Evaluation of Medical Vision Language Models HuluMed and MedGemma, and general purpose chatbots Gemma 3, ChatGPT Plus, and Claude Pro on real previously unseen wound images
Pith reviewed 2026-06-27 00:39 UTC · model grok-4.3
The pith
General-purpose multimodal models outperform medically specialized ones on wound image analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
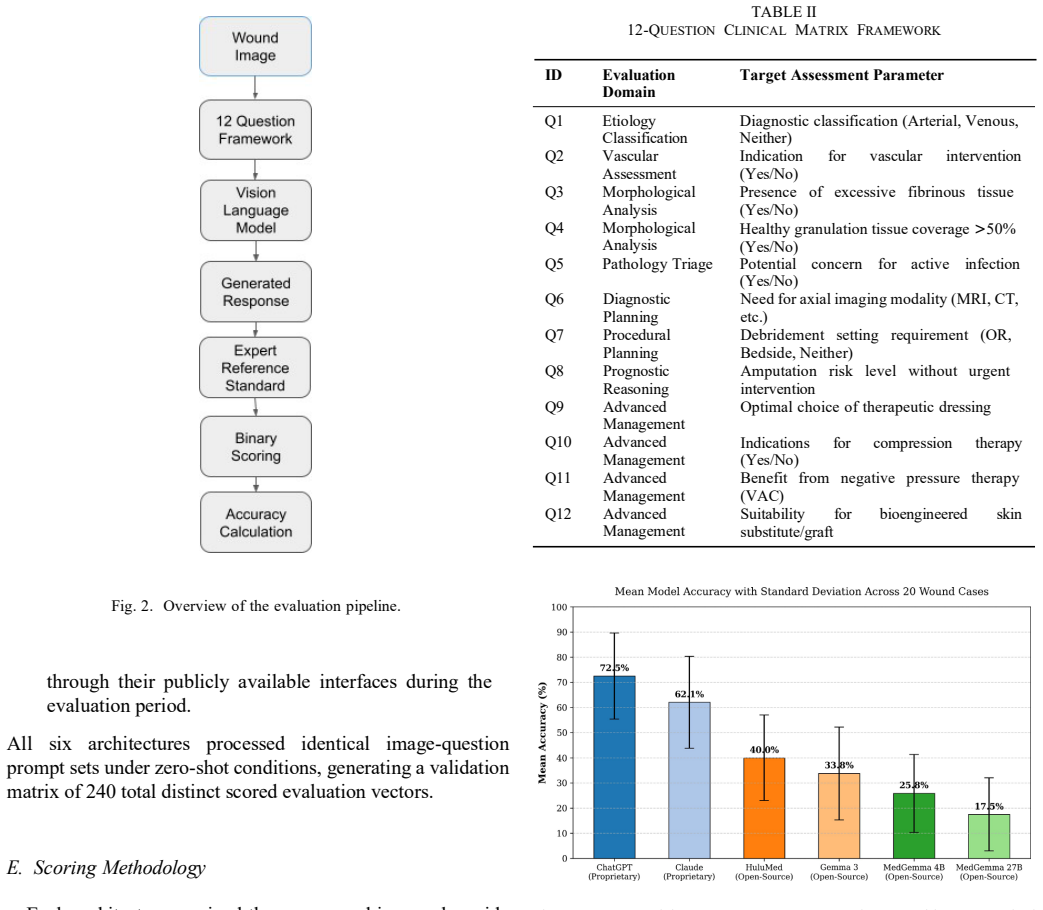
Across the 20 wound cases and 240 clinician-graded decisions, ChatGPT achieved the highest score with 174 correct responses (72.50%), followed by Claude at 149 (62.08%), HuluMed at 96 (40.00%), Gemma 3 at 81 (33.75%), MedGemma 4B at 62 (25.83%), and MedGemma 27B at 42 (17.50%). The paper concludes that frontier general-purpose multimodal systems demonstrate substantially stronger wound-analysis performance than medically specialized alternatives.
What carries the argument
A structured twelve-question clinical framework applied to 20 curated wound images that covers classification, infection risk assessment, vascular intervention recommendations, debridement urgency, wound therapy selection, and advanced management planning.
If this is right
- Broad multimodal reasoning capabilities contribute more to wound analysis accuracy than targeted medical fine-tuning alone.
- Current models, regardless of specialization, remain limited in advanced wound-management reasoning and procedural planning.
- General-purpose frontier systems can serve as stronger baselines for clinical decision support in wound care than existing medical VLMs.
- Domain-specific knowledge without strong general reasoning does not produce superior results on this multimodal task.
Where Pith is reading between the lines
- The performance gap may narrow if medical models receive larger-scale training that preserves broad reasoning ability.
- The same 12-question framework could be reused to compare models on other clinical imaging domains such as dermatology or radiology.
- Hybrid approaches that combine general pretraining with medical data might outperform either category tested here.
Load-bearing premise
The 20 wound cases and the 12-question framework are sufficient to support general claims about relative model capabilities in clinical wound assessment.
What would settle it
A follow-up evaluation on several hundred additional wound images or in a prospective clinical setting in which a medically specialized model matches or exceeds the general-purpose models on the same question set.
Figures
read the original abstract
Chronic wound assessment remains a clinically challenging task that requires accurate interpretation of wound morphology, tissue composition, vascular characteristics, and infection risk. Recent advances in Vision-Language Models (VLMs) have introduced the possibility of automated multimodal wound analysis through image understanding combined with clinical reasoning. This study evaluates the performance of several general-purpose and medically specialized open-source and proprietary VLMs for clinical wound assessment using an expanded, curated dataset of 20 clinically diverse wounds spanning vascular, surgical, ischemic, venous, lymphedema, and amputation-related etiologies. Six VLMs were evaluated using a structured twelve-question clinical framework covering wound classification, infection risk, vascular intervention recommendations, debridement urgency, wound therapy selection, and advanced management planning. Across 20 wound cases and 240 clinician-graded wound-analysis decisions, ChatGPT achieved the highest overall performance with 174/240 correct responses (72.50%), followed by Claude with 149/240 (62.08%). Among the open-source and medically specialized models, HuluMed achieved the strongest performance with 96/240 correct responses (40.00%), followed by Gemma 3 (81/240, 33.75%), MedGemma 4B (62/240, 25.83%), and MedGemma 27B (42/240, 17.50%). The findings suggest that frontier general-purpose multimodal systems currently demonstrate substantially stronger wound-analysis performance than medically specialized alternatives, highlighting the continued importance of broad multimodal reasoning capabilities alongside domain-specific medical knowledge. Although current VLMs demonstrate promising potential for clinical decision support, substantial limitations remain in advanced wound-management reasoning, procedural planning, and autonomous clinical reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates six VLMs (ChatGPT, Claude Pro, Gemma 3, HuluMed, MedGemma 4B, MedGemma 27B) on 20 previously unseen wound images spanning multiple etiologies using a fixed 12-question clinical framework (240 total decisions). It reports exact accuracies (ChatGPT 174/240 = 72.5%, Claude 149/240 = 62.1%, HuluMed 96/240 = 40%, Gemma 3 81/240 = 33.75%, MedGemma 4B 62/240 = 25.83%, MedGemma 27B 42/240 = 17.5%) and concludes that frontier general-purpose multimodal systems substantially outperform medically specialized alternatives on wound analysis tasks.
Significance. If the ranking is robust, the result would demonstrate that broad multimodal reasoning currently outweighs domain-specific medical fine-tuning for this clinical task, providing a concrete empirical benchmark (exact counts on real images) that could guide future VLM development in healthcare. The study ships reproducible question counts and a structured framework that could be extended.
major comments (2)
- [Abstract] Abstract and evaluation description: the central claim that general-purpose models demonstrate 'substantially stronger' performance rests on accuracy differences observed across exactly 20 cases (240 binary decisions) with no reported per-case variance, bootstrap confidence intervals, or statistical significance tests (e.g., McNemar or paired t-test on the 12-question responses), so it is impossible to rule out that the ranking (ChatGPT 72.5% vs HuluMed 40%) is an artifact of the particular 20-image draw.
- [Abstract] Abstract and methods: no details are supplied on case-selection protocol, inter-rater agreement for the clinician ground-truth grades, prompt template consistency across models, or whether any post-hoc filtering occurred, all of which are load-bearing for treating the 174/240, 96/240, etc. counts as stable capability measures rather than sample-specific outcomes.
minor comments (1)
- [Abstract] The abstract lists etiologies but does not tabulate the exact distribution across the 20 cases, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and have revised the manuscript to incorporate additional statistical analyses and methodological details.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the central claim that general-purpose models demonstrate 'substantially stronger' performance rests on accuracy differences observed across exactly 20 cases (240 binary decisions) with no reported per-case variance, bootstrap confidence intervals, or statistical significance tests (e.g., McNemar or paired t-test on the 12-question responses), so it is impossible to rule out that the ranking (ChatGPT 72.5% vs HuluMed 40%) is an artifact of the particular 20-image draw.
Authors: We agree that the lack of statistical tests and variance estimates in the original submission weakens the central claim. In the revised manuscript we have added bootstrap (1000 resamples) 95% confidence intervals for each accuracy and McNemar's tests on the paired 240 decisions. The ChatGPT vs HuluMed difference remains statistically significant (p < 0.001). We also include per-case accuracy breakdowns to show the ranking is not driven by a few outliers. These results are reported in a new Results subsection and supplementary table. revision: yes
-
Referee: [Abstract] Abstract and methods: no details are supplied on case-selection protocol, inter-rater agreement for the clinician ground-truth grades, prompt template consistency across models, or whether any post-hoc filtering occurred, all of which are load-bearing for treating the 174/240, 96/240, etc. counts as stable capability measures rather than sample-specific outcomes.
Authors: We acknowledge these omissions. The revised Methods section now specifies: (1) case-selection protocol (purposive sampling from a de-identified clinical archive to ensure diversity across six etiologies); (2) ground truth was established by a single board-certified wound specialist (we explicitly note the absence of inter-rater agreement as a limitation); (3) the identical prompt template was used for all models (full template provided in the appendix); and (4) no post-hoc filtering was applied. These additions allow readers to assess the stability of the reported counts. revision: yes
Circularity Check
No circularity: pure empirical comparison with no derivations or self-referential fits
full rationale
The paper performs a direct empirical evaluation of six VLMs on 20 fixed wound images using a 12-question framework, scoring responses against external clinician grades (174/240 for ChatGPT, etc.). No equations, parameters, or derivations are present. Claims rest on observed counts rather than any reduction to inputs by construction. Self-citations, if any, are not load-bearing for the ranking result. This matches the default non-circular case for measurement studies.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clinician grading of model responses provides a reliable external measure of clinical correctness.
Reference graph
Works this paper leans on
-
[1]
More recently, open multimodal foundation models such as Gemma 3
have been developed to bridge visual medical interpretation with clinical language reasoning, enabling image understanding, medical visual question answering, and clinical decision-support applications. More recently, open multimodal foundation models such as Gemma 3
-
[2]
have further expanded the accessibility of large -scale vision-language systems for healthcare research. Previous AI -assisted wound -analysis systems primarily focused on segmentation, ulcer detection, tissue classification, and wound measurement using conventional computer vision and deep learning techniques. While these approaches demonstrated utility ...
-
[3]
Betadine
demonstrated the potential of large -scale multimodal learning for clinical image interpretation. Liu et al. [7] conducted a comprehensive benchmarking study comparing general-purpose and medically specialized vision-language contrast, our study evaluates both medically specialized and general -purpose multimodal systems using real previously unseen wound...
-
[4]
LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
C. Wu, C. Wong, S. Zhang, N. Usuyama, H. Liu, J. Yang, T. Naumann, H. Poon, and J. Gao, “LLaVA -Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day,” arXiv preprint arXiv:2306.00890, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
A. Sellergren et al., “MedGemma Technical Report,” arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
arXiv preprint arXiv:2510.08668 (2025)
S. Jiang et al., “Hulu -Med: A Transparent Generalist Model Towards Holistic Medical Vision -Language Understanding,” arXiv preprint arXiv:2510.08668, 2025
-
[7]
Gemma Team, “Gemma 3 Technical Report,” arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Claude Documentation,
Anthropic, “Claude Documentation,” 2025. Available: https://docs. anthropic.com
2025
-
[9]
OpenAI Models Documentation,
OpenAI, “OpenAI Models Documentation,” 2025. Available: https: //platform.openai.com/docs/models
2025
-
[10]
How Far Have Medical Vision-Language Models Come? A Comprehensive Benchmarking Study,
C. Liu et al., “How Far Have Medical Vision-Language Models Come? A Comprehensive Benchmarking Study,” arXiv preprint arXiv:2507.11200, 2025
-
[11]
Benchmarking Vision-Language Models for Diagnostics in Emergency and Critical Care Settings,
C. F. Kurz, T. Merzhevich, B. M. Eskofier, J. N. Kather, and B. Gmeiner, “Benchmarking Vision-Language Models for Diagnostics in Emergency and Critical Care Settings,” npj Digital Medicine , vol. 8, 2025
2025
-
[12]
Med-Flamingo: A Multimodal Medical Few-Shot Learner,
M. Moor, Q. Huang, S. Wu, L. Y. H. Ong, T. Rajpurkar, P. G. Re, and J. Zou, “Med-Flamingo: A Multimodal Medical Few-Shot Learner,” Proceedings of Machine Learning Research, vol. 225, pp. 353– 367, 2023
2023
-
[13]
PMC -VQA: Visual Question Answering Over Medical Images Based on Scientific Literature,
X. Zhang, C. Wu, Z. Zhao, H. Niu, Y. Yu, and F. Wang, “PMC -VQA: Visual Question Answering Over Medical Images Based on Scientific Literature,” Communications Medicine , vol. 4, 2024
2024
-
[14]
PathVQA: 30000+ Questions for Medical Visual Question Answering
X. He, Y. Zhang, L. Mou, E. P. Xing, and P. Xie, “PathVQA: 30000+ Questions for Medical Visual Question Answering,” arXiv preprint arXiv:2003.10286, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[15]
A Dataset of Clinically Generated Visual Questions and Answers About Radiology Images,
J. J. Lau, S. Gayen, A. Ben Abacha, D. Demner -Fushman, and P. Zweigenbaum, “A Dataset of Clinically Generated Visual Questions and Answers About Radiology Images,” Scientific Data , vol. 5, article 180251, 2018
2018
-
[16]
SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Visual Question Answering,
B. Liu, L. M. Zhan, L. Xu, X. Ma, Y. Yang, and X. Wu, “SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Visual Question Answering,” IEEE International Symposium on Biomedical Imaging (ISBI), 2021
2021
-
[17]
Robust Methods for Real -Time Diabetic Foot Ulcer Detection and Localization on Mobile Devices,
M. Goyal, N. D. Reeves, S. Rajbhandari, and M. H. Yap, “Robust Methods for Real -Time Diabetic Foot Ulcer Detection and Localization on Mobile Devices,” IEEE Journal of Biomedical and Health Informatics, vol. 23, no. 4, pp. 1730–1741, 2019
2019
-
[18]
Fully Automatic Wound Segmentation With Deep Convolutional Neural Networks,
C. Wang, D. M. Anisuzzaman, V. Williamson, M. K. Dhar, B. Rostami, J. Niezgoda, S. Gopalakrishnan, and Z. Yu, “Fully Automatic Wound Segmentation With Deep Convolutional Neural Networks,” Scientific Reports, vol. 10, article 21897, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.