NeoLoc-68: End-to-end 68-point neonatal facial landmark localisation in neonatal clinical environments
Pith reviewed 2026-06-26 18:11 UTC · model grok-4.3
The pith
Mixing standardized adult face images with neonatal frames trains the first end-to-end model to locate 68 landmarks on babies in clinical settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
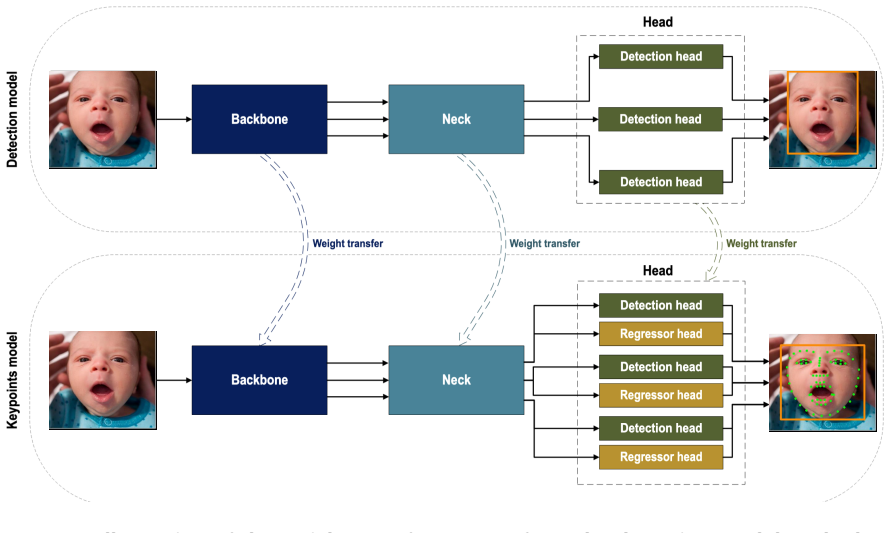
The paper claims that standardizing 37,459 single-face images from 11 public datasets to a 68-point markup and mixing them with 1,123 annotated neonatal frames produces a training set that lets an adapted YOLO-based keypoint model regress 68 landmarks on neonatal faces in clinical conditions, delivering the lowest detection failure rate among tested baselines on a clinical test set before fine-tuning and further gains after fine-tuning, establishing the first end-to-end 68-point neonatal model.
What carries the argument
The YOLO-based keypoint model adapted to regress 68 facial landmarks, initialized with weights from a pretrained neonatal face detector.
If this is right
- The model reaches state-of-the-art numbers on public face datasets using the standardized 68-point markup.
- It generalizes to clinical neonatal images with the lowest failure rate among baselines even before any neonatal fine-tuning.
- Fine-tuning on additional neonatal frames further lowers error rates and failure rates.
- The outputs can feed directly into downstream neonatal health monitoring and facial expression analysis tasks.
Where Pith is reading between the lines
- Similar mixing of public adult data with small specialized sets could reduce the need for large new annotations in other medical imaging domains with limited samples.
- The landmark outputs could support video-based tracking of expression changes over time rather than single frames.
- Deployment in neonatal units might allow continuous non-contact observation of distress signals during routine care.
Load-bearing premise
That standardizing adult images to a shared 68-point scheme and mixing them with limited neonatal frames creates a training distribution whose gap to real clinical neonatal images remains small enough for the observed generalization to hold.
What would settle it
A fresh clinical neonatal test set annotated by separate experts on which the model shows detection failure rates substantially above the reported levels would show the generalization claim does not hold.
Figures


read the original abstract
Facial landmark localisation is a prerequisite for developing automated, non-contact neonatal pain assessment methods. Clinicians use pain scales to judge the severity of pain, many of which rely on facial expression. However, facial landmark detectors trained on adult faces perform poorly in neonatal clinical environments due to frequent occlusions caused by medical equipment, varied head poses, and challenging imaging conditions, including motion blur triggered by sudden pain-related movements. We propose an end-to-end facial landmark detector capable of predicting 68 landmarks on neonatal faces in clinical environments. We combined 37,459 single-face images from 11 public datasets, standardised to 68-point markup, with 1,123 manually annotated frames from a neonatal research dataset (totalling over 76,000 landmarks). A YOLO-based keypoint model was adapted to regress the facial landmarks, initialised with weights from a pretrained neonatal face detector. On public datasets, our proposed model achieved state-of-the-art performance: Normalised Mean Error (NME) = 5.37, Failure Rate (FR) = 12.5%, Area Under the Cumulative Error Curve (AUC) at AUC0.08 = 38.00% and AUC0.1 = 48.70%. On the clinical neonatal test set, before fine-tuning, the model achieved the lowest Detection Failure Rate (DFR) = 5.3% among all baselines and showed strong generalisation. After fine-tuning, performance improved further to NME = 6.36, FR = 22.30%, DFR = 1.77%, AUC0.08 = 29.24% and AUC0.1 = 40.25%. To the best of our knowledge, this represents the first end-to-end 68-point neonatal facial landmark detection model. With further dataset expansion and refinement, it could support downstream tasks in neonatal health monitoring and pain-related facial analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NeoLoc-68, claimed as the first end-to-end 68-point facial landmark detector for neonatal faces in clinical environments. It trains a YOLO-based keypoint regressor on 37,459 images from 11 public (mostly adult) datasets standardized to 68-point markup plus 1,123 manually annotated neonatal frames, initialized from pretrained neonatal face detector weights. Reported results include SOTA on public datasets (NME=5.37, FR=12.5%, AUC0.08=38.00%) and strong generalization on a held-out clinical neonatal test set (DFR=5.3% before fine-tuning; after fine-tuning NME=6.36, FR=22.30%, DFR=1.77%).
Significance. If the generalization results hold after addressing verification gaps, the work would be significant for enabling non-contact neonatal pain assessment via facial expression analysis under real clinical conditions (occlusions, motion blur, varied poses). The mixed-dataset training strategy and multi-metric evaluation (including DFR and AUC) are positive aspects; however, the absence of protocol details limits immediate utility for downstream tasks.
major comments (2)
- [Data section] Data section: The standardization of 37,459 images from 11 heterogeneous public datasets to a common 68-point markup is described at a high level but supplies no explicit landmark mapping, inter-annotator agreement, or geometric consistency checks against neonatal anatomy. This is load-bearing for the central generalization claim (DFR=5.3% on unseen clinical neonatal frames before fine-tuning), as systematic offsets from adult-to-68 conversion could be absorbed into the regressor without true domain transfer.
- [Experiments section] Experiments section: The manuscript reports numeric performance metrics, SOTA claims, and baseline comparisons but provides no experimental protocol, train-test split information, baseline implementation details, or error analysis. This prevents verification of the reported results (e.g., pre-fine-tune DFR=5.3% and post-fine-tune metrics) and undermines the soundness of the generalization statements.
minor comments (1)
- [Abstract] Abstract: The parenthetical '(totalling over 76,000 landmarks)' appears to count only the 1,123 neonatal frames (≈76k landmarks) while omitting the contribution from the 37,459 public images; this is a minor arithmetic/presentation inconsistency.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for improving the clarity and verifiability of our work. We address each major comment point-by-point below and commit to revisions that will strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Data section] The standardization of 37,459 images from 11 heterogeneous public datasets to a common 68-point markup is described at a high level but supplies no explicit landmark mapping, inter-annotator agreement, or geometric consistency checks against neonatal anatomy. This is load-bearing for the central generalization claim (DFR=5.3% on unseen clinical neonatal frames before fine-tuning), as systematic offsets from adult-to-68 conversion could be absorbed into the regressor without true domain transfer.
Authors: We acknowledge that the Data section currently provides only a high-level description of the standardization process. To directly address this concern and support the generalization results, the revised manuscript will include an expanded Data section with explicit per-dataset landmark mappings to the 68-point format, available inter-annotator agreement statistics for the manually annotated neonatal frames, and a description of the geometric consistency checks applied during standardization to align with neonatal anatomy. These additions will clarify that the reported pre-fine-tuning DFR reflects genuine domain transfer rather than absorbed offsets. revision: yes
-
Referee: [Experiments section] The manuscript reports numeric performance metrics, SOTA claims, and baseline comparisons but provides no experimental protocol, train-test split information, baseline implementation details, or error analysis. This prevents verification of the reported results (e.g., pre-fine-tune DFR=5.3% and post-fine-tune metrics) and undermines the soundness of the generalization statements.
Authors: We agree that the absence of detailed experimental protocol information limits independent verification. In the revised manuscript, we will add a new Experimental Protocol subsection that specifies the train-test splits used for the public datasets and the held-out neonatal test set, full implementation details and hyperparameters for all baselines, the exact training procedure including initialization from the neonatal face detector, and an error analysis with qualitative examples of failure cases. This will enable full reproduction and verification of all reported metrics, including the pre- and post-fine-tuning DFR, NME, FR, and AUC values. revision: yes
Circularity Check
No circularity; empirical evaluation on held-out sets
full rationale
The paper reports an ML training and evaluation pipeline for a YOLO-based keypoint regressor on a mixed adult+neonatal dataset, with performance measured via standard metrics (NME, FR, DFR, AUC) on explicitly held-out clinical neonatal test frames. No equations, derivations, or 'predictions' appear that reduce to fitted parameters or self-definitions by construction. No load-bearing self-citations or uniqueness theorems are invoked. The central claims rest on external test-set results rather than any internal redefinition or renaming of inputs, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
free parameters (1)
- pretrained neonatal face detector weights
axioms (1)
- domain assumption Public adult face datasets can be standardized to the same 68-point markup and combined with neonatal frames without introducing systematic label noise or domain mismatch that invalidates clinical generalization
Reference graph
Works this paper leans on
-
[1]
Facial landmark detection: A literature survey
Yue Wu and Qiang Ji. Facial landmark detection: A literature survey. International Journal of Computer Vision, 127(2):115–142, Feb 2019. doi: 10.1007/s11263-018-1097-z
-
[2]
InfanFace: Bridging the infant–adult domain gap in facial landmark estimation in the wild
Meng Wan, Shu Zhu, Lei Luan, Gaurav Prateek, Xiaoming Huang, Rebecca Schwartz- Mette, Michelle Hayes, Eugene Zimmerman, and Sarah Ostadabbas. InfanFace: Bridging the infant–adult domain gap in facial landmark estimation in the wild. In Proceedings of the 26th International Conference on Pattern Recognition (ICPR), pages 4486–4492. IEEE, 2022
2022
-
[3]
Ashraf, Melissa E
Azadeh Asgarian, Shaundra Zhao, Afsaneh B. Ashraf, Melissa E. Browne, Kenneth M. Prkachin, Alex Mihailidis, Thomas Hadjistavropoulos, and Babak Taati. Limitations and biases in facial landmark detection: An empirical study on older adults with dementia. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW),...
2019
-
[4]
Donald F. Huelke. An overview of anatomical considerations of infants and children in the adult world of automobile safety design. In Annual Proceedings of the Association for the Advancement of Automotive Medicine, volume 42, pages 93–113, 1998
1998
-
[5]
Du- mont, and Farzaneh Marzbanrad
Evan Grooby, Chhama Sitaula, Sogand Ahani, Liisa Holsti, Ayush Malhotra, Guy A. Du- mont, and Farzaneh Marzbanrad. Neonatal face and facial landmark detection from video recordings. In 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC) , pages 1–5. IEEE, Jul 2023
2023
-
[6]
Fast facial landmark detection and appli- cations: A survey
Kostiantyn Khabarlak and Larysa Koriashkina. Fast facial landmark detection and appli- cations: A survey. Journal of Computer Science and Technology , 22:e02, Apr 2022. URL https://journal.info.unlp.edu.ar/JCST/article/view/1972
2022
-
[7]
One millisecond face alignment with an ensemble of regression trees
Vahid Kazemi and Josephine Sullivan. One millisecond face alignment with an ensemble of regression trees. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1867–1874, 2014. doi: 10.1109/CVPR.2014.241
-
[8]
Davis E. King. Dlib-ml: A machine learning toolkit. Journal of Machine Learning Research, 10:1755–1760, Dec 2009
2009
-
[9]
How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks)
Adrian Bulat and Georgios Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks). In Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages 1021–1030, 2017
2017
-
[10]
Stacked hourglass networks for human pose estimation
Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision (ECCV) , pages 483–499, Cham, Sep 2016. Springer International Publishing. 26
2016
-
[11]
Binarized convolutional landmark localizers for human pose estimation and face alignment with limited resources
Adrian Bulat and Georgios Tzimiropoulos. Binarized convolutional landmark localizers for human pose estimation and face alignment with limited resources. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages 3706–3714, 2017
2017
-
[12]
Haibo Jin, Shengcai Liao, and Ling Shao. Pixel-in-pixel net: Towards efficient facial land- mark detection in the wild.International Journal of Computer Vision, 129(12):3174–3194, Dec 2021. doi: 10.1007/s11263-021-01500-9
-
[13]
Antonio Prados-Torreblanca, José M. Buenaposada, and Luis Baumela. Shape preserving facial landmarks with graph attention networks, 2022. URL https://arxiv.org/abs/ 2210.07233. [Preprint]. Posted 2022 Oct 13
arXiv 2022
-
[14]
Deep high-resolution representation learning for visual recognition
Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yunchao Zhao, Dong Liu, Yintang Mu, Mingkui Tan, Xinggang Wang, and Wenyu Liu. Deep high-resolution representation learning for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(10):3349–3364, Apr 2020. doi: 10.1109/TPAMI.2020.2983686
-
[15]
Bo Huang, Wei Chen, Chih-Lin Lin, Chia-Feng Juang, Yue Xing, Yuzhu Wang, and Jun Wang. A neonatal dataset and benchmark for non-contact neonatal heart rate monitoring based on spatio-temporal neural networks. Engineering Applications of Artificial Intelligence , 106:104447, Nov 2021. doi: 10.1016/j.engappai.2021.104447
-
[16]
Sheryl Brahnam, Loris Nanni, Steven McMurtrey, Alessandra Lumini, Ryan Brattin, Mary Slack, and Trevor Barrier . Neonatal pain detection in videos using the icopevid dataset and an ensemble of descriptors extracted from gaussian of local descriptors. Applied Computing and Informatics, 19(1/2):122–143, 2023. doi: 10.1108/ACI-05-2021-0142
-
[17]
300 faces in-the-wild challenge: The first facial landmark localization challenge
Christos Sagonas, Georgios Tzimiropoulos, Stefanos Zafeiriou, and Maja Pantic. 300 faces in-the-wild challenge: The first facial landmark localization challenge. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW) , pages 397– 403, 2013
2013
-
[18]
Xm2vtsdb: The extended m2vts database
Kieron Messer, Jiri Matas, Josef Kittler, Juergen Luettin, and Gilbert Maitre. Xm2vtsdb: The extended m2vts database. In Second International Conference on Audio- and Video- Based Biometric Person Authentication (AVBPA), volume 964, pages 965–966, Mar 1999
1999
-
[19]
Ralph Gross, Iain Matthews, Jeffrey Cohn, Takeo Kanade, and Simon Baker . Multi-pie. Image and Vision Computing , 28(5):807–813, 2010. ISSN 0262-8856. doi: 10.1016/j. imavis.2009.08.002. Best of Automatic Face and Gesture Recognition 2008
work page doi:10.1016/j 2010
-
[20]
Jonathon Phillips, Patrick J
P . Jonathon Phillips, Patrick J. Flynn, Todd Scruggs, Kevin W . Bowyer, Jin Chang, Kevin Hoffman, Joe Marques, Jaesik Min, and William Worek. Overview of the face recogni- tion grand challenge. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), volume 1, pages 947–954. IEEE, Jun 2005. 27
2005
-
[21]
Peter N. Belhumeur, David W . Jacobs, David J. Kriegman, and Neeraj Kumar . Localizing parts of faces using a consensus of exemplars. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(12):2930–2940, 2013. doi: 10.1109/TPAMI.2013.23
-
[22]
Vu Le, Jonathan Brandt, Zhe Lin, Lubomir Bourdev, and Thomas S. Huang. Interactive facial feature localization. In European Conference on Computer Vision (ECCV) , pages 679–692, Berlin, Heidelberg, Oct 2012. Springer
2012
-
[23]
Face detection, pose estimation, and landmark local- ization in the wild
Xiaozhu Zhu and Deva Ramanan. Face detection, pose estimation, and landmark local- ization in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2879–2886. IEEE, Jun 2012
2012
-
[24]
300 faces in-the-wild challenge: Database and results
Christos Sagonas, Epameinondas Antonakos, Georgios Tzimiropoulos, Stefanos Zafeiriou, and Maja Pantic. 300 faces in-the-wild challenge: Database and results. Image and Vision Computing, 47:3–18, Mar 2016. doi: 10.1016/j.imavis.2015.11.005
-
[25]
Burgos-Artizzu, Pietro Perona, and Piotr Dollár
Xavier P . Burgos-Artizzu, Pietro Perona, and Piotr Dollár . Robust face landmark estimation under occlusion. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 1513–1520, 2013
2013
-
[26]
The menpo facial landmark localisation challenge: A step towards the solution
Stefanos Zafeiriou, George Trigeorgis, Grigorios Chrysos, Jiankang Deng, and Jiaxiang Shen. The menpo facial landmark localisation challenge: A step towards the solution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Work- shops (CVPRW), pages 170–179, 2017
2017
-
[27]
Look at boundary: A boundary-aware face alignment algorithm
Wayne Wu, Chen Qian, Shuo Yang, Quan Wang, Yunde Cai, and Qiang Zhou. Look at boundary: A boundary-aware face alignment algorithm. In Proceedings of the IEEE Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 2129–2138, 2018
2018
-
[28]
Cobo, Frances Moultrie, Aislinn G
Maria M. Cobo, Frances Moultrie, Aislinn G. Hauck, David Crankshaw, Victoria Monk, Caroline Hartley, Rebecca E. Fry, Sinéad Robinson, Maartje van der Vaart, Lucy Baxter, and Emma Adams. Multicentre, randomised controlled trial to investigate the effects of parental touch on relieving acute procedural pain in neonates (petal). BMJ Open, 12(7): e061841, Jul 2022
2022
-
[29]
Effect of parental touch on relieving acute procedural pain in neonates and parental anx- iety (petal): a multicentre, randomised controlled trial in the uk
Annalisa GV Hauck, Marianne van der Vaart, Eleri Adams, Luke Baxter, Aomesh Bhatt, Daniel Crankshaw, Amraj Dhami, Ria Evans Fry, Marina BO Freire, Caroline Hartley, et al. Effect of parental touch on relieving acute procedural pain in neonates and parental anx- iety (petal): a multicentre, randomised controlled trial in the uk. The Lancet Child & Adolesce...
2024
-
[30]
The premature infant pain profile-revised (pipp-r): initial validation and feasibility
Bonnie J Stevens, Sharyn Gibbins, Janet Yamada, Kimberley Dionne, Grace Lee, Céleste Johnston, and Anna Taddio. The premature infant pain profile-revised (pipp-r): initial validation and feasibility. The Clinical journal of pain , 30(3):238–243, 2014. 28
2014
-
[31]
Sample and compu- tation redistribution for efficient face detection, 2021
Jia Guo, Jiankang Deng, Alexandros Lattas, and Stefanos Zafeiriou. Sample and compu- tation redistribution for efficient face detection, 2021. URL https://arxiv.org/abs/ 2105.04714. [Preprint]. Posted 2021 May 10
arXiv 2021
-
[32]
Dsfd: Dual shot face detector
Jian Li, Yabiao Wang, Changan Wang, Ying Tai, Jun Qian, Jilin Yang, Chengjie Wang, Jinhui Li, and Feiyue Huang. Dsfd: Dual shot face detector . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5060–5069, 2019
2019
-
[33]
Joint face detection and align- ment using multitask cascaded convolutional networks
Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, and Yu Qiao. Joint face detection and align- ment using multitask cascaded convolutional networks. IEEE Signal Processing Letters , 23(10):1499–1503, Oct 2016. doi: 10.1109/LSP.2016.2603342
-
[34]
Computer vision annotation tool (cvat), 2023
CVAT .ai Corporation. Computer vision annotation tool (cvat), 2023. URL https:// github.com/cvat-ai/cvat
2023
-
[35]
Ultralytics yolo, Jan 2023
Glenn Jocher, Jing Qiu, and Ayush Chaurasia. Ultralytics yolo, Jan 2023. URL https: //github.com/ultralytics/ultralytics
2023
-
[36]
Pfld: A practical facial landmark detector, 2019
Xinyao Guo, Shuling Li, Jianzhuang Yu, Jizheng Zhang, Jing Ma, Lizhuang Ma, Wei Liu, and Haibin Ling. Pfld: A practical facial landmark detector, 2019. URL https://arxiv.org/ abs/1902.10859. [Preprint]. Posted 2019 Feb 28
Pith/arXiv arXiv 2019
-
[37]
Wing loss for robust facial landmark localisation with convolutional neural networks
Zhen-Hua Feng, Josef Kittler, Muhammad Awais, Patrick Huber, and Xiao-Jun Wu. Wing loss for robust facial landmark localisation with convolutional neural networks. In Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 2235–2245, 2018
2018
-
[38]
Structured landmark detection via topology- adapting deep graph learning
Weizhe Li, Yibo Lu, Kang Zheng, Hui Liao, Chun Lin, Jing Luo, Chih-Ting Cheng, Jing Xiao, Le Lu, Chen-Feng Kuo, and Shun Miao. Structured landmark detection via topology- adapting deep graph learning. In European Conference on Computer Vision (ECCV), pages 266–283. Springer International Publishing, Cham, Aug 2020
2020
-
[39]
InfantFace
Ming Zhu, Deyu Shi, Min Zheng, and Muhammad Sadiq. Robust facial landmark detection via occlusion-adaptive deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3486–3496, 2019. 29 Supplementary Material Preprint submitted to arXiv. This manuscript is a preprint and has not yet been peer reviewed...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.