D2HDMap: Non-visible Driveline Map Prior for Online Vectorized HD Map Prediction
Pith reviewed 2026-06-26 21:35 UTC · model grok-4.3
The pith
A lightweight non-visible driveline prior guides sensor-based prediction of visible road structures and improves results even when the prior is absent at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
D2HDMap conditions a vectorized map prediction network on a non-visible driveline prior so that the network learns to produce accurate estimates of visible structures; the same training procedure yields networks that retain most of their accuracy when the prior is withheld at inference, reaching 44.8 mAP on a geographically disjoint split while increasing robustness to localization noise.
What carries the argument
The D2HDMap network that fuses the driveline prior into the feature extractor or decoder to condition prediction of visible lane elements.
If this is right
- Prediction accuracy rises on road segments never seen during training.
- The same model can operate with or without the prior at deployment without large performance loss.
- Noise-aware training reduces sensitivity to typical localization drift.
- Map maintenance effort drops because only the driveline layer needs updating rather than full visible markings.
Where Pith is reading between the lines
- Fleets could maintain a single lightweight driveline layer across many vehicles and still obtain most of the benefit of full HD maps.
- The training transfer effect suggests partial map layers might serve as a general way to bootstrap sensor-only systems.
- Similar conditioning could be tested on other sparse priors such as road centerlines or elevation data.
Load-bearing premise
The driveline prior supplies enough geometric guidance that training on it improves estimation of visible structures and that this improvement transfers when the prior is removed at inference.
What would settle it
Run the trained D2HDMap model on the geographically disjoint split with the driveline prior deliberately withheld at inference and measure whether mAP falls to the level of a baseline model that never saw the prior during training.
Figures
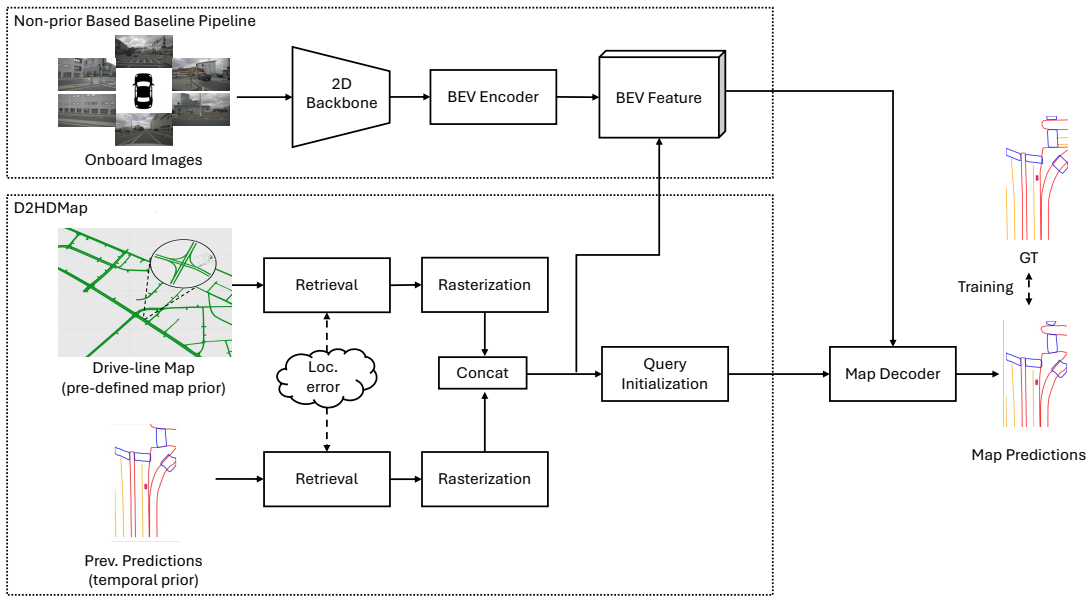

read the original abstract
Accurate, up-to-date representations of road structures are critical for the safe operation of autonomous vehicles. Existing systems rely either on costly, maintenance-heavy high-definition (HD) maps which compromise safety when outdated, or purely sensor-based online mapping which struggles with long-range reliability and occlusion. Systems incorporating map prior information into online mapping seek to overcome drawbacks of both approaches by combining them in some way. We propose 'Driveline To HD Map' (D2HDMap), an online mapping system that injects a lightweight, non-visible driveline prior to guide the estimation of visible road structures such as lane dividers, road boundaries and crosswalks. This prior incurs less effort to create and update compared to full HD map priors used in other approaches. We also show that training with such a prior can improve generalization at inference time when no prior is available. Ablation studies conducted on the nuScenes and Argoverse 2 dataset demonstrate that models trained using a driveline prior largely retain performance even when priors are not available. On a geographically disjoint split, D2HDMap achieves 44.8 mAP, surpassing recent state-of-the-art. Additionally, noise-aware training substantially increases robustness to realistic localization error.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes D2HDMap, an online vectorized HD map prediction system that injects a lightweight non-visible driveline prior to guide estimation of visible road structures (lane dividers, road boundaries, crosswalks). It claims this prior requires less effort to create/maintain than full HD maps, that training with the prior transfers to inference without it, and that noise-aware training improves robustness to localization error. On nuScenes and Argoverse 2, ablation studies show retained performance without the prior at inference; on a geographically disjoint split the method reaches 44.8 mAP, surpassing recent SOTA.
Significance. If the results and transfer claims hold, the work offers a practical middle ground between costly HD-map maintenance and purely sensor-based online mapping, with direct relevance to long-range and occluded perception in autonomous driving. The noise-aware training component and the demonstration of prior-to-no-prior generalization are concrete strengths that could influence future map-prior designs.
major comments (3)
- [Abstract] Abstract: the central performance claim (44.8 mAP on a geographically disjoint split, surpassing SOTA) is stated without reference to any results table, experimental protocol, or baseline numbers, so the claim cannot be evaluated.
- [Abstract] Abstract: the injection mechanism for the driveline prior, the model architecture, and the precise training/inference protocol are not described, leaving the methodological novelty and the training-to-inference transfer claim unverifiable.
- [Abstract] Abstract: the statement that 'models trained using a driveline prior largely retain performance even when priors are not available' is presented without any ablation numbers, controls, or dataset splits, which are load-bearing for the generalization claim.
minor comments (1)
- [Abstract] The abstract mentions ablation studies on nuScenes and Argoverse 2 but does not indicate which dataset supplies the 44.8 mAP figure; a single clarifying sentence would help.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback focused on the abstract. We agree that the abstract can be strengthened for verifiability while preserving conciseness and will revise it in the next manuscript version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim (44.8 mAP on a geographically disjoint split, surpassing SOTA) is stated without reference to any results table, experimental protocol, or baseline numbers, so the claim cannot be evaluated.
Authors: We agree that explicit references improve verifiability. The 44.8 mAP result and SOTA comparisons appear in Table 3 (geographically disjoint splits of nuScenes and Argoverse 2), with the full protocol in Section 4. The revised abstract will include a parenthetical reference to Table 3. revision: yes
-
Referee: [Abstract] Abstract: the injection mechanism for the driveline prior, the model architecture, and the precise training/inference protocol are not described, leaving the methodological novelty and the training-to-inference transfer claim unverifiable.
Authors: Abstract length limits preclude full descriptions, which are provided in Sections 3.2 (prior injection via cross-attention) and 4 (training/inference protocols). To address verifiability, the revised abstract will add one sentence briefly characterizing the lightweight prior fusion and reference Section 3. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'models trained using a driveline prior largely retain performance even when priors are not available' is presented without any ablation numbers, controls, or dataset splits, which are load-bearing for the generalization claim.
Authors: We agree that supporting numbers strengthen the claim. The relevant ablations (performance retention within 0.8 mAP without the prior at inference) are in Table 4 on the same nuScenes/Argoverse 2 splits. The revised abstract will reference Table 4 for these controls. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical online mapping architecture that incorporates a lightweight driveline prior during training. No equations, derivations, or uniqueness theorems appear in the provided text. Performance claims (44.8 mAP on disjoint split, robustness to localization noise) are presented as experimental outcomes on nuScenes and Argoverse 2 rather than as outputs of any self-referential derivation. The central premise—that training with the prior transfers to inference without it—is an empirical generalization claim, not a definitional or fitted-input reduction. No load-bearing self-citation chains or ansatz smuggling are detectable from the abstract or described content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
High-definition maps: Comprehensive survey, chal- lenges, and future perspectives.IEEE Open Journal of Intelligent Transportation Systems, 4:527–550, 2023
Gamal Elghazaly, Rapha¨ el Frank, Scott Harvey, and Stefan Safko. High-definition maps: Comprehensive survey, chal- lenges, and future perspectives.IEEE Open Journal of Intelligent Transportation Systems, 4:527–550, 2023
2023
-
[2]
MapTR: Structured modeling and learning for online vectorized HD map construction
Bencheng Liao, Shaoyu Chen, Xinggang Wang, Tianheng Cheng, Qian Zhang, Wenyu Liu, and Chang Huang. MapTR: Structured modeling and learning for online vectorized HD map construction. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[3]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
2016
-
[4]
Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Maxime Oquab, Timoth´ ee Darcet, Th´ eo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[5]
Hdmapnet: An online hd map construction and evaluation framework
Qi Li, Yue Wang, Yilun Wang, and Hang Zhao. Hdmapnet: An online hd map construction and evaluation framework. In2022 International Conference on Robotics and Automation (ICRA), pages 4628–4634. IEEE, 2022
2022
-
[6]
Vectormapnet: End-to-end vectorized hd map learning
Yicheng Liu, Tianyuan Yuan, Yue Wang, Yilun Wang, and Hang Zhao. Vectormapnet: End-to-end vectorized hd map learning. InInternational Conference on Machine Learning, pages 22352–22369. PMLR, 2023
2023
-
[7]
Maptrv2: An end-to-end framework for online vectorized hd map construction.International Journal of Computer Vision, 133(3):1352–1374, 2025
Bencheng Liao, Shaoyu Chen, Yunchi Zhang, Bo Jiang, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Maptrv2: An end-to-end framework for online vectorized hd map construction.International Journal of Computer Vision, 133(3):1352–1374, 2025
2025
-
[8]
Streammapnet: Streaming mapping network for vectorized online hd map construction
Tianyuan Yuan, Yicheng Liu, Yue Wang, Yilun Wang, and Hang Zhao. Streammapnet: Streaming mapping network for vectorized online hd map construction. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 7356–7365, 2024
2024
-
[9]
Maptracker: Tracking with strided memory fusion for consistent vector hd mapping
Jiacheng Chen, Yuefan Wu, Jiaqi Tan, Hang Ma, and Yasutaka Furukawa. Maptracker: Tracking with strided memory fusion for consistent vector hd mapping. InEuropean Conference on Computer Vision, pages 90–107. Springer, 2024
2024
-
[10]
Jing Yang, Sen Yang, Xiao Tan, and Hanli Wang. Histrackmap: Global vectorized high-definition map construction via history map tracking.arXiv preprint arXiv:2503.07168, 2025
arXiv 2025
-
[11]
Thomas Monninger, Zihan Zhang, Zhipeng Mo, Md Zafar Anwar, Steffen Staab, and Sihao Ding. Mapdiffusion: Gen- erative diffusion for vectorized online hd map construction and uncertainty estimation in autonomous driving.arXiv preprint arXiv:2507.21423, 2025
arXiv 2025
-
[12]
Enhancing vectorized map perception with historical rasterized maps
Xiaoyu Zhang, Guangwei Liu, Zihao Liu, Ningyi Xu, Yunhui Liu, and Ji Zhao. Enhancing vectorized map perception with historical rasterized maps. InEuropean Conference on Computer Vision, pages 422–439. Springer, 2024
2024
-
[13]
Prevpredmap: Exploring temporal modeling with previous predictions for online vectorized hd map construction
Nan Peng, Xun Zhou, Mingming Wang, Xiaojun Yang, Songming Chen, and Guisong Chen. Prevpredmap: Exploring temporal modeling with previous predictions for online vectorized hd map construction. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 8134–8143. IEEE, 2025. 8
2025
-
[14]
Nan Peng, Xun Zhou, Mingming Wang, Guisong Chen, and Wenqi Xu. Uni-prevpredmap: Extending prevpredmap to a unified framework of prior-informed modeling for online vectorized hd map construction.arXiv preprint arXiv:2504.06647, 2025
arXiv 2025
-
[15]
Augmenting lane perception and topology understanding with standard definition navigation maps, 2023
Katie Z Luo, Xinshuo Weng, Yan Wang, Shuang Wu, Jie Li, Kilian Q Weinberger, Yue Wang, and Marco Pavone. Augmenting lane perception and topology understanding with standard definition navigation maps, 2023
2023
-
[16]
P- mapnet: Far-seeing map generator enhanced by both sdmap and hdmap priors.IEEE Robotics and Automation Letters, 2024
Zhou Jiang, Zhenxin Zhu, Pengfei Li, Huan-ang Gao, Tianyuan Yuan, Yongliang Shi, Hang Zhao, and Hao Zhao. P- mapnet: Far-seeing map generator enhanced by both sdmap and hdmap priors.IEEE Robotics and Automation Letters, 2024
2024
-
[17]
Planet dump retrieved from https://planet.osm.org .https://www.openstreetmap.org, 2017
OpenStreetMap contributors. Planet dump retrieved from https://planet.osm.org .https://www.openstreetmap.org, 2017
2017
-
[18]
Neural map prior for autonomous driving
Xuan Xiong, Yicheng Liu, Tianyuan Yuan, Yue Wang, Yilun Wang, and Hang Zhao. Neural map prior for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17535–17544, 2023
2023
-
[19]
Xi Zhu, Xiya Cao, Zhiwei Dong, Caifa Zhou, Qiangbo Liu, Wei Li, and Yongliang Wang. Nemo: Neural map growing system for spatiotemporal fusion in bird’s-eye-view and bdd-map benchmark.arXiv preprint arXiv:2306.04540, 2023
arXiv 2023
-
[20]
Mind the map! accounting for existing maps when estimating online hdmaps from sensors
Remy Sun, Li Yang, Diane Lingrand, and Fr´ ed´ eric Precioso. Mind the map! accounting for existing maps when estimating online hdmaps from sensors. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1671–1681. IEEE, 2025
2025
-
[21]
Deguo Xia, Weiming Zhang, Xiyan Liu, Wei Zhang, Chenting Gong, Xiao Tan, Jizhou Huang, Mengmeng Yang, and Di- ange Yang. Ldmapnet-u: An end-to-end system for city-scale lane-level map updating.arXiv preprint arXiv:2501.02763, 2025
arXiv 2025
-
[22]
Bateman, Ning Xu, H
Samuel M. Bateman, Ning Xu, H. Charles Zhao, Yae Ben Shalon, Vince Gong, Greg Long, and Will Maddern. Exploring real world map change generation for prior-informed hd map prediction models. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR W), 2024
2024
-
[23]
Hitvarth Diwanji, Jing-Yan Liao, Akshar Tumu, Henrik I Christensen, Marcell Vazquez-Chanlatte, and Chikao Tsuchiya. Sd++: Enhancing standard definition maps by incorporating road knowledge using llms.arXiv preprint arXiv:2502.02773, 2025
arXiv 2025
-
[24]
Christensen, Marcell Vazquez-Chanlatte, Chikao Tsuchiya, and Dhaval Bhanderi
Akshar Tumu, Henrik I. Christensen, Marcell Vazquez-Chanlatte, Chikao Tsuchiya, and Dhaval Bhanderi. Using lan- guage and road manuals to inform map reconstruction for autonomous driving, 2025
2025
-
[25]
Fabian Immel, Jan-Hendrik Pauls, Richard Fehler, Frank Bieder, Jonas Merkert, and Christoph Stiller. Sdtagnet: Leveraging text-annotated navigation maps for online hd map construction.arXiv preprint arXiv:2506.08997, 2025
arXiv 2025
-
[26]
Enhancing lane segment perception and topology reasoning with crowdsourcing trajectory priors.IEEE Robotics and Automation Letters, 2025
Peijin Jia, Ziang Luo, Tuopu Wen, Mengmeng Yang, Kun Jiang, Le Cui, and Diange Yang. Enhancing lane segment perception and topology reasoning with crowdsourcing trajectory priors.IEEE Robotics and Automation Letters, 2025
2025
-
[27]
Inferring driving maps by deep learning-based trail map extraction
Michael Hubbertz, Pascal Colling, Qi Han, and Tobias Meisen. Inferring driving maps by deep learning-based trail map extraction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2425–2434, 2025
2025
-
[28]
Junjie Ye, David Paz, Hengyuan Zhang, Yuliang Guo, Xinyu Huang, Henrik I Christensen, Yue Wang, and Liu Ren. Smart: Advancing scalable map priors for driving topology reasoning.arXiv preprint arXiv:2502.04329, 2025
arXiv 2025
-
[29]
Reid, Sarah E
Tyler G.R. Reid, Sarah E. Houts, Robert Cammarata, Graham Mills, Siddharth Agarwal, Ankit Vora, and Gaurav Pandey. Localization requirements for autonomous vehicles.SAE International Journal of Connected and Automated Vehicles, 2(3), September 2019
2019
-
[30]
Enhancing online road network perception and reasoning with standard definition maps
Hengyuan Zhang, David Paz, Yuliang Guo, Arun Das, Xinyu Huang, Karsten Haug, Henrik I Christensen, and Liu Ren. Enhancing online road network perception and reasoning with standard definition maps. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1086–1093. IEEE, 2024
2024
-
[31]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
2020
-
[32]
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, et al. Argoverse 2: Next generation datasets for self- driving perception and forecasting.arXiv preprint arXiv:2301.00493, 2023. 9
Pith/arXiv arXiv 2023
-
[33]
Junjie Huang and Guan Huang. Bevpoolv2: A cutting-edge implementation of bevdet toward deployment.arXiv preprint arXiv:2211.17111, 2022
arXiv 2022
-
[34]
Localization is all you evaluate: Data leakage in online mapping datasets and how to fix it
Adam Lilja, Junsheng Fu, Erik Stenborg, and Lars Hammarstrand. Localization is all you evaluate: Data leakage in online mapping datasets and how to fix it. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22150–22159, 2024. 10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.