REKEY: Metadata-Grounded Visual-Key Regeneration for Contamination-Resilient VQA Evaluation
Pith reviewed 2026-06-26 21:04 UTC · model grok-4.3
The pith
ReKey regenerates the answer-bearing visual detail in VQA items at evaluation time to produce fresh instances with new answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
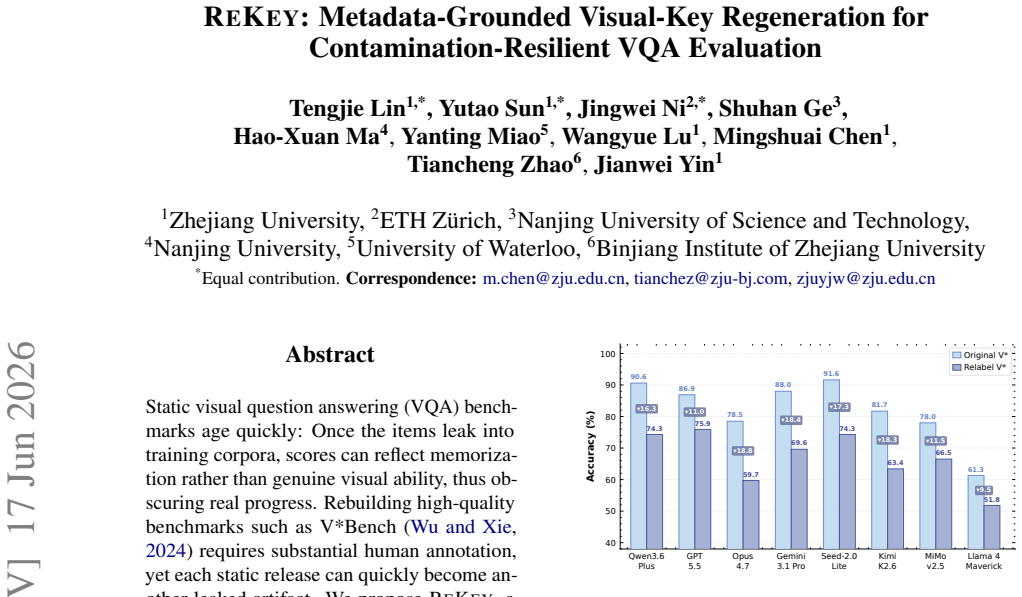
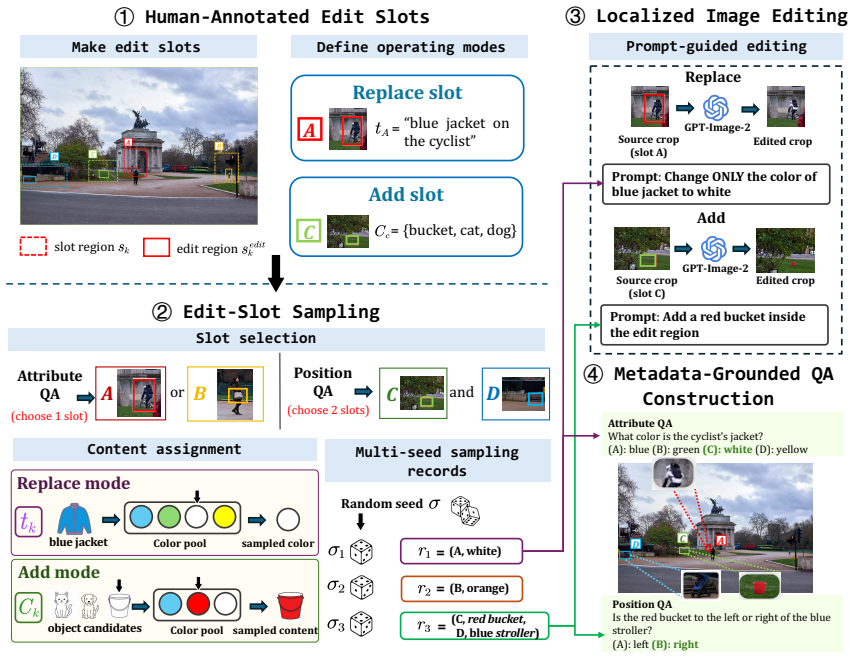
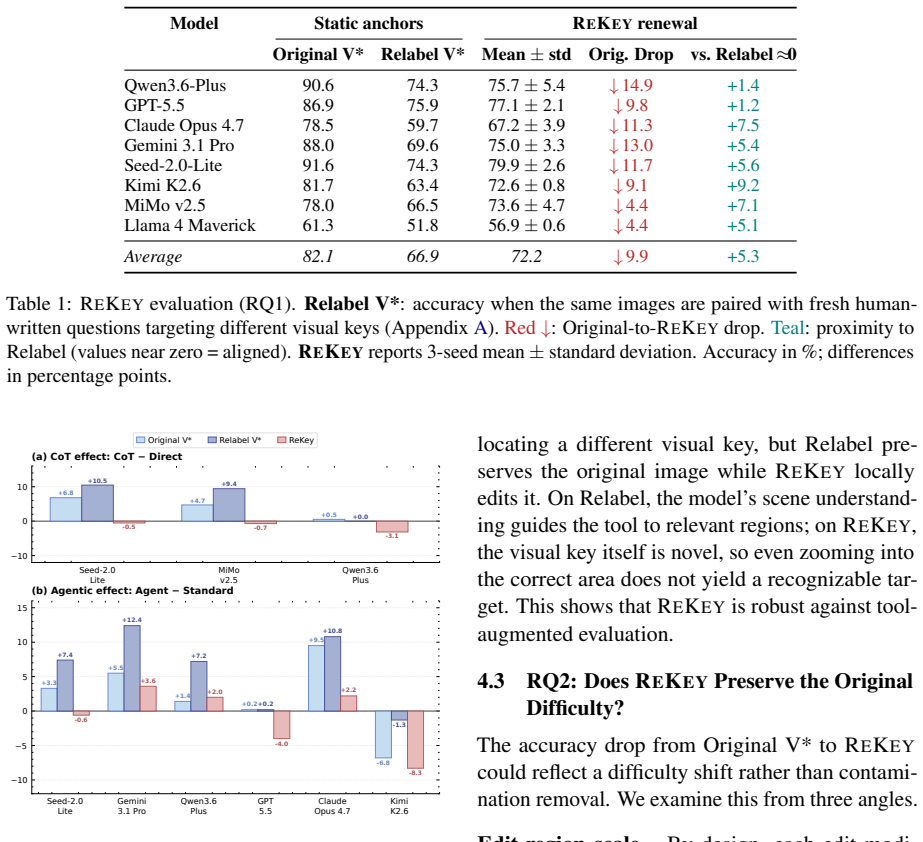
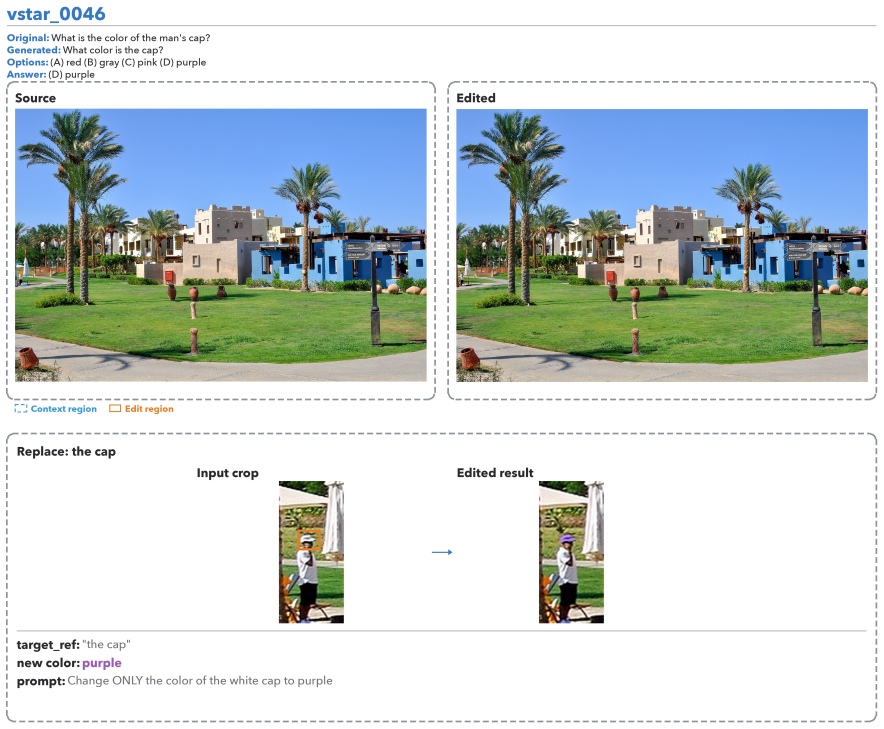
ReKey samples fresh instances by regenerating the visual key inside real images using metadata-grounded edit slots. On the V*Bench items the original versions score 9.5 to 18.8 percentage points higher than the regenerated variants across eight frontier vision-language models. The regenerated instances carry new valid answers while preserving controlled visual-search difficulty and construction-grounded labels.
What carries the argument
visual-key regeneration: the random replacement of the answer-bearing local detail in a real image at evaluation time, guided by human-validated edit slots.
If this is right
- Original V*Bench scores overestimate genuine visual ability by 9.5-18.8 points.
- The same base images can support repeated, non-overlapping evaluations without full human re-annotation.
- Score gaps between original and regenerated items directly quantify contamination for any given model.
- Live regeneration keeps benchmark difficulty stable while answers remain fresh.
Where Pith is reading between the lines
- The same edit-slot mechanism could be applied to other image-based reasoning benchmarks that rely on localized visual evidence.
- Repeated regeneration cycles on one image set would let researchers track whether models improve at genuine visual search or simply learn to handle the regeneration pattern.
- If regeneration proves reliable, benchmark maintainers could release only the edit-slot metadata rather than new full datasets.
Load-bearing premise
Human-validated edit slots produce regenerated instances that keep the same visual-search difficulty, introduce only new valid answers, and avoid unintended changes to the underlying task.
What would settle it
A controlled study in which regenerated items show no consistent score drop relative to originals, or in which new unintended biases appear in model error patterns, would falsify the claim that the regeneration isolates memorization effects.
Figures


read the original abstract
Static visual question answering (VQA) benchmarks age quickly: Once the items leak into training corpora, scores can reflect memorization rather than genuine visual ability, thus obscuring real progress. Rebuilding high-quality benchmarks such as V*Bench requires substantial human annotation, yet each static release can quickly become another leaked artifact. We propose ReKey, a live benchmark protocol that randomly regenerates the answer-bearing local detail, or visual key, in real images at evaluation time. Using human-validated edit slots, ReKey samples fresh instances with new answers, construction-grounded labels, and controlled visual-search difficulty. On V*Bench, the ReKey regenerated benchmark reveals a sharp score jump across eight frontier vision-language models (VLMs): The original items score 9.5--18.8 percentage points higher than the regenerated variants. By making the visual key renewable, ReKey keeps evaluation fresh as models and training data evolve.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReKey, a protocol for live regeneration of VQA benchmarks such as V*Bench. It uses human-validated edit slots on real images to randomly replace the answer-bearing visual key at evaluation time, producing new instances with fresh answers, construction-grounded labels, and asserted controlled visual-search difficulty. Experiments on eight frontier VLMs report that original V*Bench items yield 9.5–18.8 percentage points higher scores than the regenerated variants, which the authors interpret as evidence of contamination.
Significance. If the regenerated instances can be shown to preserve equivalent task demands and visual-search difficulty, ReKey would supply a practical mechanism for keeping static VQA benchmarks fresh against training-data leakage. The approach is notable for attempting to ground regeneration in metadata and human validation rather than synthetic generation, but the current manuscript provides no quantitative validation of the core equivalence assumption.
major comments (3)
- [§3] §3 (Method): The claim that human-validated edit slots achieve 'controlled visual-search difficulty' and 'construction-grounded labels' is load-bearing for the contamination interpretation, yet the section supplies no quantitative validation (e.g., inter-rater reliability on difficulty ratings, human accuracy or response-time parity between original and regenerated items, or ablation across edit types).
- [§4] §4 (Experiments): The headline result (9.5–18.8 pp drop) is reported without statistical tests, confidence intervals, or controls that would rule out systematic increases in search cost or new visual ambiguities introduced by the regeneration procedure.
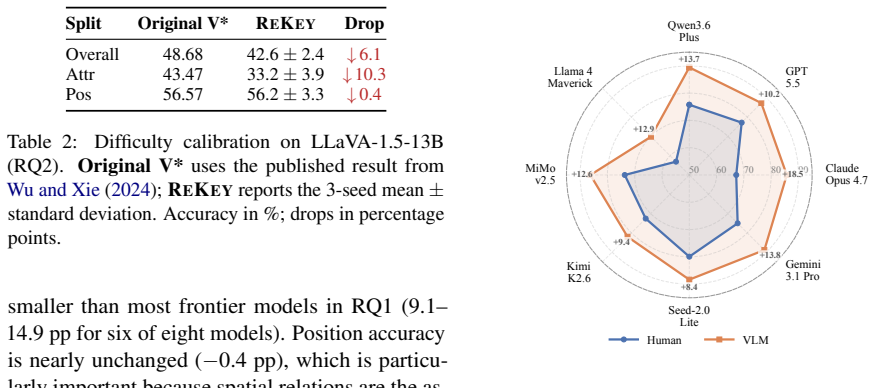
- [§4.2] §4.2 (Model evaluation): No breakdown is given by edit type or by whether regenerated answers remain equally unambiguous; without this, it is impossible to determine whether the observed gap reflects memorization or altered task difficulty.
minor comments (2)
- [Abstract] Abstract: The phrase 'sharp score jump' is imprecise; the reported direction is a drop on regenerated items.
- Notation: The term 'visual key' is used without an explicit formal definition or pointer to the metadata schema that grounds it.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional validation would strengthen the contamination interpretation. We respond to each major comment below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Method): The claim that human-validated edit slots achieve 'controlled visual-search difficulty' and 'construction-grounded labels' is load-bearing for the contamination interpretation, yet the section supplies no quantitative validation (e.g., inter-rater reliability on difficulty ratings, human accuracy or response-time parity between original and regenerated items, or ablation across edit types).
Authors: We agree that quantitative validation of the human-validated edit slots would strengthen the core equivalence assumption. The current §3 describes the metadata-grounded selection and multi-annotator agreement process used to ensure edit slots target the answer-bearing visual key while preserving overall scene coherence, but does not report inter-rater statistics or human performance parity. In the revised manuscript we will add (i) annotator agreement rates on slot selection, (ii) a small-scale human study measuring accuracy and response-time parity between original and regenerated items, and (iii) an ablation across edit types (object replacement vs. attribute change). These additions directly address the load-bearing claim. revision: yes
-
Referee: [§4] §4 (Experiments): The headline result (9.5–18.8 pp drop) is reported without statistical tests, confidence intervals, or controls that would rule out systematic increases in search cost or new visual ambiguities introduced by the regeneration procedure.
Authors: The reported 9.5–18.8 pp gap is computed across eight frontier VLMs on the same underlying images and questions, with only the visual key regenerated. We acknowledge that the current version omits statistical tests and confidence intervals. In revision we will add bootstrap confidence intervals around the per-model differences and paired statistical tests (McNemar’s test) to establish significance. To address potential search-cost or ambiguity confounds, we will also report a control analysis comparing human search difficulty ratings and model attention maps on matched original/regenerated pairs; any systematic increase will be quantified and discussed. revision: yes
-
Referee: [§4.2] §4.2 (Model evaluation): No breakdown is given by edit type or by whether regenerated answers remain equally unambiguous; without this, it is impossible to determine whether the observed gap reflects memorization or altered task difficulty.
Authors: We will expand §4.2 to include a per-edit-type breakdown (object replacement, attribute modification, spatial relation change) with model accuracies reported separately for each category. In addition, we will add a human validation step confirming that the newly generated answers remain equally unambiguous (measured by annotator agreement on the correct answer given the regenerated image). These results will be presented alongside the aggregate gap to allow readers to assess whether the observed difference is attributable to memorization versus unintended difficulty shifts. revision: yes
Circularity Check
No circularity; empirical protocol with external human validation
full rationale
The paper introduces ReKey as a regeneration protocol relying on human-validated edit slots to produce new instances, then reports an empirical observation of score drops (9.5-18.8 pp) on V*Bench. No equations, fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatzes smuggled via prior work appear in the abstract or description. The central claim is a direct measurement rather than a derivation that reduces to its own inputs by construction. The method is self-contained against external human checks and does not invoke uniqueness theorems or rename known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ellis Brown, Jihan Yang, Shusheng Yang, Rob Fergus, and Saining Xie
AutoBench-V: Can large vision- language models benchmark themselves?CoRR, abs/2410.21259. Ellis Brown, Jihan Yang, Shusheng Yang, Rob Fergus, and Saining Xie
-
[2]
Benchmark designers should "train on the test set" to expose exploitable non-visual shortcuts.CoRR, abs/2511.04655. ByteDance Seed Team
-
[3]
Re- cent advances in large language model benchmarks against data contamination: From static to dynamic evaluation.Preprint, arXiv:2502.17521. Paul Gavrikov, Wei Lin, Muhammad Jehanzeb Mirza, Soumya Jahagirdar, Muhammad Huzaifa, Sivan Doveh, Serena Yeung-Levy, James R. Glass, and Hilde Kuehne
-
[4]
Visualoverload: Probing visual understanding of vlms in really dense scenes.CoRR, abs/2509.25339. Gemini Team
-
[5]
InIEEE Conference on Computer Vision and Pattern Recogni- tion, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 6700–6709
GQA: A new dataset for real-world visual reason- ing and compositional question answering. InIEEE Conference on Computer Vision and Pattern Recogni- tion, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 6700–6709. Computer Vision Founda- tion / IEEE. Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ro...
2019
-
[6]
In2017 IEEE Conference on Computer Vi- sion and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 1988–1997
CLEVR: A diagnostic dataset for compositional language and elementary visual rea- soning. In2017 IEEE Conference on Computer Vi- sion and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 1988–1997. IEEE Computer Society. Sua Lee, Sanghee Park, and Jinbae Im
2017
-
[7]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee
Mm- judgebias: A benchmark for evaluating com- positional biases in MLLM-as-a-judge.CoRR, abs/2604.18164. Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee
-
[8]
InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seat- tle, WA, USA, June 16-22, 2024, pages 26286–26296
Improved baselines with visual instruc- tion tuning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seat- tle, WA, USA, June 16-22, 2024, pages 26286–26296. IEEE. Meta AI
2024
-
[9]
InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
Livexiv - A multi-modal live benchmark based on arxiv papers content. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[10]
InFind- ings of the Association for Computational Linguistics: EMNLP 2025, Suzhou, China, November 4-9, 2025, pages 10527–10542
Both text and images leaked! A systematic analysis of data contamination in multimodal LLM. InFind- ings of the Association for Computational Linguistics: EMNLP 2025, Suzhou, China, November 4-9, 2025, pages 10527–10542. Association for Computational Linguistics. Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwar...
2025
-
[11]
LiveBench: A challenging, contamination-limited LLM bench- mark.Preprint, arXiv:2406.19314. Penghao Wu and Saining Xie
-
[12]
InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 13084–13094
V*: Guided visual search as a core mechanism in multimodal LLMs. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 13084–13094. IEEE. Xiaomi MiMo Team
2024
-
[13]
InThe Thir- teenth International Conference on Learning Repre- sentations, ICLR 2025, Singapore, April 24-28,
Dy- namic multimodal evaluation with flexible complex- ity by vision-language bootstrapping. InThe Thir- teenth International Conference on Learning Repre- sentations, ICLR 2025, Singapore, April 24-28,
2025
-
[14]
Junzhe Zhang, Huixuan Zhang, and Xiaojun Wan
OpenReview.net. Junzhe Zhang, Huixuan Zhang, and Xiaojun Wan. 2025a. KBE-DME: Dynamic multimodal evalua- tion via knowledge enhanced benchmark evolution. CoRR, abs/2510.21182. Yifan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, Liang Wang, and Rong Jin. 2025b. Mme-realworld: Could...
arXiv 2025
-
[15]
OpenReview.net. Yusen Zhang, Wenliang Zheng, Aashrith Madasu, Peng Shi, Ryo Kamoi, Hao Zhou, Zhuoyang Zou, Shu Zhao, Sarkar Snigdha Sarathi Das, Vipul Gupta, Xi- aoxin Lu, Nan Zhang, Ranran Haoran Zhang, Avitej Iyer, Renze Lou, Wenpeng Yin, and Rui Zhang. 2025c. Hrscene: How far are vlms from effective high-resolution image understanding? InIEEE/CVF Inter...
2025
-
[16]
In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
Dynamath: A dy- namic visual benchmark for evaluating mathematical reasoning robustness of vision language models. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[17]
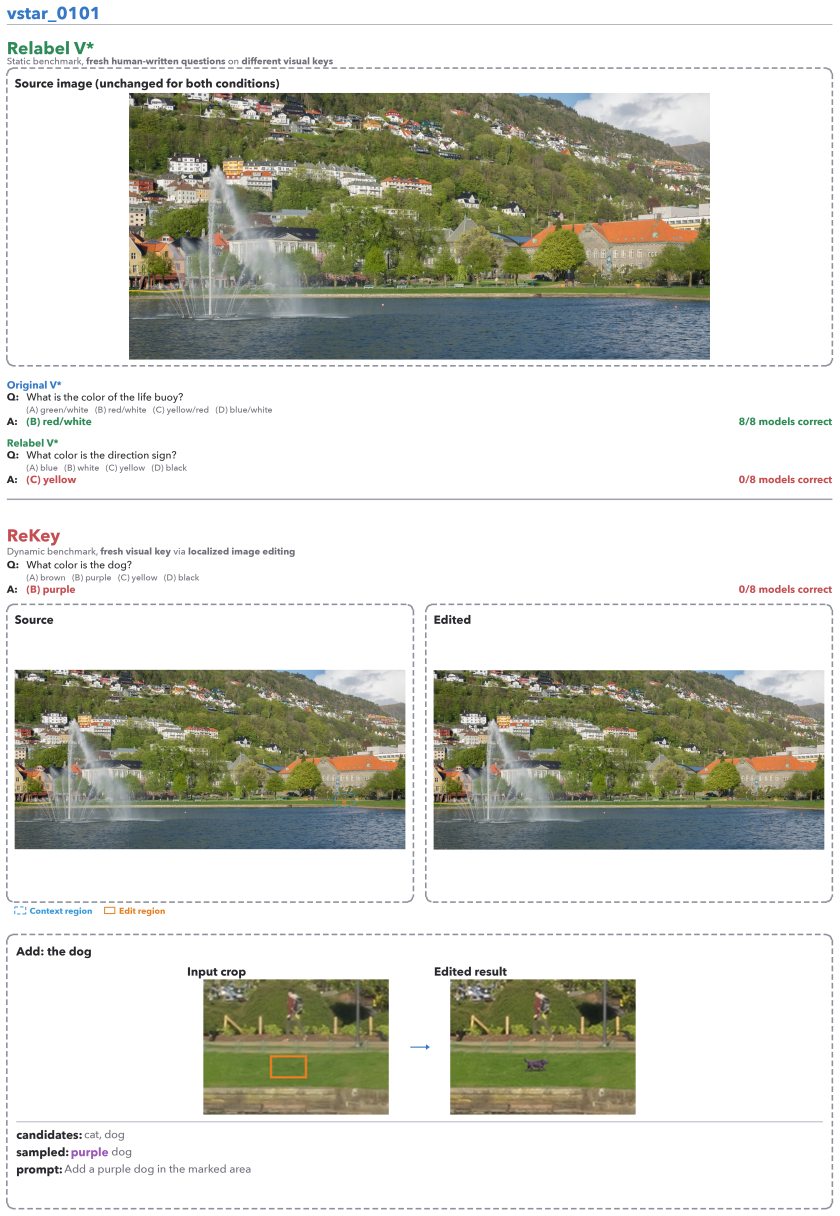
What color is the life buoy?
OpenReview.net. A V*Bench Contamination Audit To measure how much current V*Bench perfor- mance reflects memorization, we constructRela- bel V*: the same 191 images paired with fresh human-written questions that target different visual keys while preserving the original difficulty regime (small, peripheral targets in cluttered scenes). Figure 5 walks thro...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.