JanusMesh: Fast and Zero-Shot 3D Visual Illusion Generation via Cross-Space Denoising
Pith reviewed 2026-06-26 18:16 UTC · model grok-4.3
The pith
A cross-space dual-branch denoising process fuses two shapes into one coherent mesh then applies view-specific 2D textures to produce dual-semantic 3D illusions without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
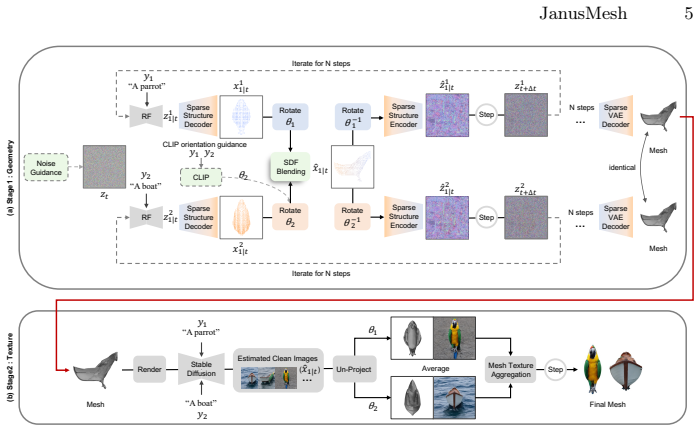
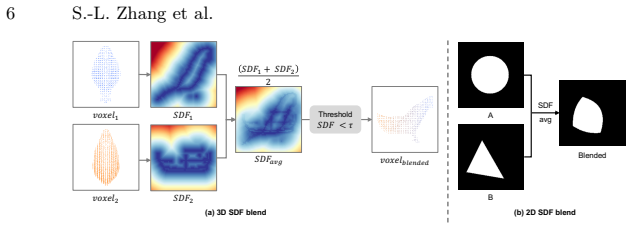
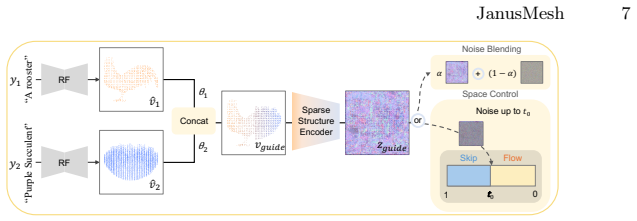
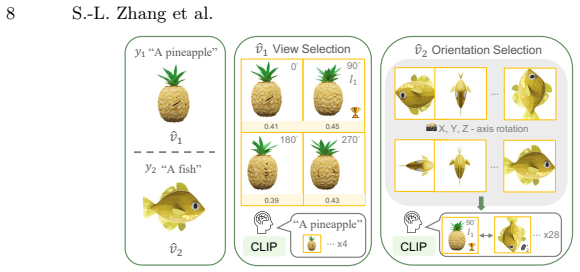
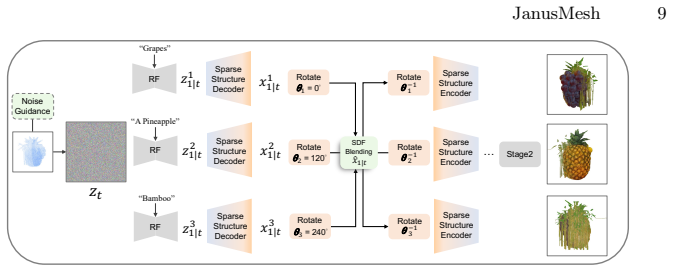
Our approach decouples the generation into two stages. First, we propose a cross-space dual-branch denoising process. This process dynamically decodes 3D latents into voxel space for CLIP-guided orientation alignment and Signed Distance Field (SDF) blending, which ensures seamless geometric fusion. Second, we introduce a view-conditioned texture synthesis module that projects and aggregates view-specific 2D diffusion priors onto the fused geometry. Extensive experiments demonstrate that our method generates highly realistic, dual-semantic 3D illusions in just 3-5 minutes and significantly outperforms existing methods in geometric integrity, semantic recognizability, and efficiency.
What carries the argument
Cross-space dual-branch denoising process that dynamically decodes 3D latents into voxel space for CLIP-guided orientation alignment and SDF blending, combined with a view-conditioned texture synthesis module that projects and aggregates 2D diffusion priors.
If this is right
- Produces geometrically seamless fusion of two distinct shapes into one mesh
- Maintains dual semantics through aggregation of view-specific 2D priors
- Completes the full generation pipeline in 3-5 minutes
- Achieves higher geometric integrity and semantic recognizability than optimization or stitching baselines
Where Pith is reading between the lines
- The explicit separation of geometry fusion from texture synthesis could be reused for other multi-view consistency tasks in 3D content creation.
- Because the method relies on existing 2D diffusion models for textures, its output quality tracks improvements in those models over time.
- The dual-branch structure might be extended to support three or more distinct viewing angles by adding further alignment branches.
Load-bearing premise
Dynamically decoding 3D latents into voxel space and applying CLIP-guided alignment plus SDF blending will automatically produce geometrically coherent objects without seams or semantic leaks, and projecting 2D diffusion priors will preserve dual semantics on the fused mesh without additional training.
What would settle it
A generated mesh that shows visible seams at fusion boundaries or loses clear recognition of one intended semantic object when rendered from the corresponding viewpoint would show the method fails to deliver the claimed coherence.
Figures



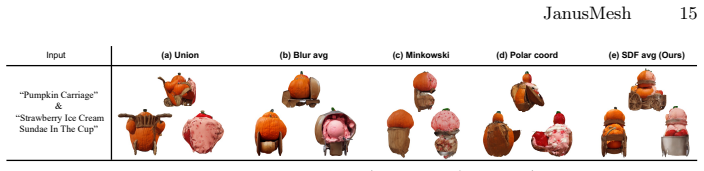
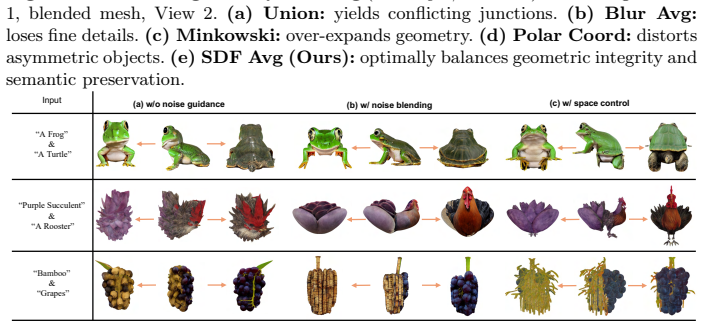


read the original abstract
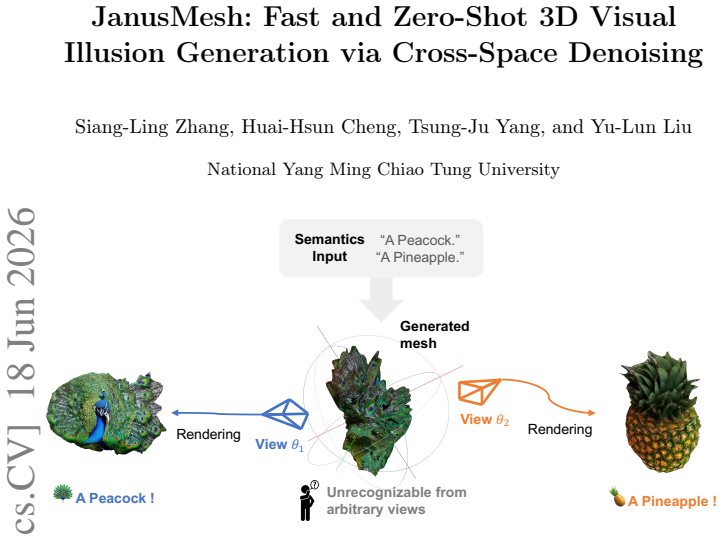
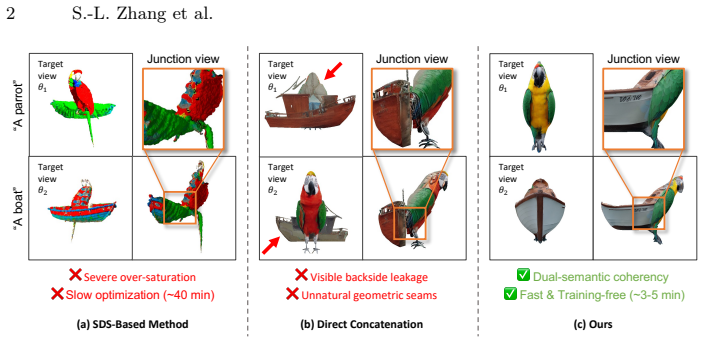
Creating 3D visual illusions, a single 3D mesh that reveals entirely different semantics from various viewing angles, is a fascinating but tough challenge. Existing optimization-based methods are slow and can produce oversaturated colors. In contrast, naive stitching approaches fail to produce geometrically coherent objects. This results in visible unnatural seams and semantic leaks. In this paper, we present a fast and training-free framework for generating text-driven 3D visual illusions. Our approach decouples the generation into two stages. First, we propose a cross-space dual-branch denoising process. This process dynamically decodes 3D latents into voxel space for CLIP-guided orientation alignment and Signed Distance Field (SDF) blending, which ensures seamless geometric fusion. Second, we introduce a view-conditioned texture synthesis module that projects and aggregates view-specific 2D diffusion priors onto the fused geometry. Extensive experiments demonstrate that our method generates highly realistic, dual-semantic 3D illusions in just 3-5 minutes. It significantly outperforms existing methods in geometric integrity, semantic recognizability, and efficiency. Project page: https://siang1105.github.io/JanusMesh.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce JanusMesh, a fast training-free framework for text-driven 3D visual illusions. It decouples generation into (1) a cross-space dual-branch denoising process that dynamically decodes 3D latents into voxel space, applies CLIP-guided orientation alignment and SDF blending for seamless geometric fusion, and (2) a view-conditioned texture synthesis module that projects and aggregates 2D diffusion priors onto the fused mesh. The method is asserted to produce realistic dual-semantic 3D meshes in 3-5 minutes and to significantly outperform prior optimization-based and stitching methods on geometric integrity, semantic recognizability, and efficiency.
Significance. If the central claims hold, the work would be significant for providing an efficient zero-shot alternative to slow optimization pipelines and seam-prone stitching, with potential impact on AR/VR content creation and creative 3D design. The explicit decoupling of geometry fusion from texture synthesis is a clear conceptual contribution; the reported runtime is a practical strength.
major comments (2)
- [Abstract / §3] Abstract and §3 (method description): the cross-space dual-branch denoising process is presented only at the level of high-level stages (voxel decoding, CLIP alignment, SDF blending) with no equations, pseudocode, or explicit definition of the blending operator, latent initialization for the two text prompts, or the alignment loss. This mechanism is load-bearing for the central claim that the process 'ensures seamless geometric fusion' without post-processing or semantic leaks; its absence prevents verification of the contrast with naive stitching failures.
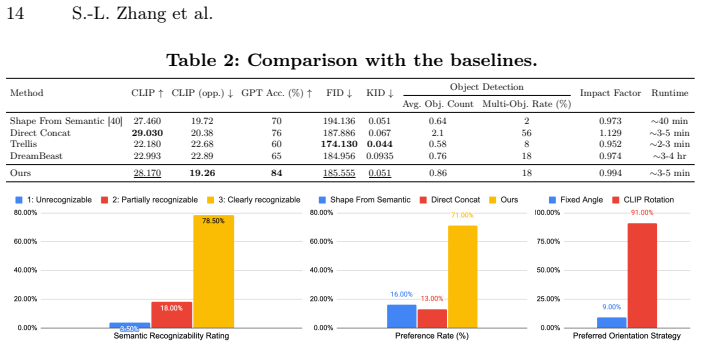
- [§4] §4 (experiments): the abstract states that 'extensive experiments demonstrate' significant outperformance and supplies runtime numbers, yet the provided text contains no tables of quantitative metrics (e.g., geometric error, CLIP similarity scores, user-study percentages), no ablation results, and no error bars or statistical tests. Without these, the performance claims cannot be assessed and remain unverified.
minor comments (2)
- [§3] Notation for the two text prompts and the dual-branch latents should be introduced explicitly at first use to avoid ambiguity.
- [Figures] Figure captions should include the exact text prompts used for each example to allow direct reproduction of the dual-semantic results.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to incorporate the requested details and evaluations.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method description): the cross-space dual-branch denoising process is presented only at the level of high-level stages (voxel decoding, CLIP alignment, SDF blending) with no equations, pseudocode, or explicit definition of the blending operator, latent initialization for the two text prompts, or the alignment loss. This mechanism is load-bearing for the central claim that the process 'ensures seamless geometric fusion' without post-processing or semantic leaks; its absence prevents verification of the contrast with naive stitching failures.
Authors: We agree that the current description remains at a high level. In the revised manuscript we will add the explicit mathematical formulation of the cross-space dual-branch denoising, including latent initialization for the pair of text prompts, the CLIP-guided alignment loss, the precise definition of the SDF blending operator, and pseudocode for the overall procedure. These additions will make the mechanism verifiable and will clarify the distinction from naive stitching. revision: yes
-
Referee: [§4] §4 (experiments): the abstract states that 'extensive experiments demonstrate' significant outperformance and supplies runtime numbers, yet the provided text contains no tables of quantitative metrics (e.g., geometric error, CLIP similarity scores, user-study percentages), no ablation results, and no error bars or statistical tests. Without these, the performance claims cannot be assessed and remain unverified.
Authors: We acknowledge that the manuscript text as provided lacks quantitative tables, ablations, and statistical reporting. In the revision we will insert tables with geometric error metrics, CLIP-based semantic similarity scores, user-study percentages, component ablations, error bars, and statistical tests to substantiate the performance claims. revision: yes
Circularity Check
No circularity: method described as composition of existing components without reduction to fitted inputs or self-citation chains
full rationale
The provided abstract and description present a two-stage pipeline (cross-space dual-branch denoising with voxel decoding + CLIP alignment + SDF blending, followed by view-conditioned texture projection) as an empirical engineering combination of standard diffusion, CLIP, and SDF primitives. No equations, fitted parameters, or 'predictions' are shown that reduce by construction to the inputs. No self-citations or uniqueness theorems are invoked in the visible text. The central claim is therefore an assertion of effectiveness for the described composition, which can be evaluated against external benchmarks without internal circular reduction. This is the normal self-contained case.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CLIP embeddings can reliably guide orientation alignment between two semantic views inside voxel space
- domain assumption SDF blending of voxel-decoded latents produces seamless geometry without post-hoc fixes
Reference graph
Works this paper leans on
-
[1]
Bar-Tal, O., Yariv, L., Lipman, Y., Dekel, T.: Multidiffusion: Fusing diffusion paths for controlled image generation (2023)
2023
-
[2]
arXiv preprint arXiv:1801.01401 (2018)
Bińkowski, M., Sutherland, D.J., Arbel, M., Gretton, A.: Demystifying mmd gans. arXiv preprint arXiv:1801.01401 (2018)
Pith/arXiv arXiv 2018
-
[3]
In: ACM SIGGRAPH 2024 Conference Papers
Burgert, R., Li, X., Leite, A., Ranasinghe, K., Ryoo, M.: Diffusion illusions: Hiding images in plain sight. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[4]
In: Proceedings of the IEEE/CVF international conference on computer vision
Cao, T., Kreis, K., Fidler, S., Sharp, N., Yin, K.: Texfusion: Synthesizing 3d tex- tures with text-guided image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4169–4181 (2023)
2023
-
[5]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chang, P., Sancho, S., Tang, J., Gross, M., Azevedo, V.: Lookingglass: Generative anamorphoses via laplacian pyramid warping. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24–33 (2025)
2025
-
[6]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chen, D.Z., Siddiqui, Y., Lee, H.Y., Tulyakov, S., Nießner, M.: Text2tex: Text- driven texture synthesis via diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 18558–18568 (2023)
2023
-
[7]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chen, R., Chen, Y., Jiao, N., Jia, K.: Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 22246–22256 (2023)
2023
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, T.H., Chen, Y.H., Tu, T., Lee, J.Y., Wu, C.Y., Lin, F., Zhang, H., Paz, D., Huang, X., Guo, Y., et al.: Pantheon360: Taming digital twin generation via 3d-aware 360deg video diffusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11138–11149 (2026)
2026
-
[9]
Advances in Neural Information Processing Systems37, 85045– 85073 (2024)
Chen, Z., Geng, D., Owens, A.: Images that sound: Composing images and sounds on a single canvas. Advances in Neural Information Processing Systems37, 85045– 85073 (2024)
2024
-
[10]
arXiv preprint arXiv:2602.12280 (2026)
Cheng, H.H., Zhang, S.L., Liu, Y.L.: Stroke of surprise: Progressive semantic illu- sions in vector sketching. arXiv preprint arXiv:2602.12280 (2026)
Pith/arXiv arXiv 2026
-
[11]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Cheng, W., Mu, J., Zeng, X., Chen, X., Pang, A., Zhang, C., Wang, Z., Fu, B., Yu, G., Liu, Z., et al.: Mvpaint: Synchronized multi-view diffusion for painting anything 3d. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 585–594 (2025)
2025
-
[12]
Debnath, S., Tiwari, A., Sadekar, K., Raman, S.: Rasp: revisiting 3d anamorphic artforshadow-guidedpackingofirregularobjects.In:ProceedingsoftheComputer Vision and Pattern Recognition Conference. pp. 5849–5858 (2025)
2025
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13142–13153 (2023) 18 S.-L. Zhang et al
2023
-
[14]
In: European conference on computer vision
Deng, K., Omernick, T., Weiss, A., Ramanan, D., Zhu, J.Y., Zhou, T., Agrawala, M.: Flashtex: Fast relightable mesh texturing with lightcontrolnet. In: European conference on computer vision. pp. 90–107. Springer (2024)
2024
-
[15]
ACM Transac- tions on Graphics (TOG)44(4), 1–10 (2025)
Dodik, A., Yu, I., Chandra, K., Ragan-Kelley, J., Tenenbaum, J., Sitzmann, V., Solomon, J.: Meschers: Geometry processing of impossible objects. ACM Transac- tions on Graphics (TOG)44(4), 1–10 (2025)
2025
-
[16]
In: International confer- ence on machine learning
Du, Y., Durkan, C., Strudel, R., Tenenbaum, J.B., Dieleman, S., Fergus, R., Sohl- Dickstein, J., Doucet, A., Grathwohl, W.S.: Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc. In: International confer- ence on machine learning. pp. 8489–8510. PMLR (2023)
2023
-
[17]
arXiv preprint arXiv:2512.05343 (2025)
Fedele, E., Engelmann, F., Huang, I., Litany, O., Pollefeys, M., Guibas, L.: Space- control: Introducing test-time spatial control to 3d generative modeling. arXiv preprint arXiv:2512.05343 (2025)
arXiv 2025
-
[18]
arXiv preprint arXiv:2412.09625 (2024)
Feng, Y., Sanjay, V., Lutz, S., AlBahar, B., Ge, S., Huang, J.B.: Illusion3d: 3d multiview illusion with 2d diffusion priors. arXiv preprint arXiv:2412.09625 (2024)
arXiv 2024
-
[19]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Gao, X., Yang, S., Liu, J.: Ptdiffusion: Free lunch for generating optical illusion hid- den pictures with phase-transferred diffusion model. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 18240–18249 (2025)
2025
-
[20]
In: European Conference on Computer Vision
Geng, D., Park, I., Owens, A.: Factorized diffusion: Perceptual illusions by noise de- composition. In: European Conference on Computer Vision. pp. 366–384. Springer (2024)
2024
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Geng, D., Park, I., Owens, A.: Visual anagrams: Generating multi-view optical illusions with diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24154–24163 (2024)
2024
-
[22]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[23]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[24]
arXiv preprint arXiv:2207.12598 (2022)
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
Pith/arXiv arXiv 2022
-
[25]
arXiv preprint arXiv:2311.04400 (2023)
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400 (2023)
Pith/arXiv arXiv 2023
-
[26]
ACM Trans
Hsiao, K.W., Huang, J.B., Chu, H.K.: Multi-view wire art. ACM Trans. Graph. 37(6), 242 (2018)
2018
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Y.C., Chan, J., Chien, H.J., Liu, Y.L.: Voxify3d: Pixel art meets volumetric rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15398–15410 (2026)
2026
-
[28]
arXiv preprint arXiv:2512.25073 (2025)
Huang, Y.C., Chien, H.J., Lin, C.Y., Chen, Y.H., Liu, Y.L.: Gamo: Geometry- aware multi-view diffusion outpainting for sparse-view 3d reconstruction. arXiv preprint arXiv:2512.25073 (2025)
Pith/arXiv arXiv 2025
-
[29]
URLhttps://doi.org/10.5281/zenodo.5143773
Ilharco, G., Wortsman, M., Wightman, R., Gordon, C., Carlini, N., Taori, R., Dave, A., Shankar, V., Namkoong, H., Miller, J., Hajishirzi, H., Farhadi, A., Schmidt, L.: Openclip (Jul 2021).https://doi.org/10.5281/zenodo.5143773,https://doi. org/10.5281/zenodo.5143773, if you use this software, please cite it as below
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Jain, A., Mildenhall, B., Barron, J.T., Abbeel, P., Poole, B.: Zero-shot text-guided object generation with dream fields. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 867–876 (2022) JanusMesh 19
2022
-
[31]
In: Proceedings of the IEEE/CVF international conference on computer vision
Jain, A., Tancik, M., Abbeel, P.: Putting nerf on a diet: Semantically consistent few-shot view synthesis. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5885–5894 (2021)
2021
-
[32]
arXiv preprint arXiv:2305.02463 (2023)
Jun, H., Nichol, A.: Shap-e: Generating conditional 3d implicit functions. arXiv preprint arXiv:2305.02463 (2023)
Pith/arXiv arXiv 2023
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ke, B.H., Xie, Y.Z., Liu, Y.L., Chiu, W.C.: Stealthattack: Robust 3d gaussian splatting poisoning via density-guided illusions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27400–27411 (2025)
2025
-
[34]
arXiv preprint arXiv:2403.14370 (2024)
Kim, J., Koo, J., Yeo, K., Sung, M.: Synctweedies: A general generative framework based on synchronized diffusions. arXiv preprint arXiv:2403.14370 (2024)
arXiv 2024
-
[35]
arXiv preprint arXiv:2307.04787 (2023)
Kim, S., Lee, K., Choi, J.S., Jeong, J., Sohn, K., Shin, J.: Collaborative score distillation for consistent visual synthesis. arXiv preprint arXiv:2307.04787 (2023)
arXiv 2023
-
[36]
Lan, Y., Zhou, S., Lyu, Z., Hong, F., Yang, S., Dai, B., Pan, X., Loy, C.C.: Gaus- siananything: Interactive point cloud latent diffusion for 3d generation (2025)
2025
-
[37]
arXiv preprint arXiv:2510.15869 (2025)
Lee, J.Y., Liu, Y.R., Tsai, S.R., Chang, W.C., Wu, C.H., Chan, J., Zhao, Z., Lin, C.H., Liu, Y.L.: Skyfall-gs: Synthesizing immersive 3d urban scenes from satellite imagery. arXiv preprint arXiv:2510.15869 (2025)
arXiv 2025
-
[38]
Advances in Neural Information Processing Systems36, 50648–50660 (2023)
Lee, Y., Kim, K., Kim, H., Sung, M.: Syncdiffusion: Coherent montage via syn- chronized joint diffusions. Advances in Neural Information Processing Systems36, 50648–50660 (2023)
2023
-
[39]
arXiv preprint arXiv:2502.00360 (2025)
Li, L., Wang, C., Zhou, Y., Deng, B., Zhang, J.: Shape from semantics: 3d shape generation from multi-view semantics. arXiv preprint arXiv:2502.00360 (2025)
arXiv 2025
-
[40]
Li, L., Wang, C., Zhou, Y., Deng, B., Zhang, J.: Shape from semantics: 3d shape generation from multi-view semantics (2025),https://arxiv.org/abs/2502. 00360
2025
-
[41]
In: European Conference on Computer Vision
Li, M.F., Ku, Y.F., Yen, H.X., Liu, C., Liu, Y.L., Chen, A.Y., Kuo, C.H., Sun, M.: Genrc: Generative 3d room completion from sparse image collections. In: European Conference on Computer Vision. pp. 146–163. Springer (2024)
2024
-
[42]
In: 2025 International Conference on 3D Vision (3DV)
Li, R., Han, J., Melas-Kyriazi, L., Sun, C., An, Z., Gui, Z., Sun, S., Torr, P., Jakab,T.:Dreambeast:Distilling3dfantasticalanimalswithpart-awareknowledge transfer. In: 2025 International Conference on 3D Vision (3DV). pp. 1243–1252. IEEE (2025)
2025
-
[43]
IEEE Transactions on Pattern Analysis and Machine Intel- ligence (2025)
Li, Y., Zou, Z.X., Liu, Z., Wang, D., Liang, Y., Yu, Z., Liu, X., Guo, Y.C., Liang, D., Ouyang, W., et al.: Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models. IEEE Transactions on Pattern Analysis and Machine Intel- ligence (2025)
2025
-
[44]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liang, Y., Yang, X., Lin, J., Li, H., Xu, X., Chen, Y.: Luciddreamer: Towards high- fidelity text-to-3d generation via interval score matching. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6517–6526 (2024)
2024
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Lin, C.H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.Y., Lin, T.Y.: Magic3d: High-resolution text-to-3d content creation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 300–309 (2023)
2023
-
[46]
arXiv preprint arXiv:2210.02747 (2022)
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
Pith/arXiv arXiv 2022
-
[47]
In: European conference on computer vision
Liu, N., Li, S., Du, Y., Torralba, A., Tenenbaum, J.B.: Compositional visual gen- eration with composable diffusion models. In: European conference on computer vision. pp. 423–439. Springer (2022) 20 S.-L. Zhang et al
2022
-
[48]
In: Proceedings of the IEEE/CVF inter- national conference on computer vision
Liu, R., Wu, R., Van Hoorick, B., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero- 1-to-3: Zero-shot one image to 3d object. In: Proceedings of the IEEE/CVF inter- national conference on computer vision. pp. 9298–9309 (2023)
2023
-
[49]
arXiv preprint arXiv:2209.03003 (2022)
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
Pith/arXiv arXiv 2022
-
[50]
arXiv preprint arXiv:2309.03453 (2023)
Liu, Y., Lin, C., Zeng, Z., Long, X., Liu, L., Komura, T., Wang, W.: Syncdreamer: Generating multiview-consistent images from a single-view image. arXiv preprint arXiv:2309.03453 (2023)
Pith/arXiv arXiv 2023
-
[51]
In: SIGGRAPH Asia 2024 Conference Papers
Liu,Y.,Xie,M.,Liu,H.,Wong,T.T.:Text-guidedtexturingbysynchronizedmulti- view diffusion. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[52]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Long, X., Guo, Y.C., Lin, C., Liu, Y., Dou, Z., Liu, L., Ma, Y., Zhang, S.H., Habermann, M., Theobalt, C., et al.: Wonder3d: Single image to 3d using cross- domain diffusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9970–9980 (2024)
2024
-
[53]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Metzer, G., Richardson, E., Patashnik, O., Giryes, R., Cohen-Or, D.: Latent-nerf for shape-guided generation of 3d shapes and textures. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12663– 12673 (2023)
2023
-
[54]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Michel, O., Bar-On, R., Liu, R., Benaim, S., Hanocka, R.: Text2mesh: Text-driven neural stylization for meshes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13492–13502 (2022)
2022
-
[55]
Advances in Neural Information Processing Systems36, 72983–73007 (2023)
Minderer, M., Gritsenko, A., Houlsby, N.: Scaling open-vocabulary object detec- tion. Advances in Neural Information Processing Systems36, 72983–73007 (2023)
2023
-
[56]
ACM Transactions on Graphics28(5), 156–1 (2009)
Mitra, N.J., Pauly, M.: Shadow art. ACM Transactions on Graphics28(5), 156–1 (2009)
2009
-
[57]
ACM Transactions on Graph- ics (TOG)25(3), 527–532 (2006)
Oliva, A., Torralba, A., Schyns, P.G.: Hybrid images. ACM Transactions on Graph- ics (TOG)25(3), 527–532 (2006)
2006
-
[58]
In: ACM SIGGRAPH 2023 conference proceedings
Perroni-Scharf, M., Rusinkiewicz, S.: Constructing printable surfaces with view- dependent appearance. In: ACM SIGGRAPH 2023 conference proceedings. pp. 1–10 (2023)
2023
-
[59]
arXiv preprint arXiv:2209.14988 (2022)
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022)
Pith/arXiv arXiv 2022
-
[60]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Qu, Z., Yang, L., Zhang, H., Xiang, T., Pang, K., Song, Y.Z.: Wired perspectives: Multi-view wire art embraces generative ai. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6149–6158 (2024)
2024
-
[61]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[62]
In: ACM SIGGRAPH 2023 conference proceedings
Richardson, E., Metzer, G., Alaluf, Y., Giryes, R., Cohen-Or, D.: Texture: Text- guided texturing of 3d shapes. In: ACM SIGGRAPH 2023 conference proceedings. pp. 1–11 (2023)
2023
-
[63]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[64]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Sadekar, K., Tiwari, A., Raman, S.: Shadow art revisited: a differentiable ren- dering based approach. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 29–37 (2022)
2022
-
[65]
arXiv preprint arXiv:2308.16512 (2023) JanusMesh 21
Shi,Y.,Wang,P.,Ye,J.,Long,M.,Li,K.,Yang,X.:Mvdream:Multi-viewdiffusion for 3d generation. arXiv preprint arXiv:2308.16512 (2023) JanusMesh 21
Pith/arXiv arXiv 2023
-
[66]
arXiv preprint arXiv:2010.02502 (2020)
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
Pith/arXiv arXiv 2010
-
[67]
arXiv preprint arXiv:2309.16653 (2023)
Tang, J., Ren, J., Zhou, H., Liu, Z., Zeng, G.: Dreamgaussian: Generative gaussian splatting for efficient 3d content creation. arXiv preprint arXiv:2309.16653 (2023)
Pith/arXiv arXiv 2023
-
[68]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Wang, C., Chai, M., He, M., Chen, D., Liao, J.: Clip-nerf: Text-and-image driven manipulation of neural radiance fields. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 3835–3844 (2022)
2022
-
[69]
arXiv preprint arXiv:2411.19161 (2024)
Wang, C., Deng, B., Zhang, J.: Neural shadow art. arXiv preprint arXiv:2411.19161 (2024)
arXiv 2024
-
[70]
Advances in neural information processing systems36, 8406–8441 (2023)
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information processing systems36, 8406–8441 (2023)
2023
-
[71]
In: European conference on computer vision
Wang, Z., Wang, Y., Chen, Y., Xiang, C., Chen, S., Yu, D., Li, C., Su, H., Zhu, J.: Crm: Single image to 3d textured mesh with convolutional reconstruction model. In: European conference on computer vision. pp. 57–74. Springer (2024)
2024
-
[72]
Advances in Neural Information Processing Systems37, 121859–121881 (2024)
Wu, S., Lin, Y., Zhang, F., Zeng, Y., Xu, J., Torr, P., Cao, X., Yao, Y.: Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer. Advances in Neural Information Processing Systems37, 121859–121881 (2024)
2024
-
[73]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21469–21480 (2025)
2025
-
[74]
arXiv preprint arXiv:2404.07191 (2024)
Xu, J., Cheng, W., Gao, Y., Wang, X., Gao, S., Shan, Y.: Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models. arXiv preprint arXiv:2404.07191 (2024)
Pith/arXiv arXiv 2024
-
[75]
arXiv preprint arXiv:2406.03293 (2024)
Yang, X., Chen, C., Yang, X., Liu, F., Lin, G.: Text-to-image rectified flow as plug-and-play priors. arXiv preprint arXiv:2406.03293 (2024)
arXiv 2024
-
[76]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yeh, Y.Y., Huang, J.B., Kim, C., Xiao, L., Nguyen-Phuoc, T., Khan, N., Zhang, C., Chandraker, M., Marshall, C.S., Dong, Z., et al.: Texturedreamer: Image- guided texture synthesis through geometry-aware diffusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4304– 4314 (2024)
2024
-
[77]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yi, T., Fang, J., Wang, J., Wu, G., Xie, L., Zhang, X., Liu, W., Tian, Q., Wang, X.: Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6796–6807 (2024)
2024
-
[78]
ACM Transactions on Graphics (TOG)43(6), 1–14 (2024)
Yu, X., Yuan, Z., Guo, Y.C., Liu, Y.T., Liu, J., Li, Y., Cao, Y.P., Liang, D., Qi, X.: Texgen: a generative diffusion model for mesh textures. ACM Transactions on Graphics (TOG)43(6), 1–14 (2024)
2024
-
[79]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Zeng, X., Chen, X., Qi, Z., Liu, W., Zhao, Z., Wang, Z., Fu, B., Liu, Y., Yu, G.: Paint3d: Paint anything 3d with lighting-less texture diffusion models. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4252–4262 (2024)
2024
-
[80]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.