
2023
-
[6]
O. C. Granmo, “The Tsetlin Machine – A Game Theoretic Bandit Driven Approach to Optimal Pattern Recognition with Propositional Logic,” 2021. [Online]. Available: https://arxiv.org/abs/1804.01508
-
[7]
ETHEREAL: Energy-efficient and High-throughput Inference using Compressed Tsetlin Machine,
S. Duan, R. Shafik, and A. Yakovlev, “ETHEREAL: Energy-efficient and High-throughput Inference using Compressed Tsetlin Machine,” in Proc. of the IWASI, 2025, pp. 1–6
2025
-
[8]
Learning Dynamics, Pattern Recognition Capability and Interpretability of the Tsetlin Machine,
O. Tarasyuk, A. Gorbenko, T. Rahman, L. Jiao, O.-C. Granmo, R. Shafik, and A. Yakovlev, “Learning Dynamics, Pattern Recognition Capability and Interpretability of the Tsetlin Machine,”Pattern Recognition, vol. 174, p. 113028, 2026
2026
-
[9]
M. Courbariaux, I. Hubara, D. Soudry, R. El-Yaniv, and Y . Bengio, “Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to + 1 or-1,” 2016. [Online]. Available: https://arxiv.org/abs/1602.02830
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[10]
RISC-V GNU Toolchain,
RISC-V Collab, “RISC-V GNU Toolchain,” [Online]. Available: https://github.com/riscv-collab/riscv-gnu-toolchain, 2025, [Accessed:Feb,2026]
2025
-
[11]
REDRESS: Generating Compressed Models for Edge Inference Using Tsetlin Machines,
S. Maheshwari, T. Rahman, R. Shafik, A. Yakovlev, A. Rafiev, L. Jiao, and O.-C. Granmo, “REDRESS: Generating Compressed Models for Edge Inference Using Tsetlin Machines,”IEEE TPAMI, vol. 45, no. 9, pp. 11 152–11 168, 2023
2023
-
[12]
Available: https://github.com/cair/tmu/tree/main, 2025, [Accessed:Feb,2026]
Cair, “TMU,” [Online]. Available: https://github.com/cair/tmu/tree/main, 2025, [Accessed:Feb,2026]
2025
-
[13]
Available: https://github.com/ultraembedded/riscv, 2025, [Accessed:Feb,2026]
Ultraembedded, “RISC-V,” [Online]. Available: https://github.com/ultraembedded/riscv, 2025, [Accessed:Feb,2026]
2025
-
[14]
CIFAR-2,
A. Krizhevsky, V . Nair, and G. Hinton, “CIFAR-2,” [Online]. Available: https://keras.io/api/datasets/cifar10/, 2017, [Accessed:Feb,2026]
2017
-
[15]
Statlog (Vehicle Silhouettes),
P. Mowforth and B. Shepherd, “Statlog (Vehicle Silhouettes),” UCI Machine Learning Repository, [Online]. Available: https://archive.ics.uci.edu/ml/datasets/Statlog+(Vehicle+Silhouettes), 2023, [Accessed:Feb,2026]
2023
-
[16]
Gesture Phase Segmentation,
R. Madeo, P. Wagner, and S. Peres, “Gesture Phase Segmentation,” UCI Machine Learning Repository, [Online]. Available: https://archive.ics.uci.edu/ml/datasets/Gesture+Phase+Segmentation, 2014, [Accessed: Feb, 2026]
2014
-
[17]
Gas Sensor Array Drift Dataset,
A. Vergara, “Gas Sensor Array Drift Dataset,” UCI Machine Learning Repository, [Online]. Available: https://archive.ics.uci.edu/ml/datasets/Gas+Sensor+Array+Drift+Dataset, 2012, [Accessed: Feb, 2026]
2012
-
[18]
EMG Data for Gestures,
N. Krilova, I. Kastalskiy, V . Kazantsev, V . A. Makarov, and S. Lobov, “EMG Data for Gestures,” UCI Machine Learning Repository, [Online]. Available: https://archive.ics.uci.edu/ml/datasets/EMG+data+for+gestures, 2019, [Accessed: Feb, 2026]
2019
-
[19]
Fashion-MNIST,
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-MNIST,” Keras, [Online]. Available: https://keras.io/api/datasets/fashion mnist/, 2017, [Accessed: Feb, 2026]
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.