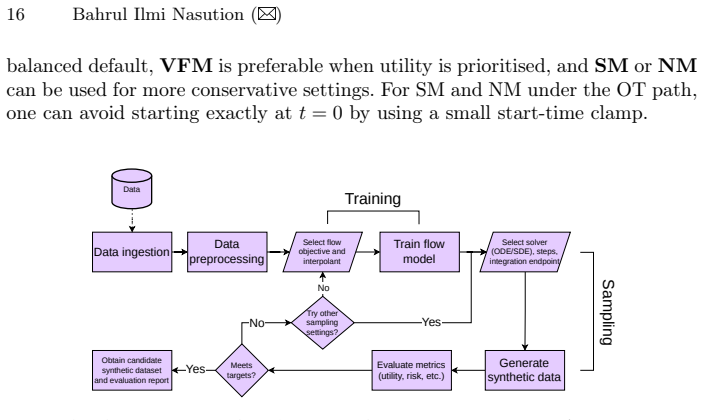
Understanding Latent Flow Models for Tabular Data Synthesis: Targets, Paths, and Sampling
Pith reviewed 2026-06-26 18:04 UTC · model grok-4.3
The pith
The learning target in latent flow models for tabular synthesis sets the utility-risk operating regime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
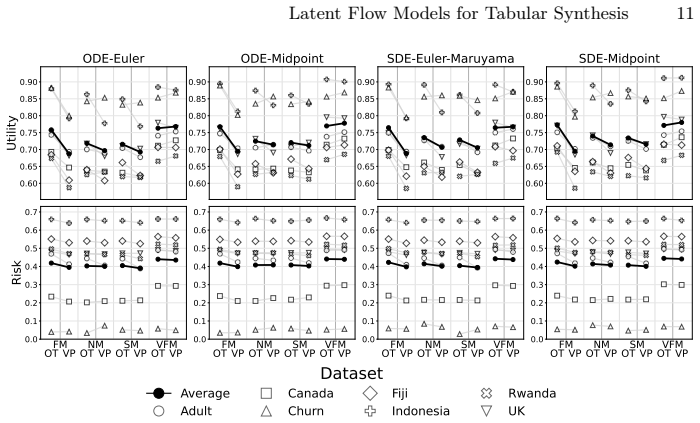
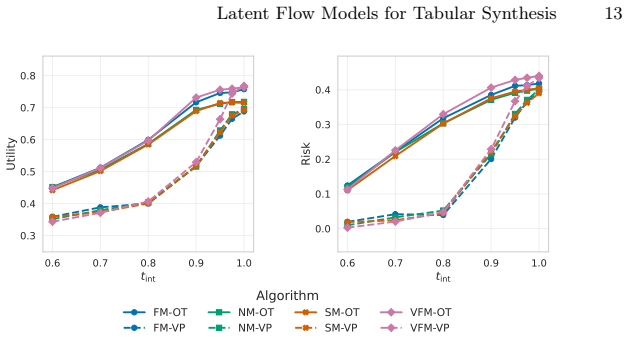
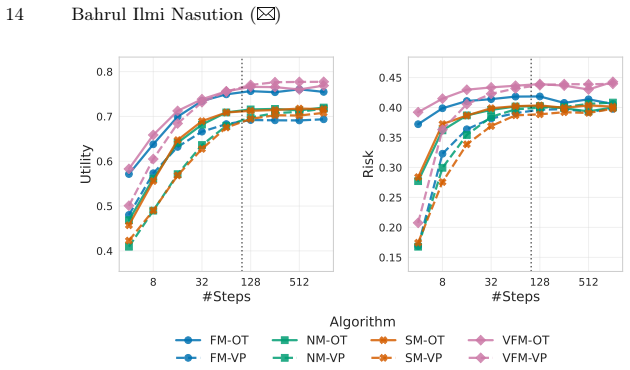
The learning target largely determines the utility-risk operating regime, with velocity and posterior matching tending to yield higher utility, while score and noise matching tend to achieve lower disclosure risk. Midpoint sampling often improves distributional fidelity, and OT paths often tolerate earlier stopping than VP paths, enabling compute savings under fixed budgets or risk thresholds.
What carries the argument
The learning target (velocity, score, noise, or posterior matching) that defines the training objective of the continuous-time flow model in latent space.
If this is right
- Velocity and posterior matching tend to produce higher analytical utility.
- Score and noise matching tend to produce lower disclosure risk.
- Midpoint sampling often improves distributional fidelity.
- OT paths often allow earlier stopping than VP paths under fixed budgets.
Where Pith is reading between the lines
- Modelers can pick the target according to whether downstream utility or privacy leakage is the binding constraint.
- The guidance can be used for pre-release selection when a disclosure-risk threshold is fixed.
- Repeating the experiments with additional risk metrics would test whether the same target ordering holds under different privacy definitions.
Load-bearing premise
The seven chosen datasets and the chosen utility and disclosure metrics are representative enough for the observed target-dependent regimes to generalize to other tabular domains and risk definitions.
What would settle it
Running the same comparison on an eighth tabular dataset drawn from a different domain and finding that velocity matching no longer produces higher utility than score matching would falsify the claim that the learning target sets the regime.
Figures
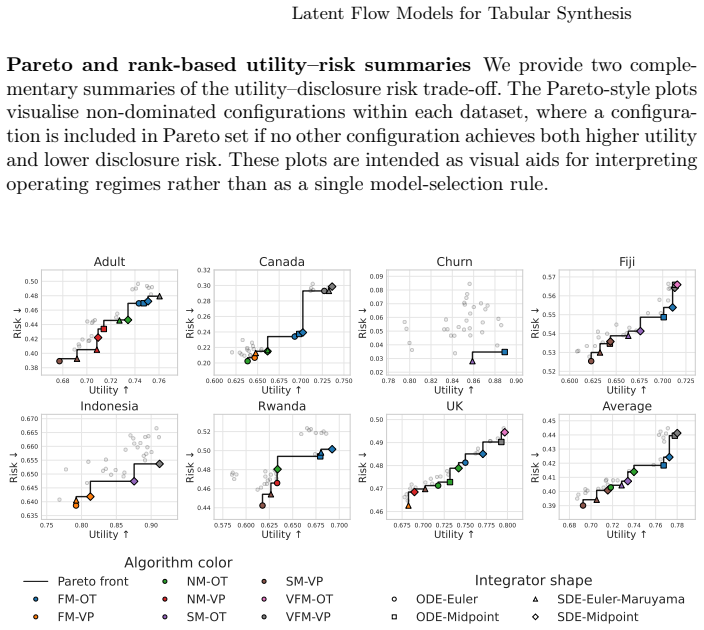
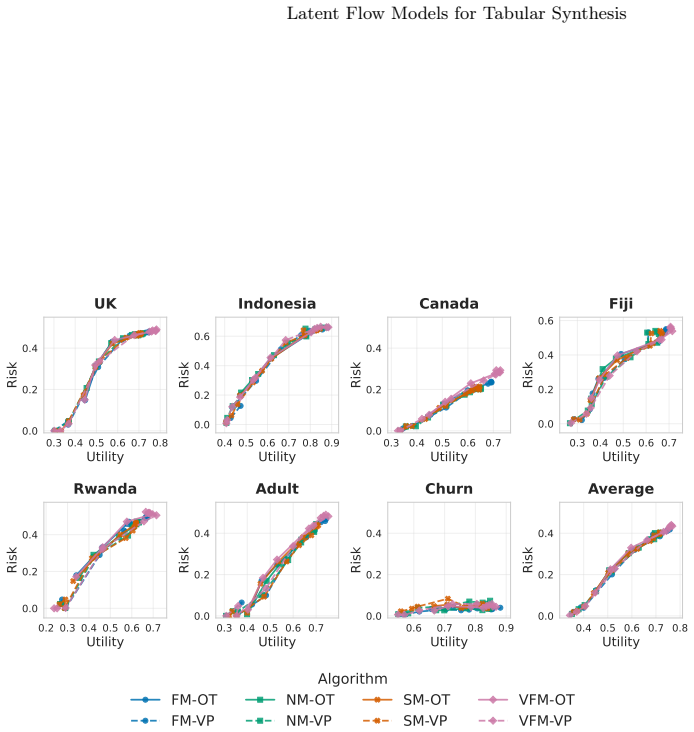
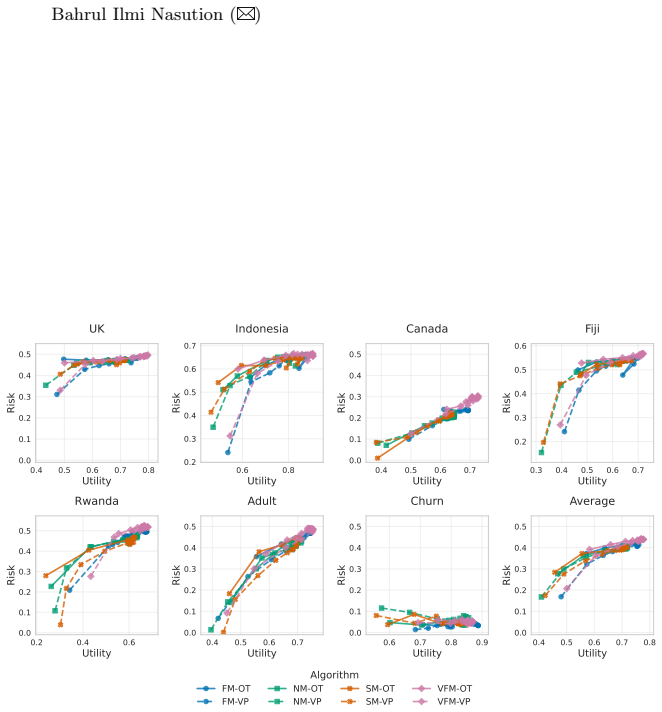
read the original abstract
Synthetic tabular data enables microdata sharing in regulated domains, yet deploying continuous-time generative models requires balancing analytical utility, disclosure risk, and computational cost. Latent-space flow models are flexible, but theoretical equivalences across learning targets, probability paths, and sampling dynamics can translate into different behaviour under finite-step integration and explicit compute budgets. We present an empirical study of tabular latent flow models across seven datasets, evaluating velocity, score, noise, and posterior matching objectives under optimal transport (OT) and variance-preserving (VP) paths, ODE and SDE sampling, and varying integration budgets. Our contributions are threefold: (1) we show that the learning target largely determines the utility-risk operating regime, with velocity and posterior matching tending to yield higher utility, while score and noise matching tend to achieve lower disclosure risk; (2) we demonstrate that configuration and sampling choices shift performance, with midpoint often improving distributional fidelity and OT paths often tolerating earlier stopping than VP, enabling compute savings under fixed budgets or risk thresholds; and (3) we distil these findings into actionable defaults and practical configuration guidance to support pre-release model selection under disclosure risk and resource constraints. The code implementation and supplementary materials can be accessed in https://github.com/rulnasution/tabular-latent-flow/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study of latent flow models for tabular data synthesis. It evaluates four learning targets (velocity, score, noise, and posterior matching) under optimal transport (OT) and variance-preserving (VP) paths, combined with ODE and SDE sampling at varying integration budgets, across seven datasets. The central claim is that the learning target largely determines the utility-risk operating regime, with velocity and posterior matching tending to produce higher utility while score and noise matching achieve lower disclosure risk. Secondary observations include benefits from midpoint sampling for distributional fidelity and OT paths tolerating earlier stopping for compute savings. The authors distill findings into configuration guidance and release code and supplementary materials.
Significance. If the target-dependent regimes hold beyond the evaluated setting, the study would supply practitioners with actionable defaults for balancing utility, disclosure risk, and compute in continuous-time generative models for regulated tabular data release. The public GitHub implementation supporting reproduction of all reported configurations is a clear strength that facilitates verification and extension.
major comments (2)
- [Abstract and experimental results] Abstract, contribution (1): the claim that the learning target 'largely determines' the utility-risk regime is supported solely by results on seven datasets with fixed utility and disclosure metrics; no hold-out domains, alternative risk measures (e.g., membership inference variants), or statistical significance tests are reported, directly limiting the strength of the generalization.
- [§4 (Datasets and evaluation)] Experimental design: the observed separation between velocity/posterior versus score/noise matching could be driven by dataset-specific properties (feature-type mix, size range, or correlation structure) rather than the target itself; without cross-domain validation or sensitivity analysis to metric definitions, the 'largely determines' conclusion remains load-bearing and untested.
minor comments (2)
- [Abstract] The abstract states that 'midpoint often improving distributional fidelity'; a brief definition or reference to the midpoint integrator would aid readers unfamiliar with the sampling variants.
- [Results tables] Ensure all tables reporting utility and risk metrics include the number of independent runs and any error bars or standard deviations to allow assessment of variability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work's significance and for the constructive feedback on strengthening the generalization of our claims. We address each major comment below and propose targeted revisions.
read point-by-point responses
-
Referee: [Abstract and experimental results] Abstract, contribution (1): the claim that the learning target 'largely determines' the utility-risk regime is supported solely by results on seven datasets with fixed utility and disclosure metrics; no hold-out domains, alternative risk measures (e.g., membership inference variants), or statistical significance tests are reported, directly limiting the strength of the generalization.
Authors: We agree that the generalization claim is bounded by our experimental scope. The seven datasets are standard in tabular synthesis and exhibit consistent target-based separation. In revision we will add statistical significance tests (Wilcoxon signed-rank) on utility-risk differences and explicitly discuss limitations on hold-out domains and alternative risk measures (e.g., membership inference) in the discussion. This clarifies the evidential basis without overstating generality. revision: partial
-
Referee: [§4 (Datasets and evaluation)] Experimental design: the observed separation between velocity/posterior versus score/noise matching could be driven by dataset-specific properties (feature-type mix, size range, or correlation structure) rather than the target itself; without cross-domain validation or sensitivity analysis to metric definitions, the 'largely determines' conclusion remains load-bearing and untested.
Authors: While full cross-domain validation would require new datasets, our seven datasets already vary substantially in size, feature count, and categorical/continuous mix. In the revision we will add a supplementary stratification of results by these characteristics to show the target regimes persist within subgroups. We will also note the use of standard literature metrics and any sensitivity considerations. This provides additional evidence that the separation is target-driven. revision: partial
Circularity Check
Empirical benchmarking study contains no derivation chain or self-referential predictions
full rationale
The paper is an empirical comparison of velocity/score/noise/posterior matching objectives under OT/VP paths and ODE/SDE sampling across seven fixed datasets. No mathematical derivation is claimed; the central statement that 'the learning target largely determines the utility-risk operating regime' is presented as an observed pattern from the reported experiments rather than a quantity derived from fitted parameters or prior self-citations. All performance differences are measured on external utility and disclosure metrics computed from the generated samples, with no step that renames a fitted quantity as a prediction or reduces a result to a self-citation chain. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of flow matching and continuous-time generative models hold for the evaluated configurations.
Reference graph
Works this paper leans on
-
[1]
Knowledge-Based Systems238, 107886 (2022)
Akrami, H., Joshi, A.A., Li, J., Aydöre, S., Leahy, R.M.: A robust variational autoencoder using beta divergence. Knowledge-Based Systems238, 107886 (2022)
2022
-
[2]
Albergo,M.S.,Boffi,N.M.,Vanden-Eijnden,E.:Stochasticinterpolants:Aunifying framework for flows and diffusions (2023)
2023
-
[3]
Journal of Machine Learning Research25(1) (2024)
Ankan, A., Textor, J.: pgmpy: a python toolkit for Bayesian networks. Journal of Machine Learning Research25(1) (2024)
2024
-
[4]
Dao, Q., Phung, H., Nguyen, B., Tran, A.: Flow matching in latent space (2023)
2023
-
[5]
In: Proceedingsofthe33rdInternationalConferenceonNeuralInformationProcessing Systems (2019)
Durkan, C., Bekasov, A., Murray, I., Papamakarios, G.: Neural spline flows. In: Proceedingsofthe33rdInternationalConferenceonNeuralInformationProcessing Systems (2019)
2019
-
[6]
In: The Thirty-eighth Annual Con- ference on Neural Information Processing Systems (2024)
Eijkelboom, F., Bartosh, G., Naesseth, C.A., Welling, M., van de Meent, J.W.: Variational flow matching for graph generation. In: The Thirty-eighth Annual Con- ference on Neural Information Processing Systems (2024)
2024
-
[7]
Elliot, M., Little, C., Allmendinger, R.: Do samples taken from a synthetic micro- data population replicate the relationship between samples taken from an original population? In: 2023 Expert Meeting on Statistical Data Confidentiality, Confer- ence of European Statisticians (2023)
2023
-
[8]
In: Forty-second International Conference on Machine Learning (2025)
Guzmán-Cordero,A.,Eijkelboom,F.,vandeMeent,J.W.:Exponentialfamilyvari- ational flow matching for tabular data generation. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[9]
In: Pro- ceedings of the 34th International Conference on Neural Information Processing Systems (2020) Latent Flow Models for Tabular Synthesis
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Pro- ceedings of the 34th International Conference on Neural Information Processing Systems (2020) Latent Flow Models for Tabular Synthesis
2020
-
[10]
Holderrieth, P., Erives, E.: An introduction to flow matching and diffusion models (2025)
2025
-
[11]
In: Proceedings of the 40th International Con- ference on Machine Learning
Kotelnikov, A., Baranchuk, D., Rubachev, I., Babenko, A.: TabDDPM: Modelling tabular data with diffusion models. In: Proceedings of the 40th International Con- ference on Machine Learning. vol. 202, pp. 17564–17579 (2023)
2023
-
[12]
In: The Eleventh International Conference on Learning Representations (2023)
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[13]
Journal of Official Statistics41(1), 255–308 (2025)
Little, C., Allmendinger, R., Elliot, M.: Synthetic census microdata generation: A comparative study of synthesis methods examining the trade-off between disclosure risk and utility. Journal of Official Statistics41(1), 255–308 (2025)
2025
-
[14]
In: Privacy in Statistical Databases: International Conference
Little, C., Elliot, M., Allmendinger, R.: Comparing the utility and disclosure risk of synthetic data with samples of microdata. In: Privacy in Statistical Databases: International Conference. p. 234–249 (2022)
2022
-
[15]
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow (2022)
2022
-
[16]
Minnesota Population Center: Integrated public use microdata series, interna- tional:Version7.4[dataset].Minneapolis,MN:IPUMS.IPUMsCensusData(2023)
2023
-
[17]
In: The Thirteenth International Conference on Learning Representations (2025)
Mueller,M.,Gruber,K.,Fok,D.:Continuousdiffusionformixed-typetabulardata. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[18]
Transactions on Machine Learning Research (2026)
Nasution, B.I., Eijkelboom, F., Elliot, M., Allmendinger, R., Naesseth, C.A.: Flow matching for tabular data synthesis. Transactions on Machine Learning Research (2026)
2026
-
[19]
In: IEEE International Conference on Data Science and Advanced Analytics (DSAA)
Patki, N., Wedge, R., Veeramachaneni, K.: The synthetic data vault. In: IEEE International Conference on Data Science and Advanced Analytics (DSAA). pp. 399–410 (2016)
2016
-
[20]
Qian, Z., Davis, R., van der Schaar, M.: Synthcity: a benchmark framework for diverseusecasesoftabularsyntheticdata.In:Proceedingsofthe37thInternational Conference on Neural Information Processing Systems (2023)
2023
-
[21]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models (2022)
2022
-
[22]
In: Proceedings of the 35th International Conference on Neural Information Processing Systems (2021)
Song, Y., Durkan, C., Murray, I., Ermon, S.: Maximum likelihood training of score- based diffusion models. In: Proceedings of the 35th International Conference on Neural Information Processing Systems (2021)
2021
-
[23]
In: Proceedings of the 33rd International Conference on Neural Infor- mation Processing Systems (2019)
Song, Y., Ermon, S.: Generative modeling by estimating gradients of the data distribution. In: Proceedings of the 33rd International Conference on Neural Infor- mation Processing Systems (2019)
2019
-
[24]
In: Joint UNECE/Eurostat Work Session on Statistical Data Confidentiality, 29-31 October 2019, the Hague, the Netherlands (2019)
Taub,J.,Elliot,M.,Raab,G.,Charest,A.S.,Chen,C.,O’Keefe,C.M.,Nixon,M.P., Snoke, J., Slavkovic, A.: The synthetic data challenge. In: Joint UNECE/Eurostat Work Session on Statistical Data Confidentiality, 29-31 October 2019, the Hague, the Netherlands (2019)
2019
-
[25]
ACM Trans
Villaizán-Vallelado, M., Salvatori, M., Segura, C., Arapakis, I.: Diffusion models for tabular data imputation and synthetic data generation. ACM Trans. Knowl. Discov. Data19(6) (Jul 2025)
2025
-
[26]
In: Advances in Neural Information Processing Systems
Xu, L., Skoularidou, M., Cuesta-Infante, A., Veeramachaneni, K.: Modeling tab- ular data using conditional GAN. In: Advances in Neural Information Processing Systems. vol. 32 (2019)
2019
-
[27]
Understanding Latent Flow Models for Tabular Data Synthesis: Targets, Paths, and Sampling
Zhang, H., Zhang, J., Shen, Z., Srinivasan, B., Qin, X., Faloutsos, C., Rangwala, H., Karypis, G.: Mixed-type tabular data synthesis with score-based diffusion in latentspace.In:TheTwelfthInternationalConferenceonLearningRepresentations (2024) Bahrul Ilmi Nasution () Supplementary Materials for “Understanding Latent Flow Models for Tabular Data Synthesis:...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.