CORTIS: Text-Only Adaptation of Spoken Language Models for Task-Oriented Voice Agents
Pith reviewed 2026-06-26 13:21 UTC · model grok-4.3
The pith
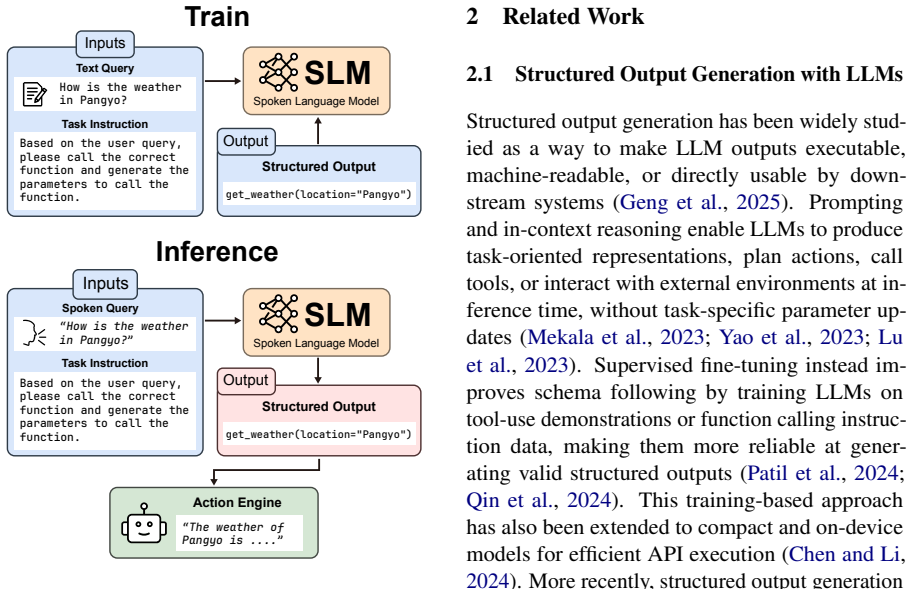
CORTIS adapts spoken language models to generate structured outputs from speech using only text-form task supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
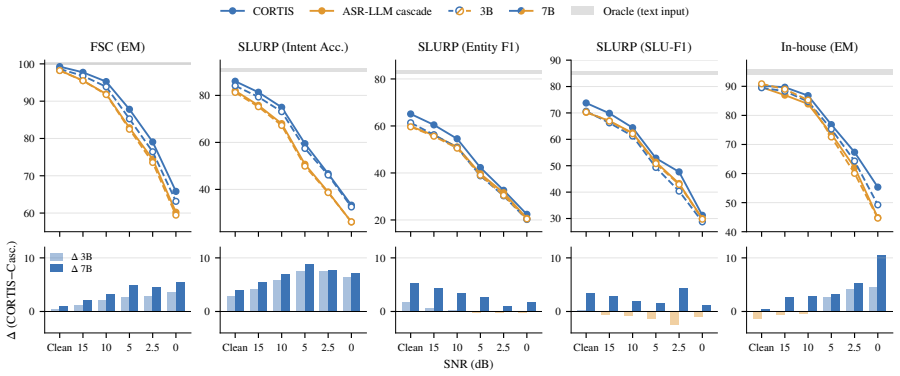
CORTIS fine-tunes SLMs using text-form task supervision, enabling speech-based structured output generation at inference time without task-specific speech-target annotations during adaptation. On two Qwen2.5-Omni backbones and three task-oriented speech datasets it performs competitively with matched ASR-LLM cascades trained on identical text supervision and shows clearer advantages under acoustic degradation, particularly in preserving high-level task semantics.
What carries the argument
CORTIS, the text-only adaptation framework that transfers task supervision from text to the speech-to-structured-output mapping inside an SLM.
If this is right
- CORTIS matches the accuracy of ASR-LLM cascades on standard task-oriented speech datasets.
- It maintains higher task-semantic fidelity than cascades when input audio is degraded.
- The same text-only procedure works across different SLM backbones and both public and in-house product datasets.
- It removes the requirement to collect paired speech-target annotations for each new task.
Where Pith is reading between the lines
- Voice-agent developers could iterate on new domains by writing text task examples alone rather than recording speech.
- The approach may reduce downstream error propagation in environments where transcription quality is unreliable.
- Similar text-only transfer could be tested on other structured output tasks such as slot filling or API call generation.
Load-bearing premise
Text-form task supervision alone is sufficient to transfer the speech-to-structured-output mapping without any task-specific speech-target pairs during adaptation.
What would settle it
Apply CORTIS to a new task-oriented speech dataset recorded under strong acoustic degradation and measure whether its structured-output accuracy drops substantially below a matched ASR-LLM cascade trained on the same text supervision.
Figures

read the original abstract
Task-oriented voice agents need to map spoken user requests to structured outputs such as semantic frames, executable actions, and function calls. A common approach is to cascade ASR with a text-based LLM, but transcription errors can propagate to downstream structured output generation, especially under noisy conditions. Spoken language models (SLMs) offer a direct speech-based alternative, yet adapting them to new tasks typically requires paired speech-target annotations. Motivated by this gap, we present CORTIS, a text-only adaptation framework for task-oriented voice agents. CORTIS fine-tunes SLMs using text-form task supervision, enabling speech-based structured output generation at inference time without task-specific speech-target annotations during adaptation. We evaluate CORTIS on two Qwen2.5-Omni backbones and three task-oriented speech datasets, including an in-house product dataset, and compare it with matched ASR-LLM cascades trained with the same text-form task supervision. Results show that CORTIS performs competitively with matched cascades and offers clearer advantages under acoustic degradation, particularly in preserving high-level task semantics. These findings suggest that text-only fine-tuning of SLMs can serve as a practical adaptation strategy for voice agents when paired speech-target data are costly to collect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CORTIS, a text-only adaptation framework for spoken language models (SLMs) that enables task-oriented structured output generation (semantic frames, actions, function calls) from speech. By fine-tuning SLMs such as Qwen2.5-Omni variants solely on text-form task supervision, the method claims to achieve speech-based inference without any task-specific speech-target pairs during adaptation. Evaluations across three task-oriented speech datasets, including an in-house product dataset, report competitive performance against matched ASR-LLM cascades trained with identical text supervision, with clearer advantages under acoustic degradation in preserving high-level task semantics.
Significance. If the central claim holds, the work offers a practical route to adapting SLMs for voice agents when paired speech annotations are expensive or unavailable, potentially improving robustness in noisy conditions without cascading transcription errors. The approach is notable for attempting to leverage pre-trained speech capabilities via text-only updates, which could lower barriers in human-computer interaction applications if the speech pathway is demonstrably engaged by the adaptation.
major comments (3)
- [Method] Method section: the description of the fine-tuning procedure does not state whether the speech encoder parameters are updated or frozen while text-only task supervision is applied to the decoder. This detail is load-bearing for the claim that text-form supervision alone transfers the speech-to-structured-output mapping; if the encoder remains frozen, any noise-robustness advantage would derive only from the base SLM pre-training rather than CORTIS, undermining isolation from the ASR-LLM baseline.
- [Experiments] Experiments / Results: the central claim of competitive performance and clearer advantages under acoustic degradation is presented without reference to specific quantitative metrics (accuracy, semantic frame F1, error rates), dataset sizes, exclusion criteria, or statistical tests in the provided text. Without these, the comparison to cascades cannot be verified and the robustness advantage cannot be assessed for effect size or significance.
- [§4] §4 (Evaluation): the comparison to ASR-LLM cascades uses the same text-form supervision, but does not report an ablation that isolates the effect of text-only SLM adaptation versus simply using the frozen SLM backbone; this leaves open whether the reported gains under degradation are attributable to the proposed method.
minor comments (2)
- [Abstract] Abstract: the statement that results are 'competitive' and offer 'clearer advantages' should be accompanied by at least one key quantitative figure even in the abstract to orient readers.
- [Evaluation] Notation: the manuscript should explicitly define what constitutes 'high-level task semantics' and how it is measured separately from exact structured output match.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, clarifying details from the manuscript and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Method] Method section: the description of the fine-tuning procedure does not state whether the speech encoder parameters are updated or frozen while text-only task supervision is applied to the decoder. This detail is load-bearing for the claim that text-form supervision alone transfers the speech-to-structured-output mapping; if the encoder remains frozen, any noise-robustness advantage would derive only from the base SLM pre-training rather than CORTIS, undermining isolation from the ASR-LLM baseline.
Authors: We agree this specification is essential. In CORTIS, the speech encoder remains frozen during text-only fine-tuning; only the decoder and cross-modal alignment layers receive gradient updates from the text-form task supervision. This choice preserves the pre-trained speech representations while adapting the output head for structured generation. We will add an explicit statement of this design choice, including the rationale, to the Method section in the revision. revision: yes
-
Referee: [Experiments] Experiments / Results: the central claim of competitive performance and clearer advantages under acoustic degradation is presented without reference to specific quantitative metrics (accuracy, semantic frame F1, error rates), dataset sizes, exclusion criteria, or statistical tests in the provided text. Without these, the comparison to cascades cannot be verified and the robustness advantage cannot be assessed for effect size or significance.
Authors: The manuscript reports these quantities in Tables 1–3 and the accompanying text of Section 4 (accuracy, semantic-frame F1, and task-completion error rates; dataset cardinalities and splits; exclusion rules for noisy utterances). We acknowledge that inline textual summaries and statistical tests (e.g., McNemar or paired t-tests on degradation conditions) are not sufficiently prominent. We will insert a concise results paragraph and add significance testing in the revised Section 4. revision: yes
-
Referee: [§4] §4 (Evaluation): the comparison to ASR-LLM cascades uses the same text-form supervision, but does not report an ablation that isolates the effect of text-only SLM adaptation versus simply using the frozen SLM backbone; this leaves open whether the reported gains under degradation are attributable to the proposed method.
Authors: We concur that an explicit ablation against the frozen, unadapted SLM backbone would further isolate the contribution of text-only adaptation. Although the base SLM lacks task-specific structured-output training and therefore cannot produce valid semantic frames or function calls, we will add this ablation (reporting failure rates on both clean and degraded speech) to Section 4 to demonstrate that adaptation is required for the observed behavior. revision: yes
Circularity Check
No circularity: empirical comparison on external benchmarks
full rationale
The paper describes an empirical adaptation method (CORTIS) and evaluates it via direct comparisons to ASR-LLM cascades on three task-oriented speech datasets using text-form supervision. No equations, fitted parameters, or self-citations are presented that reduce reported performance metrics to definitions or inputs by construction. The central claims rest on experimental outcomes against matched baselines rather than any self-referential derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Transactions of the Association for Computational Linguistics , volume=
On generative spoken language modeling from raw audio , author=. Transactions of the Association for Computational Linguistics , volume=
-
[2]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Text-free prosody-aware generative spoken language modeling , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[3]
An exploration of prompt tuning on generative spoken language model for speech processing tasks , author=. Proc. Interspeech , pages=
-
[4]
IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=
On decoder-only architecture for speech-to-text and large language model integration , author=. IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=
-
[5]
arXiv preprint arXiv:2310.02050 , year=
Tuning large language model for end-to-end speech translation , author=. arXiv preprint arXiv:2310.02050 , year=
-
[6]
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Salm: Speech-augmented language model with in-context learning for speech recognition and translation , author=. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
-
[7]
arXiv preprint arXiv:2407.10759 , year=
Qwen2-audio technical report , author=. arXiv preprint arXiv:2407.10759 , year=
-
[8]
arXiv preprint arXiv:2309.00916 , year=
Blsp: Bootstrapping language-speech pre-training via behavior alignment of continuation writing , author=. arXiv preprint arXiv:2309.00916 , year=
-
[9]
Frozen large language models can perceive paralinguistic aspects of speech , author=. Proc. Interspeech , pages=
-
[10]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Blsp-emo: Towards empathetic large speech-language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[11]
Proceedings of the 37th International Conference on Neural Information Processing Systems , pages=
Toolformer: language models can teach themselves to use tools , author=. Proceedings of the 37th International Conference on Neural Information Processing Systems , pages=
-
[12]
International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. International Conference on Learning Representations , year=
-
[13]
Advances in Neural Information Processing Systems , year=
Gorilla: Large Language Model Connected with Massive APIs , author=. Advances in Neural Information Processing Systems , year=
-
[14]
International Conference on Learning Representations , pages=
Toolllm: Facilitating large language models to master 16000+ real-world apis , author=. International Conference on Learning Representations , pages=
-
[15]
Zuxin Liu and Thai Quoc Hoang and Jianguo Zhang and Ming Zhu and Tian Lan and Shirley Kokane and Juntao Tan and Weiran Yao and Zhiwei Liu and Yihao Feng and Rithesh R N and Liangwei Yang and Silvio Savarese and Juan Carlos Niebles and Huan Wang and Shelby Heinecke and Caiming Xiong , booktitle=
-
[16]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[17]
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Towards ASR robust spoken language understanding through in-context learning with word confusion networks , author=. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
-
[18]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Measuring the Effect of Transcription Noise on Downstream Language Understanding Tasks , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[19]
Computational Linguistics , volume=
Revisiting the Boundary between ASR and NLU in the Age of Conversational Dialog Systems , author=. Computational Linguistics , volume=
-
[20]
arXiv preprint arXiv:2306.06819 , year=
Multimodal audio-textual architecture for robust spoken language understanding , author=. arXiv preprint arXiv:2306.06819 , year=
-
[21]
arXiv preprint arXiv:2605.17443 , year=
Analyzing Error Propagation in Korean Spoken QA with ASR-LLM Cascades , author=. arXiv preprint arXiv:2605.17443 , year=
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
Audiogpt: Understanding and generating speech, music, sound, and talking head , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[23]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Audiochatllama: Towards general-purpose speech abilities for llms , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[24]
International Conference on Learning Representations , pages=
Salmonn: Towards generic hearing abilities for large language models , author=. International Conference on Learning Representations , pages=
-
[25]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
SpeechLLMs for Large-scale Contextualized Zero-shot Slot Filling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2025
-
[26]
Aa-sllm: An acoustically augmented speech large language model for speech emotion recognition , author=. Proc. Interspeech , pages=
-
[27]
30th International Joint Conference on Artificial Intelligence (IJCAI) , pages=
A Survey on Spoken Language Understanding: Recent Advances and New Frontiers , author=. 30th International Joint Conference on Artificial Intelligence (IJCAI) , pages=. 2021 , organization=
2021
-
[28]
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Leveraging unpaired text data for training end-to-end speech-to-intent systems , author=. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
-
[29]
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Exploring Fine-Tuning Of Large Audio Language Models For Spoken Language Understanding Under Limited Speech Data , author=. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
-
[30]
arXiv preprint arXiv:2506.05671 , year=
Low-resource domain adaptation for speech LLMs via text-only fine-tuning , author=. arXiv preprint arXiv:2506.05671 , year=
-
[31]
2024 IEEE Spoken Language Technology Workshop (SLT) , pages=
Effective text adaptation for llm-based asr through soft prompt fine-tuning , author=. 2024 IEEE Spoken Language Technology Workshop (SLT) , pages=
2024
-
[32]
arXiv preprint arXiv:2601.20900 , year=
Text-only adaptation in LLM-based asr through text denoising , author=. arXiv preprint arXiv:2601.20900 , year=
-
[33]
arXiv preprint arXiv:2404.01744 , year=
Octopus v2: On-device language model for super agent , author=. arXiv preprint arXiv:2404.01744 , year=
-
[34]
Adjunct Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology , pages=
DESAMO: A Device for Elder-Friendly Smart Homes Powered by Embedded LLM with Audio Modality , author=. Adjunct Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology , pages=
-
[35]
arXiv preprint arXiv:2604.22821 , year=
Audio2Tool: Speak, Call, Act--A Dataset for Benchmarking Speech Tool Use , author=. arXiv preprint arXiv:2604.22821 , year=
-
[36]
Leander Melroy Maben and Gayathri Ganesh Lakshmy and Srijith Radhakrishnan and Siddhant Arora and Shinji Watanabe , title =
-
[37]
Speech Model Pre-Training for End-to-End Spoken Language Understanding , author=. Proc. Interspeech , pages=
-
[38]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
SLURP: A spoken language understanding resource package , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[39]
arXiv preprint arXiv:1510.08484 , year=
Musan: A music, speech, and noise corpus , author=. arXiv preprint arXiv:1510.08484 , year=
-
[40]
arXiv preprint arXiv:2501.10868 , year=
Geng, Saibo and Cooper, Hudson and Moskal, Micha. arXiv preprint arXiv:2501.10868 , year=
-
[41]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Zerotop: Zero-shot task-oriented semantic parsing using large language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[42]
International Conference on Machine Learning , pages=
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents , author=. International Conference on Machine Learning , pages=
-
[43]
arXiv preprint arXiv:2503.20215 , year =
Qwen2.5-Omni Technical Report , author =. arXiv preprint arXiv:2503.20215 , year =
-
[44]
arXiv preprint arXiv:2412.15115 , year=
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[45]
arXiv preprint arXiv:2407.10671 , year=
Qwen2 Technical Report , author=. arXiv preprint arXiv:2407.10671 , year=
-
[46]
IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
X-vectors: Robust dnn embeddings for speaker recognition , author=. IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.