Lagrange: An Open-Vocabulary, Energy-Based Sparse Framework for Generalized End-to-End Driving
Pith reviewed 2026-06-26 17:09 UTC · model grok-4.3
The pith
Framing driving as Lagrangian minimization over an implicit energy field from vision-language tokens produces kinematically valid trajectories without dense reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
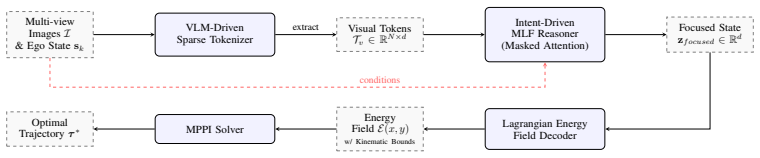
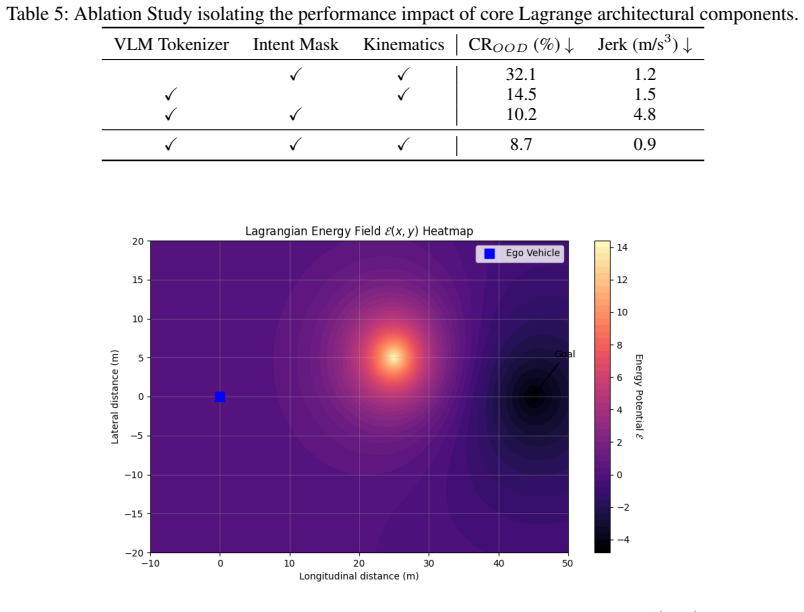
Lagrange decodes attended vision-language tokens into an implicit continuous energy field and casts trajectory generation as minimization of a Lagrangian action defined over that field; the authors state that this procedure directly yields trajectories that are both collision-free and kinematically feasible in open-world settings.
What carries the argument
Masked Latent Fields (MLF) that turn temporally filtered vision-language tokens into an implicit continuous energy field over spatial coordinates, with Lagrangian action minimization performed on the field.
If this is right
- Kinematic feasibility and collision avoidance are obtained directly from the minimization step without separate post-processing modules.
- Open-vocabulary reasoning from vision-language models extends to continuous control rather than discrete token sequences.
- Sparse token-based representations replace dense volumetric occupancy maps while retaining generalization to anomalous scenarios.
- The same energy-field construction supports both standard benchmarks and long-tail distributions such as CODA.
Where Pith is reading between the lines
- If the energy field is made differentiable, the minimization step could be folded into gradient-based end-to-end training loops.
- The masked-attention filtering mechanism might be reused in multi-agent coordination settings where only a subset of detected entities matter for the ego-vehicle.
- Visualizing the learned energy field could provide an interpretable diagnostic for why a particular trajectory was selected.
Load-bearing premise
Vision-language model encodings of class-agnostic proposals can be decoded into an implicit continuous energy field whose minimization directly produces trajectories that are collision-free and kinematically feasible without post-processing or dense geometry.
What would settle it
A trajectory produced by the energy-field minimization that violates non-holonomic kinematic constraints or intersects an object on either the nuScenes or CODA test sets would falsify the central claim.
Figures
read the original abstract
Scaling end-to-end autonomous driving to complex, open-world environments requires perceptual models that generalize to anomalous scenarios and planners that produce kinematically valid trajectories. Existing paradigms face a distinct dichotomy between representational efficiency and generalization capacity. Dense models (e.g., occupancy networks), while geometrically robust, incur critical computational bottlenecks and struggle with high-level semantic reasoning. Conversely, sparse, query-based planners are efficient but reliant on closed-set definitions, rendering them vulnerable to out-of-distribution (OOD) events. Although recent Vision-Language-Action (VLA) models offer open-vocabulary reasoning, their autoregressive, discrete token generation fundamentally conflicts with the continuous, high-frequency control requirements of vehicle dynamics. To address this, we propose Lagrange, an open-vocabulary, computationally sparse driving framework based on Masked Latent Fields (MLF). Rather than relying on dense volumetric reconstructions or closed-set query mechanisms, Lagrange exploits Vision-Language Models (VLMs) to encode class-agnostic object proposals into continuous semantic visual tokens. We introduce an intent-driven masked cross-attention module that temporally filters irrelevant entities, decoding the attended tokens into an implicit continuous energy field defined over spatial coordinates. By framing decision-making as a Lagrangian action minimization problem spanning this energy field, we enforce strict compliance with vehicle kinematics while executing collision avoidance. Extensive offline evaluations on both standard (nuScenes) and long-tail (CODA) benchmarks demonstrate that Lagrange establishes a promising framework for robust, interpretable, and kinematically feasible open-world autonomy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Lagrange, an open-vocabulary sparse framework for end-to-end autonomous driving. It encodes class-agnostic object proposals from Vision-Language Models into semantic visual tokens, applies an intent-driven masked cross-attention module for temporal filtering, and decodes the result into an implicit continuous energy field over spatial coordinates. Planning is cast as Lagrangian action minimization over this field to produce trajectories that are claimed to satisfy vehicle kinematics exactly while avoiding collisions. The approach is positioned as addressing the efficiency-generalization trade-off in existing dense occupancy and closed-set query-based methods, with offline evaluations reported on nuScenes and CODA.
Significance. If the technical components function as described, the work could provide a conceptually interesting bridge between VLM-based open-vocabulary reasoning and continuous, kinematically constrained planning without dense reconstruction or autoregressive token generation. The energy-based Lagrangian formulation offers a potential route to interpretable, post-processing-free feasibility. However, the complete absence of equations, field parameterization, optimization details, or any quantitative results makes it impossible to determine whether the claimed advantages are realized or whether the approach improves upon existing energy-based or query-based planners.
major comments (2)
- [Abstract] Abstract: The central claim that 'framing decision-making as a Lagrangian action minimization problem spanning this energy field, we enforce strict compliance with vehicle kinematics while executing collision avoidance' is unsupported by any derivation, definition of the energy field E(x), action integral, or optimization procedure. No equations show how VLM tokens are decoded into a continuous field whose gradients guarantee non-holonomic feasibility or exact collision costs, leaving the skeptic's concern about discretization artifacts and semantic inaccuracies unaddressed.
- [Abstract] Abstract: Despite the statement of 'extensive offline evaluations on both standard (nuScenes) and long-tail (CODA) benchmarks' that 'demonstrate that Lagrange establishes a promising framework', the manuscript contains no metrics, baselines, ablations, error bars, or tables. This absence is load-bearing because the paper's value rests on showing that the implicit field produces superior or at least competitive kinematically valid trajectories in OOD settings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the current manuscript draft requires substantial expansion to include the missing mathematical derivations, field definitions, optimization details, and quantitative experimental results. We will revise the paper to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'framing decision-making as a Lagrangian action minimization problem spanning this energy field, we enforce strict compliance with vehicle kinematics while executing collision avoidance' is unsupported by any derivation, definition of the energy field E(x), action integral, or optimization procedure. No equations show how VLM tokens are decoded into a continuous field whose gradients guarantee non-holonomic feasibility or exact collision costs, leaving the skeptic's concern about discretization artifacts and semantic inaccuracies unaddressed.
Authors: We acknowledge that the abstract summarizes the core idea at a high level without the supporting technical details. In the revised manuscript we will add a dedicated methods section containing: (1) the explicit parameterization of the implicit continuous energy field E(x) decoded from the attended VLM tokens, (2) the definition of the Lagrangian action integral, (3) the optimization procedure used to minimize it, and (4) the derivations showing how the resulting gradients enforce exact non-holonomic kinematic constraints and collision costs. These additions will also address potential discretization and semantic accuracy concerns. revision: yes
-
Referee: [Abstract] Abstract: Despite the statement of 'extensive offline evaluations on both standard (nuScenes) and long-tail (CODA) benchmarks' that 'demonstrate that Lagrange establishes a promising framework', the manuscript contains no metrics, baselines, ablations, error bars, or tables. This absence is load-bearing because the paper's value rests on showing that the implicit field produces superior or at least competitive kinematically valid trajectories in OOD settings.
Authors: The referee correctly notes the absence of any quantitative results in the current draft. We will incorporate a full experimental section reporting metrics, baseline comparisons, ablations, error bars, and tables for the offline evaluations on both nuScenes and CODA, thereby providing the necessary evidence for the claimed advantages in kinematically valid open-world planning. revision: yes
Circularity Check
No derivations or equations available for circularity analysis
full rationale
The abstract and provided text describe a high-level framework using VLMs, masked cross-attention, and Lagrangian minimization but contain no equations, parameter fittings, self-citations, or derivation steps. Without explicit mathematical content or load-bearing claims that reduce to inputs by construction, no circularity can be identified or quoted. The derivation chain is not inspectable from the given material, so the default non-finding applies.
Axiom & Free-Parameter Ledger
invented entities (3)
-
Masked Latent Fields (MLF)
no independent evidence
-
intent-driven masked cross-attention module
no independent evidence
-
implicit continuous energy field
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hu et al
Y . Hu et al. Planning-oriented autonomous driving. InCVPR, 2023
2023
-
[2]
Lin et al
X. Lin et al. SparseDrive: End-to-end autonomous driving via sparse macroscopic representa- tions. InarXiv preprint, 2024
2024
-
[3]
Ahn et al
M. Ahn et al. OpenVLA: An open-source vision-language-action model. InarXiv preprint, 2024
2024
-
[4]
Li et al
K. Li et al. CODA: A real-world road corner case dataset for object detection in autonomous driving. InECCV, 2022
2022
-
[5]
Williams et al
G. Williams et al. Information theoretic MPC for model-based reinforcement learning. InICRA, 2017
2017
-
[6]
Radford et al
A. Radford et al. Learning Transferable Visual Models From Natural Language Supervision. In ICML, 2021
2021
-
[7]
Li et al
J. Li et al. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. InICML, 2022
2022
-
[8]
Liu et al
Y . Liu et al. PETR: Position Embedding Transformation for Multi-View 3D Object Detection. InECCV, 2022
2022
-
[9]
Jiang et al
B. Jiang et al. V AD: Vectorized Autonomous Driving via Object-centric Scene Representation. InICCV, 2023
2023
-
[10]
Tian et al
X. Tian et al. DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models. InCVPR, 2024
2024
-
[11]
Sun et al
W. Sun et al. LLaMA-Drive: An empirical study on large language models for autonomous driving. InarXiv preprint, 2023. 8
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.