Train, Retrieve, or Both? A Four-Arm Head-to-Head for Correct Statutory Citation on the Ontario Residential Tenancies Act
Pith reviewed 2026-06-26 17:34 UTC · model grok-4.3
The pith
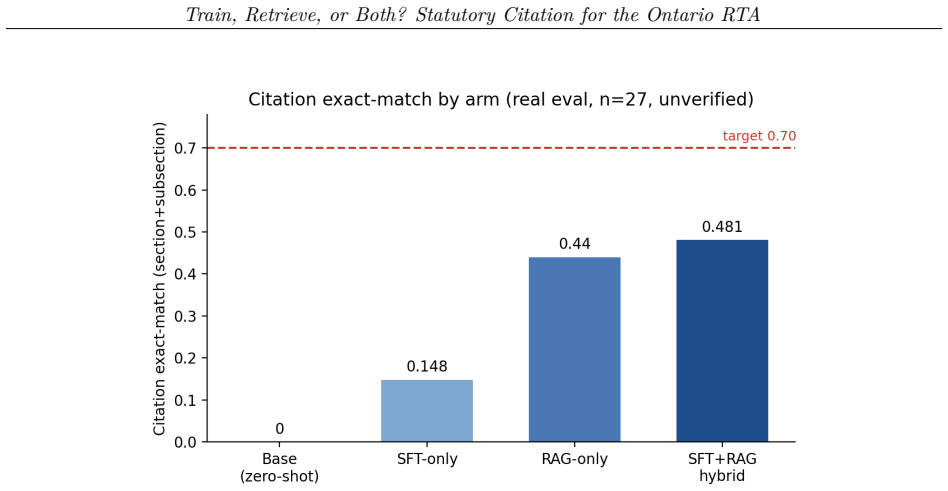
A hybrid of supervised fine-tuning and retrieval on a 7B model reaches 0.481 exact-match citation accuracy on the Ontario Residential Tenancies Act with no hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
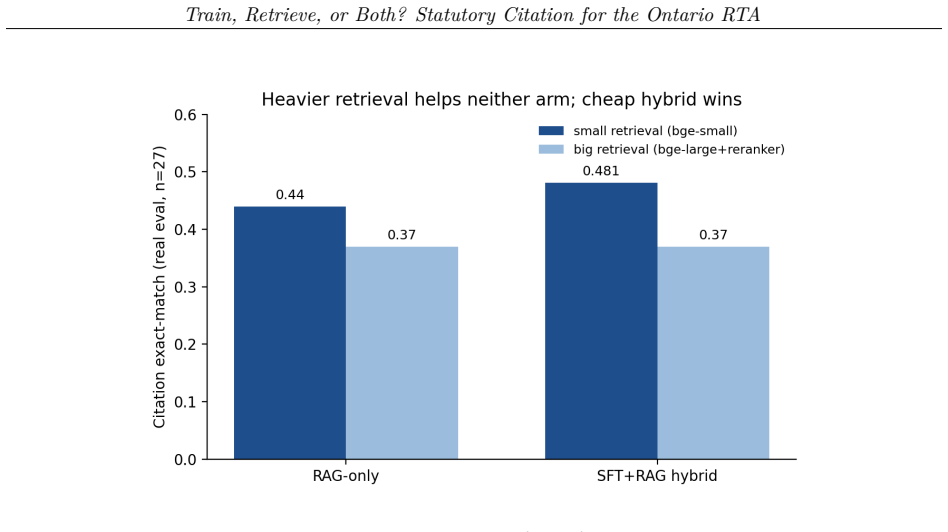
Through direct comparison of base zero-shot, LoRA SFT-only, RAG-only, and SFT+RAG hybrid arms on a small real-world evaluation set, the authors show that the hybrid configuration scores highest at 0.481 exact-match citation accuracy while producing zero hallucinated citations. The advantage arises because supervised fine-tuning improves the model's ability to select the right provision from the higher-recall candidate lists supplied by retrieval. The same hybrid built on a cheap bge-small embedder matches or exceeds pipelines that use larger embedders and cross-encoder rerankers, and expanding the training set yields no further gain.
What carries the argument
The four-arm head-to-head experiment comparing base zero-shot, LoRA SFT-only, RAG-only, and SFT+RAG hybrid configurations scored on section-plus-subsection exact-match citation accuracy.
If this is right
- Retrieval is required to eliminate hallucinated citations by construction.
- Supervised fine-tuning improves robustness when the retrieval stage returns higher-recall candidate sets.
- A hybrid built on a cheap bge-small embedder matches or beats pipelines that use larger specialized retrieval models.
- Increasing the size or quality of the training set does not raise statutory-citation performance.
- The hybrid clears the lift-over-base threshold but remains below the 0.70 exact-match target.
Where Pith is reading between the lines
- Similar hybrid methods may suffice for citation tasks on other statutes or in other jurisdictions without requiring frontier-scale models.
- Full human verification of the current evaluation set could shift the reported 0.481 score upward or downward.
- Legal-assistance systems may achieve reliable citation performance by pairing modest adaptation with retrieval rather than by scaling model size alone.
- The finding that extra training data adds no value suggests the bottleneck lies in retrieval coverage or model selection rather than data volume.
Load-bearing premise
The small human-verification-pending evaluation set accurately represents real-world performance and the preliminary results will hold upon full verification and larger testing.
What would settle it
A larger fully human-verified evaluation set in which the SFT+RAG hybrid no longer leads the other three arms in exact-match accuracy, or in which a specialized retrieval pipeline outperforms the cheap hybrid, would falsify the reported superiority.
Figures
read the original abstract
Self-represented tenants, landlords, and help-desk staff need to be pointed at the provision of law that actually governs a question, with a correct statutory citation. We study this task on the Ontario Residential Tenancies Act, 2006 (RTA) and its core regulation, asking the operator's question empirically: is fine-tuning enough, or is hybrid retrieval needed? We run a four-arm head-to-head on Qwen2.5-7B-Instruct (base zero-shot, LoRA SFT-only, RAG-only, and an SFT+RAG hybrid), scored on citation exact-match (section+subsection) over a small, human-verification-pending real eval set. The base model cannot cite the RTA and SFT-only mis-recalls sections; retrieval is essential and drives hallucination to zero by construction; and the SFT+RAG hybrid scores highest at 0.481 exact-match with zero hallucinated citations. Its edge comes from SFT making provision selection more robust to the higher-recall candidate sets that hurt zero-shot RAG. Notably, this cheap bge-small hybrid matches or beats a pipeline built on bigger, specialized retrieval models (a larger embedder and a cross-encoder reranker), and a larger/improved training set does not help either: strong statutory-citation performance here does not require specialized retrieval models or more data. The artifact zeroes hallucination and clears the lift-over-base bar but does not reach the aspirational 0.70 exact-match target. All results are on a small, human-verification-pending real eval set and are reported as preliminary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically evaluates four configurations of Qwen2.5-7B-Instruct (zero-shot base, LoRA SFT-only, RAG-only, and SFT+RAG hybrid) for exact statutory citation to provisions of the Ontario Residential Tenancies Act on a small real-world question set. It reports that retrieval is required to eliminate hallucinations, that the SFT+RAG hybrid reaches the highest exact-match accuracy of 0.481 with zero hallucinations, that this hybrid is robust to high-recall candidate sets, and that the result is achieved with a cheap bge-small embedder without benefit from larger specialized retrievers or additional training data. All metrics are presented as preliminary.
Significance. If the reported margins survive human verification of the evaluation labels, the work provides evidence that lightweight SFT+RAG hybrids can deliver hallucination-free citation performance competitive with heavier retrieval pipelines on a narrow statutory domain. This would be useful for practical legal-help tools, though the absolute score remains well below the 0.70 target mentioned in the abstract.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): All central performance claims, including the 0.481 exact-match score, the zero-hallucination result, the superiority of the SFT+RAG hybrid over zero-shot RAG, and the conclusion that cheap bge-small suffices, rest exclusively on a small evaluation set whose ground-truth citations remain pending full human verification. No inter-annotator agreement, error analysis, or sensitivity check to label changes is reported, so even modest shifts in the reference citations could alter the reported margins and the robustness interpretation.
- [Abstract and Results] Abstract and Results: The statements that 'a larger/improved training set does not help' and that the hybrid 'matches or beats' pipelines using bigger embedders and cross-encoders are likewise computed on the same unverified set; without completed verification, statistical tests, or error bars, these comparative conclusions lack the evidential support needed to ground the design recommendations.
minor comments (1)
- [Abstract] Abstract: The exact size of the 'small' evaluation set is not stated, which would allow readers to gauge the precision of the reported percentages.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for emphasizing the need for verified ground-truth labels. We agree that the pending verification limits the strength of the current claims and will complete it as part of the revision. Point-by-point responses to the major comments are below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): All central performance claims, including the 0.481 exact-match score, the zero-hallucination result, the superiority of the SFT+RAG hybrid over zero-shot RAG, and the conclusion that cheap bge-small suffices, rest exclusively on a small evaluation set whose ground-truth citations remain pending full human verification. No inter-annotator agreement, error analysis, or sensitivity check to label changes is reported, so even modest shifts in the reference citations could alter the reported margins and the robustness interpretation.
Authors: We agree that the evaluation set requires completed human verification before the reported margins can be treated as definitive. The manuscript already flags all results as preliminary for this reason. In revision we will finish the verification, report inter-annotator agreement, add an error analysis, and include a sensitivity check on how plausible label changes affect the metrics and comparative conclusions. revision: yes
-
Referee: [Abstract and Results] Abstract and Results: The statements that 'a larger/improved training set does not help' and that the hybrid 'matches or beats' pipelines using bigger embedders and cross-encoders are likewise computed on the same unverified set; without completed verification, statistical tests, or error bars, these comparative conclusions lack the evidential support needed to ground the design recommendations.
Authors: We concur that the comparative statements on training-set size and retriever scale rest on the same pending labels and therefore need stronger evidential grounding. The revision will complete verification and, where sample size permits, add appropriate statistical support or error bars for the key comparisons while retaining the preliminary framing already present in the text. revision: yes
Circularity Check
No circularity: purely empirical four-arm comparison on fixed eval set
full rationale
The paper reports direct accuracy measurements (exact-match citation scores) across four model configurations on a held-out real eval set. No equations, fitted parameters, or predictions are derived from the reported results themselves. Retrieval driving hallucination to zero is a design property of RAG, not a self-referential claim. No self-citations appear in the load-bearing claims. The analysis is self-contained against external benchmarks (the eval set labels), with results presented as preliminary due to pending verification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cite Pretrain: Retrieval-free knowledge attribution for large language models
Yukun Huang, Sanxing Chen, Jian Pei, Manzil Zaheer, and Bhuwan Dhingra. Cite Pretrain: Retrieval-free knowledge attribution for large language models. 2025. URLhttps://arxiv. org/abs/2506.17585
Pith/arXiv arXiv 2025
-
[2]
Pouya Pezeshkpour and Estevam Hruschka. Learning Beyond the Surface: How far can continual pre-training with LoRA enhance LLMs’ domain-specific insight learning? 2025. URL https://arxiv.org/abs/2501.17840
arXiv 2025
-
[3]
Ran Xu, Hui Liu, Sreyashi Nag, Zhenwei Dai, Yaochen Xie, Xianfeng Tang, Chen Luo, Yang Li, Joyce C. Ho, Carl Yang, and Qi He. SimRAG: Self-improving retrieval-augmented generation for adapting large language models to specialized domains. 2024. URLhttps: //arxiv.org/abs/2410.17952
arXiv 2024
-
[4]
Suppressing Domain-Specific Hallucination in Construction LLMs: A knowledge graph foundation for GraphRAG and QLoRA on river and sediment control technical standards
Takato Yasuno. Suppressing Domain-Specific Hallucination in Construction LLMs: A knowledge graph foundation for GraphRAG and QLoRA on river and sediment control technical standards
-
[5]
URLhttps://arxiv.org/abs/2603.13307
-
[6]
TRACE: TRansformer- based attribution using contrastive embeddings in LLMs
Cheng Wang, Xinyang Lu, See-Kiong Ng, and Bryan Kian Hsiang Low. TRACE: TRansformer- based attribution using contrastive embeddings in LLMs. 2024. URLhttps://arxiv.org/ abs/2407.04981
arXiv 2024
-
[7]
Judgement Citation Retrieval using Contextual Similarity
Akshat Mohan Dasula, Hrushitha Tigulla, and Preethika Bhukya. Judgement Citation Retrieval using Contextual Similarity. 2024. URLhttps://arxiv.org/abs/2406.01609
arXiv 2024
-
[8]
IL-PCSR: Legal corpus for prior case and statute retrieval
Shounak Paul, Dhananjay Ghumare, Pawan Goyal, Saptarshi Ghosh, and Ashutosh Modi. IL-PCSR: Legal corpus for prior case and statute retrieval. 2025. URLhttps://arxiv.org/ abs/2511.00268
arXiv 2025
-
[9]
Jahidul Arafat. Citation-Grounded Code Comprehension: Preventing LLM hallucination through hybrid retrieval and graph-augmented context. 2025. URLhttps://arxiv.org/abs/ 2512.12117
arXiv 2025
-
[10]
Segment First, Retrieve Better: Realistic legal search via rhetorical role-based queries
Shubham Kumar Nigam, Tanmay Dubey, Noel Shallum, and Arnab Bhattacharya. Segment First, Retrieve Better: Realistic legal search via rhetorical role-based queries. 2025. URL https://arxiv.org/abs/2508.00679
arXiv 2025
-
[11]
LegalRAG: A hybrid RAG system for multilingual legal information retrieval
Muhammad Rafsan Kabir, Rafeed Mohammad Sultan, Fuad Rahman, Mohammad Ruhul Amin, Sifat Momen, Nabeel Mohammed, and Shafin Rahman. LegalRAG: A hybrid RAG system for multilingual legal information retrieval. 2025. URLhttps://arxiv.org/abs/2504.16121
arXiv 2025
-
[12]
LawPal: A retrieval augmented generation based system for enhanced legal accessibility in india
Dnyanesh Panchal, Aaryan Gole, Vaibhav Narute, and Raunak Joshi. LawPal: A retrieval augmented generation based system for enhanced legal accessibility in india. 2025. URL https://arxiv.org/abs/2502.16573
arXiv 2025
-
[13]
Anuraj Maurya. Scaling Legal AI: Benchmarking mamba and transformers for statutory classification and case law retrieval. 2025. URLhttps://arxiv.org/abs/2509.00141. 9 Train, Retrieve, or Both? Statutory Citation for the Ontario RTA
arXiv 2025
-
[14]
Le, Lesly Miculicich, Nanyun Peng, Chen-Yu Lee, and Tomas Pfister
I-Hung Hsu, Zifeng Wang, Long T. Le, Lesly Miculicich, Nanyun Peng, Chen-Yu Lee, and Tomas Pfister. CaLM: Contrasting large and small language models to verify grounded generation
-
[15]
URLhttps://arxiv.org/abs/2406.05365
-
[16]
Hallu- Graph: Auditable hallucination detection for legal RAG systems via knowledge graph alignment
Valentin Noël, Elimane Yassine Seidou, Charly Ken Capo-Chichi, and Ghanem Amari. Hallu- Graph: Auditable hallucination detection for legal RAG systems via knowledge graph alignment
-
[17]
URLhttps://arxiv.org/abs/2512.01659
-
[18]
Piotr Komorowski, Elena Golimblevskaia, Reduan Achtibat, Thomas Wiegand, Sebastian Lapuschkin, and Wojciech Samek. Attribution-Guided Decoding. 2025. URLhttps://arxiv. org/abs/2509.26307
arXiv 2025
-
[19]
NyayaRAG: Realistic legal judgment prediction with RAG under the indian common law system
Shubham Kumar Nigam, Balaramamahanthi Deepak Patnaik, Shivam Mishra, Ajay Varghese Thomas, Noel Shallum, Kripabandhu Ghosh, and Arnab Bhattacharya. NyayaRAG: Realistic legal judgment prediction with RAG under the indian common law system. 2025. URL https://arxiv.org/abs/2508.00709
arXiv 2025
-
[20]
How Much is Too Much? exploring LoRA rank trade-offs for retaining knowledge and domain robustness
Darshita Rathore, Vineet Kumar, Chetna Bansal, and Anindya Moitra. How Much is Too Much? exploring LoRA rank trade-offs for retaining knowledge and domain robustness. 2025. URLhttps://arxiv.org/abs/2512.15634. 10
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.