InfantFace: Detecting infant faces in neonatal clinical environments
Pith reviewed 2026-06-26 18:07 UTC · model grok-4.3
The pith
A YOLOv11m model fine-tuned on neonatal videos detects infant faces in clinical settings at 0.96 AP50.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A one-stage YOLOv11m model trained on combined public face datasets and then fine-tuned on a neonatal dataset of 228 videos from 114 sessions of 113 infants reaches an AP50 of 0.96 for localizing infant faces, outperforming three state-of-the-art general face detectors evaluated on the same clinical data.
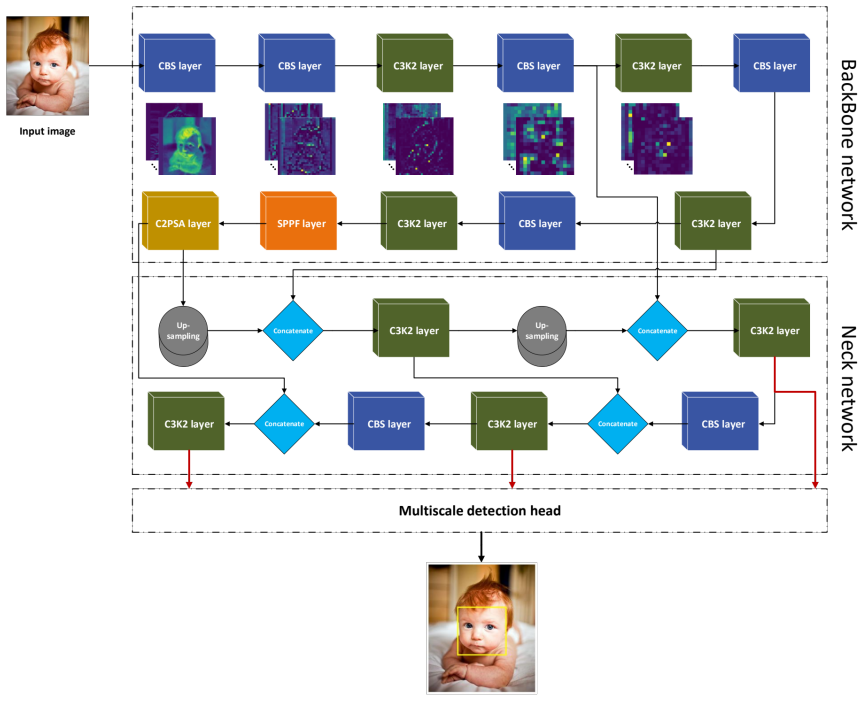
What carries the argument
The one-stage YOLOv11m-based detector with clinical-domain adaptation on neonatal video data.
If this is right
- Reliable face localization becomes available as the starting point for camera-based pain scoring and distress analysis in neonates.
- Non-contact cardiorespiratory signal extraction and breathing-cessation alerts can operate without physical sensors attached to the infant.
- The same adapted model can be evaluated against other general face detectors to quantify the gain from neonatal-specific fine-tuning.
Where Pith is reading between the lines
- Similar domain-adaptation steps could be tested on older children or other pediatric wards where face detection is also obstructed.
- Public release of additional neonatal face datasets, with privacy protections, would allow direct comparison of future detectors.
- The performance jump after adaptation suggests that small targeted clinical datasets can close large gaps left by adult-trained models.
Load-bearing premise
The collection of 228 videos from 113 infants is varied enough to represent real clinical conditions and to support domain adaptation without overfitting or hidden bias.
What would settle it
Running the same fine-tuned model on a fresh collection of neonatal videos recorded under different hospitals, lighting, or equipment and finding that AP50 falls well below 0.96 would show the adaptation does not generalize.
Figures

read the original abstract
Reliable localisation of the neonatal face is the first step for several video-camera based non-contact assessments such as pain and distress related facial expression analysis, pain scoring, cardiorespiratory signal extraction and cessation of breathing alerts. However, major challenges persist in neonatal clinical environments. Cluttered backgrounds, illumination changes and poor lighting conditions can reduce the accuracy of face detection models. Clinical interventions, monitoring equipment and, in some cases, medical devices can obstruct the face, making visual assessment difficult. We propose a one-stage YOLOv11m-based model tailored for face detection of infants in neonatal clinical environments. We combined multiple publicly available datasets (VGGFace2, CelebA, FDDB, WIDER FACE) to train and evaluate our proposed model. We then fine-tuned our model on a neonatal research dataset involving 228 videos from 114 recording sessions of 113 independent infants. Before fine-tuning, our model achieved an AP50 of 0.87, surpassing the performance of three state-of-the-art general face detectors. Performance improved further to an AP50 of 0.96 after clinical-domain adaptation. Evaluating face detection performance across different datasets remains a challenge due to the lack of publicly available neonatal datasets. Prioritising the creation of such datasets, while upholding appropriate privacy safeguards and ethical standards in their creation and use, would greatly support further progress in this field.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a YOLOv11m-based one-stage detector for infant faces in neonatal clinical settings. It first trains on the union of VGGFace2, CelebA, FDDB and WIDER FACE, reporting AP50 = 0.87 that exceeds three unnamed general-purpose face detectors; it then fine-tunes on a private neonatal corpus of 228 videos from 114 sessions of 113 infants and reports an improved AP50 of 0.96. The work notes the absence of public neonatal benchmarks and calls for their creation under appropriate privacy safeguards.
Significance. A reliably validated domain-adapted detector would directly support downstream non-contact neonatal monitoring tasks (pain scoring, cardiorespiratory extraction, apnoea alerts). The reported 0.09 AP50 gain is potentially impactful, but its significance cannot be assessed without evidence that the fine-tuning evaluation used infant-disjoint, session-disjoint held-out data.
major comments (2)
- [Abstract] Abstract: the headline claim that fine-tuning raises AP50 from 0.87 to 0.96 is load-bearing for the central contribution, yet the abstract (and, by the provided text, the manuscript) supplies no information on train/test partitioning of the 228-video neonatal set, whether the 114 sessions were split by infant identity, or any cross-validation protocol. Without these details the 0.09 gain cannot be distinguished from overfitting or identity leakage.
- [Abstract] Abstract: the statement that the pre-fine-tuning model 'surpass[es] the performance of three state-of-the-art general face detectors' is unsupported by any named baselines, per-detector AP50 scores, or evaluation protocol on the public datasets, preventing verification of the claimed superiority.
minor comments (1)
- [Abstract] Abstract: the phrase '114 recording sessions of 113 independent infants' is internally inconsistent (one extra session) and should be clarified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight the need for greater transparency in our evaluation protocol and baseline comparisons, which we will address through revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that fine-tuning raises AP50 from 0.87 to 0.96 is load-bearing for the central contribution, yet the abstract (and, by the provided text, the manuscript) supplies no information on train/test partitioning of the 228-video neonatal set, whether the 114 sessions were split by infant identity, or any cross-validation protocol. Without these details the 0.09 gain cannot be distinguished from overfitting or identity leakage.
Authors: We agree that explicit details on the train/test partitioning are required to substantiate the reported performance gain and rule out identity leakage or overfitting. The neonatal corpus comprises 228 videos from 114 sessions of 113 independent infants. In the revision we will add a dedicated subsection describing the partitioning protocol, confirming that the splits are infant-disjoint (and session-disjoint where relevant) and specifying the cross-validation procedure employed. revision: yes
-
Referee: [Abstract] Abstract: the statement that the pre-fine-tuning model 'surpass[es] the performance of three state-of-the-art general face detectors' is unsupported by any named baselines, per-detector AP50 scores, or evaluation protocol on the public datasets, preventing verification of the claimed superiority.
Authors: We acknowledge that the manuscript does not name the three general face detectors, report their individual AP50 scores, or detail the evaluation protocol on the combined public datasets. In the revision we will explicitly identify the detectors, provide their per-detector AP50 values on the union of VGGFace2, CelebA, FDDB and WIDER FACE, and describe the evaluation protocol used. revision: yes
Circularity Check
No circularity: standard empirical ML training and fine-tuning with no self-referential derivations
full rationale
The paper reports training a YOLOv11m detector on public datasets (VGGFace2, CelebA, FDDB, WIDER FACE) to AP50 0.87, followed by fine-tuning on the authors' private neonatal corpus (228 videos, 113 infants) to reach AP50 0.96. No equations, first-principles derivations, or 'predictions' are claimed. The performance numbers are direct empirical measurements after supervised training/fine-tuning; they do not reduce to fitted parameters by construction, nor do they rely on self-citation chains, uniqueness theorems, or ansatzes imported from prior work. The evaluation protocol is described as standard domain adaptation without any load-bearing self-referential steps. This is the expected non-finding for an applied computer-vision paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- fine-tuning hyperparameters
axioms (1)
- domain assumption General face datasets provide transferable features to infant faces in clinical settings
Reference graph
Works this paper leans on
-
[1]
& Kumar, M
Kumar, A., Kaur, A. & Kumar, M. Face detection techniques: a review. Artif. Intell. Rev. 52, 927–948 (2019)
2019
-
[2]
M., Agarwal, B
Rizvi, Q. M., Agarwal, B. G. & Beg, R. A review on face detection methods. J. Manag. Dev. Inf. Technol. 11 (2011)
2011
-
[3]
K., Ahsan, M
Hasan, M. K., Ahsan, M. S., Newaz, S. S. & Lee, G. M. Human face detection techniques: A comprehensive review and future research directions. Electronics 10, 2354 (2021)
2021
-
[4]
Huang, B. et al. A neonatal dataset and benchmark for non-contact neonatal heart rate monitoring based on spatio-temporal neural networks. Eng. Appl. Artif. Intell. 106, 104447 (2021)
2021
-
[5]
Heiderich, T. M. et al. Face-based automatic pain assessment: challenges and perspectives in neonatal intensive care units. Jornal de Pediatr. 99, 546–560 (2023)
2023
-
[6]
Bergamasco, L. et al. Pain assessment in neonatal clinical practice via facial expression analysis and deep learning. In International Work-Conference on Bioinformatics and Biomedical Engineering, 249–263 (Springer, 2024)
2024
-
[7]
Hausmann, J. et al. Accurate neonatal face detection for improved pain classification in the challenging nicu setting. IEEE Access (2024)
2024
-
[8]
Deep learning-based pain intensity estimation from facial expressions
Ben Aoun, N. Deep learning-based pain intensity estimation from facial expressions. In International Conference on Intelligent Systems Design and Applications , 484–493 (Springer, 2023)
2023
-
[9]
Giordano, V. et al. Comparative analysis of artificial intelligence and expert assessments in detecting neonatal procedural pain. Sci. Reports 14, 20374 (2024)
2024
-
[10]
& Sun, Y
Cao, K., Tan, T., Chen, Z., Yang, K. & Sun, Y . A novel heart rate estimation framework with self-correcting face detection for neonatal intensive care unit. Displays 85, 102852 (2024)
2024
-
[11]
Villarroel, M. et al. Continuous non-contact vital sign monitoring in neonatal intensive care unit. Healthc. technology letters 1, 87–91 (2014). 25
2014
-
[12]
Chaichulee, S. et al. Cardio-respiratory signal extraction from video camera data for continuous non-contact vital sign monitoring using deep learning. Physiol. measurement 40, 115001 (2019)
2019
-
[13]
Chaichulee, S. et al. Localised photoplethysmography imaging for heart rate estimation of pre-term infants in the clinic. In Optical diagnostics and sensing XVIII: toward point-of-care diagnostics, vol. 10501, 146–159 (SPIE, 2018)
2018
-
[14]
& Qiao, Y
Zhang, K., Zhang, Z., Li, Z. & Qiao, Y . Joint face detection and alignment using multitask cascaded convolutional networks. IEEE signal processing letters 23, 1499–1503 (2016)
2016
-
[15]
Bazarevsky, V., Kartynnik, Y ., Vakunov, A., Raveendran, K. & Grundmann, M. Blazeface: Sub- millisecond neural face detection on mobile gpus. arXiv preprint arXiv:1907.05047 (2019)
Pith/arXiv arXiv 1907
-
[16]
Howard, A. G. et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017)
Pith/arXiv arXiv 2017
-
[17]
Deng, J. et al. Retinaface: Single-stage dense face localisation in the wild. arXiv preprint arXiv:1905.00641 (2019)
Pith/arXiv arXiv 1905
-
[18]
& Dollár, P
Lin, T.-Y ., Goyal, P ., Girshick, R., He, K. & Dollár, P . Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, 2980–2988 (2017)
2017
-
[19]
Guo, J., Deng, J., Lattas, A. & Zafeiriou, S. Sample and computation redistribution for efficient face detection. arXiv preprint arXiv:2105.04714 (2021)
arXiv 2021
-
[20]
Li, J. et al. Dsfd: dual shot face detector. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 5060–5069 (2019)
2019
-
[21]
Dosso, Y . S. et al. Neonatal face tracking for non-contact continuous patient monitoring. In 2020 IEEE International Symposium on Medical Measurements and Applications (MeMeA) , 1–6 (IEEE, 2020)
2020
-
[22]
Grooby, E. et al. Neonatal face and facial landmark detection from video recordings. In 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), 1–5 (IEEE, 2023). 26
2023
-
[23]
S., Kyrollos, D., Greenwood, K
Dosso, Y . S., Kyrollos, D., Greenwood, K. J., Harrold, J. & Green, J. R. Nicuface: Robust neonatal face detection in complex nicu scenes. IEEE Access 10, 62893–62909 (2022)
2022
-
[24]
Gleichauf, J. et al. Sensor fusion for the robust detection of facial regions of neonates using neural networks. Sensors 23, 4910 (2023)
2023
-
[25]
Cao, Q., Shen, L., Xie, W., Parkhi, O. M. & Zisserman, A. VGGFace2: A dataset for recognising faces across pose and age. In International Conference on Automatic Face and Gesture Recognition (2018)
2018
-
[26]
& Tang, X
Liu, Z., Luo, P ., Wang, X. & Tang, X. Deep learning face attributes in the wild. In Proceedings of International Conference on Computer Vision (ICCV) (2015)
2015
-
[27]
& Learned-Miller, E
Jain, V. & Learned-Miller, E. Fddb: A benchmark for face detection in unconstrained settings. Tech. Rep., UMass Amherst technical report (2010)
2010
-
[28]
Yang, S., Luo, P ., Loy, C. C. & Tang, X. Wider face: A face detection benchmark. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
2016
-
[29]
Cobo, M. M. et al. Multicentre, randomised controlled trial to investigate the effects of parental touch on relieving acute procedural pain in neonates (petal). BMJ open 12, e061841 (2022)
2022
-
[30]
Hauck, A. G. et al. Effect of parental touch on relieving acute procedural pain in neonates and parental anxiety (petal): a multicentre, randomised controlled trial in the uk. The Lancet Child & Adolesc. Heal. 8, 259–269 (2024)
2024
-
[31]
Stevens, B. J. et al. The premature infant pain profile-revised (pipp-r): initial validation and feasibility. The Clin. journal pain 30, 238–243 (2014)
2014
-
[32]
Labelme: Image polygonal annotation with python
Wada, K. Labelme: Image polygonal annotation with python. GitHub: https://github.com/wkentaro/labelme (2021).Version 5.0.1. DOI: 10.5281/zenodo.5711226
-
[33]
& Qiu, J
Jocher, G. & Qiu, J. Ultralytics yolov11. GitHub: https://github.com/ultralytics/ultralytics (2024). Version 11.0.0. 27
2024
-
[34]
Lin, T.-Y . et al. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, 740–755 (Springer, 2014)
2014
-
[35]
Torchvision image transforms - pytorch documentation (2026)
PyTorch Team. Torchvision image transforms - pytorch documentation (2026). URL https://docs.pytorch. org/vision/main/transforms.html
2026
-
[36]
Zheng, Z. et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Transactions on cybernetics 52, 8574–8586 (2021)
2021
-
[37]
Li, X. et al. Generalized focal loss: Towards efficient representation learning for dense object detection. IEEE transactions on pattern analysis machine intelligence 45, 3139–3153 (2022)
2022
-
[38]
& Wolfowitz, J
Kiefer, J. & Wolfowitz, J. Stochastic estimation of the maximum of a regression function. The Annals Math. Stat. 462–466 (1952). S1 Supplementary Information InfantFace: Detecting infant faces in neonatal clinical environments Supplementary materials A: WIDER FACE category distribution To better understand the composition of the WIDER FACE dataset, we vis...
1952
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.