Learning to Place Guards by Reinforcement: A Geo-Free Neural Policy for the Vertex-Guard Art Gallery Problem
Pith reviewed 2026-06-26 14:47 UTC · model grok-4.3
The pith
The encoder trained by reinforcement on the art gallery problem has already internalized the geometry needed for feasible guard placement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
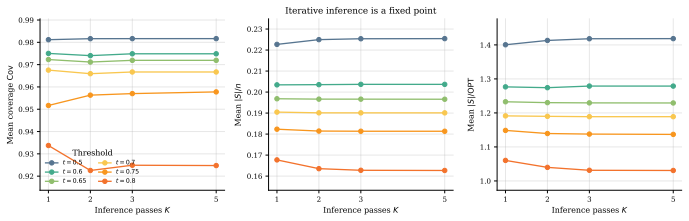
The reinforcement-trained representation already encodes the geometry required for feasibility, and residual failures reflect decoder calibration rather than missing knowledge. Probing a frozen encoder thus offers a practical way to ask what a neural combinatorial solver has internalized.
What carries the argument
Pointer-network policy trained from a coverage-aware reward under geo-free inference, probed by freezing the encoder and reading its embeddings with a single-shot classifier.
Load-bearing premise
That the single-shot classifier on frozen embeddings demonstrates the encoder has internalized the geometry without the classifier itself performing implicit geometric reasoning or the improvement arising from post-training on similar data distributions.
What would settle it
Train the classifier on embeddings from a policy trained on polygons whose vertex distributions differ sharply from the original training set and check whether the coverage improvement disappears.
Figures
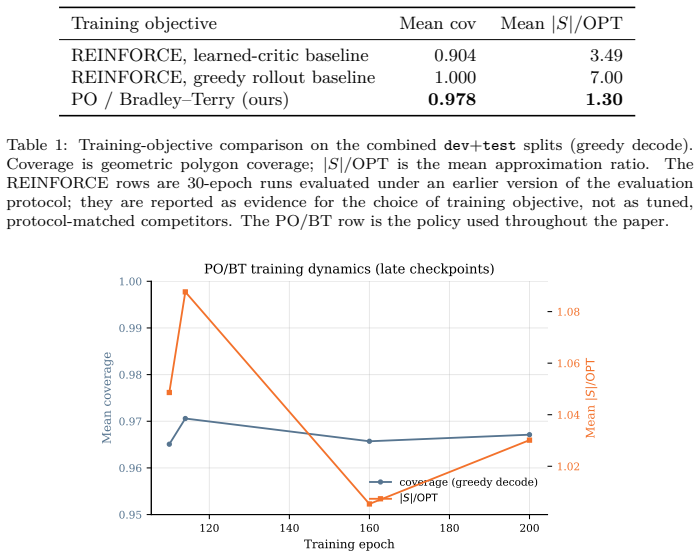
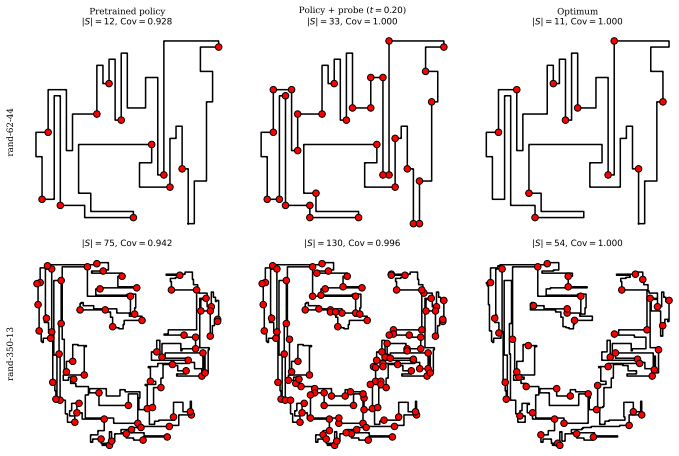
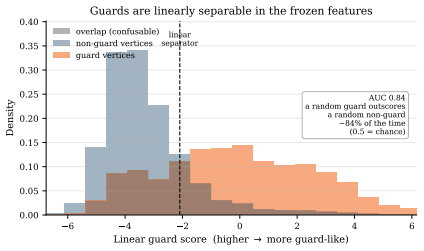
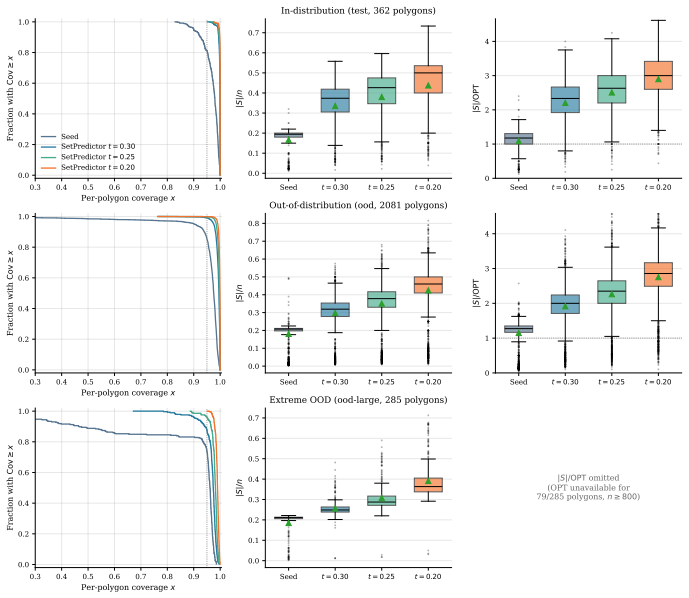
read the original abstract
Neural combinatorial optimization (NCO) has shown that policies trained by reinforcement can construct strong solutions to NP-hard problems directly from raw instances. What such a policy actually learns, as opposed to what its decoder expresses, remains much less clear. We study this distinction on the vertex-guard Art Gallery Problem, the NP-hard task of choosing polygon vertices from which to observe an entire region. A pointer-network policy is trained from a coverage-aware reward over its own rollouts under the constraint we call geo-free inference: at test time it sees only vertex coordinates, with no visibility computation and no geometric oracle. The policy places guards economically but leaves a tail of under-covered polygons that widens far beyond the training range. To locate the cause, we freeze the trained encoder and read its embeddings with a small single-shot classifier, still geo-free at inference. The classifier closes most of the feasibility gap, in and out of distribution and at up to roughly five times the training range, cutting under-covered polygons by about an order of magnitude at an explicitly reported cost in guard count. We read this as evidence that the reinforcement-trained representation already encodes the geometry required for feasibility, and that residual failures reflect decoder calibration rather than missing knowledge. Probing a frozen encoder thus offers a practical way to ask what a neural combinatorial solver has internalized.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a reinforcement learning-based pointer network policy for the vertex-guard Art Gallery Problem that operates without geometric oracles at inference time (geo-free). The policy is trained with a coverage-aware reward and achieves economical guard placement but leaves a tail of under-covered instances. By freezing the encoder and training a small classifier on its embeddings, the authors show improved feasibility both in and out of distribution, interpreting this as evidence that the RL-trained representation encodes the required geometric (visibility) information, with decoder calibration as the remaining issue.
Significance. If the central interpretation holds, the work offers a diagnostic tool for understanding what neural combinatorial optimization policies internalize from raw instances. The geo-free setting and out-of-distribution probing are notable strengths, providing falsifiable evidence about learned representations in an NP-hard geometric problem. This could influence how we evaluate and improve NCO methods beyond end-to-end performance.
major comments (2)
- [Probing experiments (abstract and §4–5)] The claim that the single-shot classifier merely reads out pre-encoded geometry from the RL encoder (rather than itself performing implicit geometric reasoning on coordinate-derived embeddings) is load-bearing for the central interpretation. No ablation is reported that trains the same classifier on raw vertex coordinates or on embeddings from an untrained encoder; without these controls the source of the visibility knowledge cannot be isolated. This directly affects the conclusion that residual failures reflect decoder calibration rather than missing knowledge in the encoder.
- [Abstract and experimental results] The abstract states that the classifier 'closes most of the feasibility gap' and cuts under-covered polygons 'by about an order of magnitude' at 'explicitly reported cost in guard count,' yet supplies no details on instance counts, training/test ranges, exact coverage metrics, statistical significance, or variance across runs. These omissions make it impossible to evaluate whether the reported OOD gains (up to 5× training range) are robust or whether they support the encoder-encoding claim.
minor comments (1)
- [Introduction] Define 'geo-free inference' explicitly in the introduction with a clear contrast to standard visibility-oracle settings to prevent reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our probing experiments and result reporting. We address each major point below and will revise the manuscript to strengthen the evidence and clarity.
read point-by-point responses
-
Referee: [Probing experiments (abstract and §4–5)] The claim that the single-shot classifier merely reads out pre-encoded geometry from the RL encoder (rather than itself performing implicit geometric reasoning on coordinate-derived embeddings) is load-bearing for the central interpretation. No ablation is reported that trains the same classifier on raw vertex coordinates or on embeddings from an untrained encoder; without these controls the source of the visibility knowledge cannot be isolated. This directly affects the conclusion that residual failures reflect decoder calibration rather than missing knowledge in the encoder.
Authors: We agree that the requested ablations would more rigorously isolate whether visibility knowledge originates in the RL-trained encoder. The manuscript reports only the classifier trained on the frozen RL encoder embeddings and does not include controls on raw coordinates or an untrained encoder. We will add these two ablations in the revised version (new subsection in §4) to directly test the source of the geometric information and thereby strengthen the claim that residual failures are due to decoder calibration. revision: yes
-
Referee: [Abstract and experimental results] The abstract states that the classifier 'closes most of the feasibility gap' and cuts under-covered polygons 'by about an order of magnitude' at 'explicitly reported cost in guard count,' yet supplies no details on instance counts, training/test ranges, exact coverage metrics, statistical significance, or variance across runs. These omissions make it impossible to evaluate whether the reported OOD gains (up to 5× training range) are robust or whether they support the encoder-encoding claim.
Authors: We acknowledge that the abstract and main experimental sections omit the precise instance counts, exact coverage thresholds, statistical tests, and run-to-run variance needed for full evaluation. The full manuscript does report the 5× OOD range and an explicit guard-count cost, but without the requested granularity. We will revise the abstract for conciseness while expanding §5 with a table listing polygon counts per range, exact feasibility percentages, mean/variance over 5 seeds, and significance markers. This will allow readers to assess robustness of the OOD gains. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper trains a pointer-network policy via RL using coverage-aware rewards (which require geometry only during training), then at inference operates geo-free on vertex coordinates alone. It subsequently freezes the encoder and trains an independent single-shot classifier on the resulting embeddings. No equations or steps are shown that reduce a claimed prediction to a fitted input by construction, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz is smuggled via prior work. The probing classifier is presented as a post-training diagnostic rather than part of the original derivation. The central claim therefore rests on empirical separation between training-time supervision and test-time behavior, which does not collapse to the inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of reinforcement learning for policy optimization hold, including that the coverage-aware reward over rollouts provides a valid training signal.
Reference graph
Works this paper leans on
-
[1]
D. T. Lee, A. K. Lin, Computational complexity of art gallery problems, IEEE Transactions on Information Theory 32 (2) (1986) 276–282
1986
-
[2]
O’Rourke, Art Gallery Theorems and Algorithms, Oxford University Press, 1987
J. O’Rourke, Art Gallery Theorems and Algorithms, Oxford University Press, 1987
1987
-
[3]
A. Elnagar, L. Lulu, An art gallery-based approach to autonomous robot motion planning in global environments, in: 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2005, pp. 2079–2084.doi: 10.1109/IROS.2005.1545170
-
[4]
B. S. Bigham, S. Dolatikalan, A. Khastan, Minimum landmarks for robot localization in orthogonal environments, Evol. Intell. 15 (3) (2022) 2235– 2238.doi:10.1007/s12065-021-00616-8. URLhttps://doi.org/10.1007/s12065-021-00616-8
-
[5]
M. Pan, G. Lin, Y.-W. Luo, B. Zhu, Z. Dai, L. Sun, C. Yuan, Preference optimization for combinatorial optimization problems, in: Proceedings of the 42nd International Conference on Machine Learning (ICML), 2025, arXiv:2505.08735
arXiv 2025
-
[6]
R. A. Bradley, M. E. Terry, Rank analysis of incomplete block designs: I. the method of paired comparisons, Biometrika 39 (3–4) (1952) 324–345
1952
-
[7]
R. J. Williams, Simple statistical gradient-following algorithms for connec- tionist reinforcement learning, Machine Learning 8 (3-4) (1992) 229–256
1992
-
[8]
I. Bello, H. Pham, Q. V. Le, M. Norouzi, S. Bengio, Neural combinatorial optimization with reinforcement learning, arXiv preprint arXiv:1611.09940 (2016). 27
Pith/arXiv arXiv 2016
-
[9]
G. Alain, Y. Bengio, Understanding intermediate layers using linear clas- sifier probes (2017).arXiv:1610.01644
Pith/arXiv arXiv 2017
-
[10]
Hewitt, P
J. Hewitt, P. Liang, Designing and interpreting probes with control tasks, in: Proceedings of the 2019 Conference on Empirical Methods in Natural LanguageProcessingandthe9thInternationalJointConferenceonNatural Language Processing (EMNLP-IJCNLP), 2019, pp. 2733–2743
2019
-
[11]
Belinkov, Probing classifiers: Promises, shortcomings, and advances, Computational Linguistics 48 (1) (2022) 207–219
Y. Belinkov, Probing classifiers: Promises, shortcomings, and advances, Computational Linguistics 48 (1) (2022) 207–219
2022
-
[12]
Vinyals, M
O. Vinyals, M. Fortunato, N. Jaitly, Pointer networks, in: Advances in Neural Information Processing Systems (NeurIPS), Vol. 28, 2015
2015
-
[13]
W. Kool, H. van Hoof, M. Welling, Attention, learn to solve routing prob- lems!, in: International Conference on Learning Representations (ICLR), 2019
2019
-
[14]
Y.-D. Kwon, J. Choo, B. Kim, I. Yoon, Y. Gwon, S. Min, POMO: Policy optimization with multiple optima for reinforcement learning, in: Advances in Neural Information Processing Systems (NeurIPS), Vol. 33, 2020
2020
-
[15]
M. C. Couto, P. J. de Rezende, C. C. de Souza, An exact algorithm for minimizing vertex guards on art galleries, International Transactions in Operational Research 18 (4) (2011) 425–448
2011
-
[16]
M. C. Couto, P. J. de Rezende, C. C. de Souza, Instances for the Art Gallery Problem,http://www.ic.unicamp.br/~cid/ Problem-instances/Art-Gallery(2009)
2009
-
[17]
S. K. Ghosh, Approximation algorithms for art gallery problems in poly- gons, Discrete Applied Mathematics 158 (6) (2010) 718–722
2010
-
[18]
González-Baños, A randomized art-gallery algorithm for sensor place- ment, Proceedings of the 17th Annual Symposium on Computational Ge- ometry (SoCG) (2001) 232–240
H. González-Baños, A randomized art-gallery algorithm for sensor place- ment, Proceedings of the 17th Annual Symposium on Computational Ge- ometry (SoCG) (2001) 232–240
2001
-
[19]
G.L.Nemhauser, L.A.Wolsey, M.L.Fisher, Ananalysisofapproximations for maximizing submodular set functions—i, Mathematical Programming 14 (1) (1978) 265–294
1978
-
[20]
Ben-Moshe, M
B. Ben-Moshe, M. J. Katz, J. S. B. Mitchell, A constant-factor approx- imation algorithm for optimal 1.5D terrain guarding, SIAM Journal on Computing 36 (6) (2007) 1631–1647
2007
-
[21]
K. Elbassioni, D. Matijević, J. Mestre, D. Ševerdija, Improved approxima- tions for guarding 1.5-dimensional terrains, CoRR abs/0809.0159v1 (2008)
Pith/arXiv arXiv 2008
-
[22]
Liao, P.-C
Y.-H. Liao, P.-C. Chang, H.-H. Li, Reinforcement learning for optimize coverage in art gallery problem using Q-learning based in grid world, IEEE Access 13 (2025) 52711–52724. 28
2025
-
[23]
M. D. Kaba, M. G. Uzunbas, S. N. Lim, A reinforcement learning approach to the view planning problem (2016).arXiv:1610.06204
Pith/arXiv arXiv 2016
-
[24]
Deudon, P
M. Deudon, P. Cournut, A. Lacoste, Y. Adulyasak, L.-M. Rousseau, Learn- ing heuristics for the TSP by policy gradient, in: Integration of Constraint Programming, Artificial Intelligence, and Operations Research (CPAIOR), Vol. 10848 of Lecture Notes in Computer Science, Springer, 2018, pp. 170– 181
2018
-
[25]
Y. Jin, Y. Ding, X. Pan, K. He, L. Zhao, T. Qin, L. Song, J. Bian, Pointer- former: Deep reinforced multi-pointer transformer for the traveling sales- man problem, aAAI 2023 (2023).arXiv:2304.09407
arXiv 2023
-
[26]
Y. Bengio, A. Lodi, A. Prouvost, Machine learning for combi- natorial optimization: A methodological tour d’horizon, Euro- pean Journal of Operational Research 290 (2) (2021) 405–421. doi:https://doi.org/10.1016/j.ejor.2020.07.063. URLhttps://www.sciencedirect.com/science/article/pii/ S0377221720306895
- [27]
-
[28]
K. Li, T. Zhang, R. Wang, Deep reinforcement learning for multiobjective optimization, IEEE Transactions on Cybernetics 51 (6) (2021) 3103–3114
2021
-
[29]
C. Caramanis, D. Fotakis, A. Kalavasis, V. Kontonis, C. Tzamos, Op- timizing solution-samplers for combinatorial problems: The landscape of policy-gradient methods, neurIPS 2023 (2023).arXiv:2310.05309
arXiv 2023
-
[30]
S. Ross, G. J. Gordon, J. A. Bagnell, A reduction of imitation learning and structured prediction to no-regret online learning, in: Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS), 2011, pp. 627–635
2011
-
[31]
Hochreiter, J
S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural Compu- tation 9 (8) (1997) 1735–1780
1997
-
[32]
org/5.6/Manual/packages.html(2024)
TheCGALProject, CGALuserandreferencemanual,https://doc.cgal. org/5.6/Manual/packages.html(2024)
2024
-
[33]
Loshchilov, F
I. Loshchilov, F. Hutter, Decoupled weight decay regularization, in: Inter- national Conference on Learning Representations (ICLR), 2019. 29
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.