ARGUSTRACK: A Multi-View Annotation System for Multi-Object Tracking
Pith reviewed 2026-06-27 03:43 UTC · model grok-4.3
The pith
ARGUS-TRACK allows single bird's-eye-view annotations to generate consistent 2D boxes across multiple camera views for multi-object tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
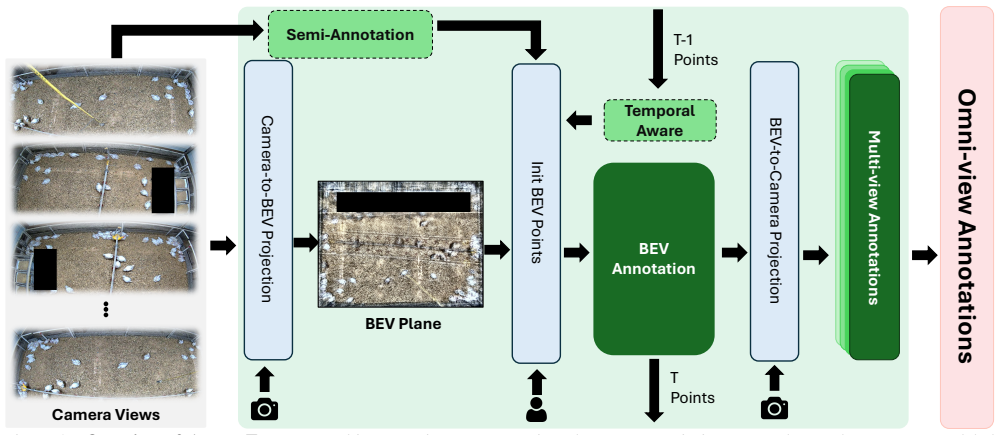
ARGUS-TRACK enables annotators to work directly on a bird's-eye-view (BEV) plane. Given calibrated camera parameters, a single ground-plane annotation is automatically projected into 2D bounding boxes across all relevant views, inherently ensuring identity consistency without manual cross-view alignment. It also includes temporal propagation and semi-automatic candidate generation to speed up the process.
What carries the argument
Bird's-eye-view ground-plane annotation with automatic projection to multiple calibrated camera views using geometric transformation.
If this is right
- Annotation time decreases because only one view needs manual work per object.
- Identity consistency is automatic across cameras.
- The system works for camera-only setups without LiDAR.
- Temporal module reduces adjustments between frames.
Where Pith is reading between the lines
- This approach could extend to other multi-view tasks like 3D reconstruction if projections are accurate.
- Might integrate with more advanced detectors for better semi-annotation.
- Could be tested on human tracking or vehicle tracking datasets.
Load-bearing premise
Accurate camera calibration parameters must be available for the projections to be geometrically correct.
What would settle it
If manual verification shows that projected 2D boxes do not align with actual object positions in the camera images, the automatic projection method fails.
Figures


read the original abstract
Multi-Camera Multi-Target (MCMT) tracking has emerged as a critical capability for applications ranging from autonomous driving to animal behavior monitoring. While recent advances have yielded sophisticated tracking algorithms, the availability of annotated multi-view data remains a significant bottleneck. Existing annotation tools predominantly support single-camera workflows or rely on LiDAR sensors, making cross-view labeling tedious and impractical for camera-only setups. We present ARGUS-TRACK, a multi-camera annotation system that addresses these limitations by enabling annotators to work directly on a bird's-eye-view (BEV) plane. Given calibrated camera parameters, a single ground-plane annotation is automatically projected into 2D bounding boxes across all relevant views, inherently ensuring identity consistency without manual cross-view alignment. To further accelerate the labeling process, ARGUSTRACK incorporates two complementary mechanisms: a Temporal Aware module that propagates annotations from preceding frames to initialize new ones, requiring only minor positional adjustments; and a Multi-camera Semi-annotation module that leverages off-the-shelf 2D detectors combined with foot-point estimation to automatically generate candidate BEV positions for annotator verification. We evaluate ARGUSTRACK through a pilot study on multi-camera broiler tracking and demonstrate that it substantially reduces annotation time compared to conventional single-camera labeling workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ARGUS-TRACK, a multi-camera annotation system for multi-object tracking. Annotators label objects on a bird's-eye-view (BEV) ground plane; given calibrated camera parameters, these labels are automatically projected into 2D bounding boxes across views, enforcing identity consistency. Additional modules provide temporal propagation of annotations and semi-automatic candidate generation via off-the-shelf detectors. A pilot study on multi-camera broiler tracking is reported to show substantially reduced annotation time relative to single-camera workflows.
Significance. If the described workflow functions as claimed, the BEV projection approach offers a practical solution to the cross-view consistency bottleneck in camera-only MCMT annotation, especially for planar scenes such as animal monitoring. The design is geometrically straightforward once calibration is available and the temporal/semi-annotation features are sensible engineering additions. The pilot-study claim of time savings, however, is presented without supporting numbers, limiting the assessed impact.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the claim that the pilot study 'demonstrates that it substantially reduces annotation time' is unsupported because no quantitative results (e.g., mean annotation time per object or frame, number of annotators, baseline single-view times, or statistical comparison) are supplied. This directly weakens the central efficiency claim.
- [System Description] System description: while the projection mechanism is described, there is no analysis of how calibration error propagates into projected box accuracy or identity consistency, nor any reported calibration procedure or tolerance. This is load-bearing for the 'inherently ensuring identity consistency' guarantee.
minor comments (1)
- [Title / Abstract] The system name appears as both 'ARGUSTRACK' and 'ARGUS-TRACK'; adopt a single consistent spelling throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript describing ARGUSTRACK. The points raised identify clear gaps in the presentation of quantitative evidence and system robustness. We respond to each major comment below and will revise the manuscript to address them.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the claim that the pilot study 'demonstrates that it substantially reduces annotation time' is unsupported because no quantitative results (e.g., mean annotation time per object or frame, number of annotators, baseline single-view times, or statistical comparison) are supplied. This directly weakens the central efficiency claim.
Authors: We agree that the submitted manuscript omits the specific quantitative results from the pilot study. Although the study was performed, the numerical details (annotation times, annotator count, baseline comparisons, and statistics) were not reported. In the revised version we will add these figures to both the abstract and evaluation section to support the efficiency claim. revision: yes
-
Referee: [System Description] System description: while the projection mechanism is described, there is no analysis of how calibration error propagates into projected box accuracy or identity consistency, nor any reported calibration procedure or tolerance. This is load-bearing for the 'inherently ensuring identity consistency' guarantee.
Authors: We acknowledge that the manuscript provides neither a description of the calibration procedure nor an analysis of error propagation. These omissions weaken the claim of inherent identity consistency. We will revise the system description to include the calibration method employed in the broiler study and add a discussion of calibration tolerance together with a sensitivity analysis on how errors affect projected box accuracy and identity consistency. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a system description of an annotation tool rather than a derivation of new mathematical results. No equations, fitted parameters, predictions, or self-citation chains appear in the provided text; the projection mechanism is presented as a direct geometric consequence of supplied camera calibration, which is stated as an explicit precondition. The pilot-study timing claim is empirical and does not reduce to any internal fit or definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Camera calibration parameters are available and accurate
Reference graph
Works this paper leans on
-
[1]
Multi-camera tracking of dairy cows using rotated bounding boxes
Shunpei Aou, Yota Yamamoto, Kazuaki Nakamura, and Yukinobu Taniguchi. Multi-camera tracking of dairy cows using rotated bounding boxes. InInternational Workshop on Advanced Imaging Technology (IWAIT) 2024, pages 104–
2024
-
[2]
Label efficient lifelong multi-view broiler detection
Thorsten Cardoen, Sam Leroux, and Pieter Simoens. Label efficient lifelong multi-view broiler detection. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5393–5402, 2024
2024
-
[3]
Multi-camera detection and tracking for individual broiler monitoring.Computers and Electronics in Agricul- ture, 237:110435, 2025
Thorsten Cardoen, Patricia Soster de Carvalho, Gunther Antonissen, Frank AM Tuyttens, Sam Leroux, and Pieter Simoens. Multi-camera detection and tracking for individual broiler monitoring.Computers and Electronics in Agricul- ture, 237:110435, 2025. 1
2025
-
[4]
Rest: A reconfigurable spatial-temporal graph model for multi-camera multi-object tracking
Cheng-Che Cheng, Min-Xuan Qiu, Chen-Kuo Chiang, and Shang-Hong Lai. Rest: A reconfigurable spatial-temporal graph model for multi-camera multi-object tracking. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 10051–10060, 2023. 1
2023
-
[5]
Computer Vision Annotation Tool (CV AT), 2023
CV AT.ai Corporation. Computer Vision Annotation Tool (CV AT), 2023. 2, 4
2023
-
[6]
Camuvid: Calibration-free multi-view de- tection
Amir Etefaghi Daryani, M Bhutta, Byron Hernandez, and Henry Medeiros. Camuvid: Calibration-free multi-view de- tection. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1220–1229, 2025. 1
2025
-
[7]
Ada-track: End-to-end multi-camera 3d multi-object tracking with alternating detection and association
Shuxiao Ding, Lukas Schneider, Marius Cordts, and Juergen Gall. Ada-track: End-to-end multi-camera 3d multi-object tracking with alternating detection and association. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15184–15194, 2024. 1
2024
-
[8]
All-day multi-camera multi-target track- ing
Huijie Fan, Yu Qiao, Yihao Zhen, Tinghui Zhao, Baojie Fan, and Qiang Wang. All-day multi-camera multi-target track- ing. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16892–16901, 2025. 1
2025
-
[9]
Openbox: Annotate any bound- ing boxes in 3d.arXiv preprint arXiv:2512.01352, 2025
In-Jae Lee, Mungyeom Kim, Kwonyoung Ryu, Pierre Musacchio, and Jaesik Park. Openbox: Annotate any bound- ing boxes in 3d.arXiv preprint arXiv:2512.01352, 2025. 2
arXiv 2025
-
[10]
Infrared-visible cross-modal person re-identification with an x modality
Diangang Li, Xing Wei, Xiaopeng Hong, and Yihong Gong. Infrared-visible cross-modal person re-identification with an x modality. InProceedings of the AAAI conference on artifi- cial intelligence, pages 4610–4617, 2020. 1
2020
-
[11]
State-aware re-identification feature for multi-target multi-camera tracking
Peng Li, Jiabin Zhang, Zheng Zhu, Yanwei Li, Lu Jiang, and Guan Huang. State-aware re-identification feature for multi-target multi-camera tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019. 1
2019
-
[12]
Visio- temporal attention for multi-camera multi-target association
Yu-Jhe Li, Xinshuo Weng, Yan Xu, and Kris M Kitani. Visio- temporal attention for multi-camera multi-target association. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9834–9844, 2021. 1
2021
-
[13]
Bayesian loss for crowd count estimation with point super- vision
Zhiheng Ma, Xing Wei, Xiaopeng Hong, and Yihong Gong. Bayesian loss for crowd count estimation with point super- vision. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 6142–6151, 2019. 1
2019
-
[14]
Thinh Phan, Isaac Phillips, Andrew Lockett, Michael T Kidd, and Ngan Le. Trackme: A simple and effective multiple object tracking annotation tool.arXiv preprint arXiv:2410.15518, 2024. 2, 4
arXiv 2024
-
[15]
Kidd, James Ma- son, Santiago Avendano, and Ngan Le
Thinh Phan, Hoang Kim Tran, Andrew Lockett, Isaac Phillips, Hao V o, Duy Le, Michael T. Kidd, James Ma- son, Santiago Avendano, and Ngan Le. Broilertrack: Au- tomatic multi-camera multi-broiler tracking.Smart Agricul- tural Technology, 12:101312, 2025. 1
2025
-
[16]
Earlybird: Early-fusion for multi- view tracking in the bird’s eye view
Torben Teepe, Philipp Wolters, Johannes Gilg, Fabian Her- zog, and Gerhard Rigoll. Earlybird: Early-fusion for multi- view tracking in the bird’s eye view. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 102–111, 2024. 2
2024
-
[17]
Lifting multi-view detection and tracking to the bird’s eye view
Torben Teepe, Philipp Wolters, Johannes Gilg, Fabian Her- zog, and Gerhard Rigoll. Lifting multi-view detection and tracking to the bird’s eye view. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 667–676, 2024. 2
2024
-
[18]
Yolov12: Attention-centric real-time object detectors.arXiv preprint arXiv:2502.12524, 2025
Yunjie Tian, Qixiang Ye, and David Doermann. Yolov12: Attention-centric real-time object detectors.arXiv preprint arXiv:2502.12524, 2025. 2, 3
Pith/arXiv arXiv 2025
-
[19]
Label studio: Data labeling soft- ware, 2020-2025
Maxim Tkachenko, Mikhail Malyuk, Andrey Holmanyuk, and Nikolai Liubimov. Label studio: Data labeling soft- ware, 2020-2025. Open source software available from https://github.com/HumanSignal/label-studio. 2
2020
-
[20]
Yolov8: A novel object detection algorithm with enhanced performance and robust- ness
Rejin Varghese and M Sambath. Yolov8: A novel object detection algorithm with enhanced performance and robust- ness. In2024 International conference on advances in data engineering and intelligent computing systems (ADICS), pages 1–6. IEEE, 2024. 3
2024
-
[21]
Labelme: Image Polygonal Annotation with Python
Kentaro Wada. Labelme: Image Polygonal Annotation with Python. 2
-
[22]
Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
Chien-Yao Wang, Alexey Bochkovskiy, and Hong- Yuan Mark Liao. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7464–7475, 2023. 3
2023
-
[23]
Exploring object-centric temporal modeling for efficient multi-view 3d object detection
Shihao Wang, Yingfei Liu, Tiancai Wang, Ying Li, and Xi- angyu Zhang. Exploring object-centric temporal modeling for efficient multi-view 3d object detection. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 3621–3631, 2023. 1
2023
-
[24]
Multi-camera multi-cow tracking under non-overhead views.Expert Sys- tems with Applications, 291:128519, 2025
Xingshi Xu, Hongxing Deng, Yuying Shang, Yunfei Wang, Shujin Zhang, Diyi Chen, and Huaibo Song. Multi-camera multi-cow tracking under non-overhead views.Expert Sys- tems with Applications, 291:128519, 2025. 1
2025
-
[25]
Entire-barn dairy cow tracking frame- work for multi-camera systems.Computers and Electronics in Agriculture, 229:109668, 2025
Yota Yamamoto, Kazuhiro Akizawa, Shunpei Aou, and Yukinobu Taniguchi. Entire-barn dairy cow tracking frame- work for multi-camera systems.Computers and Electronics in Agriculture, 229:109668, 2025. 1
2025
-
[26]
Walter Zimmer, Akshay Rangesh, and Mohan M. Trivedi. 3d bat: A semi-automatic, web-based 3d annotation toolbox for full-surround, multi-modal data streams. In2019 IEEE Intelligent Vehicles Symposium (IV), pages 1–8. IEEE, 2019. 2
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.