Error Exponent Bounds for Optimal Short-Read Clustering
Pith reviewed 2026-06-26 13:22 UTC · model grok-4.3
The pith
Upper and lower bounds on the error probability of optimal clustering are derived for noisy short sequences from unknown sources
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Focusing on the statistically optimal clustering rule, the paper derives upper and lower bounds on the probability of incorrect clustering as a function of the sequence length, the number of reads, and the channel statistics.
What carries the argument
The statistically optimal clustering rule that minimizes the probability of incorrect grouping of the observed noisy reads
If this is right
- The probability of incorrect clustering is bounded from above and below by expressions that depend on sequence length, read count, and channel statistics.
- Error probability decreases as sequence length or number of reads increases.
- Different channel statistics produce different bound values, allowing comparison across noise models.
- The bounds apply without any prior statistical knowledge of the source sequences.
Where Pith is reading between the lines
- The bounds could be used to select minimum sequence lengths needed for target reliability in DNA storage systems.
- Practical algorithms that approximate the optimal rule might achieve performance close to these bounds.
- The same bounding technique might extend to clustering problems outside DNA storage that involve short noisy strings from unknown origins.
Load-bearing premise
The source sequences are completely unknown and the channel is memoryless.
What would settle it
A direct computation or Monte Carlo simulation of the actual error probability for fixed sequence length, read count, and channel, checked against whether the value lies strictly between the derived upper and lower bounds.
Figures
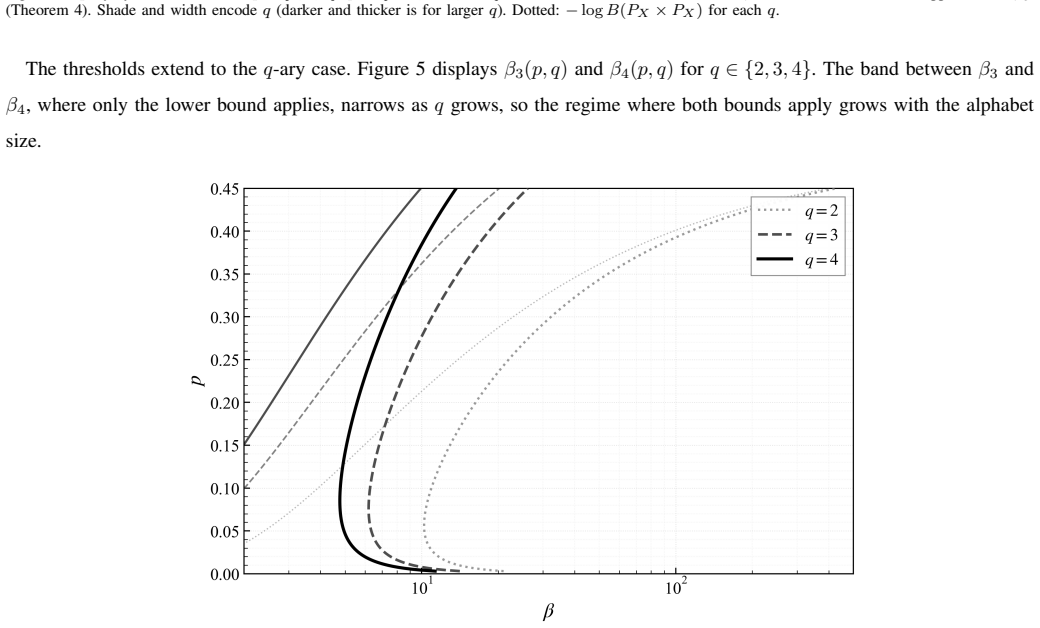
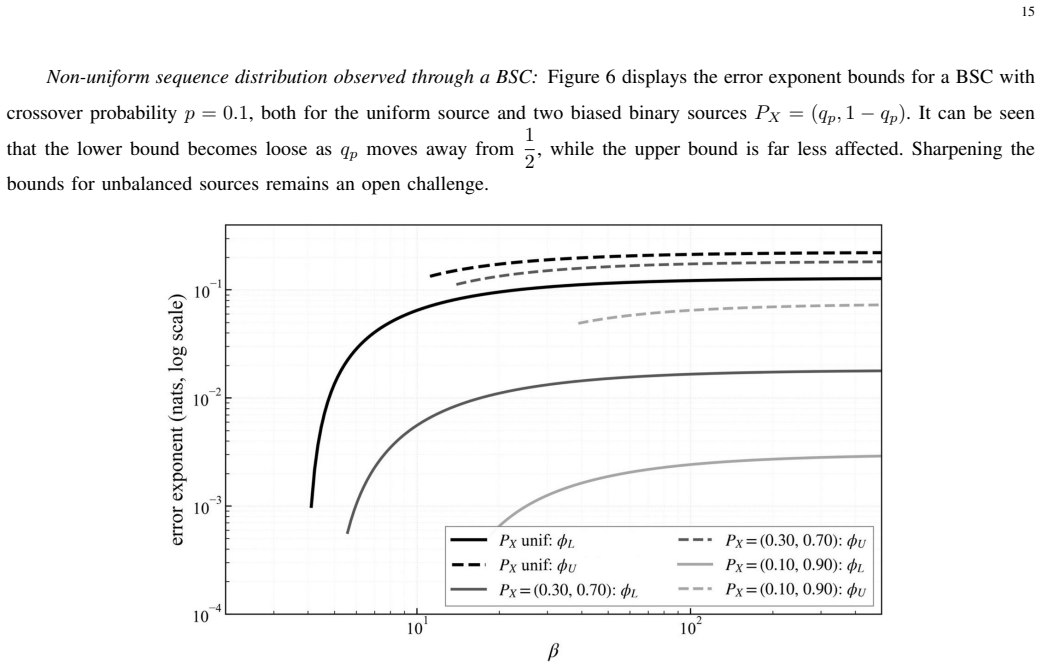
read the original abstract
Motivated by the operation of decoders for DNA storage, we consider the problem of unsupervised clustering of noisy short sequences, each generated from one of multiple possible unknown source sequences after passing through a memoryless channel. Focusing on the statistically optimal clustering rule, we derive upper and lower bounds on the probability of incorrect clustering as a function of the sequence length, the number of reads, and the channel statistics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript addresses unsupervised clustering of noisy short sequences, each generated from one of multiple unknown source sequences and passed through a memoryless channel, motivated by DNA storage decoder operation. It focuses on the statistically optimal clustering rule and derives upper and lower bounds on the probability of incorrect clustering expressed as functions of sequence length, number of reads, and channel statistics only.
Significance. If the derivations hold, the bounds offer parameter-free theoretical limits on clustering error that depend solely on observable channel statistics. This aligns with standard information-theoretic techniques for error exponents in clustering and could inform practical decoder design in DNA storage systems where source sequences are fixed but unknown.
minor comments (1)
- The abstract states that bounds are derived, but the provided text does not include the explicit derivation steps or verification; a full assessment of the central claim requires the detailed proofs in the body of the manuscript.
Simulated Author's Rebuttal
We thank the referee for their review and for accurately summarizing the manuscript's focus on deriving upper and lower bounds on clustering error probability for unsupervised clustering of noisy short sequences in the context of DNA storage decoders. We note that the referee raises no specific major comments or concerns about the derivations, technical details, or presentation.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper derives upper and lower bounds on P(incorrect clustering) for the statistically optimal rule, expressed as functions of sequence length, number of reads, and channel statistics under memoryless channels with unknown sources. No load-bearing steps reduce by construction to fitted inputs, self-citations, or ansatzes; the setup matches standard information-theoretic error analysis without hidden dependencies on the target quantities. This is the expected honest non-finding for a direct bounding derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Expurgated bounds for the asymmetric broadcast channel.IEEE Transactions on Information Theory, 65(6):3412–3435, 2019
Ran Averbuch, Nir Weinberger, and Neri Merhav. Expurgated bounds for the asymmetric broadcast channel.IEEE Transactions on Information Theory, 65(6):3412–3435, 2019
2019
-
[2]
Minimum of average conditional entropy for given minimum probability of error.Kybernetika, 2(5):416–422, 1966
Libuše Baladová. Minimum of average conditional entropy for given minimum probability of error.Kybernetika, 2(5):416–422, 1966
1966
-
[3]
DNA-correcting codes: End-to-end correction in DNA storage systems.IEEE Transactions on Information Theory, 71(6):4214–4227, 2025
Avital Boruchovsky, Daniella Bar-Lev, and Eitan Yaakobi. DNA-correcting codes: End-to-end correction in DNA storage systems.IEEE Transactions on Information Theory, 71(6):4214–4227, 2025
2025
-
[4]
Chu and J
J. Chu and J. Chueh. Inequalities between information measures and error probability.Journal of the Franklin Institute, 282(2):121–125, 1966
1966
-
[5]
Church, Yuan Gao, and Sriram Kosuri
George M. Church, Yuan Gao, and Sriram Kosuri. Next-generation digital information storage in DNA.Science, 337(6102):1628–1628, 2012
2012
-
[6]
I. Csiszár. The method of types.IEEE Transactions on Information Theory, 44(6):2505–2523, 1998
1998
-
[7]
Csiszár and J
I. Csiszár and J. Körner.Information Theory: Coding Theorems for Discrete Memoryless Systems. Cambridge University Press, 2011
2011
-
[8]
DNA fountain enables a robust and efficient storage architecture.Science, 355(6328):950–954, 2017
Yaniv Erlich and Dina Zielinski. DNA fountain enables a robust and efficient storage architecture.Science, 355(6328):950–954, 2017
2017
-
[9]
R. G. Gallager.Information Theory and Reliable Communication. John Wiley and Sons, 1968
1968
-
[10]
The random coding bound is tight for the average code (corresp.).IEEE Transactions on Information Theory, 19(2):244–246, 1973
Robert Gallager. The random coding bound is tight for the average code (corresp.).IEEE Transactions on Information Theory, 19(2):244–246, 1973
1973
-
[11]
Capacity of frequency-based channels: Encoding information in molecular concentrations.IEEE Transactions on Information Theory, 71(8):5788–5808, 2025
Yuval Gerzon, Ilan Shomorony, and Nir Weinberger. Capacity of frequency-based channels: Encoding information in molecular concentrations.IEEE Transactions on Information Theory, 71(8):5788–5808, 2025
2025
-
[12]
Goldman, S
N. Goldman, S. Bertone, P. Chen, C. Dessimoz, E. M. LeProust, B. Sipos, and E. Birney. Towards practical, high-capacity, low-maintenance information storage in synthesized DNA.Nature, 494(7435):77–80, 2013
2013
-
[13]
R. N. Grass, R. Heckel, M. Puddu, D. Paunescu, and Wendelin J. Stark. Robust chemical preservation of digital information on DNA in silica with error-correcting codes.Angewandte Chemie International Edition, 54(8):2552–2555, 2015
2015
-
[14]
Probability of error, equivocation, and the Chernoff bound.IEEE Transactions on Information Theory, 16(4):368–372, 1970
Martin Hellman and Josef Raviv. Probability of error, equivocation, and the Chernoff bound.IEEE Transactions on Information Theory, 16(4):368–372, 1970
1970
-
[15]
H. M. Kiah, G. J. Puleo, and O. Milenkovic. Codes for DNA sequence profiles.IEEE Transactions on Information Theory, 62(6):3125–3146, 2016
2016
-
[16]
Siegel, Antonia Wachter-Zeh, and Eitan Yaakobi
Andreas Lenz, Paul H. Siegel, Antonia Wachter-Zeh, and Eitan Yaakobi. An upper bound on the capacity of the DNA storage channel. In2019 IEEE Information Theory Workshop (ITW), pages 1–5. IEEE, 2019
2019
-
[17]
Siegel, Antonia Wachter-Zeh, and Eitan Yaakobi
Andreas Lenz, Paul H. Siegel, Antonia Wachter-Zeh, and Eitan Yaakobi. Achieving the capacity of the DNA storage channel. In2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 8846–8850. IEEE, 2020. 36
2020
-
[18]
Siegel, Antonia Wachter-Zeh, and Eitan Yaakobi
Andreas Lenz, Paul H. Siegel, Antonia Wachter-Zeh, and Eitan Yaakobi. The noisy drawing channel: Reliable data storage in DNA sequences.IEEE Transactions on Information Theory, 69(5):2757–2778, May 2023
2023
-
[19]
Efficient reconstruction of sequences.IEEE Transactions on Information Theory, 47(1):2–22, 2002
Vladimir I Levenshtein. Efficient reconstruction of sequences.IEEE Transactions on Information Theory, 47(1):2–22, 2002
2002
-
[20]
Y . H. Ling, N. Weinberger, and J. Scarlett. Error exponents for DNA storage codes with a variable number of reads.IEEE Journal on Selected Areas in Information Theory, pages 205–216, 2025
2025
-
[21]
Exact error exponents of concatenated codes for DNA storage.IEEE Transactions on Information Theory, 71(9):6566–6585, 2025
Yan Hao Ling and Jonathan Scarlett. Exact error exponents of concatenated codes for DNA storage.IEEE Transactions on Information Theory, 71(9):6566–6585, 2025
2025
-
[22]
Optimal overlap detection of shotgun reads.Submitted to IEEE Transactions on Information Theory, 2025
Nir Luria and Nir Weinberger. Optimal overlap detection of shotgun reads.Submitted to IEEE Transactions on Information Theory, 2025
2025
-
[23]
A toolbox for refined information-theoretic analyses with applications.Foundations and Trends in Communications and Information Theory, 22(1):1–184, 2025
Neri Merhav and Nir Weinberger. A toolbox for refined information-theoretic analyses with applications.Foundations and Trends in Communications and Information Theory, 22(1):1–184, 2025
2025
-
[24]
Organick, S
L. Organick, S. D. Ang, Y . Chen, R. Lopez, S. Yekhanin, K. Makarychev, M. Z. Racz, G. Kamath, P. Gopalan, and B. Nguyen. Random access in large-scale DNA data storage.Nature biotechnology, 36(3):242–248, 2018
2018
-
[25]
Arvind Rameshwar and Nir Weinberger
V . Arvind Rameshwar and Nir Weinberger. Information rates over multi-view channels.IEEE Transactions on Information Theory, 71(2):847–861, 2025
2025
-
[26]
Clustering billions of reads for DNA data storage.Advances in Neural Information Processing Systems, 30, 2017
Cyrus Rashtchian, Konstantin Makarychev, Miklos Racz, Siena Ang, Djordje Jevdjic, Sergey Yekhanin, Luis Ceze, and Karin Strauss. Clustering billions of reads for DNA data storage.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[27]
Arimoto–Rényi conditional entropy and Bayesianm-ary hypothesis testing.IEEE Transactions on Information theory, 64(1):4–25, 2017
Igal Sason and Sergio Verdú. Arimoto–Rényi conditional entropy and Bayesianm-ary hypothesis testing.IEEE Transactions on Information theory, 64(1):4–25, 2017
2017
-
[28]
DNA-based storage: Models and fundamental limits.IEEE Transactions on Information Theory, 67(6):3675–3689, 2021
Ilan Shomorony and Reinhard Heckel. DNA-based storage: Models and fundamental limits.IEEE Transactions on Information Theory, 67(6):3675–3689, 2021
2021
-
[29]
Information-theoretic foundations of DNA data storage.Foundations and Trends® in Communications and Information Theory, 19(1):1–106, 2022
Ilan Shomorony and Reinhard Heckel. Information-theoretic foundations of DNA data storage.Foundations and Trends® in Communications and Information Theory, 19(1):1–106, 2022
2022
-
[30]
Shulman.Communication over an unknown channel via common broadcasting
N. Shulman.Communication over an unknown channel via common broadcasting. PhD thesis, Tel-Aviv University, Tel-Aviv, Israel, 2003
2003
-
[31]
On coding over sliced information.IEEE Transactions on Information Theory, 67(5):2793–2807, 2021
Jin Sima, Netanel Raviv, and Jehoshua Bruck. On coding over sliced information.IEEE Transactions on Information Theory, 67(5):2793–2807, 2021
2021
-
[32]
Error correction for DNA storage.IEEE BITS the Information Theory Magazine, 3(3):78–94, 2023
Jin Sima, Netanel Raviv, Moshe Schwartz, and Jehoshua Bruck. Error correction for DNA storage.IEEE BITS the Information Theory Magazine, 3(3):78–94, 2023
2023
-
[33]
Achievable rates and error probability bounds of frequency-based channels of unlimited input resolution.IEEE Journal on Selected Areas in Information Theory, 6:283–295, 2025
Ran Tamir and Nir Weinberger. Achievable rates and error probability bounds of frequency-based channels of unlimited input resolution.IEEE Journal on Selected Areas in Information Theory, 6:283–295, 2025
2025
-
[34]
Error probability bounds for coded-index DNA storage systems.IEEE Transactions on Information Theory, 68(11):7005–7022, 2022
Nir Weinberger. Error probability bounds for coded-index DNA storage systems.IEEE Transactions on Information Theory, 68(11):7005–7022, 2022
2022
-
[35]
The DNA storage channel: Capacity and error probability bounds.IEEE Transactions on Information Theory, 68(9):5657–5700, 2022
Nir Weinberger and Neri Merhav. The DNA storage channel: Capacity and error probability bounds.IEEE Transactions on Information Theory, 68(9):5657–5700, 2022
2022
-
[36]
Fundamental limits of reference-based sequence reordering.IEEE Transactions on Information Theory, 70(7):4634– 4654, 2024
Nir Weinberger and Ilan Shomorony. Fundamental limits of reference-based sequence reordering.IEEE Transactions on Information Theory, 70(7):4634– 4654, 2024
2024
-
[37]
S. M. H. T. Yazdi, Y . Yuan, J. Ma, H. Zhao, and O. Milenkovic. A rewritable, random-access DNA-based storage system.Scientific reports, 5(1):1–10, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.