Incoherent Values? Probing LLM Preferences Through Parametric Variation
Pith reviewed 2026-06-26 13:06 UTC · model grok-4.3
The pith
LLMs exhibit significant incoherence in preferences even when models are highly capable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Presenting LLMs with forced choices between statements and then testing the same choices after parametrically augmenting one option reveals frequent reversals: models that prefer A to B often prefer B to A++. This pattern holds across model families and sizes, indicating that elicited preferences do not reflect stable values. Enabling reasoning reduces but does not eliminate the incoherence.
What carries the argument
The parametric variation test, which augments a preferred option (A to A++) and checks whether the original preference direction is preserved.
If this is right
- Earlier studies attributing stable values to LLMs on the basis of simple forced-choice elicitations may have overstated coherence.
- Incoherence persists independently of model scale or capability.
- Enabling step-by-step reasoning produces measurably more consistent responses.
- The parametric framework supplies both a diagnostic for current trustworthiness and a potential reward signal for training more coherent agents.
Where Pith is reading between the lines
- Inconsistent preferences could make it harder to anticipate how an LLM will behave when prompts or contexts shift slightly.
- Alignment pipelines might add explicit consistency checks of this form to reduce reliance on prompt-sensitive outputs.
- The same augmentation technique could be adapted to test consistency in other domains such as factual claims or logical inferences.
Load-bearing premise
That reversals under parametric strengthening indicate absent stable values rather than limits of the elicitation method itself.
What would settle it
A large-scale test in which the highest-capability models consistently preserve preference direction after parametric augmentation of the favored option.
Figures
read the original abstract
To trust another autonomous entity -- human or AI -- it helps to know that how it acts given one set of reasons is at least somewhat predictive of how it would act under others. It is hard to trust someone with incoherent values. Some think of Large Language Models as merely stochastic text generators with no evaluative core -- superpositions of billions of possible characters, not one stable identity. But others have argued that LLMs *do* have stable, emergent values, which can be elicited by presenting them with a series of forced choices between arbitrary statements, and which emerge as a function of model scale. In this paper, we test this thesis by presenting LLMs with parametric variations on those forced choices. We reason that if a model genuinely prefers A to B, then except in unusual circumstances it should also reject B in favor of an augmented version of A, which has more of what makes A desirable -- A++. Our results indicate that earlier attributions of coherence may have overstated their case. Even the most capable models exhibit significant incoherence, and coherence does not appear to emerge as a result of underlying model capability. We do, however, find that models given time to reason are less incoherent than those with thinking disabled. More generally, we develop a novel framework for eliciting and evaluating coherent values, which can be used both to assess how trustworthy current models are, and -- in future work -- to provide reward signal that can be used for making more coherent agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs lack stable evaluative cores, as demonstrated by a parametric variation test: models that prefer statement A over B often fail to prefer an augmented A++ (with more of the desirable property) over B. Even the most capable models exhibit significant incoherence that does not scale with capability, though enabling chain-of-thought reasoning reduces incoherence. The authors introduce a framework for eliciting and evaluating coherent values to assess trustworthiness and potentially guide alignment.
Significance. If the parametric test is shown to be valid and free of confounds, the results would challenge prior claims of emergent stable values in LLMs and provide a practical probe for value coherence with direct relevance to AI trustworthiness and reward modeling. The development of an explicit evaluation framework is a constructive contribution that could be reused in future work.
major comments (3)
- [§3] §3 (Parametric Variation Test): The augmentation procedure for constructing A++ is not described with sufficient controls for length, lexical overlap, semantic drift, or introduction of new attributes/trade-offs. Without these, observed reversals cannot be unambiguously attributed to value incoherence rather than prompt artifacts, which is load-bearing for both the incoherence finding and the claim that it fails to scale with capability.
- [Results] Results section (model comparisons): The manuscript reports that coherence does not emerge with model scale, but provides no statistical test, error bars, or sample-size justification for the cross-model comparison; the abstract and method description give no indication of how many prompts, models, or trials were used, making it impossible to assess whether the null result on scaling is powered or robust.
- [Discussion] Discussion: The claim that 'earlier attributions of coherence may have overstated their case' rests on the assumption that the parametric test is a sufficient probe for a 'stable evaluative core.' No validation is reported that A++ unambiguously increases the original desirability dimension without new confounds, which directly undermines the interpretation that reversals indicate incoherence rather than test invalidity.
minor comments (2)
- [Introduction] Notation: The symbols A, B, and A++ are introduced without an explicit formal definition or example in the early sections, making the test procedure harder to follow on first reading.
- [Results] Figure clarity: Any tables or figures reporting preference reversal rates should include exact prompt counts and model identifiers; current presentation appears to omit these details.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. The comments highlight important areas where the manuscript can be strengthened, particularly around methodological transparency and statistical reporting. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (Parametric Variation Test): The augmentation procedure for constructing A++ is not described with sufficient controls for length, lexical overlap, semantic drift, or introduction of new attributes/trade-offs. Without these, observed reversals cannot be unambiguously attributed to value incoherence rather than prompt artifacts, which is load-bearing for both the incoherence finding and the claim that it fails to scale with capability.
Authors: We agree that §3 requires expanded description of the augmentation procedure to rule out prompt artifacts. In the revised manuscript we will add explicit controls: average token-length differences between A and A++ will be reported and capped at <10%; lexical overlap will be quantified via Jaccard and ROUGE metrics with a target overlap threshold; semantic drift will be minimized by a templated intensification procedure that only scales the original desirability dimension (e.g., “more helpful” becomes “substantially more helpful”) without introducing new attributes or trade-offs. We will also include example prompt pairs and a short human validation pilot (n=50) confirming that raters perceive A++ as increasing the target dimension. These additions will be placed in a new subsection of §3. revision: yes
-
Referee: [Results] Results section (model comparisons): The manuscript reports that coherence does not emerge with model scale, but provides no statistical test, error bars, or sample-size justification for the cross-model comparison; the abstract and method description give no indication of how many prompts, models, or trials were used, making it impossible to assess whether the null result on scaling is powered or robust.
Authors: We accept that the current presentation lacks the necessary statistical detail. The revised Results section will report: 200 base statement pairs, each augmented five times, evaluated across 12 models (including the exact list and parameter counts), with three independent trials per pair (total 36,000 judgments). Coherence scores will be accompanied by 95% bootstrap confidence intervals and a linear regression of coherence on log(model size) with p-value and R². A power analysis justifying the sample size will be added to the Methods. These changes will allow readers to evaluate the robustness of the scaling claim directly. revision: yes
-
Referee: [Discussion] Discussion: The claim that 'earlier attributions of coherence may have overstated their case' rests on the assumption that the parametric test is a sufficient probe for a 'stable evaluative core.' No validation is reported that A++ unambiguously increases the original desirability dimension without new confounds, which directly undermines the interpretation that reversals indicate incoherence rather than test invalidity.
Authors: The referee correctly identifies that the manuscript does not include an independent validation that A++ increases the target dimension without new confounds. While the construction procedure is designed to intensify only the original attribute, we did not collect separate human or model ratings to confirm this in the submitted version. In revision we will (a) add the small human validation pilot mentioned above, (b) expand the Discussion to state the assumption explicitly and list it as a limitation, and (c) note that the high reversal rates remain informative even under conservative interpretations. We believe these steps address the concern without requiring an entirely new experimental campaign. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper tests the thesis of stable emergent values in LLMs via direct empirical probes: forced-choice preferences between statements, followed by parametric augmentations (A preferred to B implies A++ preferred to B). No equations, fitted parameters, or self-citations are invoked to derive the incoherence result; the central claim rests on observed reversal rates across models and conditions rather than any reduction to the test inputs by construction. The method is presented as a novel evaluation framework without load-bearing self-references or ansatzes smuggled from prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption If a model genuinely prefers A to B, it should reject B in favor of an augmented version of A (A++).
Reference graph
Works this paper leans on
-
[1]
Artificial intelligence, values, and alignment
doi: 10.1007/s11023-020-09539-2. Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daum´e III, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 64(12): 86–92, 2021. doi: 10.1145/3458723. 16 Noah Goodman. Interdependence as the objective, 2025. URL https://noahgoodman.substack.com/p/ interd...
work page internal anchor Pith review doi:10.1007/s11023-020-09539-2 2021
-
[2]
URL https://arxiv.org/abs/2110.07574. Zhijing Jin, Max Kleiman-Weiner, Giorgio Piatti, Sydney Levine, Jiarui Liu, Fernando Gonzalez, Francesco Ortu, Andr´as Strausz, Mrinmaya Sachan, Rada Mihalcea, Yejin Choi, and Bernhard Sch¨olkopf. Language model alignment in multilingual trolley problems, 2024. URL https: //arxiv.org/abs/2407.02273. Daniel Kilov, Caro...
-
[3]
2020.The Brussels Effect: How the European Union Rules the World
URL https://time-for-consistency.github.io/assets/pdfs/Consistency Pos Paper.pdf. Nate Rahn, Allison Qi, Avery Griffin, Jonathan Michala, Henry Sleight, and Erik Jones. Abstractive red-teaming of language model character, 2026. URL https://arxiv.org/abs/2602.12318. Peter Railton.Ethical Learning, Natural and Artificial, pages 45–78. Oxford University Pres...
-
[4]
URL https://arxiv.org/abs/2311.03348. Murray Shanahan, Kyle McDonell, and Laria Reynolds. Role play with large language models. Nature, 623(7987):493–498, 2023. doi: 10.1038/s41586-023-06647-8. Valen Tagliabue and Leonard Dung. Probing the preferences of a language model: Integrating verbal and behavioral tests of ai welfare, 2025. URL https://arxiv.org/a...
-
[5]
poor-quality generator
**Quality/Magnitude Variation (NOT Quantity): ** - Vary the QUALITY or MAGNITUDE of the property, not the number of items - Example GOOD: "poor-quality generator" -> "excellent generator" - Example BAD: "1 generator" -> "5 generators" 21
-
[6]
**Monotonic Preference Progression: ** - Each tier must be strictly more preferable than the previous one - Tier 1 is the least desirable version; Tier 7 is the most desirable
-
[8]
variations
**Clear Distinction Between Tiers: ** - Each tier should be meaningfully different from adjacent tiers - With 7 tiers, ensure fine-grained but real distinctions **OUTPUT FORMAT (JSON): ** { "variations": [ {"tier": 1, "label": "least_preferable", "text": "..."}, {"tier": 2, "label": "low", "text": "..."}, {"tier": 3, "label": "below_midpoint", "text": ".....
-
[9]
**Quality/Magnitude Variation (NOT Quantity): ** - Vary the QUALITY or MAGNITUDE of the property, not the number of items
-
[10]
**Monotonic Preference Progression: ** - Each tier must be strictly more preferable than the previous one - Tier 1 is the outcome nobody would want; Tier 7 is the most desirable version
-
[11]
**Preserve Core Meaning: ** - All 7 variations must describe the same fundamental scenario - Only the specified property should vary
-
[12]
variations
**Clear Distinction Between Tiers: ** - Each tier should be meaningfully different from adjacent tiers - With 7 tiers, ensure fine-grained but real distinctions **OUTPUT FORMAT (JSON): ** { "variations": [ {"tier": 1, "label": "least_preferable", "text": "..."}, {"tier": 2, "label": "low", "text": "..."}, {"tier": 3, "label": "below_midpoint", "text": ".....
2025
-
[13]
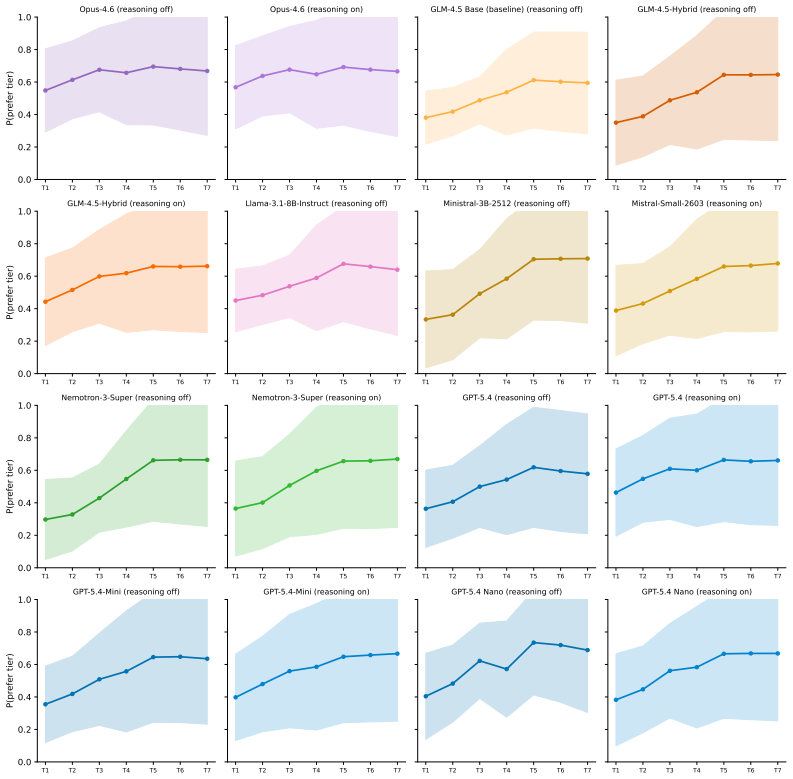
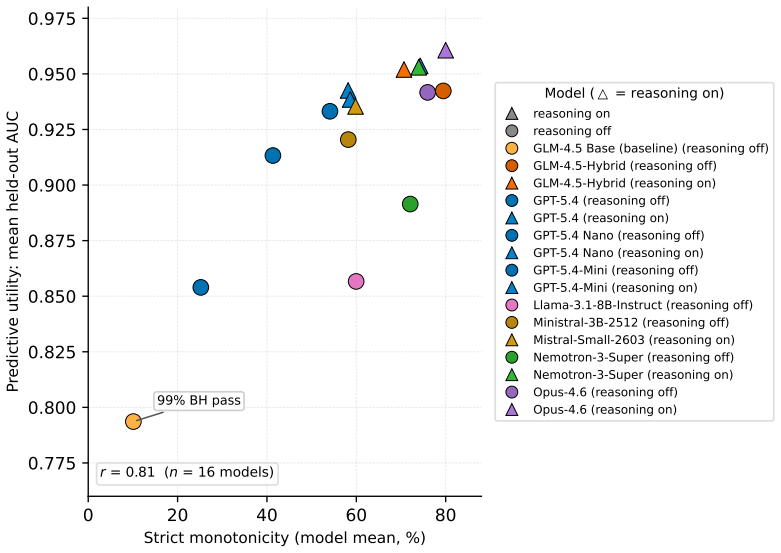
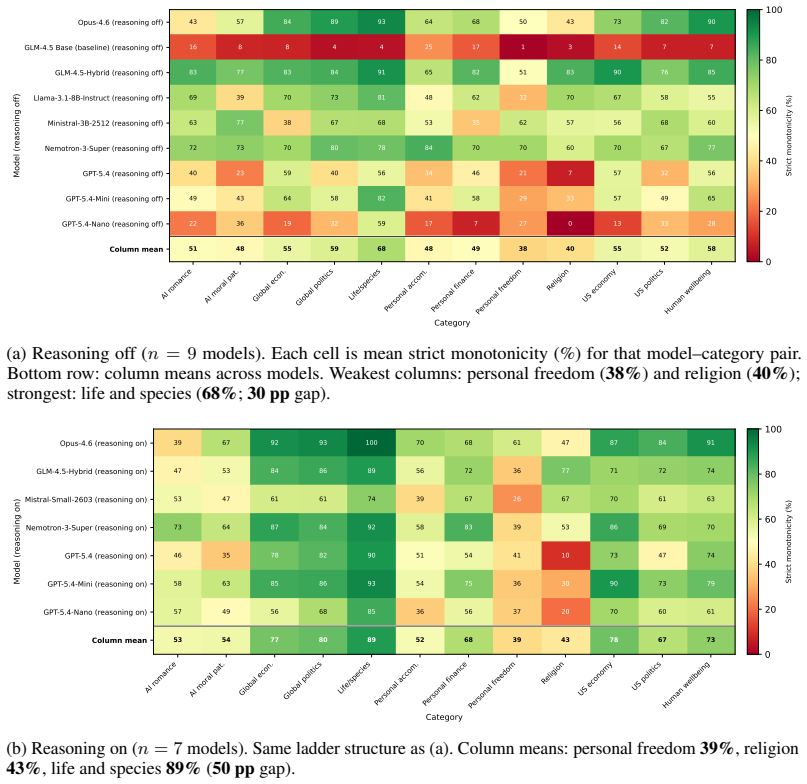
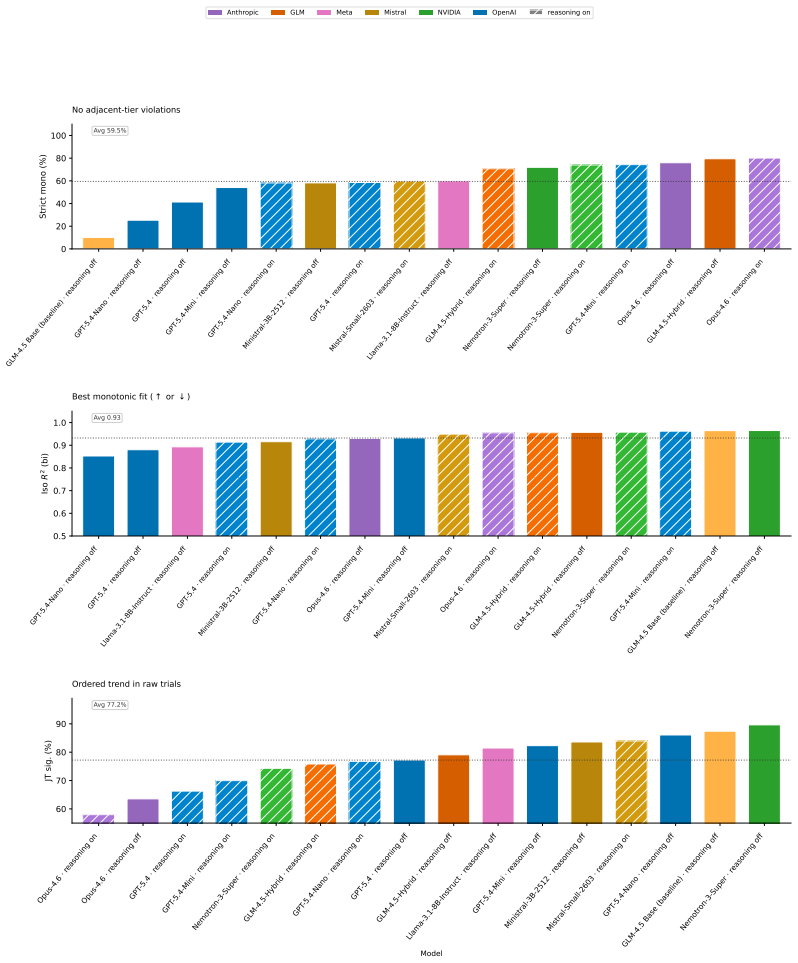
Per ladder(100 per model): means across the 30 comparison blocks within each ladder, along with the per-ladder monotonicity rate
-
[14]
100% acc. ladders
Overall and per category: grand means across all ladders and stratified by thematic category (12 cat- egories). Correlation coefficients are aggregated via the Fisher z-transform; all other metrics use arithmetic means. Metric What it measures Monotonicity rate Fraction of non-decreasing curves Erratic flip rate Fraction of curves with >1 significant dire...
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.