When Compression Helps and When It Hurts: Condition-Aware Analysis of Chain-of-Thought Distillation
Pith reviewed 2026-06-26 14:06 UTC · model grok-4.3
The pith
CoT compression in distillation only helps when matched to domain, granularity, and whether savings are measured at training or inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
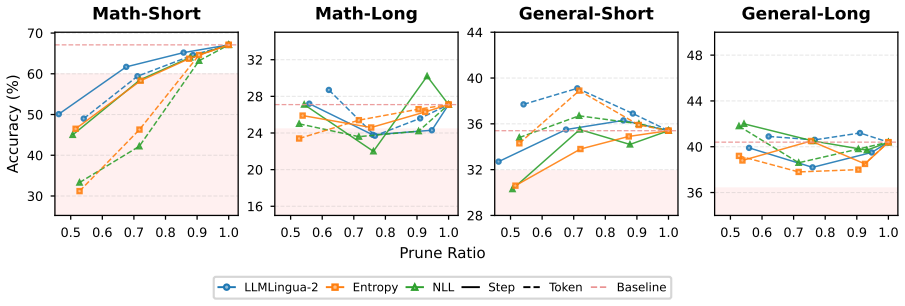
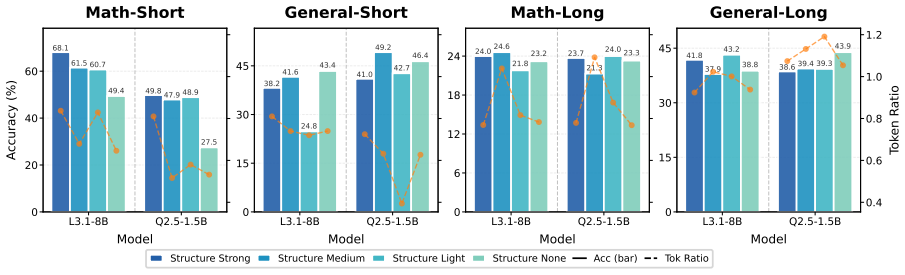
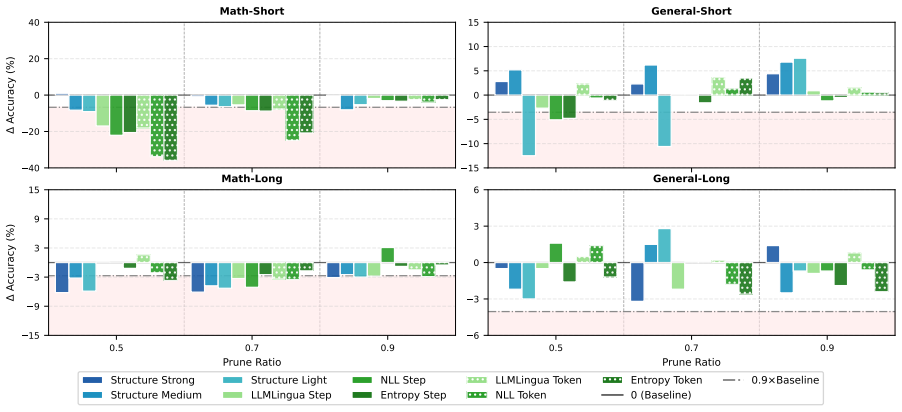
By recasting CoT compression along three dimensions—importance criterion, restructuring level, and compression budget—and sweeping them across two model families, Math and General domains, and Long-/Short-CoT regimes, the work finds that importance criterion utility is strictly governed by granularity (step-level criteria converge on a shared reasoning backbone, token-level pruning requires symbol-aware signals to preserve the logical core), restructuring level inverts across domains (Math degrades monotonically with structural disruption, aggressive rewriting acts as a denoiser on General tasks), and training-time compression does not necessarily translate to inference-time savings (Long-Co
What carries the argument
The three isolated dimensions of CoT compression: importance criterion for selection, restructuring level for rewriting, and compression budget.
If this is right
- Step-level importance criteria produce similar reasoning backbones regardless of the specific criterion chosen.
- Token-level pruning preserves the logical core only when symbol-aware signals are supplied.
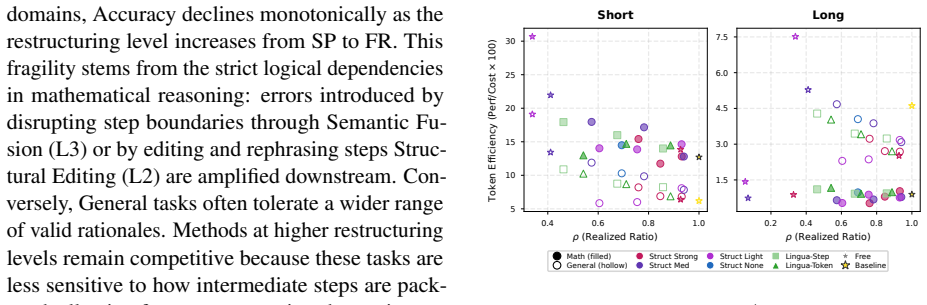
- Math performance degrades steadily as rewriting increases structural disruption.
- Aggressive rewriting improves general-domain tasks by removing noise.
- Long-CoT students keep verbose output patterns at inference even after training on concise traces.
Where Pith is reading between the lines
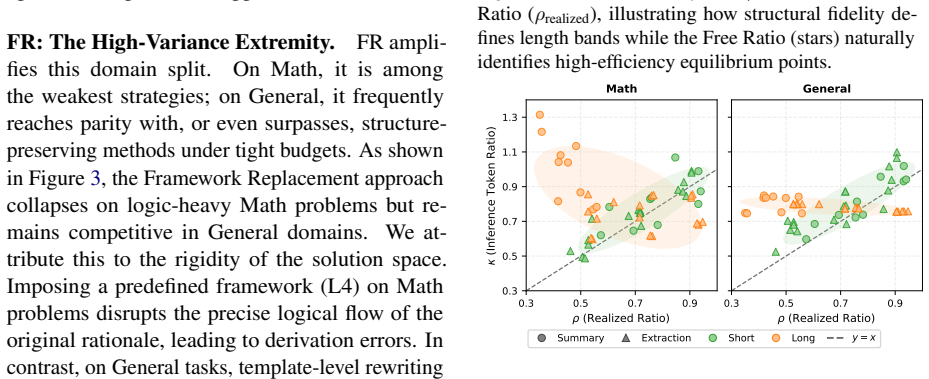
- Deployers should prefer pruning over rewriting when the target domain is mathematics.
- Cost models for long-CoT systems must measure actual inference length rather than relying on training compression ratios.
- Symbol-aware token pruning methods could be developed to extend fine-grained compression benefits beyond current limits.
- The domain inversion pattern could be tested in code-generation tasks to check whether it generalizes.
Load-bearing premise
The experimental dimensions of importance criterion, restructuring level, and compression budget can be varied independently across model families, domains, and CoT regimes without residual confounding.
What would settle it
A controlled run in which token-level pruning without symbol-aware signals still preserves full logical performance on math tasks would falsify the claim that granularity strictly governs criterion utility.
Figures


read the original abstract
Chain-of-Thought (CoT) distillation transfers multi-step reasoning from large reasoning models to smaller students, but verbose teacher traces inflate both training and inference cost. Existing CoT compression methods fall into two families, selective pruning and generative rewriting, yet prior studies have left key factors entangled: granularity is confounded with importance criteria in pruning, restructuring level is rarely isolated in rewriting, and compression budgets are not systematically evaluated across domains or regimes. We recast CoT compression along three dimensions: importance criterion, restructuring level, and compression budget. Sweeping these across two model families, Math and General domains, and Long-/Short-CoT regimes, we find that (i) importance criterion utility is strictly governed by granularity: step-level criteria converge on a shared reasoning backbone, while token-level pruning requires symbol-aware signals to preserve the logical core; (ii) restructuring level inverts across domains: Math degrades monotonically with structural disruption, while aggressive rewriting acts as a denoiser on General tasks; (iii) training-time compression does not necessarily translate to inference-time savings: Long-CoT students retain verbose habits despite concise supervision, making the training ratio an optimistic lower bound on deployment cost. These findings yield condition-aware guidelines for matching compression to deployment context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper recasts CoT compression into three isolable dimensions—importance criterion, restructuring level, and compression budget—and sweeps them across two model families, Math/General domains, and Long-/Short-CoT regimes. It reports three condition-specific findings: (i) step-level criteria converge on a shared backbone while token-level pruning needs symbol-aware signals; (ii) structural disruption hurts Math monotonically but aggressive rewriting denoises General tasks; (iii) training-time compression does not guarantee inference-time savings because Long-CoT students retain verbose habits.
Significance. If the three dimensions can be varied independently with explicit interaction checks, the work supplies practical, condition-aware guidelines that prior entangled studies lacked. The broad factorial-style sweep and the falsifiable claim that training ratios are optimistic lower bounds on deployment cost are strengths; however, the empirical nature means the significance hinges entirely on whether the design actually isolates the factors.
major comments (1)
- [§3] §3 (Experimental Design): The central claim that the sweeps disentangle importance criterion, restructuring level, and compression budget requires a near-factorial design with explicit tests for model×domain×regime interactions. The abstract asserts prior work left factors entangled, yet without reported interaction statistics or balanced cell counts (e.g., token-level symbol-aware pruning tested equally across Long-CoT Math vs. Short-CoT General), finding (i) could reflect sampling imbalance rather than a general granularity principle. The same risk applies to the domain inversion in (ii) and the inference-time retention in (iii).
minor comments (2)
- [Abstract] Abstract: The phrase 'strictly governed by granularity' is strong; the results section should qualify it with effect-size ranges or counter-examples rather than leaving it unqualified.
- Table/Figure captions: Ensure every table reports the exact number of runs, seeds, and whether error bars reflect standard deviation across models or domains.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need to more explicitly demonstrate factor isolation. We respond to the single major comment below and outline targeted revisions.
read point-by-point responses
-
Referee: [§3] §3 (Experimental Design): The central claim that the sweeps disentangle importance criterion, restructuring level, and compression budget requires a near-factorial design with explicit tests for model×domain×regime interactions. The abstract asserts prior work left factors entangled, yet without reported interaction statistics or balanced cell counts (e.g., token-level symbol-aware pruning tested equally across Long-CoT Math vs. Short-CoT General), finding (i) could reflect sampling imbalance rather than a general granularity principle. The same risk applies to the domain inversion in (ii) and the inference-time retention in (iii).
Authors: The experimental grid varies importance criterion, restructuring level, and compression budget while crossing each with the two model families, two domains, and two CoT regimes, producing a broad (though not perfectly balanced) factorial coverage. The reported patterns were checked for consistency across the populated cells rather than relying on any single subset. We acknowledge that formal interaction statistics (e.g., ANOVA) and an explicit cell-count table are absent. We will therefore revise §3 to add (a) a supplementary table enumerating runs per condition combination and (b) a short discussion of qualitative interaction patterns observed in the data. These additions will increase transparency without requiring new experiments. revision: partial
Circularity Check
Purely empirical study; no derivation chain or self-referential predictions
full rationale
The paper is an experimental analysis that sweeps three dimensions (importance criterion, restructuring level, compression budget) across model families, domains, and CoT regimes. It reports observed patterns from those sweeps without any equations, fitted parameters presented as predictions, self-citations used to establish uniqueness theorems, or ansatzes smuggled in via prior work. The central claims are condition-specific empirical findings, not derivations that reduce to inputs by construction. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training verifiers to solve math word prob- lems. CoRR, abs/2110.14168. Yingqian Cui, Pengfei He, Jingying Zeng, Hui Liu, Xi- anfeng Tang, Zhenwei Dai, Yan Han, Chen Luo, Jing Huang, Zhen Li, Suhang Wang, Yue Xing, Jiliang Tang, and Qi He. 2025. Stepwise perplexity-guided refinement for efficient chain-of-thought reasoning in large language models. Prepri...
Pith/arXiv arXiv 2025
-
[2]
C3oT: Generating shorter chain-of-thought without compromising effectiveness. Preprint, arXiv:2412.11664. Zeju Li, Jianyuan Zhong, Ziyang Zheng, Xiangyu Wen, Zhijian Xu, Yingying Cheng, Fan Zhang, and Qiang Xu. 2025. Compressing chain-of-thought in LLMs via step entropy. Preprint, arXiv:2508.03346. Mathematical Association of America. 2025. American Mathe...
arXiv 2025
-
[3]
**Evaluate each logical component/step** within the THOUGHT PROCESS
-
[4]
* **DELETE:** If a step is redundant, unnecessary, or logically flawed, remove it
Based on your evaluation, decide how to act on it: * **KEEP:** If a step is necessary and concise, keep it. * **DELETE:** If a step is redundant, unnecessary, or logically flawed, remove it. * **SINGLE-STEP COMPRESS:** If a step is neces- sary but verbose, rewrite it more concisely. * **MULTI-STEP COMPRESS:** If several adjacent steps can be logically com...
-
[5]
Ensure the final answer is clearly stated at the end
Synthesize your revisions into a single, coherent, and fluent reasoning path that preserves the core logical progression to the final answer. Ensure the final answer is clearly stated at the end
-
[6]
key info
Conclude with the "ANSWER" section only for ques- tions with a definitive, boxable answer. Otherwise, omit it entirely. Level 3: Semantic Fusion (SF).The prompt encourages abstraction by instructing the model to retain only the essential "key info." The SF Compress Strategy Section - Retain the key info needed to solve the question and do not add addition...
-
[7]
You are **NOT** compressing or editing the original text
**PRIMARY GOAL:** Your main goal is to **RE- PLACE** the original ‘THOUGHT PROCESS‘. You are **NOT** compressing or editing the original text. You are generating a superior, structured replacement from scratch
-
[8]
**ASSESS COMPLEXITY:** First, analyze the provided ‘QUESTION‘ to assess its complexity (simple, moderately complex, or highly complex)
-
[9]
**CHOOSE FRAMEWORK:** Based on your assessment, choose **ONE** of the following three frameworks to generate a new thought process
-
[10]
**FRAMEWORKS:** * **For simple problems:** **Analysis:** [Understand the core elements and goals of the problem] **Approach:** [Propose direct solution methods] **Summary:** [Concisely summarize the solution approach and key points] * **For moderately complex problems:** **Analysis:** [Understand the problem and identify key points and challenges] **Initi...
-
[11]
**DO NOT** follow its structure, wording, or verbosity
**REFERENCE USAGE:** Use the original ‘THOUGHT PROCESS‘ (‘answer‘) only as a reference to understand the key values, steps, and final conclu- sion. **DO NOT** follow its structure, wording, or verbosity. Your new output must be self-contained and strictly adhere to the selected structured framework. A.3 Component 2: Compression Ratio Control The {STRICT_L...
-
[12]
First, carefully read the entire THOUGHT PROCESS
-
[13]
Then, mentally apply the rules from the COMPRESS STRATEGY below
-
[14]
Self-Determined Budget
Estimate the final word count that would result from this pruning process. Let’s call this your "Self-Determined Budget". ### Phase 2: Execution
-
[15]
Now, perform the actual pruning according to the COMPRESS STRATEGY
-
[16]
Self-Determined Budget
Your final output’s word count MUST be close to the "Self-Determined Budget" you estimated in Phase 1. B Experimental Details B.1 Implementation Details Training Corpora. (R)To study how compres- sion strategies perform across different reasoning lengths, we create training sets from two repre- sentative datasets. For theshort-CoTregime, we use 5,000 inst...
2025
-
[17]
let", "assume
Class 1: Constraint-Bearing & Symbolic (High Priority).This class captures the struc- tural anchors of the reasoning chain. It includes: • Logic Markers:Key deductive connec- tives (e.g.,"let", "assume", "implies", "therefore", "since", "if", "iff"). • Math Operators & Symbols:All stan- dard arithmetic operators, comparators, and Unicode mathematical symb...
-
[18]
if", "not
Class 2: Stopwords.Tokens found in stan- dard English stopword lists (sourced from NLTK (Bird and Loper, 2004)/scikit-learn). Crucially, to prevent misclassification, any stop- word that also appears in theLogic Markerslist (e.g., "if", "not") is removed from this set and forced into Class 1. Thus, Class 2 strictly repre- sents low-semantic syntactic glue
2004
-
[19]
Class 3: Content.All remaining tokens that do not fall into Class 1 or Class 2. These are typically domain-specific nouns, verbs, and ad- jectives describing the problem context. F.2 Results: Deletion Distribution Table 12 presents theDeletion Ratefor each cate- gory, defined as the fraction of tokens of that type removed from the original trace. The data...
-
[20]
Alignment:We align samples by question ID across the generated ‘.jsonl‘ outputs
-
[21]
Index Mapping:For each sample, we map the retained text segments back to the original teacher step indices{1, . . . , N}
-
[22]
Set Construction:We derive the set ofdeleted indices for each method, denoted as DA and DB
-
[23]
Math-Prot
Metric:We compute the Jaccard Similarity Co- efficient for the deletion sets: J(D A,D B) = |DA ∩ DB| |DA ∪ DB| (17) This process is repeated for each target ratio and averaged across the dataset. G.2 Divergence in Deletion Choices Table 14 presents the overlap ofdeleted steps across methods. We observe a clear dichotomy: • High Internal Consistency:Entrop...
2025
-
[24]
Global organization: the rationale states the goal/- known facts clearly and follows a sensible overall plan
-
[25]
Which of the authors of this article can endorse?
Step-to-step logic: each step follows logically from previous steps, without unexplained jumps. 3. Use of intermediate conclusions: important intermediate results are clearly derived and then used later. 4. Noise and re- dundancy: the rationale avoids unnecessary digressions, off-topic commentary, or excessive repetition that makes it harder to follow. If...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.