ReA-OVCD: Reliability-Aware Open-Vocabulary Change Detection via Semantic and Spatial Refinement
Pith reviewed 2026-06-26 18:22 UTC · model grok-4.3
The pith
A training-free method spots land cover changes from any text prompt by deriving pixel discrepancies and refining them semantically and spatially.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
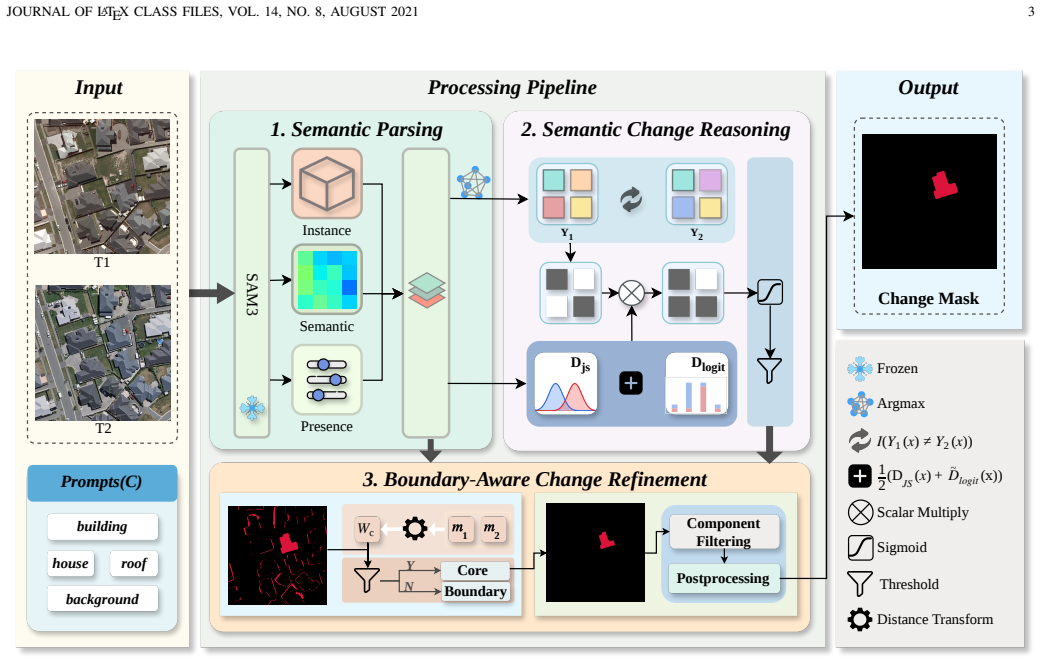
The paper claims that deriving candidate change regions from pixel-wise semantic discrepancies and then applying collaborative semantic and spatial refinement via the SCR and BCR modules produces reliable open-vocabulary change detection, yielding F1^C gains of 2.13% to 9.75% over state-of-the-art methods on LEVIR-CD, WHU-CD, DSIFN, and SECOND with improved efficiency.
What carries the argument
The collaborative refinement strategy that uses the Semantic Change Reasoning module to reassess changes via distributional divergence and response variation, together with the Boundary-aware Change Refinement module to validate candidate regions against reliable interior pixels.
If this is right
- Outperforms existing approaches by 2.13% to 9.75% in F1^C on four public remote sensing change detection datasets.
- Achieves the gains with lower computational cost than trained state-of-the-art models.
- Supports detection of changes described by arbitrary text prompts rather than fixed categories.
- Suppresses incidental semantic inconsistencies while preserving genuine shifts and reducing boundary artifacts.
Where Pith is reading between the lines
- The same candidate-plus-refinement pattern could be tested on video sequences to track evolving changes over time.
- Integration with newer vision-language backbones might further reduce reliance on the initial pixel discrepancy step.
- The modules could be applied as post-processing to other open-vocabulary segmentation tasks facing similar ambiguity issues.
Load-bearing premise
Pixel-wise semantic discrepancies reliably generate candidate regions that the refinement modules can clean without systematically discarding true changes or retaining false positives.
What would settle it
Running the method on a dataset dominated by partial changes or heavy boundary ambiguity and checking whether its F1^C score falls below that of direct pixel comparison baselines.
Figures


read the original abstract
Unlike traditional remote sensing change detection that relies on predefined categories, Open-Vocabulary Change Detection (OVCD) identifies land cover changes flexibly using arbitrary text prompts. However, existing methods suffer from an inherent trade-off when modeling changes: instance-level comparison overlooks fine-grained semantic variations (e.g., partial building extensions), while direct pixel comparison proves unreliable, yielding unstable responses and boundary artifacts due to semantic ambiguity and spatial inconsistency. To this end, we propose an efficient training-free Reliability-Aware Open-Vocabulary Change Detection (ReA-OVCD) framework. It first derives candidate change regions from pixel-wise semantic discrepancies to ensure flexible and detailed localization. To ensure reliability, it subsequently introduces a collaborative refinement strategy to explicitly model change validity from both semantic and spatial perspectives. Specifically, we develop a Semantic Change Reasoning (SCR) module that reassesses changes by jointly analyzing distributional divergence and response variation, enabling the suppression of incidental inconsistencies while preserving reliable semantic shifts. In addition, a Boundary-aware Change Refinement (BCR) module is designed to mitigate artifacts stemming from boundary misalignment and uncertainty through validating whether candidate regions are supported by reliable interior pixels. Extensive experiments across multiple datasets (LEVIR-CD, WHU-CD, DSIFN, and SECOND) demonstrate that our method consistently outperforms state-of-the-art approaches, achieving $\mathrm{F}_{1}^{C}$ improvements of 2.13\% to 9.75\% with higher computational efficiency. The code is publicly available at \https://github.com/Funny0101/ReA-OVCD
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReA-OVCD, a training-free framework for open-vocabulary change detection in remote sensing imagery. Candidate change regions are first identified via pixel-wise semantic discrepancies; these are then refined by a Semantic Change Reasoning (SCR) module (using distributional divergence and response variation) and a Boundary-aware Change Refinement (BCR) module (validating interior-pixel support) to suppress artifacts while preserving genuine changes. Experiments on LEVIR-CD, WHU-CD, DSIFN and SECOND report consistent F₁^C gains of 2.13–9.75 % over prior SOTA methods together with improved computational efficiency; code is released publicly.
Significance. If the refinement modules can be shown to deliver net-positive error reduction, the work would supply a practical, training-free route to flexible OVCD that mitigates the instance-level vs. pixel-level trade-off. Public code release supports reproducibility and is a clear strength.
major comments (2)
- [Methods (SCR/BCR)] Methods section describing SCR and BCR: the headline F₁^C gains are credible only if the collaborative refinement demonstrably reduces net errors on the candidate set. No ablation tables, stage-wise precision/recall breakdowns, or error-rate analysis on the initial candidate regions are supplied, leaving open the possibility that the modules trade true positives for fewer false positives or merely re-label boundary artifacts.
- [Experiments] Experiments section: overall dataset-level F₁^C numbers are reported, yet the absence of per-module contribution metrics or controlled removal of SCR/BCR prevents attribution of the observed gains specifically to the proposed reliability mechanisms.
minor comments (2)
- [Abstract] The symbol F₁^C is used without an explicit definition or reference to the precise formulation of the change-detection F1 metric.
- [Figures] Figure captions and axis labels in the experimental results could be expanded to clarify which curves correspond to which ablation or baseline variant.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validation of the SCR and BCR modules. We agree that additional analyses are required to demonstrate net error reduction and per-module contributions. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Methods (SCR/BCR)] Methods section describing SCR and BCR: the headline F₁^C gains are credible only if the collaborative refinement demonstrably reduces net errors on the candidate set. No ablation tables, stage-wise precision/recall breakdowns, or error-rate analysis on the initial candidate regions are supplied, leaving open the possibility that the modules trade true positives for fewer false positives or merely re-label boundary artifacts.
Authors: We agree that the current manuscript lacks these detailed analyses on the candidate regions. In the revision we will add ablation tables with stage-wise precision, recall and F₁ scores computed on the initial candidate set before and after SCR/BCR. We will also include error-rate breakdowns quantifying net false-positive reduction versus any true-positive loss, using the same four datasets. These additions will directly address the concern that gains may arise from trading true positives or merely re-labeling artifacts. revision: yes
-
Referee: [Experiments] Experiments section: overall dataset-level F₁^C numbers are reported, yet the absence of per-module contribution metrics or controlled removal of SCR/BCR prevents attribution of the observed gains specifically to the proposed reliability mechanisms.
Authors: We acknowledge the absence of per-module metrics and controlled ablations in the experiments section. The revised manuscript will include new experiments that systematically remove SCR, BCR, and both modules, reporting the resulting F₁^C, precision and recall on each dataset. These controlled removals, together with per-module contribution tables, will allow explicit attribution of the reported gains to the reliability-aware components. revision: yes
Circularity Check
No circularity: training-free pipeline with empirical validation on external benchmarks
full rationale
The paper describes a training-free OVCD method that generates candidate regions from pixel-wise semantic discrepancies and refines them via SCR (distributional divergence + response variation) and BCR (interior-pixel support) modules. No equations, fitted parameters, or self-citations appear in the provided text. Performance claims rest on experiments across independent datasets (LEVIR-CD, WHU-CD, DSIFN, SECOND) rather than any reduction of outputs to inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Change detection methods for remote sensing in the last decade: A comprehensive review,
G. Cheng, Y . Huang, X. Li, S. Lyu, Z. Xu, H. Zhao, Q. Zhao, and S. Xiang, “Change detection methods for remote sensing in the last decade: A comprehensive review,”Remote Sensing, vol. 16, no. 13, 2024
2024
-
[2]
Global land change from 1982 to 2016,
X.-P. Song, M. C. Hansen, S. V . Stehman, P. V . Potapov, A. Tyukavina, E. F. Vermote, and J. R. Townshend, “Global land change from 1982 to 2016,”Nature, vol. 560, no. 7720, pp. 639–643, 2018
1982
-
[3]
Building damage assessment for rapid disaster response with a deep object-based semantic change detection framework: From natural disasters to man- made disasters,
Z. Zheng, Y . Zhong, J. Wang, A. Ma, and L. Zhang, “Building damage assessment for rapid disaster response with a deep object-based semantic change detection framework: From natural disasters to man- made disasters,”Remote Sensing of Environment, vol. 265, p. 112636, 2021
2021
-
[4]
Land cover change detection with heterogeneous remote sensing images: Review, progress, and perspective,
Z. Lv, H. Huang, X. Li, M. Zhao, J. A. Benediktsson, W. Sun, and N. Falco, “Land cover change detection with heterogeneous remote sensing images: Review, progress, and perspective,”Proceedings of the IEEE, vol. 110, no. 12, pp. 1976–1991, 2022
1976
-
[5]
A transformer-based siamese net- work for change detection,
W. G. C. Bandara and V . M. Patel, “A transformer-based siamese net- work for change detection,” inIGARSS 2022 - 2022 IEEE International Geoscience and Remote Sensing Symposium, pp. 207–210, 2022
2022
-
[7]
Multitask learning for large-scale semantic change detection,
R. Caye Daudt, B. Le Saux, A. Boulch, and Y . Gousseau, “Multitask learning for large-scale semantic change detection,”Computer Vision and Image Understanding, vol. 187, p. 102783, 2019
2019
-
[8]
Joint spatio-temporal modeling for semantic change detection in remote sensing images,
L. Ding, J. Zhang, H. Guo, K. Zhang, B. Liu, and L. Bruzzone, “Joint spatio-temporal modeling for semantic change detection in remote sensing images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–14, 2024
2024
-
[9]
Remote sensing of impervious surfaces in the urban areas: Requirements, methods, and trends,
Q. Weng, “Remote sensing of impervious surfaces in the urban areas: Requirements, methods, and trends,”Remote Sensing of Environment, vol. 117, pp. 34–49, 2012. Remote Sensing of Urban Environments
2012
-
[10]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Dollar, and R. Girshick, “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 4015–4026, October 2023
2023
-
[11]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the 38th International Conference on Machine Learning(M. Meila and T. Zhang, eds.), vol. 139 ofProceedings of Machine Learnin...
2021
-
[12]
DINO: DETR with improved denoising anchor boxes for end-to-end object detection,
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. Ni, and H.-Y . Shum, “DINO: DETR with improved denoising anchor boxes for end-to-end object detection,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[13]
Dynamicearth: How far are we from open-vocabulary change detection?,
K. Li, X. Cao, Y . Deng, C. Pang, Z. Xin, H. Qiao, T. Gong, D. Meng, and Z. Wang, “Dynamicearth: How far are we from open-vocabulary change detection?,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, pp. 6279–6287, 2026
2026
-
[14]
OmniOVCD: Streamlining Open-Vocabulary Change Detection with SAM 3
X. Zhang, D. Li, Y . Xia, X. Dong, H. Yu, J. Wang, and Q. Li, “Omniovcd: Streamlining open-vocabulary change detection with sam 3,”arXiv preprint arXiv:2601.13895, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Univcd: A new method for unsupervised change detection in the open-vocabulary era,
Z. Zhu and B. Yang, “Univcd: A new method for unsupervised change detection in the open-vocabulary era,”arXiv preprint arXiv:2512.13089, 2025
-
[16]
Segment anything in high quality,
L. Ke, M. Ye, M. Danelljan, Y . liu, Y .-W. Tai, C.-K. Tang, and F. Yu, “Segment anything in high quality,” inAdvances in Neural Information Processing Systems(A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, eds.), vol. 36, pp. 29914–29934, Curran Associates, Inc., 2023
2023
-
[17]
arXiv preprint arXiv:2306.12156 (2023)
X. Zhao, W. Ding, Y . An, Y . Du, T. Yu, M. Li, M. Tang, and J. Wang, “Fast segment anything,”arXiv preprint arXiv:2306.12156, 2023
-
[18]
Faster Segment Anything: Towards Lightweight SAM for Mobile Applications
C. Zhang, D. Han, Y . Qiao, J. U. Kim, S.-H. Bae, S. Lee, and C. S. Hong, “Faster segment anything: Towards lightweight sam for mobile applications,”arXiv preprint arXiv:2306.14289, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Tinysam: Pushing the envelope for efficient segment anything model,
H. Shu, W. Li, Y . Tang, Y . Zhang, Y . Chen, H. Li, Y . Wang, and X. Chen, “Tinysam: Pushing the envelope for efficient segment anything model,” inProceedings of the AAAI conference on artificial intelligence, vol. 39, pp. 20470–20478, 2025
2025
-
[20]
Efficientsam: Leveraged masked image pretraining for efficient segment anything,
Y . Xiong, B. Varadarajan, L. Wu, X. Xiang, F. Xiao, C. Zhu, X. Dai, D. Wang, F. Sun, F. Iandola,et al., “Efficientsam: Leveraged masked image pretraining for efficient segment anything,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 16111–16121, 2024
2024
-
[21]
SAM 2: Segment Anything in Images and Videos
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson,et al., “Sam 2: Segment anything in images and videos,”arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang,et al., “Sam 3: Segment anything with concepts,”arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Fully convolutional siamese networks for change detection,
R. Caye Daudt, B. Le Saux, and A. Boulch, “Fully convolutional siamese networks for change detection,” in2018 25th IEEE International Conference on Image Processing (ICIP), pp. 4063–4067, 2018
2018
-
[24]
Snunet-cd: A densely connected siamese network for change detection of vhr images,
S. Fang, K. Li, J. Shao, and Z. Li, “Snunet-cd: A densely connected siamese network for change detection of vhr images,”IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2022
2022
-
[25]
Tinycd: a (not so) deep learning model for change detection,
A. Codegoni, G. Lombardi, and A. Ferrari, “Tinycd: a (not so) deep learning model for change detection,”Neural Computing and Applica- tions, vol. 35, no. 11, pp. 8471–8486, 2023
2023
-
[26]
Zeroscd: Zero-shot street scene change detection,
S. S. Kannan and B.-C. Min, “Zeroscd: Zero-shot street scene change detection,” in2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 4665–4671, 2025
2025
-
[27]
Change detection based on artificial intelligence: State-of-the-art and challenges,
W. Shi, M. Zhang, R. Zhang, S. Chen, and Z. Zhan, “Change detection based on artificial intelligence: State-of-the-art and challenges,”Remote Sensing, vol. 12, no. 10, 2020
2020
-
[28]
Changeclip: Remote sensing change detection with multimodal vision-language representation learn- ing,
S. Dong, L. Wang, B. Du, and X. Meng, “Changeclip: Remote sensing change detection with multimodal vision-language representation learn- ing,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 208, pp. 53–69, 2024
2024
-
[29]
Textscd: Leveraging text-based semantic guidance for remote sensing image semantic change detection,
H. Huang, Q. Cheng, D. Zhu, X. Huang, and Q. Zhao, “Textscd: Leveraging text-based semantic guidance for remote sensing image semantic change detection,”ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, pp. 383–389, 2025
2025
-
[30]
Change knowledge-guided vision-language remote sens- ing change detection,
J. Wang, F. Liu, L. Jiao, H. Wang, S. Li, L. Li, P. Chen, X. Liu, and W. Ma, “Change knowledge-guided vision-language remote sens- ing change detection,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–13, 2025
2025
-
[31]
Segment change model (scm) for unsupervised change detection in vhr remote sensing images: a case study of buildings,
X. Tan, G. Chen, T. Wang, J. Wang, and X. Zhang, “Segment change model (scm) for unsupervised change detection in vhr remote sensing images: a case study of buildings,” inIGARSS 2024-2024 IEEE Inter- national Geoscience and Remote Sensing Symposium, pp. 8577–8580, IEEE, 2024
2024
-
[32]
Segment any change,
Z. Zheng, Y . Zhong, L. Zhang, and S. Ermon, “Segment any change,” inAdvances in Neural Information Processing Systems(A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, eds.), vol. 37, pp. 81204–81224, Curran Associates, Inc., 2024
2024
-
[33]
Bisam-cd: Zero-shot remote sensing change detection via bidirectional temporal memory in sam2,
Y . Qin, J. Chen, C. Wang, and C. Pan, “Bisam-cd: Zero-shot remote sensing change detection via bidirectional temporal memory in sam2,” IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1– 12, 2025
2025
-
[34]
Change3d: Revisiting change detection and captioning from a video modeling perspective,
D. Zhu, X. Huang, H. Huang, H. Zhou, and Z. Shao, “Change3d: Revisiting change detection and captioning from a video modeling perspective,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 24011–24022, June 2025
2025
-
[35]
Unichange: Unifying change detection with multimodal large language model,
X. Zhang, D. Li, X. Dong, T. Wu, H. Yu, J. Wang, Q. Li, and X. Li, “Unichange: Unifying change detection with multimodal large language model,”arXiv preprint arXiv:2511.02607, 2025
-
[36]
Semantic-cd: Re- mote sensing image semantic change detection towards open-vocabulary setting,
Y . Zhu, L. Li, K. Chen, C. Liu, F. Zhou, and Z. Shi, “Semantic-cd: Re- mote sensing image semantic change detection towards open-vocabulary setting,” inIGARSS 2025 - 2025 IEEE International Geoscience and Remote Sensing Symposium, pp. 6388–6392, 2025
2025
-
[37]
Vilacd-r1: A vision-language framework for semantic change detection in remote sensing,
X. Ma, S. Feng, B. Zhang, and B. Wang, “Vilacd-r1: A vision-language framework for semantic change detection in remote sensing,”arXiv preprint arXiv:2512.23244, 2025
-
[38]
Ov-cd:open vocabulary change detection for vhr remote sensing images,
Y . Zhuang, C. Huo, H. Yu, and D. Wu, “Ov-cd:open vocabulary change detection for vhr remote sensing images,” inIGARSS 2025 - 2025 IEEE International Geoscience and Remote Sensing Symposium, pp. 8147– 8151, 2025
2025
-
[39]
M. Dou, S. Qiu, M. Hu, Y . Chen, H. Ye, X. Liao, and Z. Sun, “Adap- tovcd: Training-free open-vocabulary remote sensing change detection via adaptive information fusion,”arXiv preprint arXiv:2602.06529, 2026
-
[40]
Q. Guo, J. Wang, Y . Liu, and Y . Zhong, “Opendpr: Open-vocabulary change detection via vision-centric diffusion-guided prototype retrieval for remote sensing imagery,”arXiv preprint arXiv:2603.27645, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
SegEarth-OV3: Exploring SAM 3 for Open-Vocabulary Semantic Segmentation in Remote Sensing Images
K. Li, S. Zhang, Y . Deng, Z. Wang, D. Meng, and X. Cao, “Segearth- ov3: Exploring sam 3 for open-vocabulary semantic segmentation in remote sensing images,”arXiv preprint arXiv:2512.08730, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Side adapter network for open-vocabulary semantic segmentation,
M. Xu, Z. Zhang, F. Wei, H. Hu, and X. Bai, “Side adapter network for open-vocabulary semantic segmentation,” inProceedings of the JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2945–2954, June 2023
2021
-
[43]
A spatial-temporal attention-based method and a new dataset for remote sensing image change detection,
H. Chen and Z. Shi, “A spatial-temporal attention-based method and a new dataset for remote sensing image change detection,”Remote Sensing, vol. 12, no. 10, 2020
2020
-
[44]
Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set,
S. Ji, S. Wei, and M. Lu, “Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 1, pp. 574–586, 2019
2019
-
[45]
A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images,
C. Zhang, P. Yue, D. Tapete, L. Jiang, B. Shangguan, L. Huang, and G. Liu, “A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 166, pp. 183–200, 2020
2020
-
[46]
Asymmetric siamese networks for semantic change detection in aerial images,
K. Yang, G.-S. Xia, Z. Liu, B. Du, W. Yang, M. Pelillo, and L. Zhang, “Asymmetric siamese networks for semantic change detection in aerial images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–18, 2022
2022
-
[47]
Aligning and prompting everything all at once for universal visual perception,
Y . Shen, C. Fu, P. Chen, M. Zhang, K. Li, X. Sun, Y . Wu, S. Lin, and R. Ji, “Aligning and prompting everything all at once for universal visual perception,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 13193–13203, June 2024
2024
-
[48]
DINOv2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. HAZIZA, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “DINOv2: Learning robust visual features withou...
2024
-
[49]
Segearth-ov: Towards training-free open-vocabulary segmentation for remote sensing images,
K. Li, R. Liu, X. Cao, X. Bai, F. Zhou, D. Meng, and Z. Wang, “Segearth-ov: Towards training-free open-vocabulary segmentation for remote sensing images,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10545–10556, June 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.