When Do Intrinsic Rewards Work for Code Reasoning? A Comprehensive Study
Pith reviewed 2026-06-26 17:04 UTC · model grok-4.3
The pith
Certainty-based intrinsic rewards for code models give early gains but cause output shortening and loss of reasoning ability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Certainty-based RLIF methods produce early performance lifts on code generation benchmarks but inevitably cause progressive output shortening and degradation of reasoning capability; the collapse rate varies with sample size and temperature, and RLIF pre-training yields no measurable advantage when initializing subsequent RLVR training from scratch.
What carries the argument
Certainty-based Reinforcement Learning from Internal Feedback (RLIF) that turns model confidence or majority-vote signals into scalar rewards for policy updates on code generation.
If this is right
- Models trained with these rewards progressively produce shorter code snippets.
- Reasoning depth and correctness decline after the initial phase.
- Collapse occurs faster at certain sample sizes and temperature values.
- Starting RLVR training from an RLIF checkpoint shows no improvement over random initialization.
- Training recipes for code models should avoid relying solely on certainty signals after the first few steps.
Where Pith is reading between the lines
- The same certainty collapse pattern may appear when intrinsic rewards are applied to other structured generation tasks that require long coherent outputs.
- Hybrid reward schemes that combine early intrinsic signals with later verifiable ones could be tested to extend the useful training window.
- Monitoring output length and reasoning step count during training offers a practical early-warning signal for collapse across model scales.
- The hyperparameter sensitivity suggests that search over temperature and batch size might delay but not eliminate the failure mode.
Load-bearing premise
The observed shortening and capability loss on LiveCodeBench stems directly from the certainty-based reward signal itself rather than from other aspects of the training setup or the benchmark.
What would settle it
Retraining the same models with the same certainty-based reward rules on LiveCodeBench while keeping outputs at original lengths and preserving or increasing reasoning depth would disprove the collapse claim.
Figures
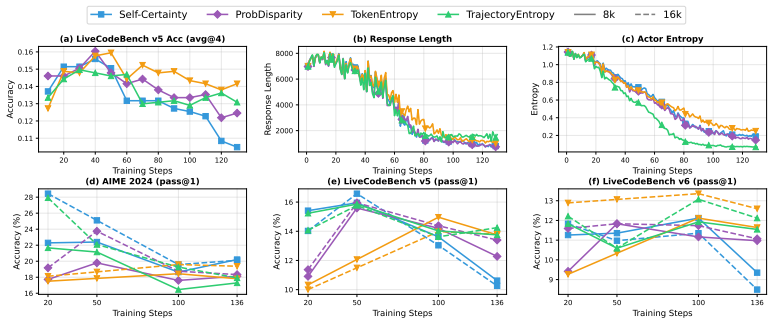




read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has driven substantial progress in large language model reasoning, but relies on ground-truth supervision that is costly or infeasible, especially in coding tasks. Recent work addresses this by deriving rewards from a model's own signals, such as majority voting or confidence-based scores, achieving notable success on mathematical reasoning benchmarks. However, code generation poses distinct challenges: programs are structurally complex, semantically equivalent solutions may differ syntactically, and verification typically requires execution. Whether these intrinsic reward methods transfer effectively to code remains unexplored. In this work, we present a systematic empirical study of intrinsic reward methods for code generation. We conduct extensive experiments on LiveCodeBench, systematically evaluating representative certainty-based Reinforcement Learning from Internal Feedback (RLIF) approaches under different training scenarios and hyperparameter settings. Our experiments reveal that certainty-based methods yield early gains but inevitably collapse: models progressively shorten outputs and lose reasoning capability, with collapse speed sensitive to sample size and temperature. When used to initialize RLVR training, RLIF pre-training offers no significant improvement over training from scratch. We also provide actionable recommendations for using intrinsic rewards for training code reasoning models. Our study shows both the promise and limitations of intrinsic reward methods for code, informing future work on code models and agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic empirical study of certainty-based Reinforcement Learning from Internal Feedback (RLIF) methods for code generation on LiveCodeBench. It reports that these intrinsic-reward approaches produce early gains but inevitably collapse—manifested as progressive output shortening and loss of reasoning capability—with collapse speed modulated by sample size and temperature. RLIF pre-training is found to confer no significant benefit when used to initialize subsequent RLVR training, and the work concludes with actionable recommendations for intrinsic rewards in code reasoning models.
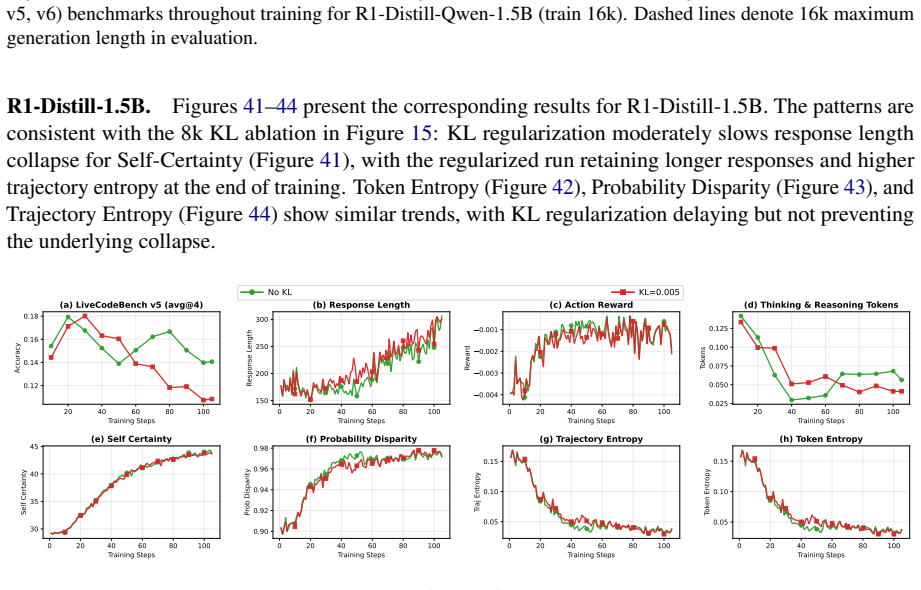
Significance. If the central empirical findings are robustly supported by quantitative results and controls, the study would be significant for LLM reasoning research. It identifies domain-specific limitations of intrinsic rewards in code (distinct from their reported success in mathematics) and supplies practical guidance on hyperparameter sensitivity, potentially steering future work away from ineffective regimes. The emphasis on extensive experiments across scenarios and the provision of recommendations are strengths if the evidence base is solid.
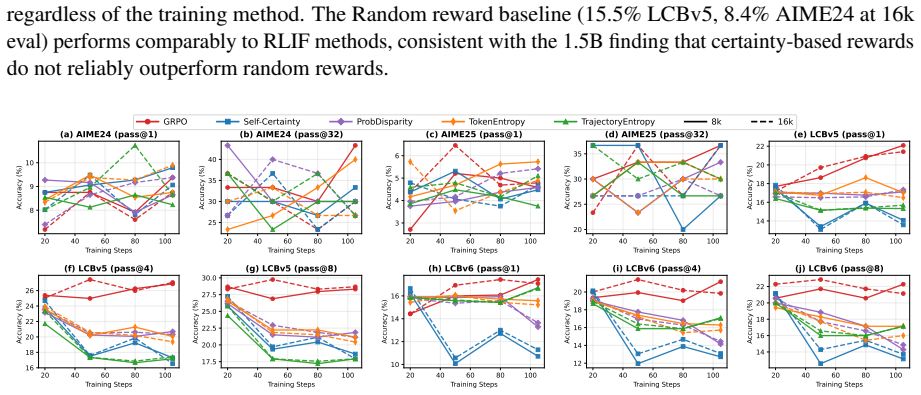
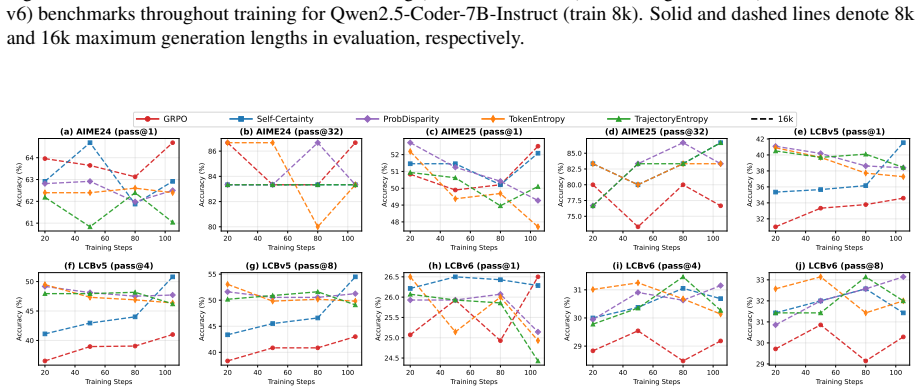
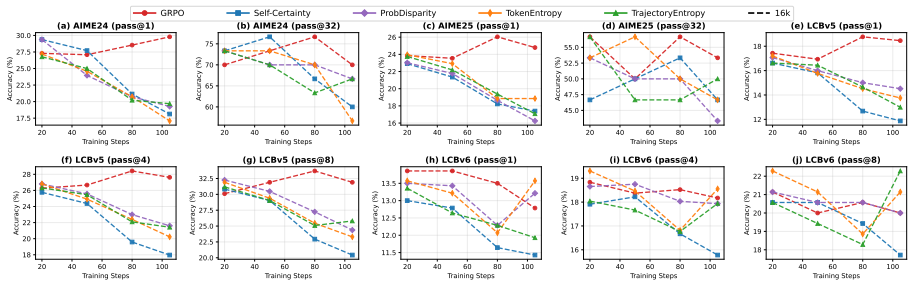
major comments (3)
- [Abstract] Abstract: the central claim that certainty-based methods 'inevitably collapse' (with output shortening and loss of reasoning) cannot be evaluated because the abstract supplies no quantitative results, performance curves, statistical details, or controls; the soundness assessment therefore remains low.
- [Experiments] Experiments section: no ablations are described that isolate the certainty-based reward signal from general RL optimizer dynamics, the code-generation objective, or LiveCodeBench-specific factors (e.g., presence of short correct programs). This leaves open the possibility that observed collapse is not reward-specific, directly undermining attribution of the pathology to the intrinsic reward mechanism itself.
- [Results on RLIF initialization] RLIF pre-training results: the claim of 'no significant improvement' over training from scratch requires explicit comparison metrics, baseline definitions, effect sizes, and statistical tests; without these, the conclusion that RLIF initialization is unhelpful cannot be assessed as load-bearing for the paper's recommendations.
minor comments (1)
- [Methods] Notation for 'certainty-based' scores and 'sample size' should be defined consistently in the methods section to avoid ambiguity when readers compare across temperature settings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical study of certainty-based RLIF for code generation. We address each major comment below with clarifications from the manuscript and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that certainty-based methods 'inevitably collapse' (with output shortening and loss of reasoning) cannot be evaluated because the abstract supplies no quantitative results, performance curves, statistical details, or controls; the soundness assessment therefore remains low.
Authors: The abstract provides a high-level overview, while the full manuscript includes quantitative evidence such as training curves showing early gains followed by performance drops, output length reductions over steps, and sensitivity to sample size and temperature. To address the concern, we will revise the abstract to incorporate key quantitative indicators, including the approximate training step at which collapse typically begins and the magnitude of the pass@1 drop on LiveCodeBench under default settings. revision: yes
-
Referee: [Experiments] Experiments section: no ablations are described that isolate the certainty-based reward signal from general RL optimizer dynamics, the code-generation objective, or LiveCodeBench-specific factors (e.g., presence of short correct programs). This leaves open the possibility that observed collapse is not reward-specific, directly undermining attribution of the pathology to the intrinsic reward mechanism itself.
Authors: We agree that stronger isolation of the reward signal would strengthen causal claims. The manuscript compares RLIF against RLVR (with verifiable rewards) and SFT baselines, with collapse observed exclusively under certainty-based rewards and not in RLVR runs. However, we lack an explicit ablation with a dummy or constant reward under the same RL optimizer. We will add this ablation in the revision to rule out general RL dynamics or LiveCodeBench factors as the sole cause. revision: yes
-
Referee: [Results on RLIF initialization] RLIF pre-training results: the claim of 'no significant improvement' over training from scratch requires explicit comparison metrics, baseline definitions, effect sizes, and statistical tests; without these, the conclusion that RLIF initialization is unhelpful cannot be assessed as load-bearing for the paper's recommendations.
Authors: The manuscript defines the from-scratch baseline as standard RLVR from the base model and reports mean pass@1 with standard deviations across random seeds in figures and tables, showing overlapping trajectories with RLIF-initialized runs. To make the 'no significant improvement' claim more robust, we will add explicit effect size reporting and statistical tests (e.g., t-tests with p-values) in the revised version. revision: partial
Circularity Check
Purely empirical study with no derivations or self-referential reductions
full rationale
The paper conducts a systematic empirical evaluation of certainty-based RLIF methods on LiveCodeBench, reporting observed behaviors such as early gains followed by collapse in output length and reasoning capability. No equations, fitted parameters, uniqueness theorems, or ansatzes are introduced; all claims rest on direct experimental outcomes under varied hyperparameters. No load-bearing self-citations or renamings of known results appear. The derivation chain is absent, rendering the work self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others
-
[2]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261. Shihan Dou, Yan Liu, Haoxiang Jia, Limao Xiong, Enyu Zhou, Wei Shen, Junjie Shan, Caishuang Huang, Xiao Wang, Xiaoran Fan, and 1 others
-
[3]
Step- coder: Improve code generation with reinforcement learning from compiler feedback.arXiv preprint arXiv:2402.01391. Pengfei Gao, Zhao Tian, Xiangxin Meng, Xinchen Wang, Ruida Hu, Yuanan Xiao, Yizhou Liu, Zhao Zhang, Junjie Chen, Cuiyun Gao, and 1 others
-
[4]
Trae agent: An llm-based agent for software en- gineering with test-time scaling.arXiv preprint arXiv:2507.23370. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shi- rong Ma, Peiyi Wang, Xiao Bi, and 1 others
-
[5]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948. Bingxiang He, Yuxin Zuo, Zeyuan Liu, Shangziqi Zhao, Zixuan Fu, Junlin Yang, Cheng Qian, Kaiyan Zhang, Yuchen Fan, Ganqu Cui, and 1 others
-
[6]
How far can unsupervised rlvr scale llm training?arXiv preprint arXiv:2603.08660. Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, and 1 others
-
[7]
5-coder technical report.arXiv preprint arXiv:2409.12186
Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica
-
[8]
Coderl+: Improving code generation via reinforce- ment with execution semantics alignment.arXiv preprint arXiv:2510.18471. Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan
-
[9]
A self-supervised reinforcement learn- ing approach for fine-tuning large language mod- els using cross-attention signals.arXiv preprint arXiv:2502.10482. Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James Validad Miranda, Alisa Liu, Nouha Dziri, Xinxi Lyu, Yuling Gu, Saumya Malik, Victoria Graf, J...
-
[10]
Confidence is all you need: Few-shot rl fine-tuning of language models.arXiv preprint arXiv:2506.06395. Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, and 1 others
-
[11]
arXiv preprint arXiv:2508.11356
Ettrl: Balancing exploration and exploitation in llm test- time reinforcement learning via entropy mechanism. arXiv preprint arXiv:2508.11356. Michael Luo, Sijun Tan, Roy Huang, Ameen Patel, Al- pay Ariyak, Qingyang Wu, Xiaoxiang Shi, Rachel Xin, Colin Cai, Maurice Weber, and 1 others
-
[12]
Post-training large language models via reinforce- ment learning from self-feedback.arXiv preprint arXiv:2507.21931. OpenAI
-
[13]
OpenAI o1 System Card.arXiv preprint arXiv:2412.16720. Guilherme Penedo, Anton Lozhkov, Hynek Ky- dlíˇcek, Loubna Ben Allal, Edward Beeching, Agustín Piqueres Lajarín, Quentin Gallouédec, Nathan Habib, Lewis Tunstall, and Leandro von Werra
-
[14]
arXiv preprint arXiv:2505.22660
Maximizing confidence alone improves reasoning. arXiv preprint arXiv:2505.22660. Sheikh Shafayat, Fahim Tajwar, Ruslan Salakhutdi- nov, Jeff Schneider, and Andrea Zanette
-
[15]
Parshin Shojaee, Aneesh Jain, Sindhu Tipirneni, and Chandan K
Can large reasoning models self-train?arXiv preprint arXiv:2505.21444. Parshin Shojaee, Aneesh Jain, Sindhu Tipirneni, and Chandan K. Reddy
-
[16]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H
Stabilizing knowledge, promot- ing reasoning: Dual-token constraints for rlvr.arXiv preprint arXiv:2507.15778. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
-
[17]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. John Yang, Carlos E Jimenez, Alexander Wettig, Kil- ian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press
-
[18]
Glm-4.5: Agentic, reasoning, and coding (arc) foundation mod- els.arXiv preprint arXiv:2508.06471. Kongcheng Zhang, QI Y AO, Shunyu Liu, Yingjie Wang, Baisheng Lai, Jieping Ye, Mingli Song, and Dacheng Tao. 2025a. Consistent paths lead to truth: Self- rewarding reinforcement learning for LLM reasoning. InThe Thirty-ninth Annual Conference on Neural Inform...
-
[19]
integrates execution semantics alignment to provide denser learning signals beyond binary pass/fail rewards. These approaches provide effective training signal when high-quality test suites are available, but face limitations in settings where test coverage is incomplete or test cases are expensive to obtain. B Additional Experimental Details B.1 Experime...
2025
-
[20]
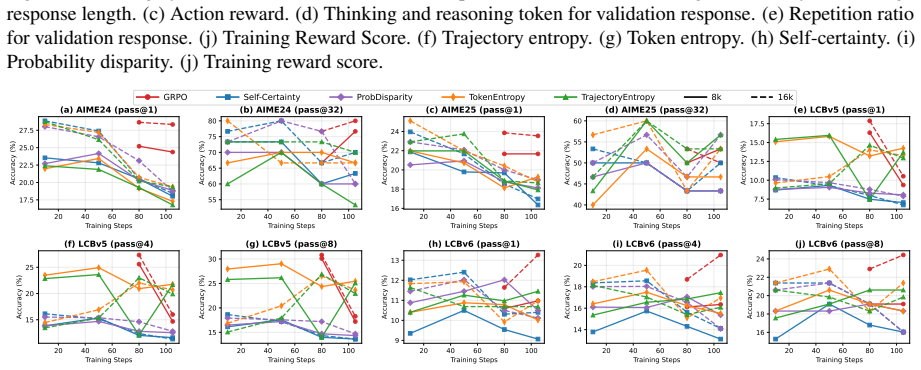
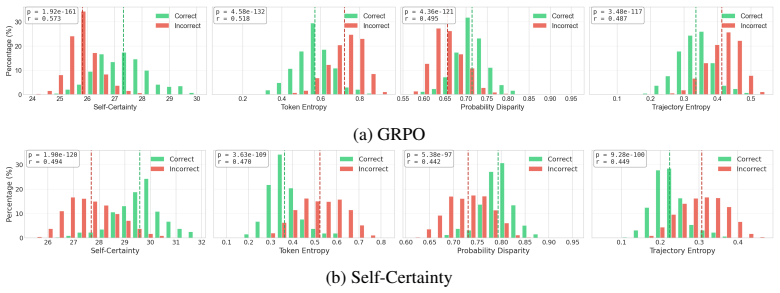
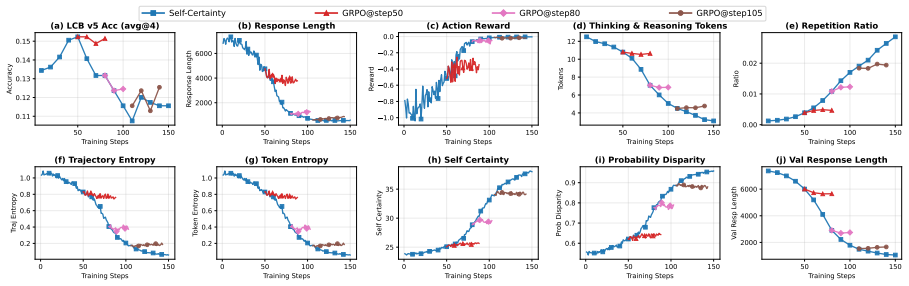
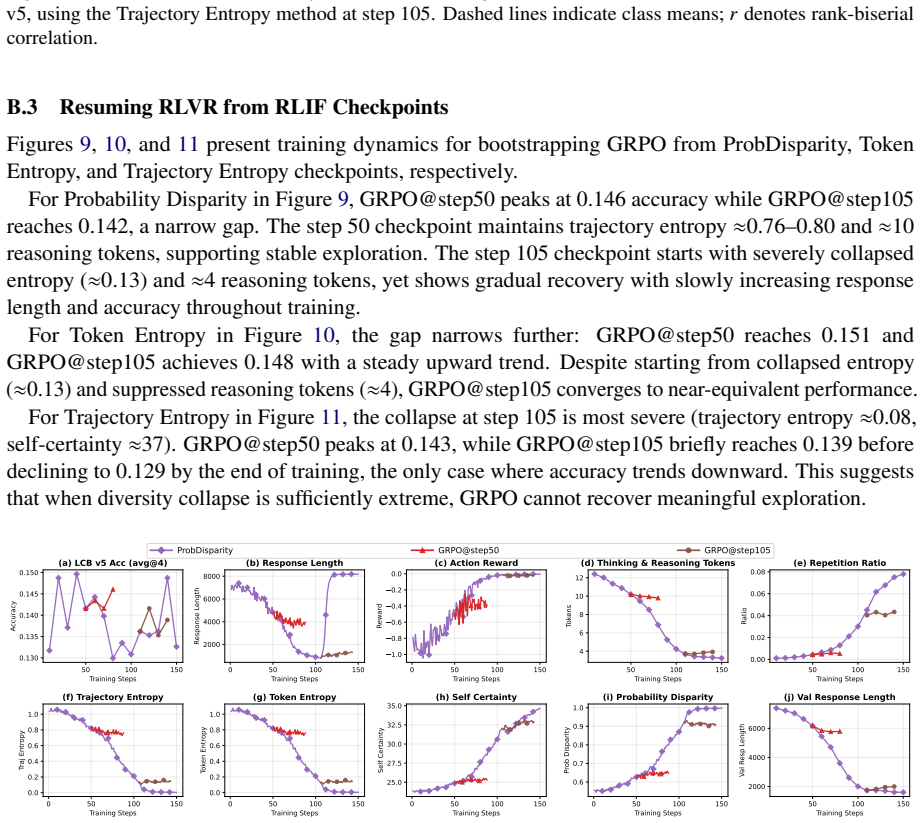
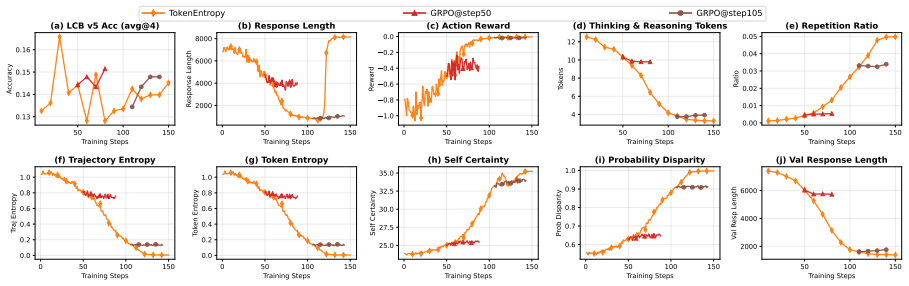
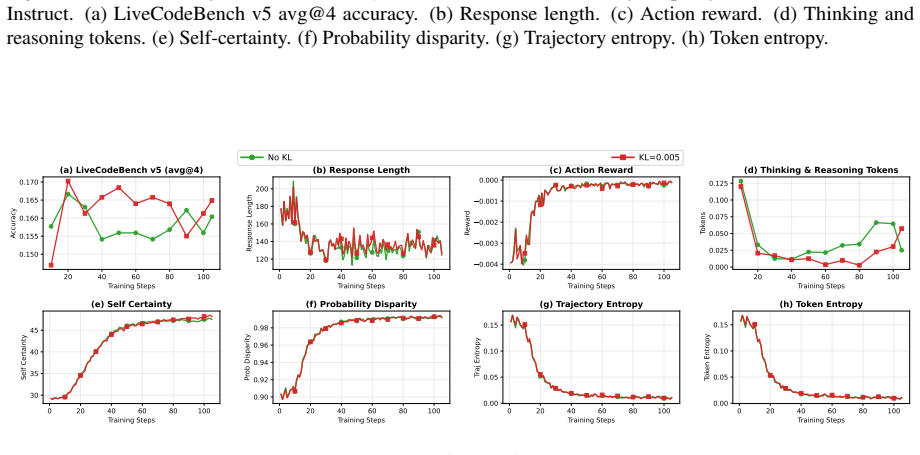
Dashed lines indicate class means; 𝑟 denotes rank-biserial correlation. B.3 Resuming RLVR from RLIF Checkpoints Figures 9, 10, and 11 present training dynamics for bootstrapping GRPO from ProbDisparity, Token Entropy, and Trajectory Entropy checkpoints, respectively. For Probability Disparity in Figure 9, GRPO@step50 peaks at 0.146 accuracy while GRPO@ste...
2000
-
[21]
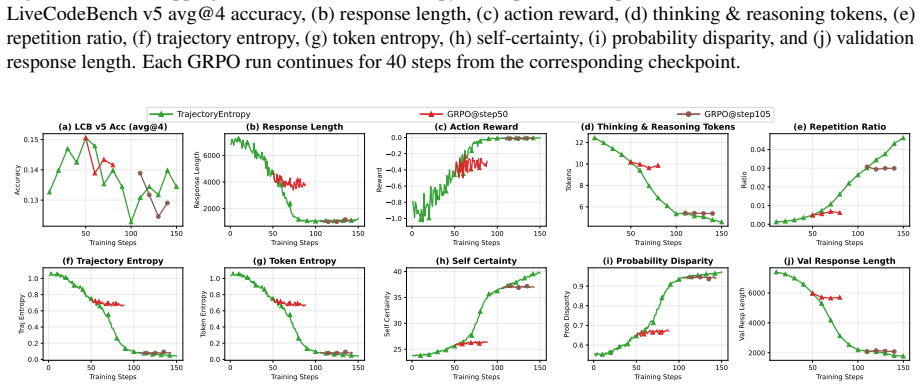
Each GRPO run continues for 40 steps from the corresponding checkpoint
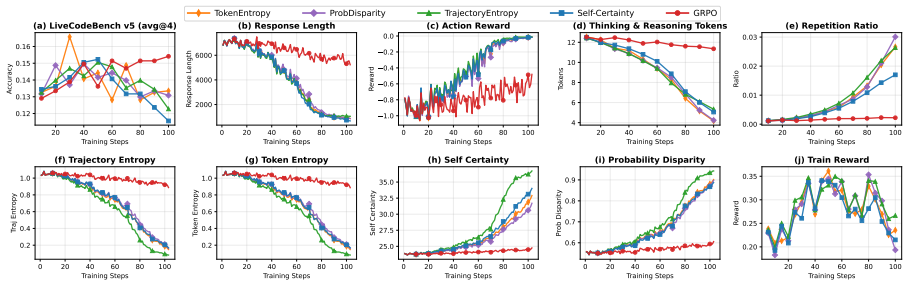
Metrics include (a) Live- CodeBench v5 avg@4 accuracy, (b) response length, (c) action reward, (d) thinking & reasoning tokens, (e) repetition ratio, (f) trajectory entropy, (g) token entropy, (h) self-certainty, (i) probability disparity, and (j) validation response length. Each GRPO run continues for 40 steps from the corresponding checkpoint. B.4 Test-...
2024
-
[22]
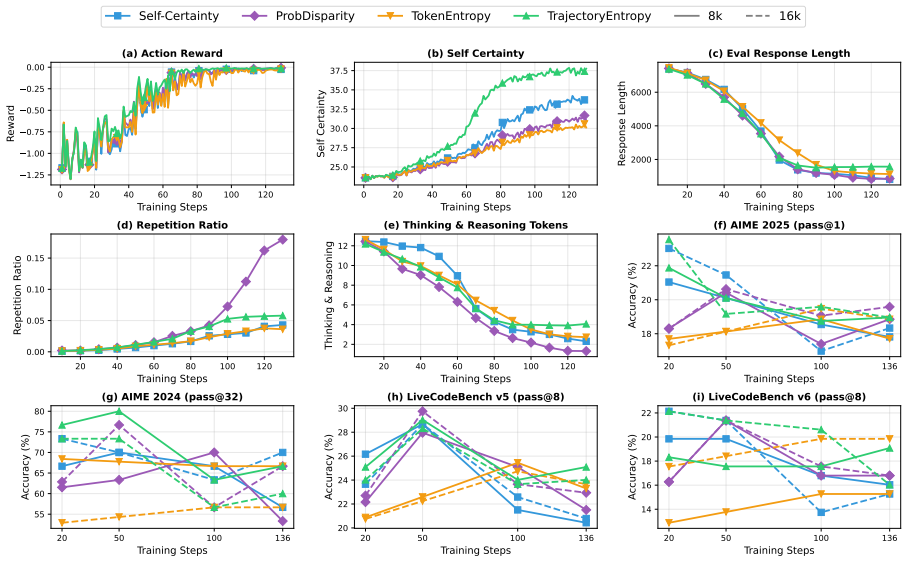
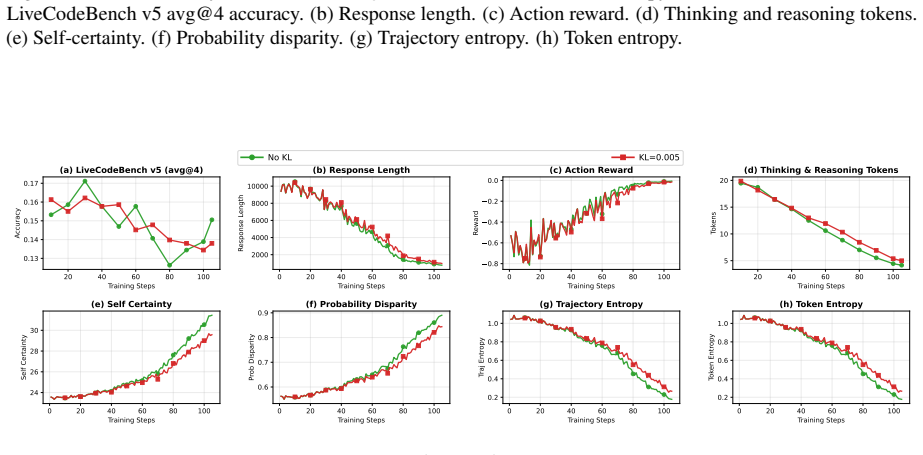
On LiveCodeBench at pass@8 (h–i), all certainty methods show 50 100 150 Training Steps 0.13 0.14 0.15 0.16Accuracy (a) LCB v5 Acc (avg@4) 0 50 100 150 Training Steps 2000 4000 6000 8000Response Length (b) Response Length 0 50 100 150 Training Steps 1.0 0.8 0.6 0.4 0.2 0.0 Reward (c) Action Reward 50 100 150 Training Steps 4 6 8 10 12T okens (d) Thinking &...
2000
-
[23]
Each GRPO run continues for 40 steps from the corresponding checkpoint
Metrics include (a) LiveCodeBench v5 avg@4 accuracy, (b) response length, (c) action reward, (d) thinking & reasoning tokens, (e) repetition ratio, (f) trajectory entropy, (g) token entropy, (h) self-certainty, (i) probability disparity, and (j) validation response length. Each GRPO run continues for 40 steps from the corresponding checkpoint. 50 100 150 ...
2000
-
[24]
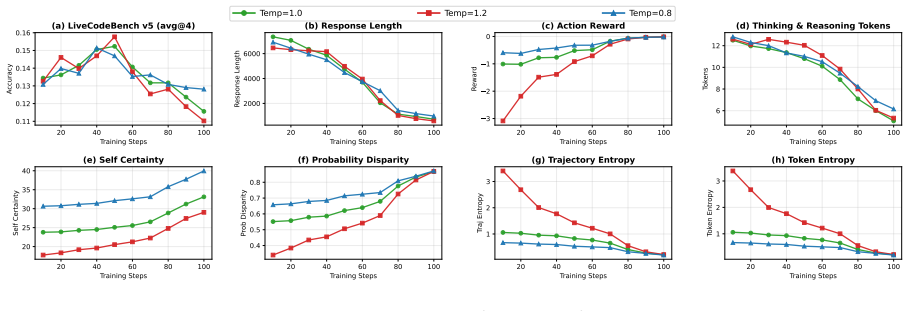
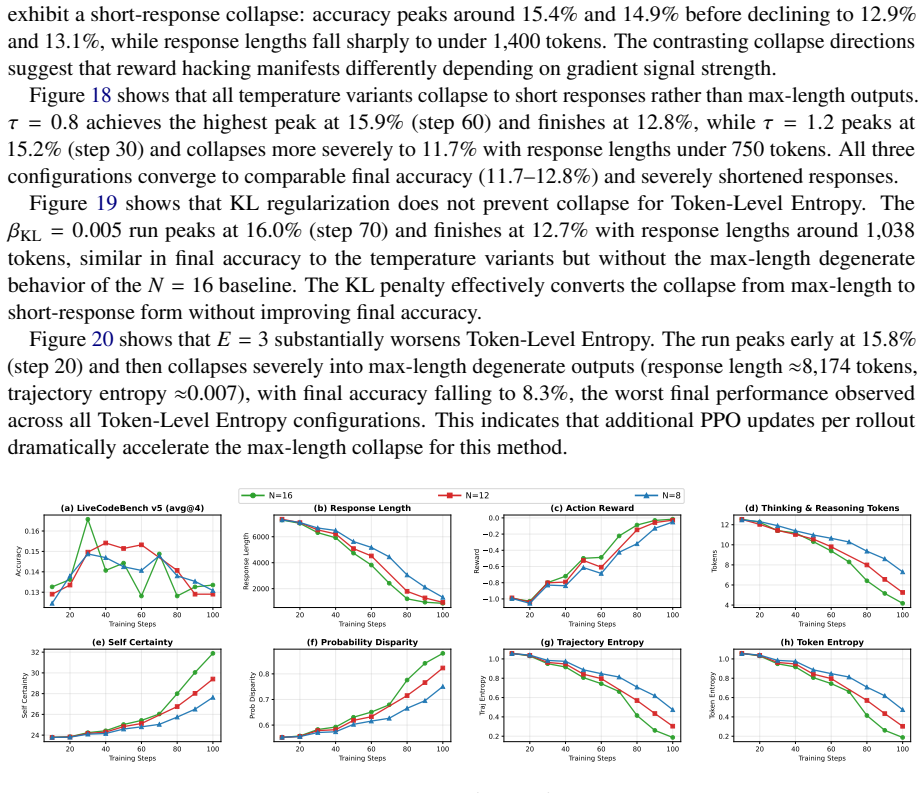
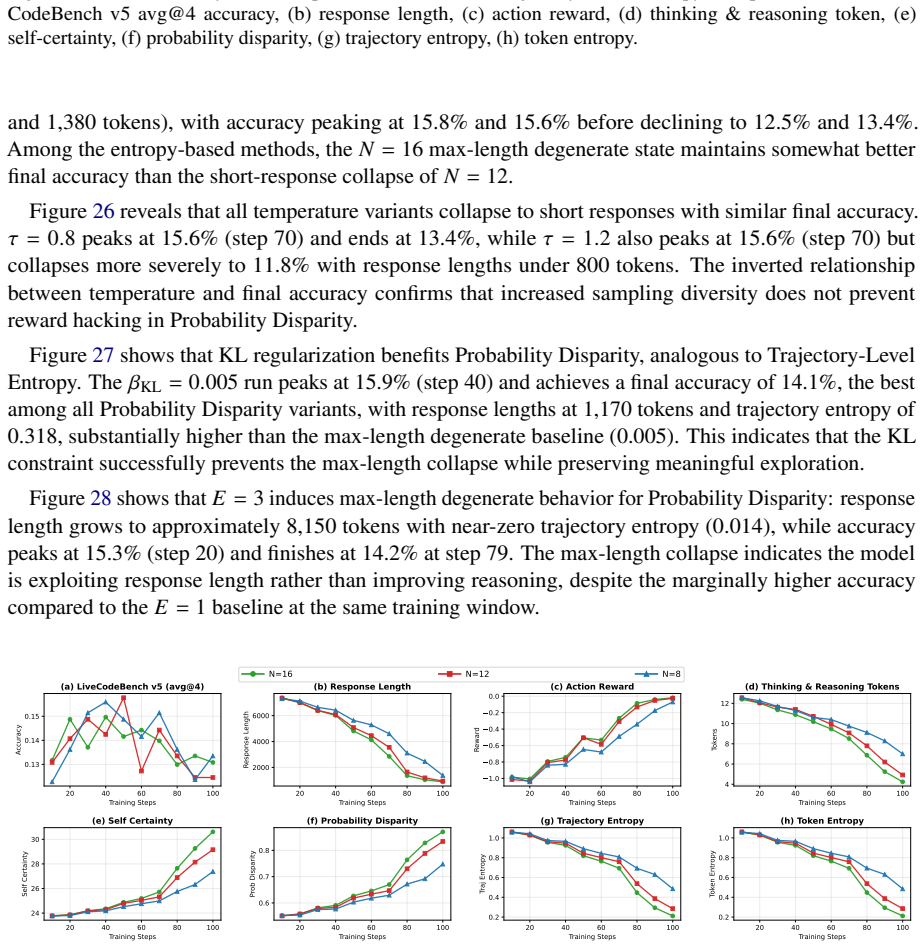
Lower temperature ( 𝜏=0.8 ) peaks at 15.1% and degrades to 12.8% by step 100 with responses around 985 tokens
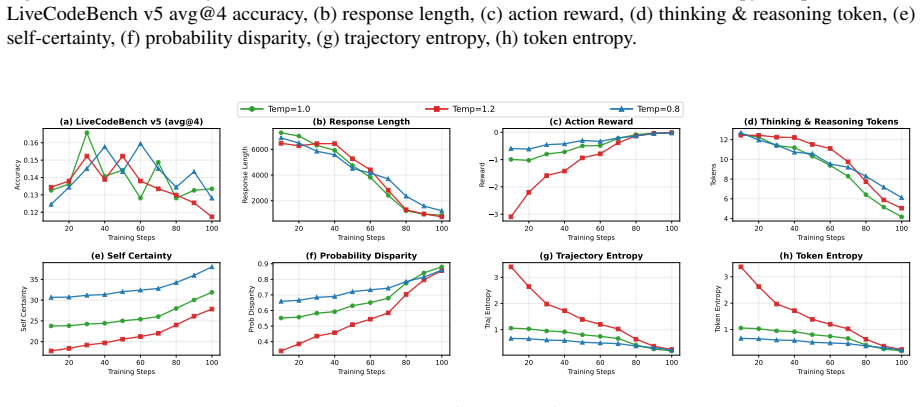
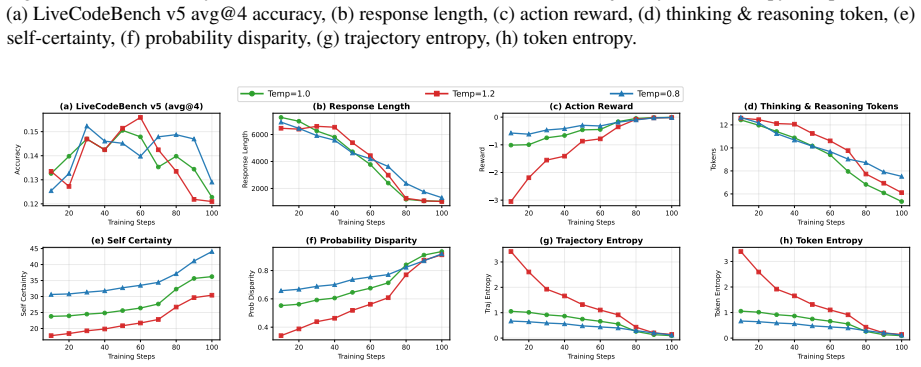
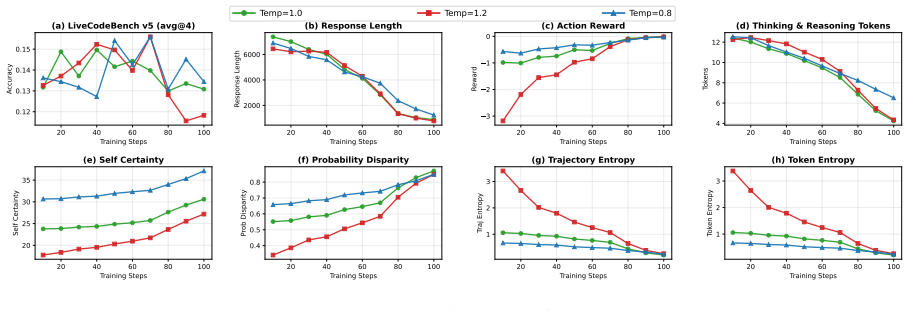
but ultimately collapses more severely, finishing at 11.0% with response length under 600 tokens. Lower temperature ( 𝜏=0.8 ) peaks at 15.1% and degrades to 12.8% by step 100 with responses around 985 tokens. All configurations converge to similar degraded performance, indicating that increased exploration does not address the fundamental reward hacking i...
2000
-
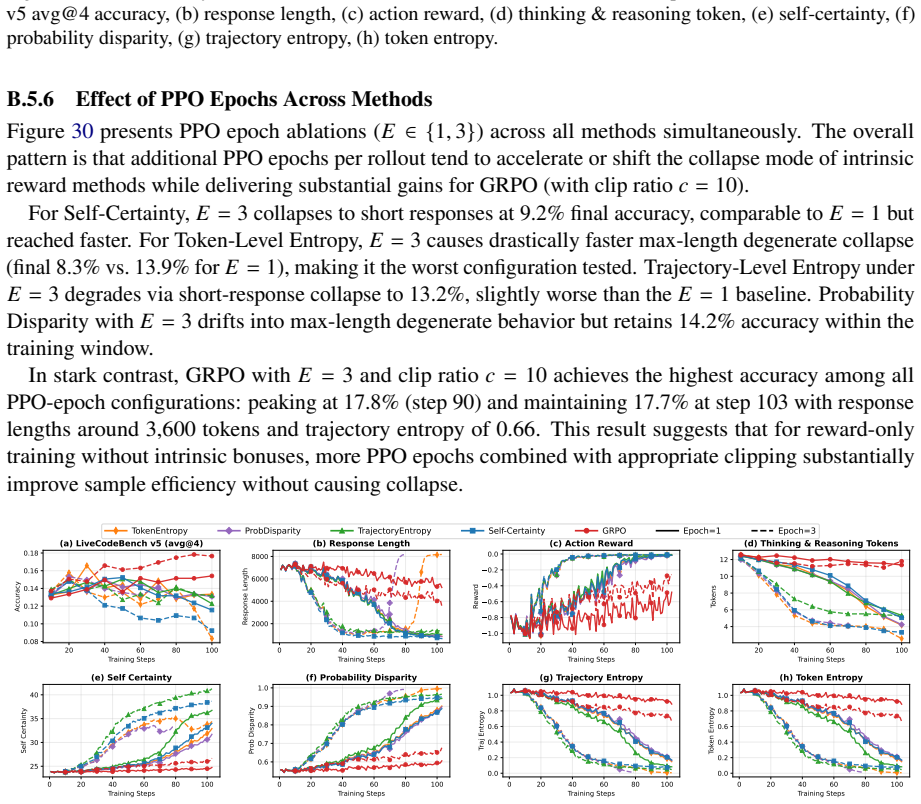
[25]
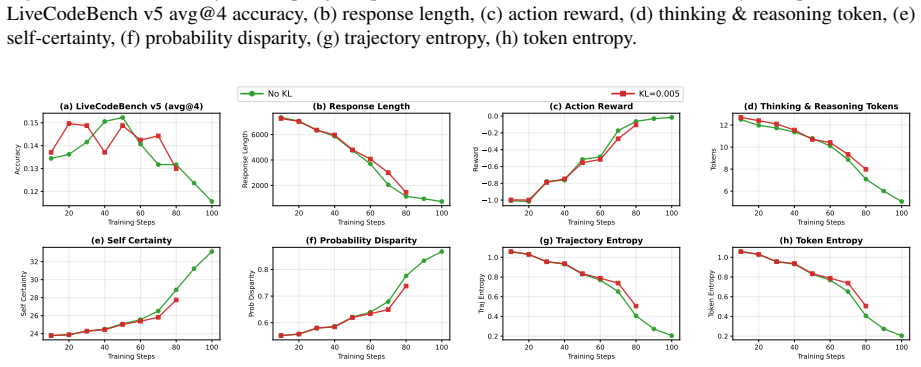
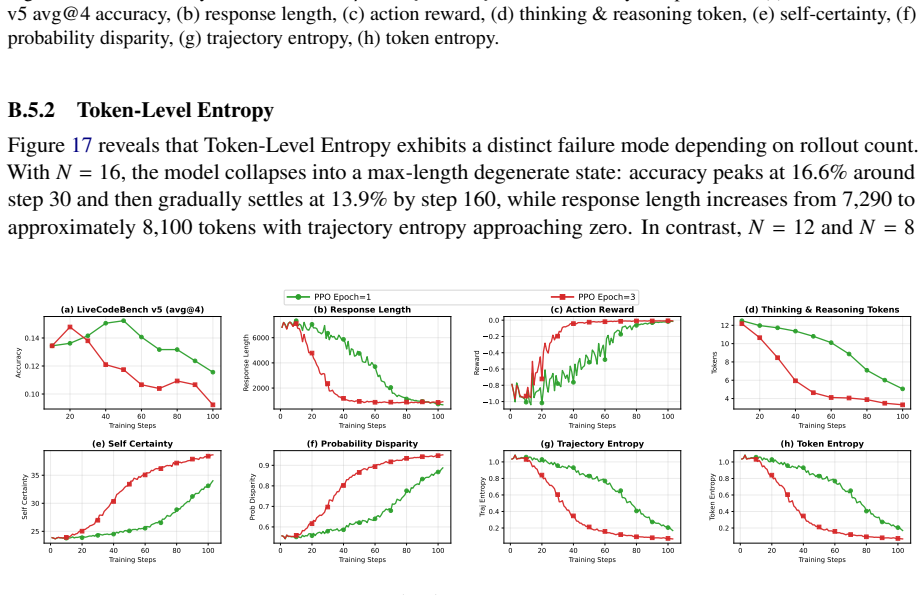
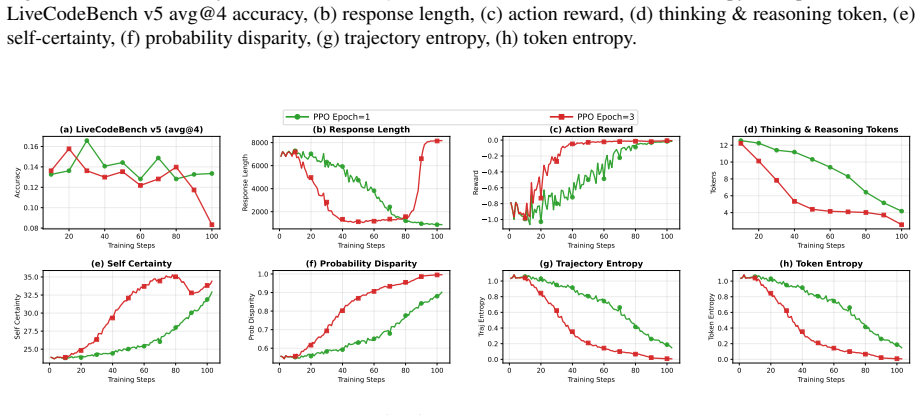
Figure 16 shows that increasing to 𝐸=3 PPO epochs does not help Self-Certainty
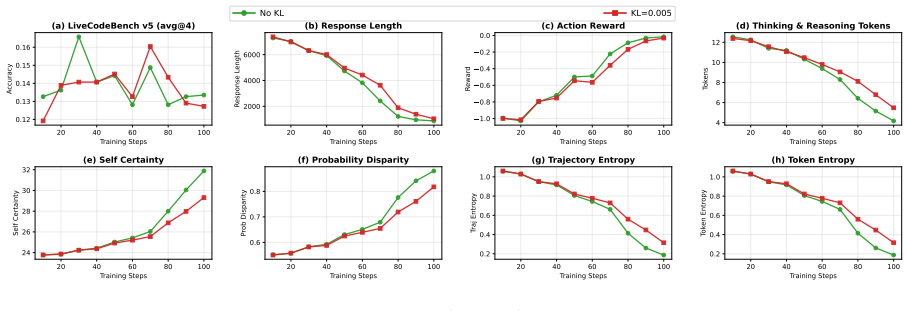
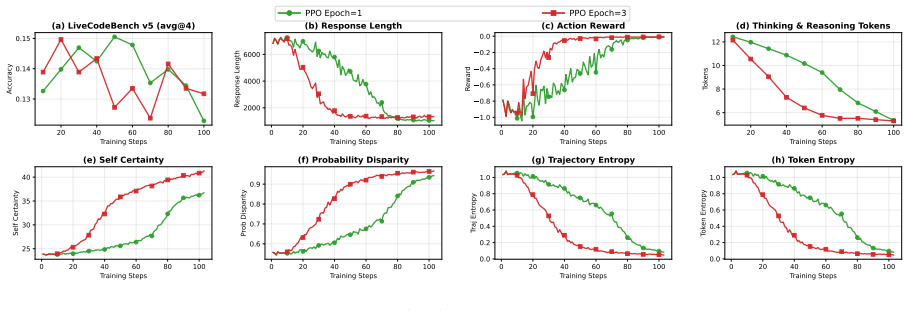
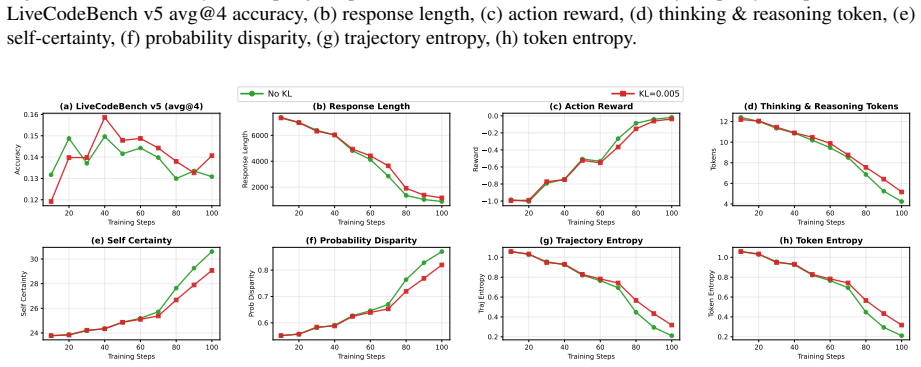
The KL constraint slows self-certainty growth and entropy reduction, but does not fully prevent degradation. Figure 16 shows that increasing to 𝐸=3 PPO epochs does not help Self-Certainty. The 𝐸=3 run peaks at 14.8% at step 20 and collapses to 9.2% by step 103, matching the final performance of 𝐸=1 but reaching degradation faster. Both configurations show...
2000
-
[26]
This indicates that additional PPO updates per rollout dramatically accelerate the max-length collapse for this method
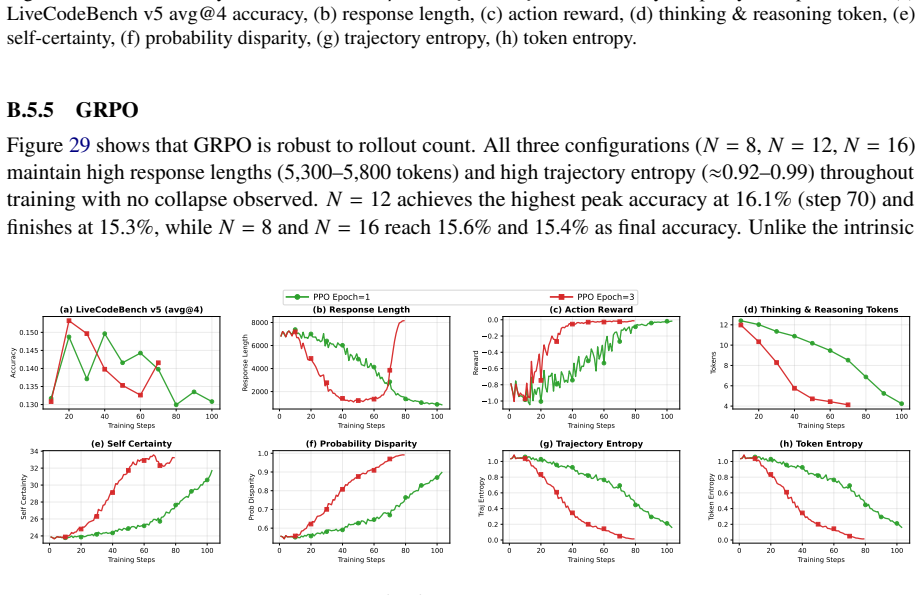
and then collapses severely into max-length degenerate outputs (response length ≈8,174 tokens, trajectory entropy ≈0.007), with final accuracy falling to 8.3%, the worst final performance observed across all Token-Level Entropy configurations. This indicates that additional PPO updates per rollout dramatically accelerate the max-length collapse for this m...
2000
-
[27]
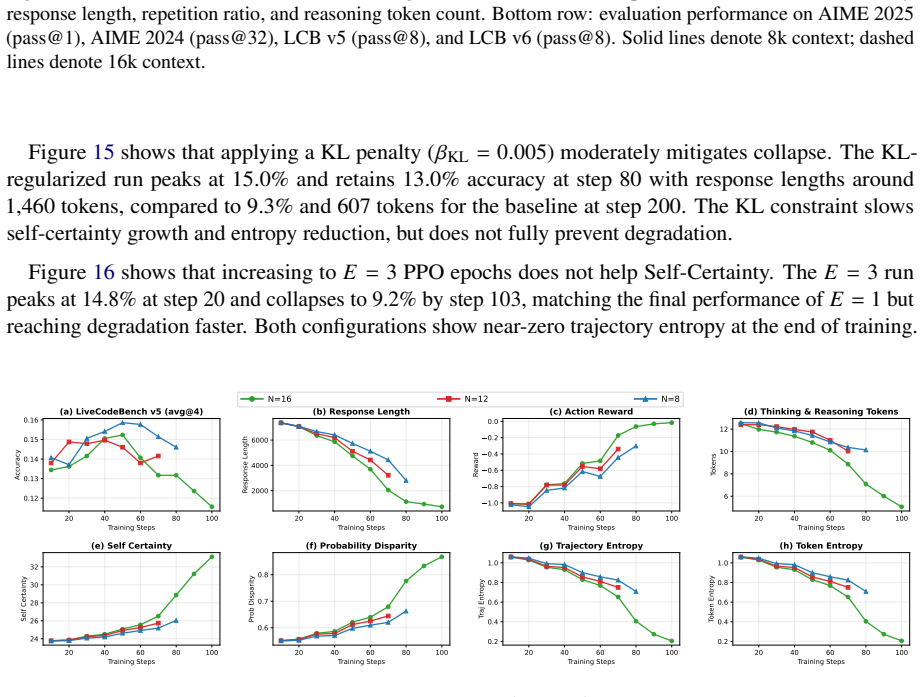
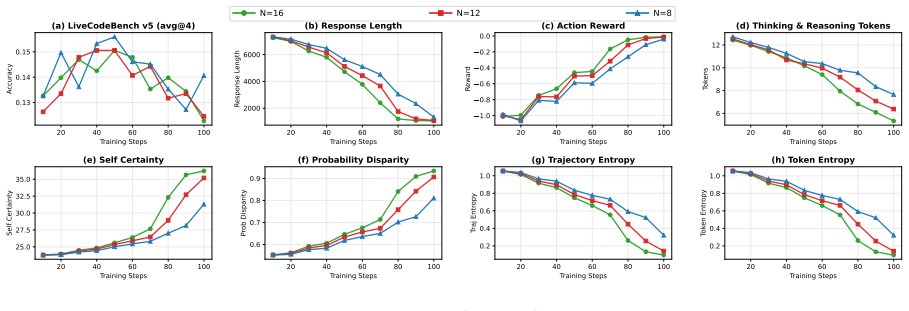
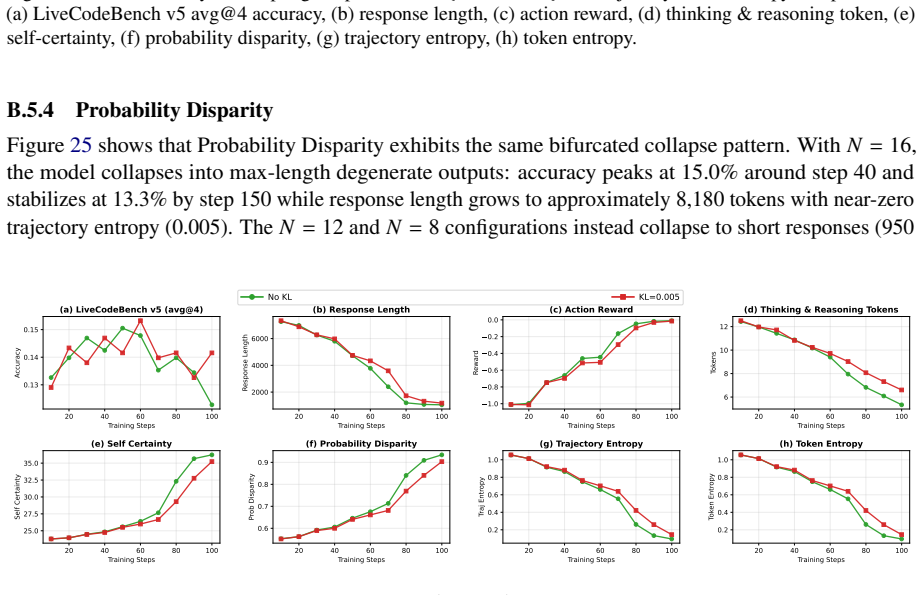
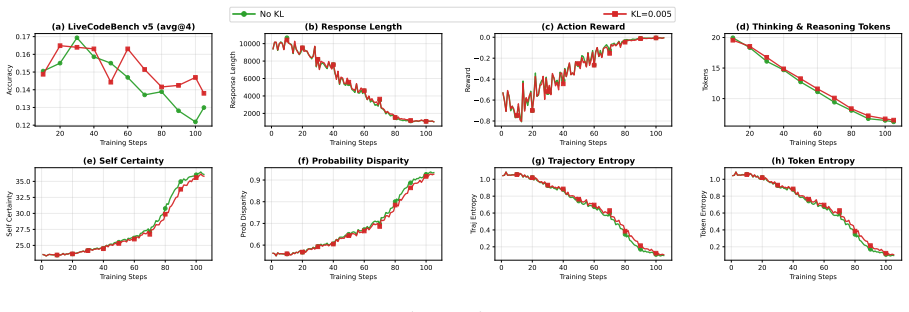
The trajectory entropy at the end (0.047) is higher than the 𝑁=16 baseline but lower than the𝛽 KL =0.005variant, indicating partial collapse. 20 40 60 80 100 Training Steps 0.13 0.14 0.15Accuracy (a) LiveCodeBench v5 (avg@4) 20 40 60 80 100 Training Steps 2000 4000 6000Response Length (b) Response Length 20 40 60 80 100 Training Steps 1.0 0.8 0.6 0.4 0.2 ...
2000
-
[28]
The max-length collapse indicates the model is exploiting response length rather than improving reasoning, despite the marginally higher accuracy compared to the𝐸=1baseline at the same training window. 20 40 60 80 100 Training Steps 0.13 0.14 0.15Accuracy (a) LiveCodeBench v5 (avg@4) 20 40 60 80 100 Training Steps 2000 4000 6000Response Length (b) Respons...
2000
-
[29]
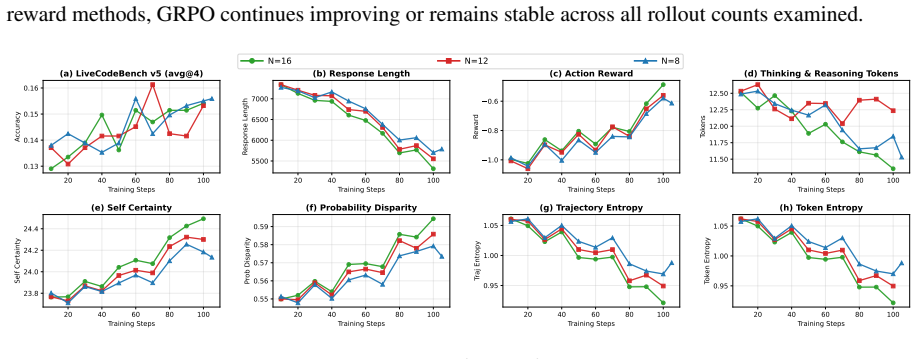
and finishes at 15.3%, while 𝑁=8 and 𝑁=16 reach 15.6% and 15.4% as final accuracy. Unlike the intrinsic 20 40 60 80 100 Training Steps 0.130 0.135 0.140 0.145 0.150Accuracy (a) LiveCodeBench v5 (avg@4) 0 20 40 60 80 100 Training Steps 2000 4000 6000 8000Response Length (b) Response Length 0 20 40 60 80 100 Training Steps 1.0 0.8 0.6 0.4 0.2 0.0 Reward (c)...
2000
-
[30]
and maintaining 17.7% at step 103 with response lengths around 3,600 tokens and trajectory entropy of 0.66. This result suggests that for reward-only training without intrinsic bonuses, more PPO epochs combined with appropriate clipping substantially improve sample efficiency without causing collapse. 20 40 60 80 100 Training Steps 0.08 0.10 0.12 0.14 0.1...
2000
-
[31]
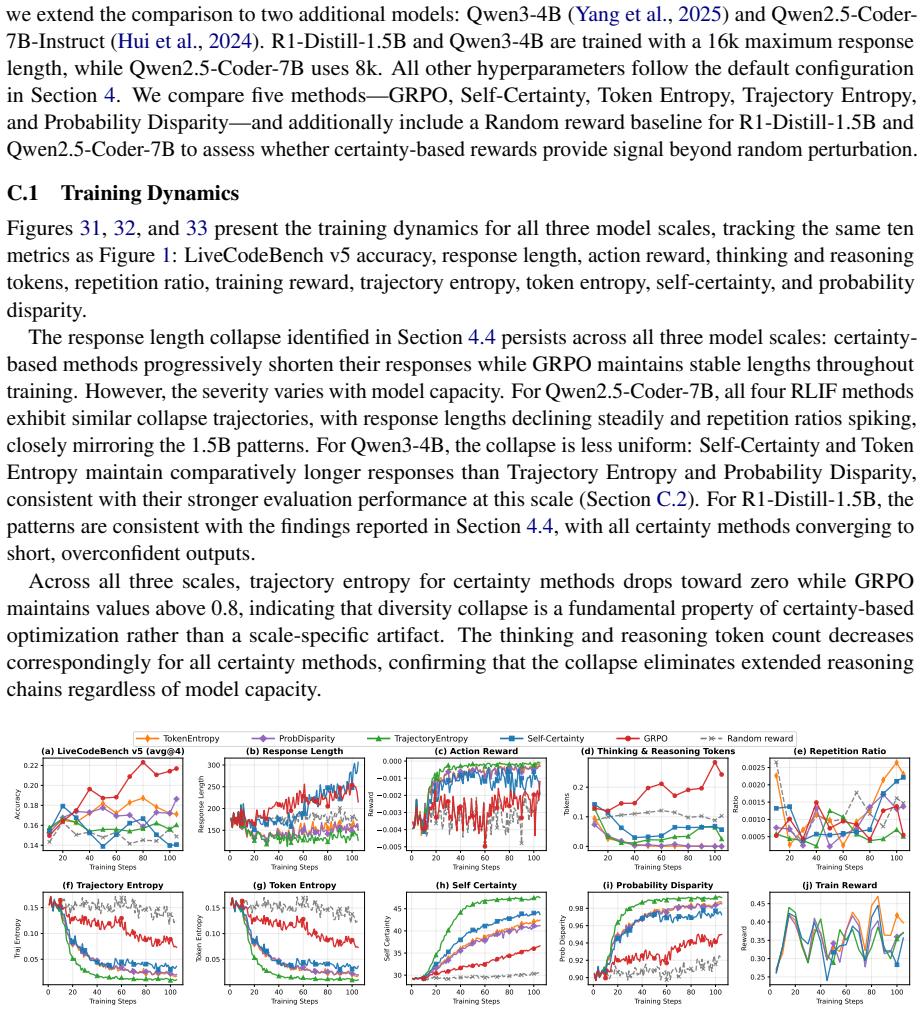
R1-Distill-1.5B and Qwen3-4B are trained with a 16k maximum response length, while Qwen2.5-Coder-7B uses 8k
and Qwen2.5-Coder- 7B-Instruct (Hui et al., 2024). R1-Distill-1.5B and Qwen3-4B are trained with a 16k maximum response length, while Qwen2.5-Coder-7B uses 8k. All other hyperparameters follow the default configuration in Section
2024
-
[32]
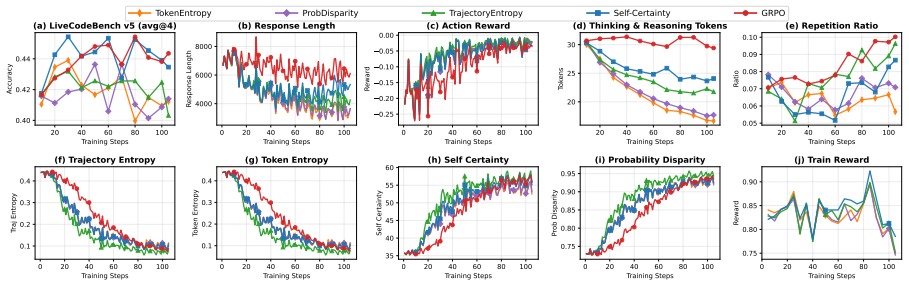
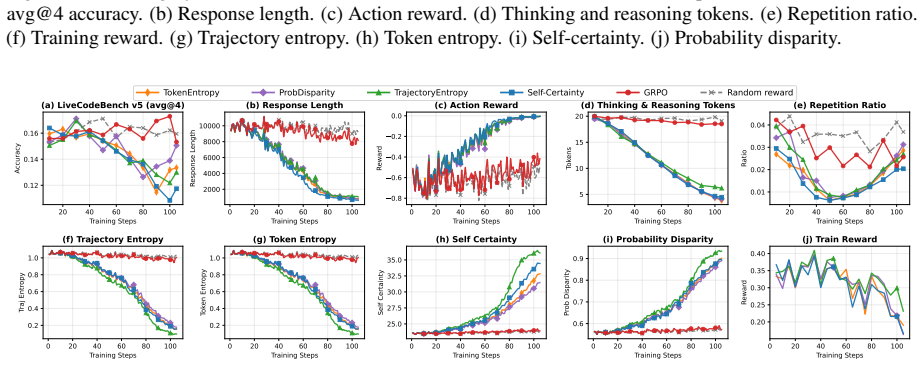
We compare five methods—GRPO, Self-Certainty, Token Entropy, Trajectory Entropy, and Probability Disparity—and additionally include a Random reward baseline for R1-Distill-1.5B and Qwen2.5-Coder-7B to assess whether certainty-based rewards provide signal beyond random perturbation. C.1 Training Dynamics Figures 31, 32, and 33 present the training dynamics...
2000
-
[33]
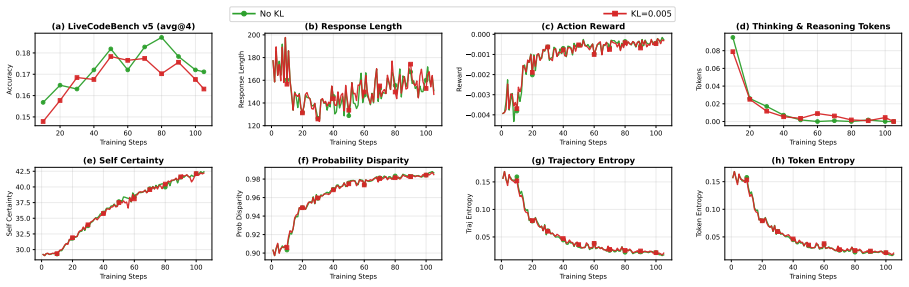
show similar trends, with KL regularization delaying but not preventing the underlying collapse. 20 40 60 80 100 Training Steps 0.12 0.14 0.16 0.18Accuracy (a) LiveCodeBench v5 (avg@4) 0 20 40 60 80 100 Training Steps 150 200 250 300Response Length (b) Response Length 0 20 40 60 80 100 Training Steps 0.004 0.003 0.002 0.001 Reward (c) Action Reward 20 40 ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.