The Significance of Style Diversity in Annotation-Free Synthetic Data Generation
Pith reviewed 2026-06-26 18:12 UTC · model grok-4.3
The pith
Synthetic data from intent definitions alone reaches 93.3 percent of human-annotated performance when style diversity is prioritized.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
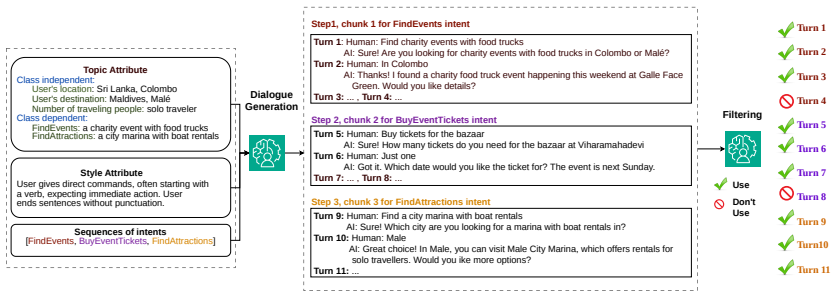
A framework that generates synthetic dialogues solely from intent definitions, using style and topic attributes during generation plus LLM-as-a-judge filtering, achieves up to 93.3 percent of the accuracy of models trained on human-annotated data; style diversity proves more important than topic diversity for preventing spurious correlations, and embedding style attributes at generation time outperforms post-hoc stylization.
What carries the argument
Style attributes incorporated at generation time together with the Univ and Exam post-hoc stylization models that increase linguistic variety in the synthetic utterances.
If this is right
- Intent classifiers can be trained to near-human performance using only intent definitions and no seed annotations.
- Style variation during data creation reduces the risk that models learn superficial cues instead of intent semantics.
- Embedding style controls inside the initial generation step is more effective than applying stylization afterward.
- The same annotation-free pipeline applies to both public benchmarks and industrial dialogue datasets.
Where Pith is reading between the lines
- The style-over-topic finding may extend to other classification tasks where models risk learning surface patterns rather than meaning.
- Industrial teams could bootstrap new intent sets by first listing definitions and then running the described generation loop.
- Combining style attributes at both generation and post-hoc stages might produce additional gains not tested in the paper.
Load-bearing premise
An LLM used as a judge can reliably remove low-quality or biased synthetic examples without introducing new stylistic artifacts that degrade the downstream classifier.
What would settle it
Measure classifier accuracy on a held-out test set after retraining on the same synthetic pool but with the LLM-judge filter disabled or replaced by a random filter; a drop below 93 percent of human performance would falsify the quality-enhancement claim.
Figures

read the original abstract
Generating high-utility synthetic data for intent classification typically requires human-annotated seed data, which is often unavailable in fast-paced industrial settings. In this paper, we propose a framework for synthetic dialogue generation that works entirely without human-annotated data, relying solely on intent definitions. Our proposed dialogue generation framework utilizes two different types of topic and style attributes to improve data diversity. Also, we propose two novel post-hoc stylization models called Univ and Exam to transform synthetic LLM-generated utterances into more varied, human-like linguistic styles. To enhance data quality, we utilize an LLM-as-a-judge filtering process. Experimental results on both industrial and public datasets demonstrate that the proposed approach achieves up to 93.3% of the performance obtained using human-annotated training data. Crucially, the findings reveal that style diversity is more critical than topic diversity for synthetic data utility, as it prevents models from learning spurious stylistic correlations. Furthermore, the study shows that incorporating style attributes during the generation process is more effective than post-hoc style adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an annotation-free framework for synthetic dialogue generation for intent classification, relying only on intent definitions. It incorporates topic and style attributes to increase diversity, introduces two post-hoc stylization models (Univ and Exam), and applies an LLM-as-a-judge filter for quality. Experiments on industrial and public datasets report up to 93.3% of human-annotated performance, concluding that style diversity matters more than topic diversity for avoiding spurious correlations and that in-generation style attributes outperform post-hoc adaptation.
Significance. If the central empirical claims hold after addressing isolation of effects, the work would be significant for industrial NLP settings where seed annotations are unavailable. The annotation-free approach and explicit comparison of style versus topic axes on multiple datasets provide a practical contribution; the relative performance numbers against human baselines are a clear strength.
major comments (2)
- [Abstract and §5] Abstract (quality enhancement paragraph) and §5 (Experimental Results): The style-versus-topic diversity comparison and the 93.3% headline result are obtained after the LLM-as-a-judge filter is applied to all generated utterances. No style-distribution statistics before versus after filtering, no ablation removing the filter, and no human inter-annotator agreement for the judge are reported. Because both diversity axes are varied inside the same filtered pipeline, the claim that “style diversity is more critical” cannot be isolated from possible judge-induced stylistic homogenization.
- [§4.2 and §5.3] §4.2 (Generation Framework) and §5.3 (Ablation Studies): The superiority of incorporating style attributes during generation over the post-hoc Univ/Exam models is asserted, yet the manuscript provides no controlled comparison that holds topic diversity and the judge filter fixed while varying only the timing of style injection. Without this isolation, the relative-effectiveness conclusion rests on confounded conditions.
minor comments (2)
- [Figures 4-6] Table captions and axis labels in the diversity-ablation figures should explicitly state whether the reported numbers are after or before the LLM judge step.
- [§4.1] The definitions of the two novel stylization models (Univ and Exam) would benefit from a short pseudocode or parameter table to clarify their difference from standard prompting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concerns about isolating the effects of the LLM-as-a-judge filter and the timing of style injection are well-taken and point to opportunities to strengthen the empirical claims. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract (quality enhancement paragraph) and §5 (Experimental Results): The style-versus-topic diversity comparison and the 93.3% headline result are obtained after the LLM-as-a-judge filter is applied to all generated utterances. No style-distribution statistics before versus after filtering, no ablation removing the filter, and no human inter-annotator agreement for the judge are reported. Because both diversity axes are varied inside the same filtered pipeline, the claim that “style diversity is more critical” cannot be isolated from possible judge-induced stylistic homogenization.
Authors: We agree that the current presentation does not fully isolate the filter's potential influence on stylistic homogenization. The filter is applied uniformly across all diversity conditions as part of the quality pipeline, and the relative ordering of style versus topic diversity is measured under identical filtering. To address the isolation concern directly, the revised manuscript will include style-distribution statistics before versus after filtering, an ablation that removes the filter entirely, and a human evaluation of the judge outputs to report agreement rates. These additions will allow readers to assess whether the style-diversity advantage persists independently of the filter. revision: yes
-
Referee: [§4.2 and §5.3] §4.2 (Generation Framework) and §5.3 (Ablation Studies): The superiority of incorporating style attributes during generation over the post-hoc Univ/Exam models is asserted, yet the manuscript provides no controlled comparison that holds topic diversity and the judge filter fixed while varying only the timing of style injection. Without this isolation, the relative-effectiveness conclusion rests on confounded conditions.
Authors: The existing comparisons place the in-generation and post-hoc conditions inside the same end-to-end pipeline (including the judge filter), with topic diversity held comparable. We acknowledge that this does not constitute a fully crossed design that varies only the timing of style injection while freezing topic diversity and the filter. The revised version will add a controlled ablation that fixes topic diversity and the judge filter and varies only whether style is injected at generation time or applied post-hoc, thereby isolating the timing effect. revision: yes
Circularity Check
No circularity; purely empirical framework with measured outcomes
full rationale
The paper presents an empirical pipeline for annotation-free synthetic dialogue generation using intent definitions, topic/style attributes, LLM generation, post-hoc stylization models (Univ/Exam), and LLM-as-a-judge filtering. All reported results (e.g., up to 93.3% of human-annotated performance, style diversity > topic diversity) are direct experimental measurements on held-out industrial and public datasets. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the central claims rest on comparative ablation experiments rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Intent disambiguation for task-oriented di- alogue systems. InProceedings of the 31st ACM International Conference on Information & Knowl- edge Management, Atlanta, GA, USA, October 17-21, 2022, pages 5079–5080. ACM. Sundus Muhsin Ali and Khalid Shakir Hussein. 2014. The comparative power of" type/token" and" hapax legomena/type" ratios: A corpus-based st...
Pith/arXiv arXiv 2022
-
[2]
Wanyu Du, Song Feng, James Gung, Lijia Sun, Yi Zhang, Saab Mansour, and Yanjun Qi
Association for Computational Linguistics. Wanyu Du, Song Feng, James Gung, Lijia Sun, Yi Zhang, Saab Mansour, and Yanjun Qi. 2025. DFLOW: Diverse dialogue flow simulation with large language models. InProceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025), pages 17–32, Vienna, Austria. Association for Computational Linguistics...
2025
-
[3]
Improved spoken language representation for intent understanding in a task-oriented dialogue sys- tem.Sensors, 22(4):1509. Atharva Kulkarni, Bo-Hsiang Tseng, Joel Ruben Antony Moniz, Dhivya Piraviperumal, Hong Yu, and Shruti Bhargava. 2024. Synthdst: Synthetic data is all you need for few-shot dialog state tracking. InProceedings of the 18th Conference of...
arXiv 2024
-
[4]
We utilized Shannon Entropy to quantify the unpredictability of word choice, where higher val- ues reflect a more varied and less repetitive commu- nicative style
serve as primary indicators of vocabulary richness; the former measures the proportion of unique words to the total word count, while the lat- ter tracks hapax legomena (words appearing only once). We utilized Shannon Entropy to quantify the unpredictability of word choice, where higher val- ues reflect a more varied and less repetitive commu- nicative st...
2002
-
[5]
Human": ,
metric to evaluate the validation set every 100 steps to select the best training checkpoint. The batch size of 32 with the same sequence length as T5 is used for training. • Intent classification: We do intent classification with Llama-3.2-1B and distilroberta-base models and select the best checkpoint based on the macro F1 metric of the validation set. ...
-
[6]
Usually, ReserveHotel intent comes after SearchHotel intent in a conversation
-
[7]
Usually, ReserveCar intent comes after GetCarsAvail- able intent in a conversation
-
[8]
Usually, ReserveRestaurant intent comes after Find- Restaurants intent in a conversation
-
[9]
Usually, the BuyBusTicket intent comes after the Find- Bus intent in a conversation
-
[10]
Usually, the BookAppointment intent comes after the FindProvider intent in a conversation
-
[11]
# The generated sequences should include at least one of the following intents {list of intents} and one of the following intents {list of intents}
Usually, the BuyEventTickets intent comes after the FindEvents intent in a conversation. # The generated sequences should include at least one of the following intents {list of intents} and one of the following intents {list of intents}. Please generate {N} realistic sequences of intents, rep- resenting the order in which a user might express these intent...
-
[12]
The system should know the name of the hotel, name of the city, check-in date and number of days to stay before reserving the hotel
-
[13]
working on it
The system should ask clarification or elicitation ques- tions to get the required information if they are not men- tioned in the chat history. The system must never produce acknowledgment-only, confirmation, or “working on it” responses
-
[14]
It uses short sentences and avoids too much details and long response
The system’s language is friendly and supportive, of- fering polite clarification and gentle questions to gather details. It uses short sentences and avoids too much details and long response
-
[15]
1 person
The conversation concludes when the system reserves the hotels and confirms it. #Note:Please do not generate more than 5 turns of conversation. Table 13: Examples of attribute dimensions and values defined for SGD dataset. Attribute Type Dimension Values Class-independent Number of people “1 person”, “2 people”, “3 people”, “a couple with 1 child”, “a cou...
2023
-
[16]
Carefully read the intent descriptions and the chat
-
[17]
If the user is simply answering a system question that is meant to clarify or elicit more information about their original request, the intent remains the same as the original request
-
[18]
Decide if the last user utterance expresses the intent predicted by the intent detection model or another intent
-
[19]
Keep the reasoning short
Tell your reasoning in the response. Keep the reasoning short. # Intents descriptions:
-
[20]
FindMovies: user wants to find movies by genre and optionally director, or search for movies by location, genre or other attributes
-
[21]
system: Should I reserve a table for you in Thai House & Wine Bar?
GetWeather: user wants to get the weather of a certain location on a date. ... # Example 1: # Chat: "system: Should I reserve a table for you in Thai House & Wine Bar?" "user: Yes, please make a reservation for morning 11:45." # Intent detection model prediction:"ReserveRestau- rant" # Output: { "reason": "user wants to reserve a table in a restaurant.", ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.