ConcernBERT: Learning Responsibilities Using Class Membership
Pith reviewed 2026-06-26 13:25 UTC · model grok-4.3
The pith
ConcernBERT learns to group code entities by shared responsibilities using class membership and triplet loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ConcernBERT is a BERT-based embedding model trained at the entity level that uses triplet loss to directly optimize the relative positioning of methods and attributes in the embedding space, and uses class-membership context to learn responsibilities and concerns, recovering original class memberships from merged groups with significantly higher performance than existing models.
What carries the argument
ConcernBERT, a BERT-based embedding model trained with triplet loss on class-membership context to position methods and attributes by shared concerns.
If this is right
- Embeddings from ConcernBERT can support architecture recovery by clustering entities according to learned concerns.
- Extract class refactoring can use the model to propose splits based on responsibility groupings rather than manual review.
- Cohesion metrics can be derived from distances in the learned embedding space.
- The large-scale Java dataset enables training models that generalize across many repositories for concern detection.
Where Pith is reading between the lines
- The class-membership signal might allow detection of god classes by identifying entities that do not cluster tightly with any single concern.
- Similar triplet-loss training on other labeled groupings, such as package or module boundaries, could extend the method to additional design principles.
- If the embeddings prove stable, they could be integrated into static analysis tools to flag low-cohesion areas during development.
Load-bearing premise
Artificially merging methods from two or more classes and testing recovery of original memberships is a valid proxy for identifying naturally cohesive responsibility groups in real unmodified code.
What would settle it
If ConcernBERT fails to match or exceed baselines when tested on human-labeled cohesive groups drawn from unaltered production code, the claim that it encodes concern-level semantics would not hold.
Figures


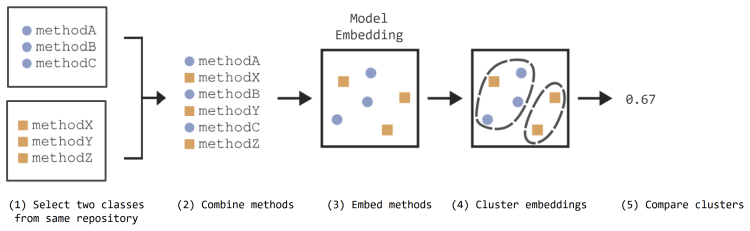
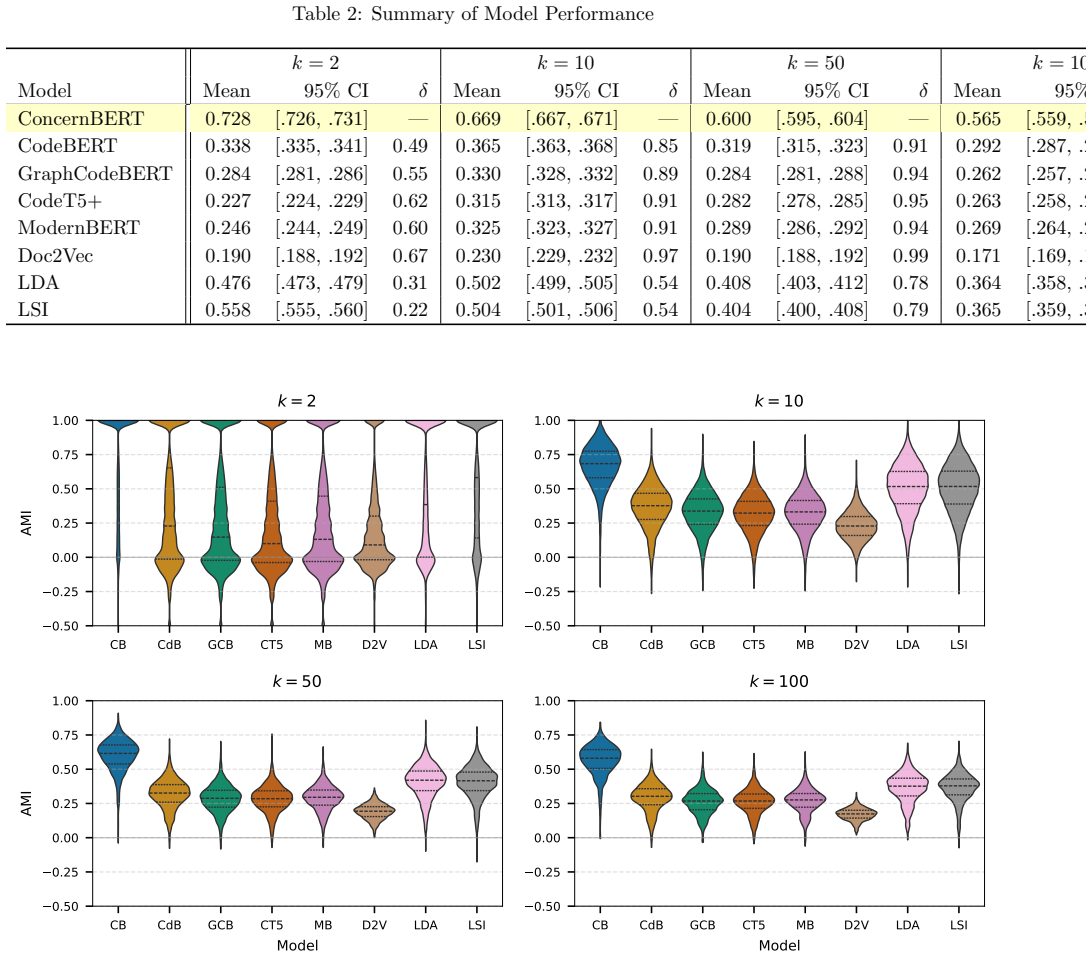
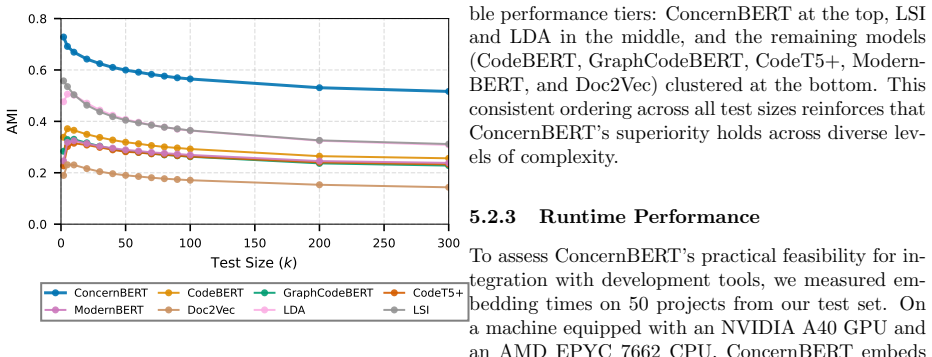
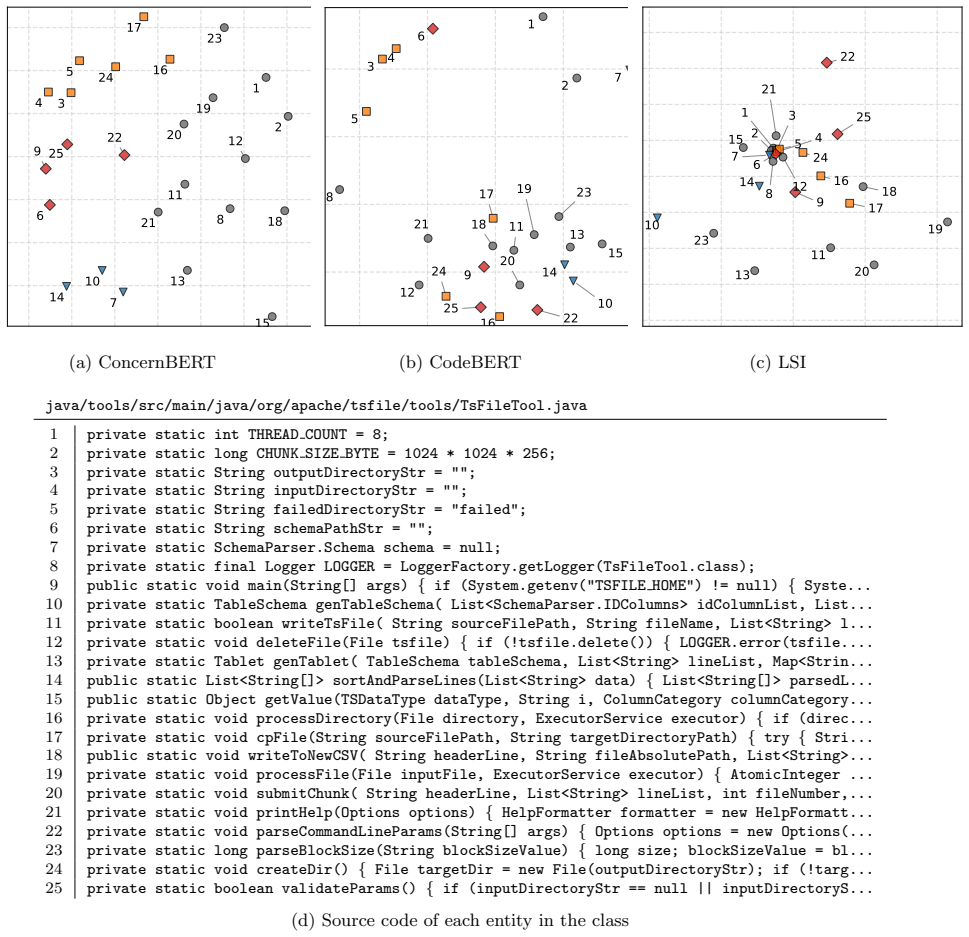
read the original abstract
The principles of separation of concerns, high cohesion, and single responsibility are among the most well-known in software design. However, their application often remains philosophical rather than actionable, relying heavily on developers' intuition and experience. Many software tasks, such as god class decomposition, extract class refactoring, and cohesion measurement, depend on techniques for identifying cohesive groups of program entities, that is, entities that collectively fulfill a common responsibility. Yet reliably identifying such groups remains a challenge. In this paper, we propose ConcernBERT, a BERT-based embedding model trained at the entity level that uses triplet loss to directly optimize the relative positioning of methods and attributes in the embedding space, and uses class-membership context to learn responsibilities and concerns. We also contribute a large-scale replication dataset for training and evaluation. Our dataset spans over two million Java files across more than six thousand repositories. To evaluate ConcernBERT, we merge methods from two or more classes into unlabeled groups and test the model's ability to recover the original class memberships. ConcernBERT achieves significantly higher performance than existing models, demonstrating its effectiveness at encoding concern-level semantics and establishing a strong foundation for downstream tasks such as architecture recovery, extract class refactoring, and cohesion measurement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ConcernBERT, a BERT-based embedding model trained at the entity level using triplet loss with class-membership context to learn responsibilities and concerns in Java code. It contributes a large-scale dataset of over two million Java files from more than six thousand repositories. Evaluation consists of merging methods from two or more classes into unlabeled groups and testing recovery of the original class memberships; the paper claims ConcernBERT achieves significantly higher performance than existing models, demonstrating effectiveness at encoding concern-level semantics for downstream tasks including architecture recovery, extract class refactoring, and cohesion measurement.
Significance. If the performance gains are substantiated with quantitative metrics and the class-recovery proxy is shown to measure concern semantics rather than class boundaries, the work could operationalize separation of concerns and single-responsibility principles in an actionable, data-driven manner. The contributed large-scale dataset would be a reusable asset for the software engineering community.
major comments (2)
- [Abstract] Abstract: the assertion that ConcernBERT 'achieves significantly higher performance than existing models' supplies no quantitative metrics, baseline descriptions, statistical significance tests, error bars, or dataset construction details, making it impossible to assess whether the data support the central claim.
- [Evaluation] Evaluation (class recovery task, as described): the central claim that higher recovery performance demonstrates encoding of concern-level semantics depends on the proxy of artificially merging methods from ≥2 classes and recovering original memberships. Because training also uses class-membership context via triplet loss, strong results on this task could arise from learning class-boundary signals rather than responsibility semantics; the proxy never tests unmodified real-world code where concerns may cross classes or require non-class cues. No independent validation (human-annotated concerns or downstream refactoring tasks) is described.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important issues regarding the abstract's claims and the evaluation design. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that ConcernBERT 'achieves significantly higher performance than existing models' supplies no quantitative metrics, baseline descriptions, statistical significance tests, error bars, or dataset construction details, making it impossible to assess whether the data support the central claim.
Authors: We agree that the abstract should include quantitative support for its claims rather than relying on a qualitative statement. In the revised version, we will update the abstract to report key performance metrics (such as accuracy or F1 improvements over baselines), reference the statistical significance of results, and briefly note the scale of the dataset and evaluation setup. Full experimental details remain in the body of the paper. revision: yes
-
Referee: [Evaluation] Evaluation (class recovery task, as described): the central claim that higher recovery performance demonstrates encoding of concern-level semantics depends on the proxy of artificially merging methods from ≥2 classes and recovering original memberships. Because training also uses class-membership context via triplet loss, strong results on this task could arise from learning class-boundary signals rather than responsibility semantics; the proxy never tests unmodified real-world code where concerns may cross classes or require non-class cues. No independent validation (human-annotated concerns or downstream refactoring tasks) is described.
Authors: We acknowledge that the class-recovery proxy is closely aligned with the class-membership signal used during training, which raises a legitimate question about whether the model is primarily capturing class boundaries rather than broader concern semantics. The task is intended to evaluate the model's ability to group entities by learned responsibility in an unlabeled setting, consistent with the single-responsibility principle. However, we agree this does not constitute fully independent validation on unmodified code or human-annotated concerns. In the revision, we will add an explicit discussion of this limitation in the evaluation section, clarify the assumptions of the proxy, and outline directions for future validation using downstream tasks such as refactoring. revision: partial
Circularity Check
Class-recovery evaluation reduces to training signal by construction
specific steps
-
fitted input called prediction
[Abstract]
"uses triplet loss to directly optimize the relative positioning of methods and attributes in the embedding space, and uses class-membership context to learn responsibilities and concerns. [...] we merge methods from two or more classes into unlabeled groups and test the model's ability to recover the original class memberships. ConcernBERT achieves significantly higher performance than existing models, demonstrating its effectiveness at encoding concern-level semantics"
Training optimizes embeddings using class-membership context as the supervisory signal; evaluation then measures success at recovering those same class memberships from artificially merged groups. High performance is therefore the expected outcome of the training procedure rather than an independent test of concern semantics.
full rationale
The paper trains ConcernBERT with triplet loss that explicitly uses class-membership context to position entities, then evaluates by merging methods from multiple classes and measuring recovery of those exact original class memberships. Success on this task therefore directly reflects optimization of the class-boundary training objective rather than an independent demonstration of concern-level semantics. No equations or external uniqueness theorems are involved; the circularity is in the proxy itself being the fitted input. This matches the 'fitted_input_called_prediction' pattern and justifies a moderate circularity score; the rest of the model architecture and dataset contribution remain non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Class membership is a reliable proxy for entities sharing a common responsibility or concern.
Reference graph
Works this paper leans on
-
[1]
E. W. Dijkstra,On the role of scientific thought. New York, NY: Springer New York, 1982, pp. 60–66
1982
-
[2]
On the criteria to be used in de- composing systems into modules,
D. L. Parnas, “On the criteria to be used in de- composing systems into modules,”Communica- tions of the ACM, vol. 15, no. 12, pp. 1053–1058, Dec. 1972
1972
-
[3]
Automatic software clustering via latent semantic analysis,
J. Maletic and N. Valluri, “Automatic software clustering via latent semantic analysis,” in14th IEEE International Conference on Automated Software Engineering, ser. ASE-99. IEEE Com- put. Soc, 1999, pp. 251–254
1999
-
[4]
Using latent seman- tic analysis to identify similarities in source code to support program understanding,
J. Maletic and A. Marcus, “Using latent seman- tic analysis to identify similarities in source code to support program understanding,” inProceed- ings 12th IEEE Internationals Conference on Tools with Artificial Intelligence. ICTAI 2000, ser. TAI-00. IEEE Comput. Soc, 2000, pp. 46– 53
2000
-
[5]
Supporting program comprehension us- ing semantic and structural information,
——, “Supporting program comprehension us- ing semantic and structural information,” in Proceedings of the 23rd International Conference 18 on Software Engineering. ICSE 2001, ser. ICSE- 01, H. A. M¨ uller, M. J. Harrold, and W. Sch¨ afer, Eds. IEEE Comput. Soc, 2001, pp. 103–112
2001
-
[6]
An information retrieval approach to concept location in source code,
A. Marcus, A. Sergeyev, V. Rajlich, and J. Maletic, “An information retrieval approach to concept location in source code,” in11th Working Conference on Reverse Engineering, ser. WCRE-04. IEEE Comput. Soc, 2004, pp. 214–223
2004
-
[7]
Enriching reverse engineering with semantic clustering,
A. Kuhn, S. Ducasse, and T. Girba, “Enriching reverse engineering with semantic clustering,” in 12th Working Conference on Reverse Engineer- ing (WCRE’05). IEEE, 2005, pp. 133–142
2005
-
[8]
Semantic clustering: Identifying topics in source code,
A. Kuhn, S. Ducasse, and T. Gˆ ırba, “Semantic clustering: Identifying topics in source code,” Information and Software Technology, vol. 49, no. 3, pp. 230–243, Mar. 2007
2007
-
[9]
A theory of aspects as latent topics,
P. F. Baldi, C. V. Lopes, E. J. Linstead, and S. K. Bajracharya, “A theory of aspects as latent topics,” inProceedings of the 23rd ACM SIG- PLAN conference on Object-oriented program- ming systems languages and applications, ser. OOPSLA08, G. E. Harris, Ed. ACM, Oct. 2008, pp. 543–562
2008
-
[10]
Enhancing architec- tural recovery using concerns,
J. Garcia, D. Popescu, C. Mattmann, N. Med- vidovic, and Y. Cai, “Enhancing architec- tural recovery using concerns,” in2011 26th IEEE/ACM International Conference on Au- tomated Software Engineering (ASE 2011), P. Alexander, C. S. Pasareanu, and J. G. Hosk- ing, Eds. IEEE, Nov. 2011, pp. 552–555
2011
-
[11]
Automatic software architecture re- covery: A machine learning approach,
H. Sajnani, “Automatic software architecture re- covery: A machine learning approach,” in2012 20th IEEE International Conference on Pro- gram Comprehension (ICPC), D. Beyer, A. van Deursen, and M. W. Godfrey, Eds. IEEE, Jun. 2012, pp. 265–268
2012
-
[12]
Recovering architectural design decisions,
A. Shahbazian, Y. Kyu Lee, D. Le, Y. Brun, and N. Medvidovic, “Recovering architectural design decisions,” in2018 IEEE International Confer- ence on Software Architecture (ICSA). IEEE, Apr. 2018, pp. 95–9509
2018
-
[13]
Software architecture recovery with information fusion,
Y. Zhang and et al., “Software architecture recovery with information fusion,” inProceed- ings of the 31st ACM Joint European Soft- ware Engineering Conference and Symposium on the Foundations of Software Engineering, ser. ESEC/FSE ’23, S. Chandra, K. Blincoe, and P. Tonella, Eds. ACM, Nov. 2023, pp. 1535– 1547
2023
-
[14]
Using structural and semantic metrics to improve class cohesion,
A. De Lucia, R. Oliveto, and L. Vorraro, “Using structural and semantic metrics to improve class cohesion,” in2008 IEEE International Confer- ence on Software Maintenance. IEEE, Sep. 2008, pp. 27–36
2008
-
[15]
A two-step technique for ex- tract class refactoring,
G. Bavota, A. De Lucia, A. Marcus, and R. Oliveto, “A two-step technique for ex- tract class refactoring,” inProceedings of the IEEE/ACM international conference on Automated software engineering, ser. ASE10, C. Pecheur, J. Andrews, and E. D. Nitto, Eds. ACM, Sep. 2010, pp. 151–154
2010
-
[16]
Identi- fying extract class refactoring opportunities us- ing structural and semantic cohesion measures,
G. Bavota, A. De Lucia, and R. Oliveto, “Identi- fying extract class refactoring opportunities us- ing structural and semantic cohesion measures,” Journal of Systems and Software, vol. 84, no. 3, pp. 397–414, Mar. 2011
2011
-
[17]
Automating extract class refactor- ing: an improved method and its evaluation,
G. Bavota, A. De Lucia, A. Marcus, and R. Oliveto, “Automating extract class refactor- ing: an improved method and its evaluation,” Empirical Software Engineering, vol. 19, no. 6, pp. 1617–1664, May 2013
2013
-
[18]
Methodbook: Rec- ommending move method refactorings via re- lational topic models,
G. Bavota, R. Oliveto, M. Gethers, D. Poshy- vanyk, and A. De Lucia, “Methodbook: Rec- ommending move method refactorings via re- lational topic models,”IEEE Transactions on Software Engineering, vol. 40, no. 7, pp. 671– 694, Jul. 2014
2014
-
[19]
An approach of extracting god class exploiting both struc- tural and semantic similarity,
P. Akash, A. Sadiq, and A. Kabir, “An approach of extracting god class exploiting both struc- tural and semantic similarity,” inProceedings of the 14th International Conference on Evaluation of Novel Approaches to Software Engineering, 19 E. Damiani, G. Spanoudakis, and L. A. Maci- aszek, Eds. SCITEPRESS - Science and Tech- nology Publications, 2019, pp. 427–433
2019
-
[20]
Using information retrieval based coupling measures for impact analysis,
D. Poshyvanyk, A. Marcus, R. Ferenc, and T. Gyim´ othy, “Using information retrieval based coupling measures for impact analysis,”Empiri- cal Software Engineering, vol. 14, no. 1, pp. 5–32, Sep. 2008
2008
-
[21]
New conceptual coupling and cohesion metrics for object-oriented systems,
B. Ujhazi, R. Ferenc, D. Poshyvanyk, and T. Gy- imothy, “New conceptual coupling and cohesion metrics for object-oriented systems,” in2010 10th IEEE Working Conference on Source Code Analysis and Manipulation. IEEE, Sep. 2010, pp. 33–42
2010
-
[22]
Using rela- tional topic models to capture coupling among classes in object-oriented software systems,
M. Gethers and D. Poshyvanyk, “Using rela- tional topic models to capture coupling among classes in object-oriented software systems,” in 2010 IEEE International Conference on Soft- ware Maintenance. Timisoara, Romania: IEEE, Sep. 2010, pp. 1–10
2010
-
[23]
The concep- tual cohesion of classes,
A. Marcus and D. Poshyvanyk, “The concep- tual cohesion of classes,” in21st IEEE Inter- national Conference on Software Maintenance (ICSM 2005), 25-30 September 2005, Budapest, Hungary. IEEE Computer Society, 2005, pp. 133–142
2005
-
[24]
Modeling class cohesion as mixtures of latent topics,
Y. Liu, D. Poshyvanyk, R. Ferenc, T. Gyimothy, and N. Chrisochoides, “Modeling class cohesion as mixtures of latent topics,” in2009 IEEE International Conference on Software Mainte- nance. IEEE, Sep. 2009, pp. 233–242
2009
-
[25]
Topic-based soft- ware defect explanation,
T.-H. Chen, W. Shang, M. Nagappan, A. E. Hassan, and S. W. Thomas, “Topic-based soft- ware defect explanation,”Journal of Systems and Software, vol. 129, pp. 79–106, Jul. 2017
2017
-
[26]
New conceptual cohesion met- rics: Assessment for software defect predic- tion,
D.-L. Miholca, “New conceptual cohesion met- rics: Assessment for software defect predic- tion,” in2021 23rd International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC). IEEE, Dec. 2021
2021
-
[27]
Detection strategies: Metrics- based rules for detecting design flaws,
R. Marinescu, “Detection strategies: Metrics- based rules for detecting design flaws,” inPro- ceedings of the 20th IEEE International Confer- ence on Software Maintenance, ser. ICSM ’04. USA: IEEE Computer Society, 2004, p. 350–359
2004
-
[28]
A Semantic-Based Approach for Detecting and Decomposing God Classes
J. Lee, D. Lee, D.-K. Kim, and S. Park, “A semantic-based approach for detecting and decomposing god classes,”ArXiv, vol. abs/1204.1967, 2012. [Online]. Available: https: //api.semanticscholar.org/CorpusID:9825280
work page internal anchor Pith review Pith/arXiv arXiv 1967
-
[29]
Concernbert: Learning respon- sibilities using class membership,
J. Lefever, “Concernbert: Learning respon- sibilities using class membership,” 2025. [Online]. Available: https://doi.org/10.5281/ zenodo.15694052
2025
-
[30]
Identification and appli- cation of extract class refactorings in object- oriented systems,
M. Fokaefs, N. Tsantalis, E. Stroulia, and A. Chatzigeorgiou, “Identification and appli- cation of extract class refactorings in object- oriented systems,”Journal of Systems and Soft- ware, vol. 85, no. 10, pp. 2241–2260, Oct. 2012
2012
-
[31]
Alzahrani,Using Clients to Support Extract Class Refactoring
M. Alzahrani,Using Clients to Support Extract Class Refactoring. Springer International Pub- lishing, 2021, pp. 695–704
2021
-
[32]
Extract class refactoring based on cohe- sion and coupling: A greedy approach,
——, “Extract class refactoring based on cohe- sion and coupling: A greedy approach,”Com- puters, vol. 11, no. 8, p. 123, Aug. 2022
2022
-
[33]
Deicide: Decomposing complex classes into re- sponsibility modules,
J. Lefever, Y. Cai, R. Kazman, and E. Pisch, “Deicide: Decomposing complex classes into re- sponsibility modules,”2025 IEEE 22nd Inter- national Conference on Software Architecture (ICSA), pp. 301–312, 2025
2025
-
[34]
Codebert: A pre-trained model for programming and natural languages,
Z. Feng and et al., “Codebert: A pre-trained model for programming and natural languages,” inFindings of the Association for Computa- tional Linguistics: EMNLP 2020, ser. Findings of ACL, T. Cohn, Y. He, and Y. Liu, Eds., vol. EMNLP 2020. Association for Computational Linguistics, 2020, pp. 1536–1547
2020
-
[35]
Graphcodebert: Pre-training code representations with data flow,
D. Guo and et al., “Graphcodebert: Pre-training code representations with data flow,” in9th In- ternational Conference on Learning Representa- tions, ICLR 2021, Virtual Event, Austria, May 3-7, 2021, 2021. 20
2021
-
[36]
Codet5+: Open code large language models for code understanding and generation,
Y. Wang, H. Le, A. Gotmare, N. Bui, J. Li, and S. Hoi, “Codet5+: Open code large language models for code understanding and generation,” inProceedings of the 2023 Conference on Em- pirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Asso- ciation for Computational Linguistics, 2023, pp. 1069–1088
2023
-
[37]
B. Warner, A. Chaffin, B. Clavi´ e, O. Weller, O. Hallstr¨ om, S. Taghadouini, A. Gallagher, R. Biswas, F. Ladhak, T. Aarsen, N. Cooper, G. Adams, J. Howard, and I. Poli, “Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference,”CoRR, vol. abs/2412.13663, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Indexing by latent semantic analysis,
S. Deerwester, S. T. Dumais, G. W. Furnas, T. K. Landauer, and R. Harshman, “Indexing by latent semantic analysis,”Journal of the Amer- ican Society for Information Science, vol. 41, no. 6, pp. 391–407, Sep. 1990
1990
-
[39]
La- tent dirichlet allocation,
D. M. Blei, A. Y. Ng, and M. I. Jordan, “La- tent dirichlet allocation,”J. Mach. Learn. Res., vol. 3, pp. 993–1022, 2003
2003
-
[40]
Distributed Representations of Sentences and Documents
Q. V. Le and T. Mikolov, “Distributed repre- sentations of sentences and documents,”CoRR, vol. abs/1405.4053, May 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[41]
Learning and evaluating contextual embedding of source code,
A. Kanade, P. Maniatis, G. Balber, and K. Shi, “Learning and evaluating contextual embedding of source code,” inProceedings of the 37th International Conference on Machine Learning (ICML), 2020
2020
-
[42]
Codeberta: A roberta-like pre-trained model for source code,
“Codeberta: A roberta-like pre-trained model for source code,” https://huggingface.co/ huggingface/CodeBERTa-small-v1, accessed: 2026-01-25
2026
-
[43]
On the validity of pre-trained transformers for natural language processing in the software en- gineering domain,
J. von der Mosel, A. Trautsch, and S. Herbold, “On the validity of pre-trained transformers for natural language processing in the software en- gineering domain,”IEEE Transactions on Soft- ware Engineering, vol. 49, no. 4, pp. 1487–1507, Apr. 2023
2023
-
[44]
Using bert for the detection of archi- tectural tactics in code,
J. Keim, A. Kaplan, A. Koziolek, and M. Mi- rakhorli, “Using bert for the detection of archi- tectural tactics in code,” Karlsruher Institut f¨ ur Technologie (KIT), Tech. Rep. 2, 2020
2020
-
[45]
Lecture Notes in Com- puter Science
——,Does BERT Understand Code? – An Ex- ploratory Study on the Detection of Architectural Tactics in Code, ser. Lecture Notes in Com- puter Science. Springer International Publish- ing, 2020, vol. 12292, pp. 220–228
2020
-
[46]
GraphCodeBERT: Pre-training Code Representations with Data Flow
D. Guo, S. Ren, S. Lu, Z. Feng, D. Tang, S. Liu, M. Zhouet al., “Graphcodebert: Pre-training code representations with data flow,” inInterna- tional Conference on Learning Representations, 2021, arXiv:2009.08366
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[47]
Unixcoder: Unified cross-modal pre- training for code representation,
D. Guo, S. Lu, N. Duan, Y. Wang, M. Zhou, and J. Yin, “Unixcoder: Unified cross-modal pre- training for code representation,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022
2022
-
[48]
SynCoBERT: Syntax-guided multi-modal con- trastive pre-training for code representation,
X. Wang, Y. Wang, F. Mi, P. Zhou, Y. Wan, X. Liu, L. Li, H. Wu, J. Liu, and X. Jiang, “SynCoBERT: Syntax-guided multi-modal con- trastive pre-training for code representation,” in Proceedings of the Thirty-Sixth AAAI Confer- ence on Artificial Intelligence (AAAI), 2022, pp. 11 339–11 347
2022
-
[49]
LineVul: A Transformer-based Line-Level Vulnerability Prediction,
W. Ma, M. Zhao, E. Soremekun, Q. Hu, J. M. Zhang, M. Papadakis, M. Cordy, X. Xie, and Y. L. Traon, “Graphcode2vec: generic code embedding via lexical and program dependence analyses,” inProceedings of the 19th International Conference on Mining Software Repositories, ser. MSR ’22. New York, NY, USA: Association for Computing Machinery, 2022, p. 524–536. [...
-
[50]
Codet5+: Open code large language models for code understanding and generation,
Y. Wang, H. Le, A. Gotmare, N. D. Q. Bui, J. Li, and S. C. H. Hoi, “Codet5+: Open code large language models for code understanding and generation,” inProceedings of the 2023 Con- ference on Empirical Methods in Natural Lan- guage Processing. Association for Computa- tional Linguistics, 2023, pp. 1069–1088. 21
2023
-
[51]
CodeT5: Identifier-aware unified pre-trained encoder-decoder models for code understand- ing and generation,
Y. Wang, W. Wang, S. Joty, and S. C. Hoi, “CodeT5: Identifier-aware unified pre-trained encoder-decoder models for code understand- ing and generation,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, 2021, pp. 8696– 8708
2021
-
[52]
Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference,
B. Warner, A. Chaffin, B. Clavi´ e, O. Weller, O. Hallstr¨ om, S. Taghadouini, A. Gallagher, R. Biswas, F. Ladhak, T. Aarsen, G. T. Adams, J. Howard, and I. Poli, “Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference,” inProceedings of the 63rd Annual Meeting of the Associati...
2025
-
[53]
R. A. Horn,Matrix analysis, second edition, cor- rected reprint ed., C. R. Johnson, Ed. New York, NY: Cambridge University Press, 2017
2017
-
[54]
Exploring topic coherence over many models and many topics,
K. Stevens, W. P. Kegelmeyer, D. Andrzejewski, and D. Buttler, “Exploring topic coherence over many models and many topics,” inProceedings of the 2012 Joint Conference on Empirical Meth- ods in Natural Language Processing and Com- putational Natural Language Learning, EMNLP- CoNLL 2012, July 12-14, 2012, Jeju Island, Ko- rea, J. Tsujii, J. Henderson, and ...
2012
-
[55]
Deep learning code fragments for code clone detection,
M. White, M. Tufano, C. Vendome, and D. Poshyvanyk, “Deep learning code fragments for code clone detection,” inProceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering (ASE), 2016, pp. 87–98
2016
-
[56]
Convolutional neural networks over tree struc- tures for programming language processing,
L. Mou, G. Li, L. Zhang, T. Wang, and Z. Jin, “Convolutional neural networks over tree struc- tures for programming language processing,” in Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, 2016, pp. 1287–1293
2016
-
[57]
Neural network-based graph embed- ding for cross-platform binary code similarity detection,
X. Xu, C. Liu, Q. Feng, H. Yin, L. Song, and D. Song, “Neural network-based graph embed- ding for cross-platform binary code similarity detection,” inProceedings of the 2017 ACM SIGSAC Conference on Computer and Commu- nications Security (CCS), 2017, pp. 363–376
2017
-
[58]
Learning to represent programs with graphs,
M. Allamanis, M. Brockschmidt, and M. Khademi, “Learning to represent programs with graphs,” inInternational Conference on Learning Representations (ICLR), 2018
2018
-
[59]
code2vec: Learning distributed representations of code,
U. Alon, M. Zilberstein, O. Levy, and E. Yahav, “code2vec: Learning distributed representations of code,”Proceedings of the ACM on Program- ming Languages, vol. 3, no. POPL, pp. 1–29, 2019
2019
-
[60]
Code Llama: Open Foundation Models for Code
B. Rozi` ere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y. Adi, J. Liu, R. Sauvestre, T. Remez, J. Rapin, A. Kozhevnikov, I. Ev- timov, J. Bitton, M. Bhatt, C. C. Fer- rer, A. Grattafiori, W. Xiong, A. D´ efossez, J. Copet, F. Azhar, H. Touvron, L. Mar- tin, N. Usunier, T. Scialom, and G. Syn- naeve, “Code llama: Open foundation models for co...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Ed- wards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. He...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[62]
The stack: 3 TB of permissively licensed source code,
D. Kocetkov and et al., “The stack: 3 TB of permissively licensed source code,”Trans. Mach. Learn. Res., vol. 2023, 2023
2023
-
[63]
Sentence- bert: Sentence embeddings using siamese bert- networks,
N. Reimers and I. Gurevych, “Sentence- bert: Sentence embeddings using siamese bert- networks,” inProceedings of the 2019 Confer- ence on Empirical Methods in Natural Lan- guage Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Compu- tational Linguistics, 2019
2019
-
[64]
BERT: pre-training of deep bidirectional trans- formers for language understanding,
J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional trans- formers for language understanding,” inPro- ceedings of the 2019 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Tech- nologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and...
2019
-
[65]
Facenet: A unified embedding for face recog- nition and clustering,
F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recog- nition and clustering,” in2015 IEEE Confer- ence on Computer Vision and Pattern Recogni- tion (CVPR). IEEE, Jun. 2015
2015
-
[66]
In Defense of the Triplet Loss for Person Re-Identification
A. Hermans, L. Beyer, and B. Leibe, “In defense of the triplet loss for person re-identification,” CoRR, vol. abs/1703.07737, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[67]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
H. Husain, H.-H. Wu, T. Gazit, M. Allama- nis, and M. Brockschmidt, “Codesearchnet chal- lenge: Evaluating the state of semantic code search,”CoRR, vol. abs/1909.09436, Sep. 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[68]
Multidimensional scaling by op- timizing goodness of fit to a nonmetric hypoth- esis,
J. B. Kruskal, “Multidimensional scaling by op- timizing goodness of fit to a nonmetric hypoth- esis,”Psychometrika, vol. 29, no. 1, pp. 1–27, Mar. 1964
1964
-
[69]
To- wards a metrics suite for object oriented de- sign,
S. R. Chidamber and C. F. Kemerer, “To- wards a metrics suite for object oriented de- sign,” inProceedings of the Sixth Annual Confer- ence on Object-Oriented Programming Systems, Languages, and Applications, OOPSLA 1991, Phoenix, Arizona, USA, October 6-11, 1991, A. Paepcke, Ed. ACM, 1991, pp. 197–211
1991
-
[70]
Software Framework for Topic Modelling with Large Corpora,
R. ˇReh˚ uˇ rek and P. Sojka, “Software Framework for Topic Modelling with Large Corpora,” in Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks. Valletta, Malta: ELRA, May 2010, pp. 45–50
2010
-
[71]
Fast and eager k-medoids clustering: O(k) runtime im- provement of the pam, clara, and CLARANS algorithms,
E. Schubert and P. J. Rousseeuw, “Fast and eager k-medoids clustering: O(k) runtime im- provement of the pam, clara, and CLARANS algorithms,”Information Systems, vol. 101, p. 101804, Nov. 2021
2021
-
[72]
Hastie,The elements of statistical learning, second edition ed., ser
T. Hastie,The elements of statistical learning, second edition ed., ser. Springer Series in Statis- tics, R. Tibshirani and J. H. Friedman, Eds. New York, NY: Springer, 2017, literaturverze- ichnis: Seite 699-727
2017
-
[73]
Investigating the use of lex- ical information for software system cluster- ing,
A. Corazza, S. Di Martino, V. Maggio, and G. Scanniello, “Investigating the use of lex- ical information for software system cluster- ing,” in2011 15th European Conference on Soft- ware Maintenance and Reengineering, T. Mens, Y. Kanellopoulos, and A. Winter, Eds. IEEE, Mar. 2011, pp. 35–44
2011
-
[74]
Hierarchical clus- tering for software architecture recovery,
O. Maqbool and H. Babri, “Hierarchical clus- tering for software architecture recovery,”IEEE Transactions on Software Engineering, vol. 33, no. 11, pp. 759–780, Nov. 2007
2007
-
[75]
Software architecture recovery using integrated dependencies based on structural, semantic, and directory information,
S. P. R. Puchala, J. K. Chhabra, and A. Rathee, “Software architecture recovery using integrated dependencies based on structural, semantic, and directory information,”International Journal of Information System Modeling and Design, vol. 13, no. 1, pp. 1–20, Feb. 2022
2022
-
[76]
Divergence measures based on the shan- non entropy,
J. Lin, “Divergence measures based on the shan- non entropy,”IEEE Transactions on Informa- tion Theory, vol. 37, no. 1, pp. 145–151, 1991. 23
1991
-
[77]
Infor- mation theoretic measures for clusterings com- parison: Variants, properties, normalization and correction for chance,
X. V. Nguyen, J. Epps, and J. Bailey, “Infor- mation theoretic measures for clusterings com- parison: Variants, properties, normalization and correction for chance,”J. Mach. Learn. Res., vol. 11, pp. 2837–2854, 2010
2010
-
[78]
An effectiveness mea- sure for software clustering algorithms,
Z. Wen and V. Tzerpos, “An effectiveness mea- sure for software clustering algorithms,” inPro- ceedings. 12th IEEE International Workshop on Program Comprehension, 2004.IEEE, 2004, pp. 194–203
2004
-
[79]
Cluster ensembles — A knowledge reuse framework for combining mul- tiple partitions,
A. Strehl and J. Ghosh, “Cluster ensembles — A knowledge reuse framework for combining mul- tiple partitions,”J. Mach. Learn. Res., vol. 3, pp. 583–617, 2002
2002
-
[80]
Objective criteria for the eval- uation of clustering methods,
W. M. Rand, “Objective criteria for the eval- uation of clustering methods,”Journal of the American Statistical Association, vol. 66, no. 336, pp. 846–850, Dec. 1971
1971
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.