From Inference to Prediction: How Machine Learning is Reconfiguring Science (1990-2025)
Pith reviewed 2026-06-26 13:12 UTC · model grok-4.3
The pith
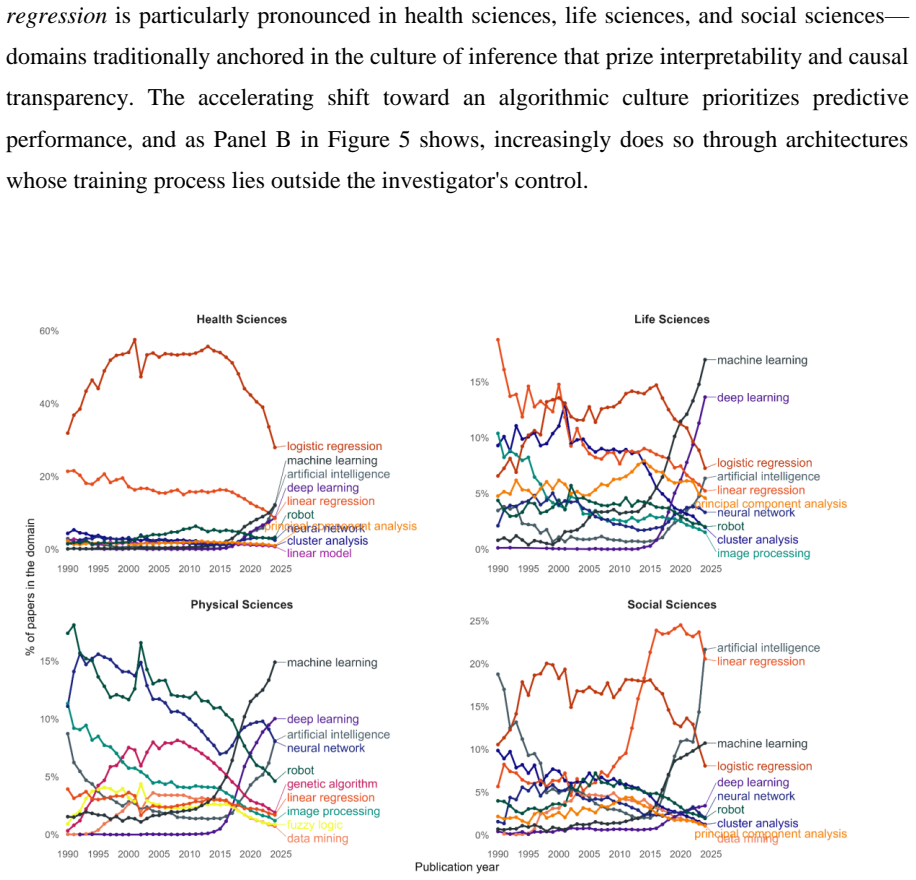
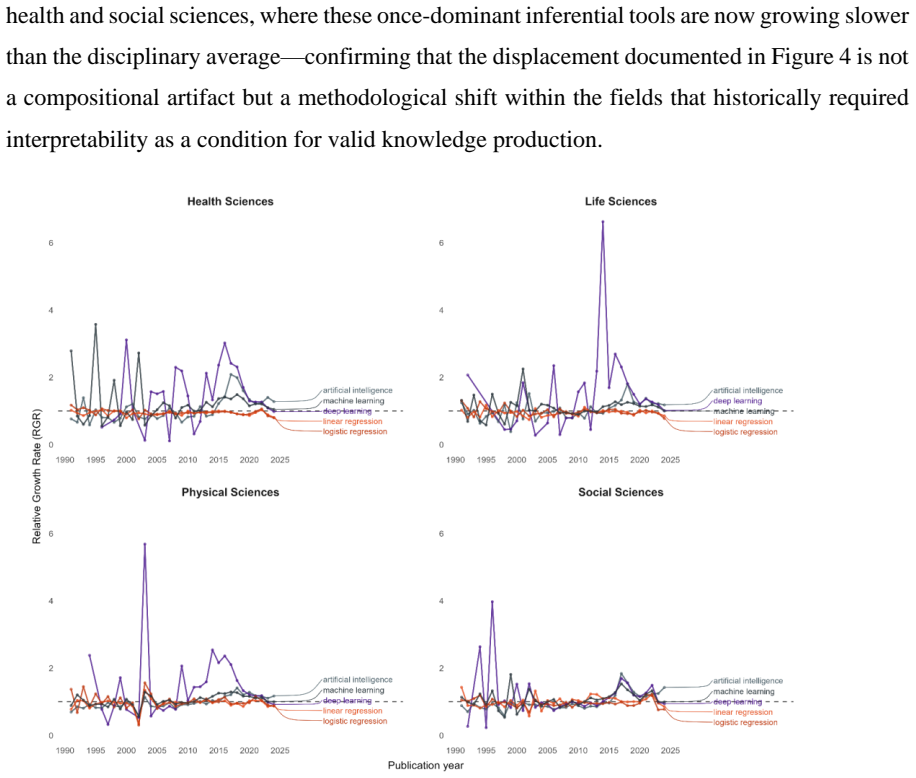
Machine learning displaces inference-oriented methods with predictive architectures in health and social sciences across two distinct waves since 2015.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A hierarchical taxonomy of 255 ML techniques and embedding-based semantic mapping applied to OpenAlex publications reveals a core-periphery structure in which physical sciences anchor the methodological core while health sciences show the largest growth. Predictive techniques cluster in computer science while inferential approaches remain distributed across applied domains. In health and social sciences the paper documents a displacement of inference by prediction that unfolds in two waves: the first (2015-2021) driven by deep learning architectures that lower predictive error yet increase epistemic opacity, and the second (post-2022) organized around a small set of architectures delivered b
What carries the argument
The hierarchical taxonomy of 255 ML techniques together with embedding-based semantic mapping, which distinguishes inferential from predictive approaches and tracks changes in validation regimes across disciplines.
If this is right
- Analytical capacity expands in health and social sciences as predictive architectures spread.
- The first wave reduces predictive error while introducing epistemic opacity through deep learning.
- The second wave adds opacity over inaccessible data and processes supplied by external companies.
- Validation regimes that once differed across domains are being reorganized around predictive performance.
- Scientific knowledge is now produced and evaluated under conditions that include components researchers cannot inspect or report.
Where Pith is reading between the lines
- Reproducibility standards may need revision when key pipeline elements lie outside researcher control.
- Physical sciences, positioned at the methodological core, may show slower adoption of the same displacement pattern.
- Funding and data-sharing policies could be adjusted to address the growing role of external company architectures.
- Similar semantic-mapping methods could test whether the two-wave pattern appears in additional disciplines beyond those examined.
Load-bearing premise
The taxonomy of ML techniques and the semantic mapping method correctly separate inferential from predictive approaches and detect genuine changes in how disciplines validate results.
What would settle it
A re-analysis of the same publication corpus that finds no net replacement of inferential by predictive techniques in health and social sciences after 2015, or that shows no measurable difference in opacity sources between the 2015-2021 and post-2022 periods.
Figures
read the original abstract
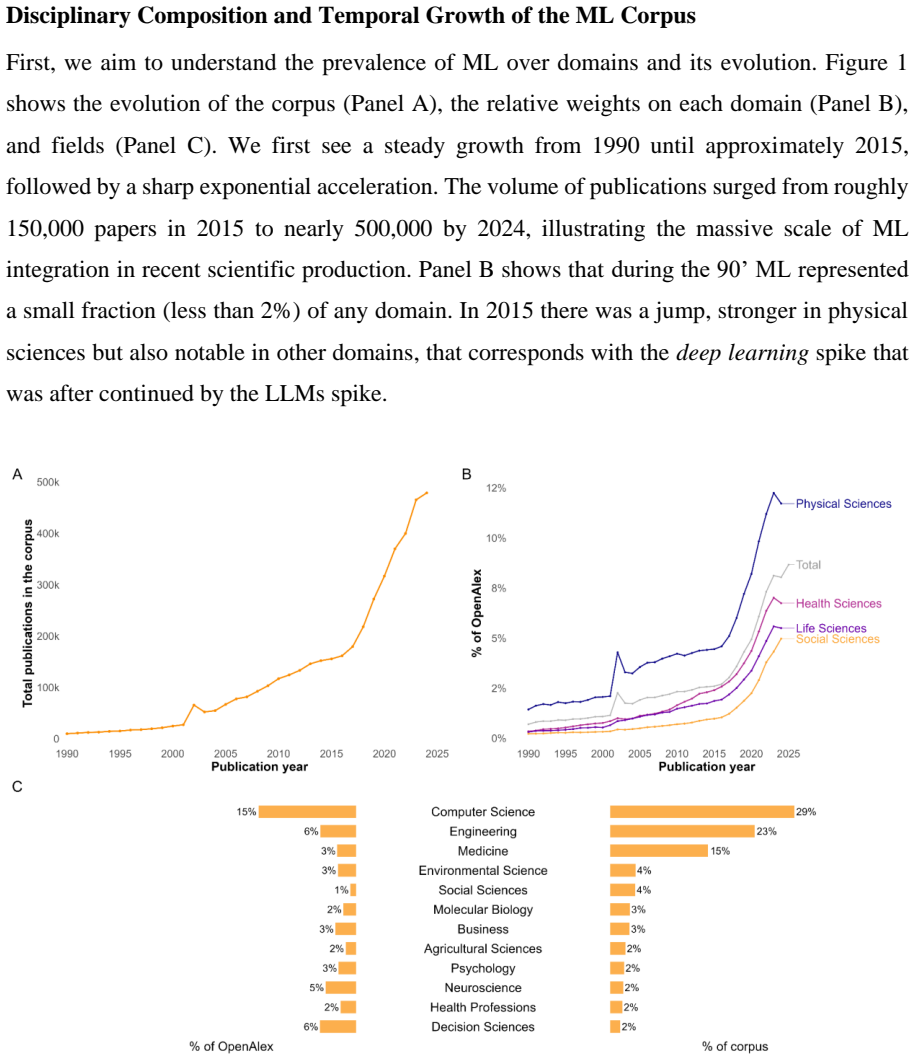
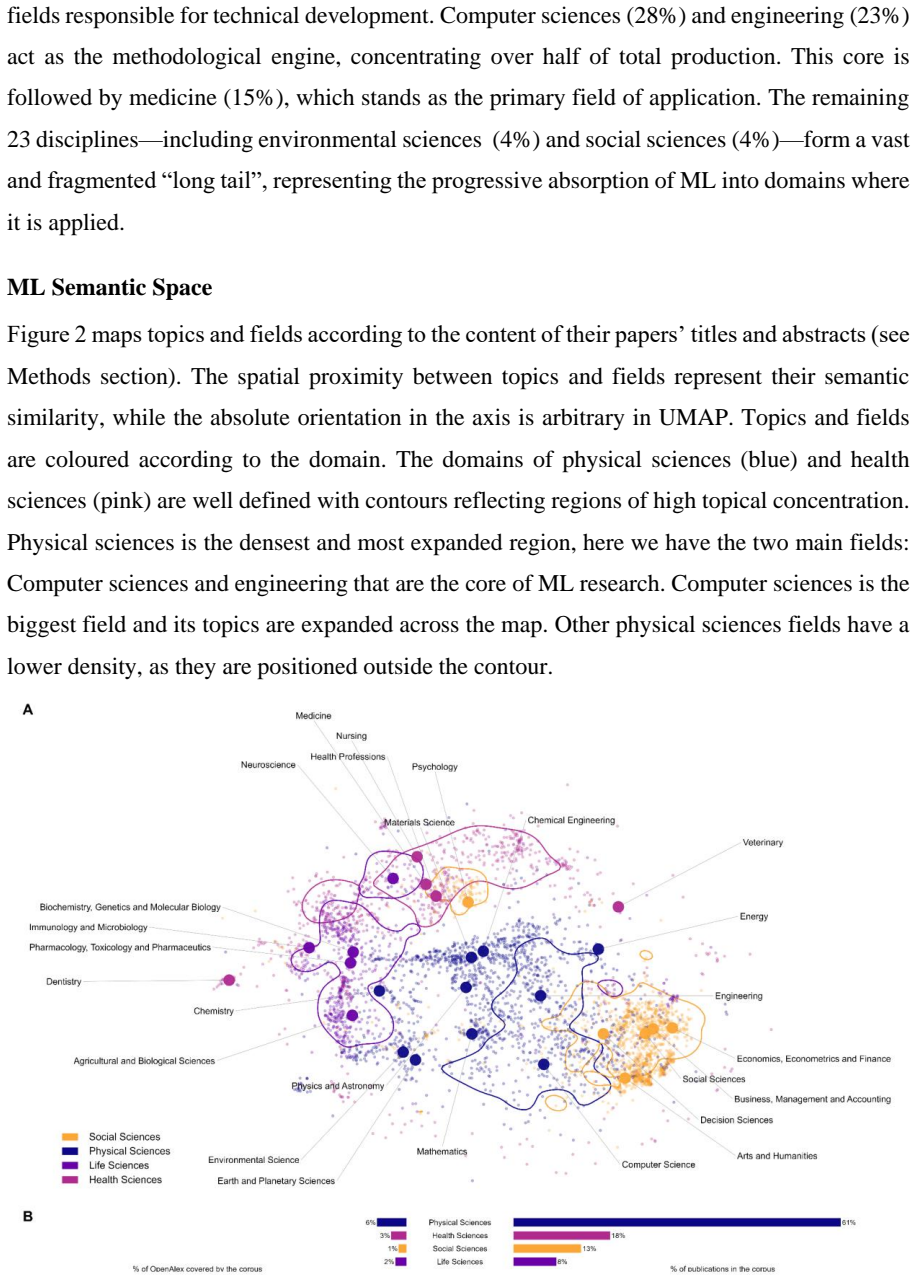
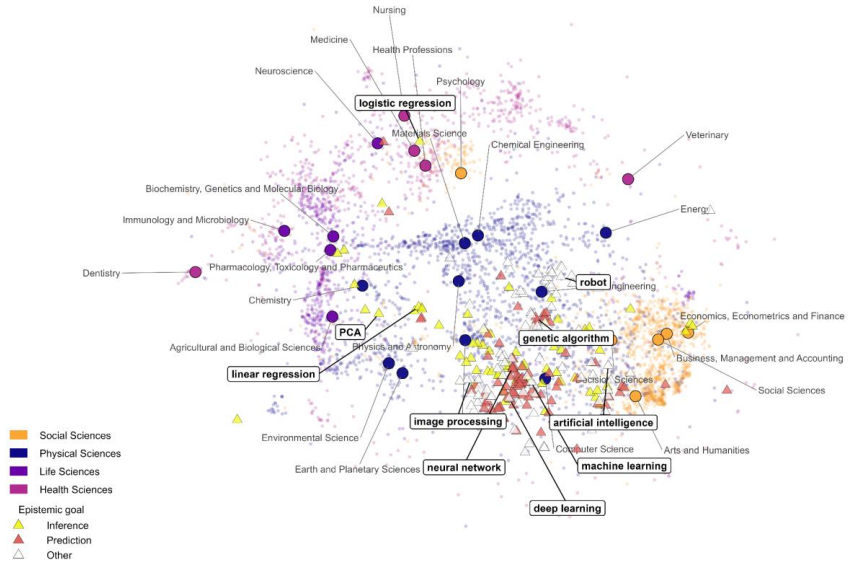
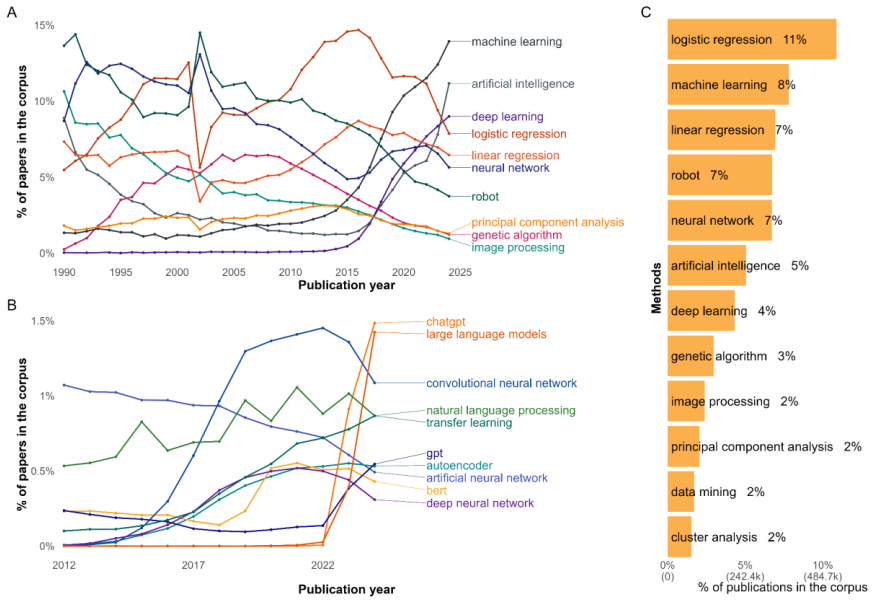
Machine learning (ML) has reshaped scientific practice across disciplines, yet its epistemic consequences remain poorly understood. This paper analyzes how its broad diffusion reconfigures the conditions under which scientific claims are produced and evaluated. Using a hierarchical taxonomy of 255 ML techniques and embedding-based semantic mapping, we analyze 4.9 million scientific publications from OpenAlex (1990-2025). We reconstruct the semantic space of ML research and show a core-periphery structure, with physical sciences forming the methodological core and health sciences representing the primary growth area. We identify distinct methodological profiles across domains: predictive techniques concentrate in computer sciences while inferential approaches remain distributed across applied fields, reflecting historically differentiated validation regimes. We observe the displacement of inference-oriented techniques by predictive architectures in domains that have traditionally prioritized interpretability-most notably health sciences and social sciences. This displacement unfolds in two qualitatively distinct waves. The first (2015-2021) was driven by deep learning architectures that reduced predictive error while introducing epistemic opacity. The second (post 2022) is organized around a small number of architectures delivered through external companies, introducing a further layer of opacity over data and processes that researchers cannot access or report. This transformation expands the analytical capacity of science, and also reorganizes the conditions under which scientific knowledge can be produced and evaluated.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that analysis of 4.9 million OpenAlex publications (1990-2025) via a hierarchical taxonomy of 255 ML techniques and embedding-based semantic mapping reveals a core-periphery structure in ML research, with predictive techniques concentrating in computer science and inference-oriented ones distributed across applied fields. It identifies displacement of inference by predictive architectures in health and social sciences unfolding in two waves (2015-2021 deep learning; post-2022 external company architectures), expanding capacity while increasing epistemic opacity over data and processes.
Significance. If the taxonomy and mapping are robust, the work supplies a large-scale empirical reconstruction of ML diffusion and its effects on validation regimes across disciplines. The 4.9M-paper corpus and identification of temporally distinct waves constitute a data-driven contribution to understanding how ML reorganizes scientific knowledge production. The embedding approach to semantic mapping is a methodological strength for tracing technique profiles.
major comments (2)
- [Methods] Methods (taxonomy and labeling): The hierarchical taxonomy of 255 ML techniques is used to partition inferential from predictive approaches and to identify the two displacement waves; however, no inter-rater reliability statistics, external validation against expert labels, ablation on boundary definitions, or sensitivity tests on the embedding mapping are reported. This directly undermines the link between observed corpus patterns and the claimed epistemic regime shifts.
- [Results] Results (wave identification): The claim that the post-2022 wave is 'organized around a small number of architectures delivered through external companies' and introduces a further layer of opacity requires explicit quantification of company-architecture prevalence and a demonstration that the embedding distances preserve epistemic (rather than merely technical) distinctions; without these, the qualitative distinction between the two waves rests on untested classification choices.
minor comments (1)
- [Abstract] Abstract: The phrase 'reconstruct the semantic space of ML research' is used without a forward reference to the specific embedding method or dimensionality reduction technique employed.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which identify key areas where additional rigor can strengthen the manuscript. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Methods] Methods (taxonomy and labeling): The hierarchical taxonomy of 255 ML techniques is used to partition inferential from predictive approaches and to identify the two displacement waves; however, no inter-rater reliability statistics, external validation against expert labels, ablation on boundary definitions, or sensitivity tests on the embedding mapping are reported. This directly undermines the link between observed corpus patterns and the claimed epistemic regime shifts.
Authors: We acknowledge that the manuscript does not include inter-rater reliability statistics or external expert validation for the taxonomy. The taxonomy was derived from a systematic synthesis of existing ML classifications in the literature. In the revised manuscript we will add sensitivity tests on the embedding mapping parameters and ablation analyses on the inferential/predictive boundary definitions. A full external inter-rater study lies beyond the scope of the current revision and will be noted as a limitation. revision: partial
-
Referee: [Results] Results (wave identification): The claim that the post-2022 wave is 'organized around a small number of architectures delivered through external companies' and introduces a further layer of opacity requires explicit quantification of company-architecture prevalence and a demonstration that the embedding distances preserve epistemic (rather than merely technical) distinctions; without these, the qualitative distinction between the two waves rests on untested classification choices.
Authors: We agree that explicit quantification is required. The revised results section will report quantitative prevalence statistics for company-associated architectures in the post-2022 period, derived from affiliation and technique co-occurrence data in the corpus. We will also add analysis correlating embedding distances with paper-level indicators of validation practices to demonstrate that the mappings capture epistemic rather than purely technical distinctions. revision: yes
Circularity Check
No circularity: empirical corpus analysis with independent classification step
full rationale
The paper conducts a large-scale empirical mapping of 4.9M publications using a pre-defined hierarchical taxonomy of 255 ML techniques plus embedding-based semantic analysis. No equations, fitted parameters, or first-principles derivations are presented whose outputs reduce to the authors' own inputs by construction. The distinction between inferential and predictive techniques is a methodological labeling choice applied to the corpus; the reported waves (2015-2021 deep learning, post-2022 external architectures) are observational trends in that labeled data rather than quantities forced by self-definition or self-citation chains. The analysis is self-contained against external benchmarks (OpenAlex corpus) and does not rely on load-bearing self-citations or uniqueness theorems imported from the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption OpenAlex database provides a representative sample of scientific publications from 1990-2025
- domain assumption The 255-technique taxonomy and embedding mapping distinguish inferential from predictive validation regimes
Reference graph
Works this paper leans on
-
[1]
(2018) The locus of legitimate interpretation in Big Data sciences: Lessons for computational social science from -omic biology and high-energy physics
Bartlett A, Lewis J, Reyes-Galindo L, et al. (2018) The locus of legitimate interpretation in Big Data sciences: Lessons for computational social science from -omic biology and high-energy physics. Big Data & Society 5(1): 2053951718768831. Benz P, Pradier C, Kozlowski D, et al. (2025) Mapping the unseen in practice: comparing latent Dirichlet allocation ...
2018
-
[2]
Journal of Machine Learning Research 3: 993–1022
23 Blei D, Ng A and Jordan M (2003) Latent Dirichlet Allocation. Journal of Machine Learning Research 3: 993–1022. Borgman CL and Brand A (2024) The Future of Data in Research Publishing: From Nice to Have to Need to Have? Harvard Data Science Review (Special Issue 4). Epub ahead of print 2 April
2003
-
[3]
DOI: 10.1162/99608f92.b73aae77. Borgohain DJ, Bhardwaj RK and Verma MK (2022) Mapping the literature on the application of artificial intelligence in libraries (AAIL): a scientometric analysis. Library Hi Tech 42(1): 149–179. Breiman L (2001) Statistical Modeling: The Two Cultures. Statist. Sci. (16(3)). Epub ahead of print
-
[4]
Brown TB, Mann B, Ryder N, et al
DOI: 10.1214/ss/1009213726. Brown TB, Mann B, Ryder N, et al. (2020) Language Models are Few-Shot Learners. arXiv:2005.14165. arXiv. Available at: http://arxiv.org/abs/2005.14165 (accessed 2 March 2026). Burrell J (2016) How the machine ‘thinks’: Understanding opacity in machine learning algorithms. Big Data & Society 3(1): 2053951715622512. Bzdok D, Altm...
-
[5]
Scientometrics 130(9): 5093–5114
Ding L, Lawson C and Shapira P (2025) Rise of Generative Artificial Intelligence in Science. Scientometrics 130(9): 5093–5114. Ding L, Lawson C and Shapira P (2026) Tracking AI’s Scientific Anatomy: A Novel Framework for Analyzing the Use and Diffusion of AI in Science. Epub ahead of print
2025
-
[6]
(2024) Oil & Water? Diffusion of AI Within and Across Scientific Fields
Duede E, Dolan W, Bauer A, et al. (2024) Oil & Water? Diffusion of AI Within and Across Scientific Fields. arXiv:2405.15828. arXiv. Available at: http://arxiv.org/abs/2405.15828 (accessed 25 February 2026). Dwivedi R and Elluri L (2024) Exploring Generative Artificial Intelligence Research: A Bibliometric Analysis Approach. IEEE Access 12: 119884–119902. ...
arXiv 2024
-
[7]
DOI: 10.1038/s41586-025-09922-y. Hastie T, Tibshirani R and Friedman J (2017) The Elements of Stadistical Learning: Data Mining, Inference, and Prediction. Springer International Publishing. Available at: https://www.sas.upenn.edu/~fdiebold/NoHesitations/BookAdvanced.pdf. He K, Zhang X, Ren S, et al. (2015) Deep Residual Learning for Image Recognition. In...
-
[8]
Iliadis A and Russo F (2016) Critical data studies: An introduction
DOI: 10.1007/s00146-025-02835-4. Iliadis A and Russo F (2016) Critical data studies: An introduction. Big Data & Society 3(2): 2053951716674238. Ioffe S and Szegedy C (2015) Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. Epub ahead of print
-
[9]
(2025) Application of artificial intelligence in academic libraries: a bibliometric analysis and knowledge mapping
Islam MN, Ahmad S, Aqil M, et al. (2025) Application of artificial intelligence in academic libraries: a bibliometric analysis and knowledge mapping. Discover Artificial Intelligence 5(1):
2025
-
[10]
(2023) An Introduction to Statistical Learning with Applications in R
James G, Witten D, Hastie T, et al. (2023) An Introduction to Statistical Learning with Applications in R. Second Edition. Springer. Available at: https://www.tandfonline.com/doi/full/10.1080/24754269.2021.1980261 (accessed 6 December 2025). Jordan MI and Mitchell TM (2015) Machine learning: Trends, perspectives, and prospects. Science Vol. 349(Issue 6245...
-
[11]
Expert Systems with Applications 186: 115728
Su M, Peng H and Li S (2021) A visualized bibliometric analysis of mapping research trends of machine learning in engineering (MLE). Expert Systems with Applications 186: 115728. Van Der Vlist F, Helmond A and Ferrari F (2024) Big AI: Cloud infrastructure dependence and the industrialisation of artificial intelligence. Big Data & Society 11(1): 2053951724...
Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.