SSD: Spatially Speculative Decoding Accelerates Autoregressive Image Generation
Pith reviewed 2026-06-26 17:34 UTC · model grok-4.3
The pith
By predicting adjacent horizontal and vertical tokens at once, spatially speculative decoding speeds autoregressive image generation up to 13.3 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
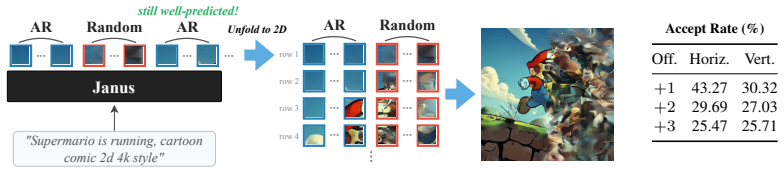
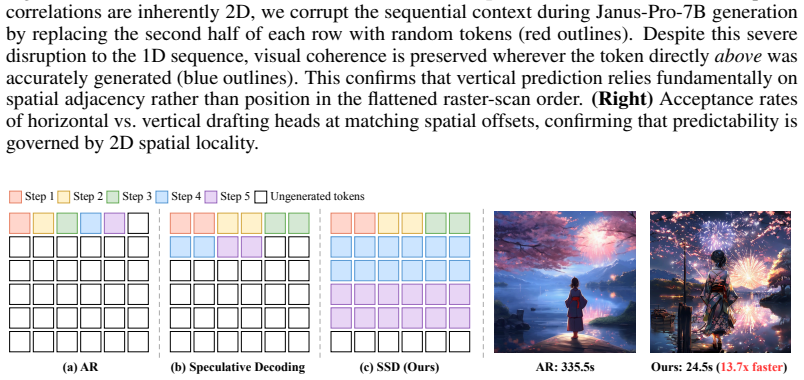
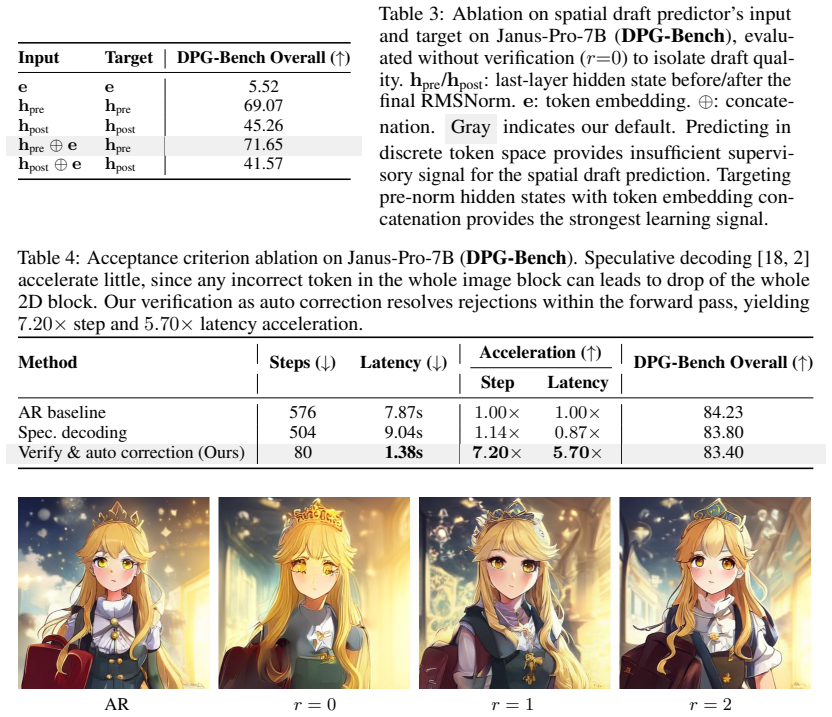
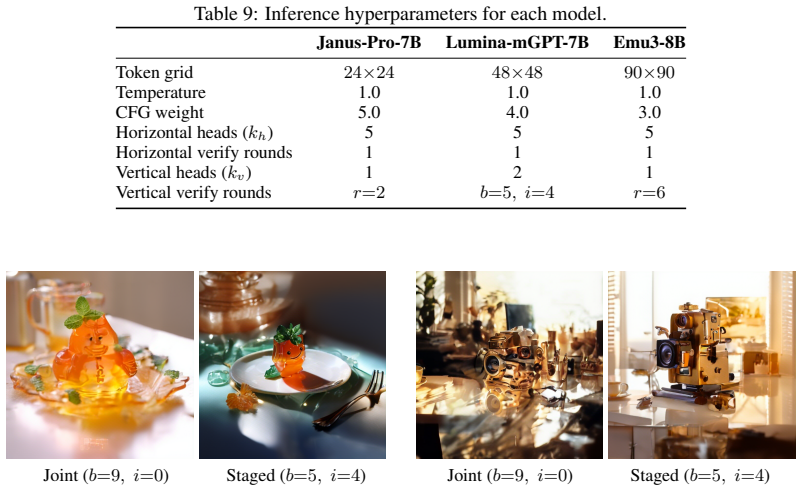
The paper claims that its Spatially Speculative Decoding framework aligns the prediction objective with image geometry by simultaneously forecasting the adjacent horizontal token and the token directly below the current position. This 2D extension of next-token prediction overcomes the memory wall that arises from 1D flattening, delivering speedups of up to 13.3 times on DPG-Bench and GenEval without loss of fidelity.
What carries the argument
Spatially Speculative Decoding (SSD), which extends single next-token prediction to joint prediction of the rightward and downward neighbor tokens by exploiting intrinsic 2D spatial correlations.
Load-bearing premise
That simultaneous prediction of adjacent horizontal and below tokens can be performed accurately enough to preserve generation quality because of 2D spatial correlations in images.
What would settle it
A measurable drop in scores on DPG-Bench or GenEval when the same base autoregressive model is run with SSD instead of standard next-token decoding.
Figures


read the original abstract
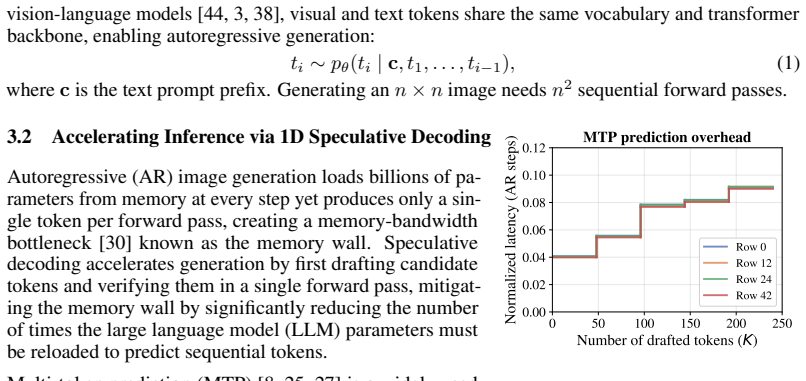
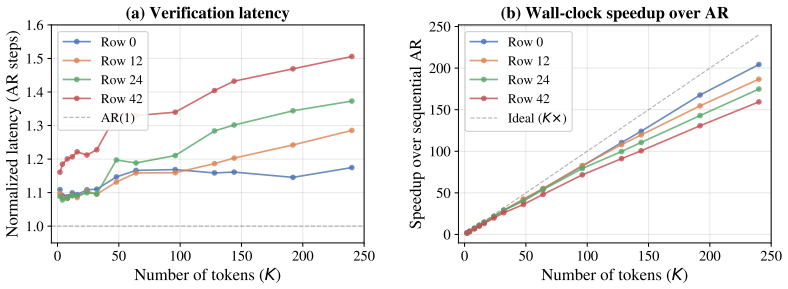
Autoregressive models excel in visual generation by treating images as 1D sequences of discrete tokens, mirroring language modeling. However, this flattening discards the intrinsic 2D spatial locality of visual signals, creating severe computational bottlenecks during inference. We introduce Spatially Speculative Decoding (SSD), a framework that aligns the predictive objective with the natural geometry of images. Rather than predicting only the immediate next token in a 1D sequence, our model simultaneously predicts the adjacent horizontal token and the token directly below it. By capitalizing on this 2D spatial correlation, spatially speculative decoding overcomes the memory wall in visual inference. Our approach accelerates autoregressive image generation by up to 13.3x while maintaining high fidelity on DPG-Bench and GenEval. Our results suggest that respecting the underlying geometry of vision unlocks massive computational efficiencies, paving the way for real-time, high-resolution autoregressive generative models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Spatially Speculative Decoding (SSD) for autoregressive image generation. Rather than predicting only the next token in a flattened 1D raster-order sequence, the model is trained to jointly predict the next token along with its right-adjacent and below-adjacent neighbors. This modification exploits intrinsic 2D spatial correlations in images to enable speculative parallel predictions that reduce the number of sequential forward passes at inference time, with the central empirical claim being an acceleration of up to 13.3x while preserving generation quality on DPG-Bench and GenEval.
Significance. If the empirical results and quality preservation hold under detailed scrutiny, the work offers a lightweight way to align the training objective with image geometry instead of discarding 2D locality, which could meaningfully improve inference throughput for high-resolution autoregressive visual generators and support real-time applications. The approach is notable for its simplicity in modifying only the predictive targets without introducing new architectural components or parameters.
major comments (1)
- The central speedup claim (up to 13.3x) and fidelity maintenance rest on the assumption that simultaneous prediction of horizontal and vertical neighbors can be performed with sufficient accuracy; however, without any reported equations for the modified loss, details on how speculative tokens are accepted or rejected during raster-order generation, or ablation studies isolating the contribution of the 2D objective, the load-bearing mechanism cannot be verified from the provided text.
minor comments (1)
- The abstract supplies only high-level claims with no methods, quantitative error analysis, or verification details, which limits immediate assessment of the reported benchmarks and speedup factor.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for greater technical detail. We address the major comment below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: The central speedup claim (up to 13.3x) and fidelity maintenance rest on the assumption that simultaneous prediction of horizontal and vertical neighbors can be performed with sufficient accuracy; however, without any reported equations for the modified loss, details on how speculative tokens are accepted or rejected during raster-order generation, or ablation studies isolating the contribution of the 2D objective, the load-bearing mechanism cannot be verified from the provided text.
Authors: We agree that the current manuscript lacks sufficient detail on these points. The revised version will add: (1) the explicit equation for the modified training loss that jointly optimizes the next token together with its right-adjacent and below-adjacent neighbors; (2) a precise description (with pseudocode) of the inference procedure, including the criteria and mechanism for accepting or rejecting the spatially speculative tokens while preserving raster-order generation; and (3) ablation experiments that isolate the contribution of the 2D spatial objective to both the observed speedup and the preservation of generation quality on DPG-Bench and GenEval. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe a speculative decoding framework that jointly predicts next, right, and below tokens to exploit 2D image correlations for faster inference. No equations, parameter-fitting steps, derivations, or self-citations appear that reduce any claimed prediction or result to its own inputs by construction. The speedup and quality claims are presented as empirical outcomes on benchmarks, with the 2D correlation assumption stated as an enabling premise rather than a fitted or self-defined quantity. The derivation chain is self-contained against external benchmarks with no load-bearing reductions to prior author work or ansatzes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Medusa: Simple llm inference acceleration framework with multiple decoding heads
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads. InProceedings of the 41st International Conference on Machine Learning, pages 5209–5235, 2024
2024
-
[2]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023
Pith/arXiv arXiv 2023
-
[3]
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
Pith/arXiv arXiv 2025
-
[4]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
2021
-
[5]
Break the sequential dependency of llm inference using lookahead decoding
Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Break the sequential dependency of llm inference using lookahead decoding. InProceedings of the 41st International Conference on Machine Learning, pages 14060–14079, 2024
2024
-
[6]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[7]
Fast r-cnn
Ross Girshick. Fast r-cnn. InProceedings of the IEEE international conference on computer vision, pages 1440–1448, 2015
2015
-
[8]
Better & faster large language models via multi-token prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, and Gabriel Synnaeve. Better & faster large language models via multi-token prediction. InProceedings of the 41st International Conference on Machine Learning, pages 15706–15734, 2024
2024
-
[9]
Zipar: Parallel autoregressive image generation through spatial locality
Yefei He, Feng Chen, Yuanyu He, Shaoxuan He, Hong Zhou, Kaipeng Zhang, and Bohan Zhuang. Zipar: Parallel autoregressive image generation through spatial locality. InInternational Conference on Machine Learning, pages 22368–22378. PMLR, 2025
2025
-
[10]
Neighboring autoregressive modeling for efficient visual generation
Yefei He, Yuanyu He, Shaoxuan He, Feng Chen, Hong Zhou, Kaipeng Zhang, and Bohan Zhuang. Neighboring autoregressive modeling for efficient visual generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19000–19010, 2025
2025
-
[11]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[12]
Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[13]
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024. 10
Pith/arXiv arXiv 2024
-
[14]
Midjourney prompts dataset
Huggingface. Midjourney prompts dataset. https://huggingface.co/datasets/vivym/ midjourney-prompts, 2024
2024
-
[15]
Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[16]
Lantern: Accelerating visual autoregressive models with relaxed speculative decoding
Doohyuk Jang, Sihwan Park, June Yong Yang, Yeonsung Jung, Jihun Yun, Souvik Kundu, Sung- Yub Kim, and Eunho Yang. Lantern: Accelerating visual autoregressive models with relaxed speculative decoding. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[17]
Cllms: consistency large language models
Siqi Kou, Lanxiang Hu, Zhezhi He, Zhijie Deng, and Hao Zhang. Cllms: consistency large language models. InProceedings of the 41st International Conference on Machine Learning, pages 25426–25440, 2024
2024
-
[18]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR, 2023
2023
-
[19]
Autoregressive image generation with randomized parallel decoding
Haopeng Li, Jinyue Yang, Guoqi Li, and Huan Wang. Autoregressive image generation with randomized parallel decoding. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[20]
Xingyao Li, Fengzhuo Zhang, Cunxiao Du, and Hui Ji. Annealed relaxation of speculative decoding for faster autoregressive image generation.arXiv preprint arXiv:2601.09212, 2026
arXiv 2026
-
[21]
Eagle: speculative sampling requires rethinking feature uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: speculative sampling requires rethinking feature uncertainty. InProceedings of the 41st International Conference on Machine Learning, pages 28935–28948, 2024
2024
-
[22]
Eagle-2: Faster inference of language models with dynamic draft trees
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-2: Faster inference of language models with dynamic draft trees. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 7421–7432, 2024
2024
-
[23]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-3: Scaling up inference acceleration of large language models via training-time test.arXiv preprint arXiv:2503.01840, 2025
Pith/arXiv arXiv 2025
-
[24]
Parallel jacobi decoding for fast autoregres- sive image generation
Boya Liao, Ying Li, Siyong Jian, and Huan Wang. Parallel jacobi decoding for fast autoregres- sive image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9008–9018, 2026
2026
-
[25]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[26]
Dongyang Liu, Shitian Zhao, Le Zhuo, Weifeng Lin, Yi Xin, Xinyue Li, Qi Qin, Yu Qiao, Hongsheng Li, and Peng Gao. Lumina-mgpt: Illuminate flexible photorealistic text-to-image generation with multimodal generative pretraining.arXiv preprint arXiv:2408.02657, 2024
arXiv 2024
-
[27]
Xiaohao Liu, Xiaobo Xia, Weixiang Zhao, Manyi Zhang, Xianzhi Yu, Xiu Su, Shuo Yang, See-Kiong Ng, and Tat-Seng Chua. L-mtp: Leap multi-token prediction beyond adjacent context for large language models.arXiv preprint arXiv:2505.17505, 2025
arXiv 2025
-
[28]
Specinfer: Accelerating large language model serving with tree-based speculative inference and verification
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, et al. Specinfer: Accelerating large language model serving with tree-based speculative inference and verification. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Lang...
2024
-
[29]
Multi-scale local speculative decoding for image generation.arXiv preprint arXiv:2601.05149, 2026
Elia Peruzzo, Guillaume Sautière, and Amirhossein Habibian. Multi-scale local speculative decoding for image generation.arXiv preprint arXiv:2601.05149, 2026. 11
Pith/arXiv arXiv 2026
-
[30]
Efficiently scaling transformer inference
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. Proceedings of machine learning and systems, 5:606–624, 2023
2023
-
[31]
Searching for activation functions.arXiv preprint arXiv:1710.05941, 2017
Prajit Ramachandran, Barret Zoph, and Quoc V Le. Searching for activation functions.arXiv preprint arXiv:1710.05941, 2017
Pith/arXiv arXiv 2017
-
[32]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInternational conference on machine learning, pages 8821–8831. Pmlr, 2021
2021
-
[33]
Accelerating transformer inference for translation via parallel decoding
Andrea Santilli, Silvio Severino, Emilian Postolache, Valentino Maiorca, Michele Mancusi, Riccardo Marin, and Emanuele Rodolà. Accelerating transformer inference for translation via parallel decoding. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12336–12355, 2023
2023
-
[34]
Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
Pith/arXiv arXiv 2002
-
[35]
Grouped speculative decoding for autoregressive image generation
Junhyuk So, Juncheol Shin, Hyunho Kook, and Eunhyeok Park. Grouped speculative decoding for autoregressive image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15375–15384, 2025
2025
-
[36]
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024
Pith/arXiv arXiv 2024
-
[37]
Emu: Generative pretraining in multimodality
Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Emu: Generative pretraining in multimodality. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[38]
Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024
Pith/arXiv arXiv 2024
-
[39]
Accelerating auto-regressive text-to-image generation with training-free speculative jacobi decoding
Yao Teng, Han Shi, Xian Liu, Xuefei Ning, Guohao Dai, Yu Wang, Zhenguo Li, and Xihui Liu. Accelerating auto-regressive text-to-image generation with training-free speculative jacobi decoding. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[40]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
2017
-
[41]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[42]
Emu3: Next-token prediction is all you need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024
Pith/arXiv arXiv 2024
-
[43]
Parallelized autoregressive visual generation
Yuqing Wang, Shuhuai Ren, Zhijie Lin, Yujin Han, Haoyuan Guo, Zhenheng Yang, Difan Zou, Jiashi Feng, and Xihui Liu. Parallelized autoregressive visual generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12955–12965, 2025
2025
-
[44]
Janus: Decoupling visual encoding for unified multimodal understanding and generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encoding for unified multimodal understanding and generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12966–12977, 2025
2025
-
[45]
Show-o: One single transformer to unify multimodal understanding and generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation. InThe Thirteenth International Conference on Learning Representations, 2025. 12
2025
-
[46]
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, et al. Scaling autoregressive models for content-rich text-to-image generation.arXiv preprint arXiv:2206.10789, 2022
Pith/arXiv arXiv 2022
-
[47]
Language model beats diffusion-tokenizer is key to visual generation
Lijun Yu, Jose Lezama, Nitesh Bharadwaj Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G Hauptmann, et al. Language model beats diffusion-tokenizer is key to visual generation. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[48]
Root mean square layer normalization.Advances in neural information processing systems, 32, 2019
Biao Zhang and Rico Sennrich. Root mean square layer normalization.Advances in neural information processing systems, 32, 2019
2019
-
[49]
Mul- timodal chain-of-thought reasoning in language models.Transactions on Machine Learning Research, 2024, 2024
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Mul- timodal chain-of-thought reasoning in language models.Transactions on Machine Learning Research, 2024, 2024
2024
-
[50]
Zhuoyang Zhang, Luke J Huang, Chengyue Wu, Shang Yang, Kelly Peng, Yao Lu, and Song Han. Locality-aware parallel decoding for efficient autoregressive image generation.arXiv preprint arXiv:2507.01957, 2025. A Technical appendices and supplementary material This supplementary material provides additional details that complement the main text. All experi- m...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.