Physics-Preserving Latent Compression for Zero-Shot Resolution Transfer in 3D Turbulence
Pith reviewed 2026-06-26 12:44 UTC · model grok-4.3
The pith
PPLC uses a shared patch-based variational autoencoder to compress 3D turbulence data while preserving physical properties and enabling zero-shot transfer to higher resolutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
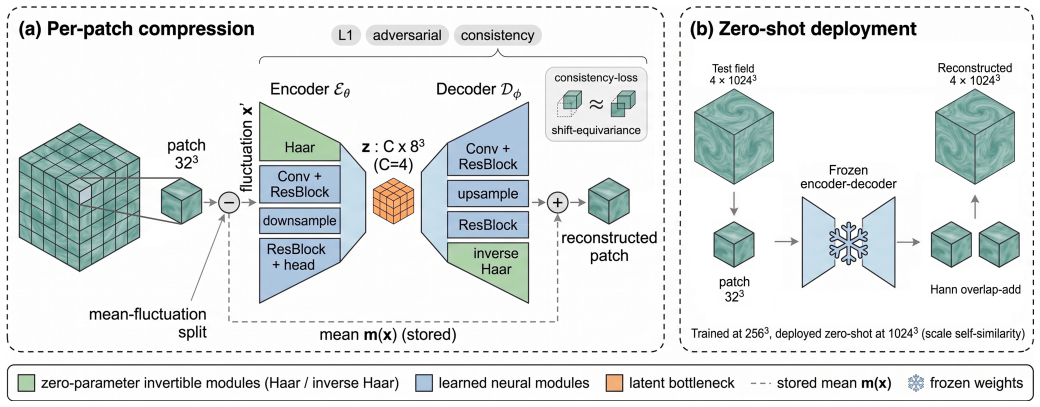
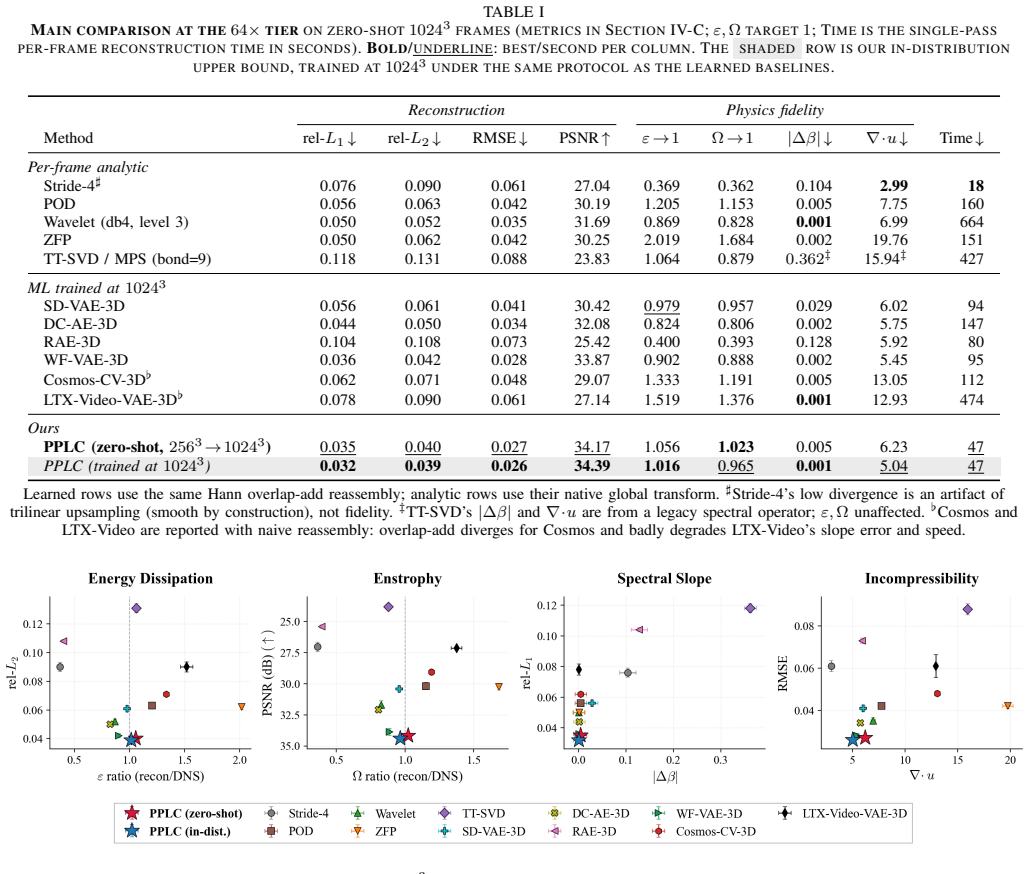
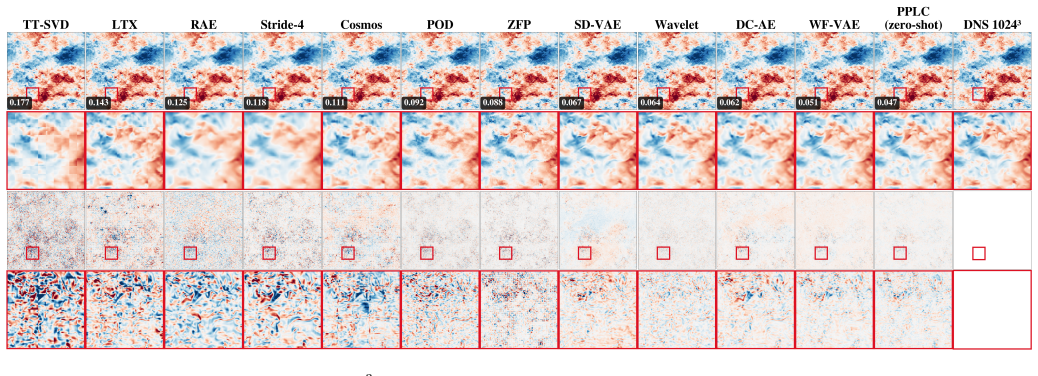
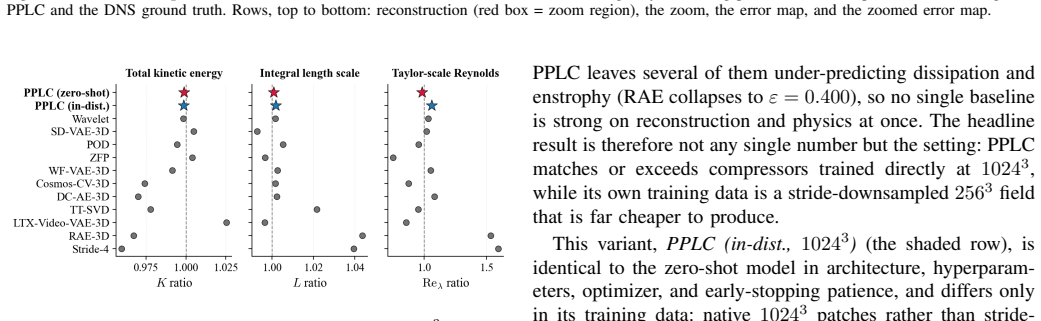
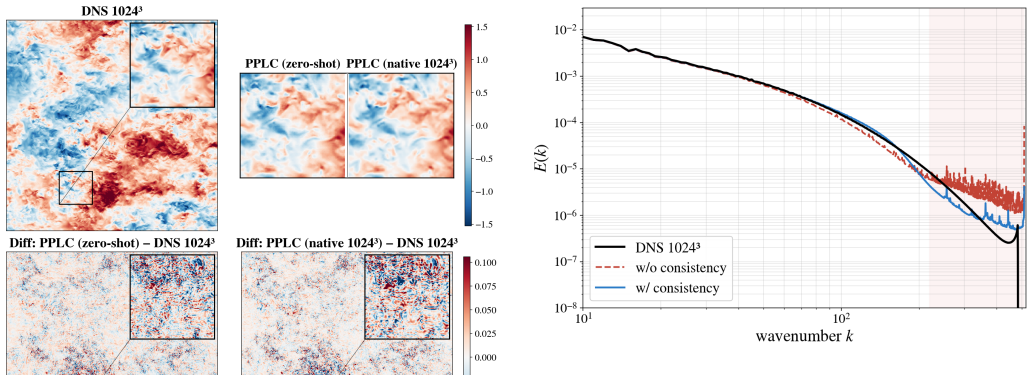
PPLC treats fixed-size patches as transferable units in a variational autoencoder that operates independently of the global grid size, combining exact mean preservation, zero-mean fluctuation encoding, an invertible Haar wavelet front-end, shift-consistency regularization, and overlap-aware reconstruction to achieve zero-shot resolution transfer from stride-downsampled 256^3 training fields to 1024^3 test fields while keeping physical diagnostics closer to ground truth than classical and learned baselines.
What carries the argument
The shared variational autoencoder applied to fixed-size patches with physics-preserving components including mean preservation and Haar wavelet front-end.
Load-bearing premise
Fixed-size patches can be treated as transferable units independent of global grid size, justified by inertial-range scale similarity.
What would settle it
A significant deviation in energy spectra or dissipation rates when applying the trained model to 1024^3 fields compared to direct simulation would falsify the zero-shot transfer effectiveness.
Figures
read the original abstract
High-resolution turbulence modeling is essential for scientific computing, but remains constrained by the cost of direct numerical simulation and the scarcity of full-resolution data. Existing scientific compressors reduce storage but typically operate on per-frame representations, whereas learned compressors yield compact latents that are often resolution-dependent and weakly aligned with the physics of turbulence. This raises the need for a compression framework that reduces data size, preserves physical diagnostics, and transfers from low-resolution training fields to high-resolution test fields without retraining. In this paper, we propose Physics-Preserving Latent Compression (PPLC), a patch-local latent compressor for three-dimensional turbulence. Motivated by inertial-range scale similarity, PPLC treats fixed-size patches as transferable units and applies a shared variational autoencoder independently of the global grid size. It combines exact mean preservation, zero-mean fluctuation encoding, an invertible Haar wavelet front-end, shift-consistency regularization, and overlap-aware reconstruction. Instantiated on forced isotropic turbulence, PPLC is trained only on stride-downsampled 256^3 fields and transfers zero-shot to 1024^3 fields. Experiments show that PPLC improves the balance between reconstruction accuracy and physical fidelity over classical and learned baselines, keeping diagnostics such as dissipation, enstrophy, energy spectra, and incompressibility closer to the ground truth. Beyond turbulence compression, PPLC offers a general strategy for physics-preserving latent representations that support data-efficient scientific surrogate modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Physics-Preserving Latent Compression (PPLC), a patch-local variational autoencoder for 3D turbulence data. Motivated by inertial-range scale similarity, it treats fixed-size patches as resolution-independent units and combines exact mean preservation, zero-mean fluctuation encoding, an invertible Haar wavelet front-end, shift-consistency regularization, and overlap-aware reconstruction. The method is trained exclusively on stride-downsampled 256^3 forced isotropic turbulence fields and claims zero-shot transfer to native 1024^3 fields while improving the trade-off between reconstruction accuracy and physical fidelity (dissipation, enstrophy, energy spectra, incompressibility) relative to classical and learned baselines.
Significance. If the zero-shot transfer and physical-preservation claims are quantitatively validated, the work would offer a practical route to resolution-agnostic compression for large-scale turbulence datasets, reducing storage demands while supporting downstream surrogate modeling that respects key invariants.
major comments (2)
- [Abstract] Abstract: the central claim that PPLC 'improves the balance between reconstruction accuracy and physical fidelity' and keeps 'diagnostics such as dissipation, enstrophy, energy spectra, and incompressibility closer to the ground truth' is asserted without any reported quantitative metrics, baseline comparisons, error bars, or dataset specifications. This absence prevents evaluation of whether the experimental results actually support the claimed superiority and zero-shot transfer.
- [Motivation] Motivation section: the zero-shot guarantee rests on the assumption that a VAE trained on stride-downsampled 256^3 patches produces latents whose decoded outputs preserve the listed diagnostics on native 1024^3 patches via inertial-range similarity. The manuscript does not address whether the downsampling operator imprints a spectral filter or aliasing pattern absent from the high-resolution DNS; if it does, the learned nonlinear encoder/decoder mappings would be tuned to that artifact rather than to resolution-independent physics, undermining the transfer claim.
minor comments (1)
- [Abstract] The abstract states the method is 'instantiated on forced isotropic turbulence' but supplies no Reynolds number, forcing mechanism, or grid details for either the 256^3 training or 1024^3 test data.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our manuscript. We address each major comment point-by-point below, proposing revisions to improve clarity and rigor where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that PPLC 'improves the balance between reconstruction accuracy and physical fidelity' and keeps 'diagnostics such as dissipation, enstrophy, energy spectra, and incompressibility closer to the ground truth' is asserted without any reported quantitative metrics, baseline comparisons, error bars, or dataset specifications. This absence prevents evaluation of whether the experimental results actually support the claimed superiority and zero-shot transfer.
Authors: The abstract is intended as a high-level summary. Quantitative metrics (including relative errors, error bars, baseline comparisons against classical compressors and other learned methods, and dataset details for the 256^3 training and 1024^3 test fields) are reported in full in Section 4, with supporting tables and figures demonstrating improvements in physical diagnostics. We agree the abstract would benefit from greater specificity and will revise it to include key quantitative highlights, such as percentage improvements in dissipation and enstrophy preservation. revision: yes
-
Referee: [Motivation] Motivation section: the zero-shot guarantee rests on the assumption that a VAE trained on stride-downsampled 256^3 patches produces latents whose decoded outputs preserve the listed diagnostics on native 1024^3 patches via inertial-range similarity. The manuscript does not address whether the downsampling operator imprints a spectral filter or aliasing pattern absent from the high-resolution DNS; if it does, the learned nonlinear encoder/decoder mappings would be tuned to that artifact rather than to resolution-independent physics, undermining the transfer claim.
Authors: This is a valid concern regarding the training data generation. Stride-downsampling was selected to produce fixed-size patches at lower effective resolution while preserving patch locality and domain physics. The invertible Haar wavelet front-end and physics-preserving constraints (mean preservation, zero-mean fluctuations) are intended to focus the latent representation on resolution-independent inertial-range features. We will revise the Motivation section to explicitly discuss the spectral characteristics of the downsampling operator, including potential aliasing, and add supporting analysis or validation showing that the learned mappings and empirical zero-shot performance on native 1024^3 fields remain robust. revision: yes
Circularity Check
No circularity: derivation relies on external physical assumption and explicit architectural choices rather than self-definition or fitted inputs
full rationale
The provided abstract and description present PPLC as a composite construction (exact mean preservation, zero-mean fluctuation encoding, Haar wavelet front-end, shift-consistency regularization, overlap-aware reconstruction) motivated by inertial-range scale similarity. No equations are shown that equate a claimed prediction or performance metric to a fitted parameter or self-referential normalization by construction. The zero-shot transfer claim rests on an external turbulence assumption rather than reducing to the training procedure itself. No self-citations or uniqueness theorems are invoked in the given text. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fourier neural operator for parametric partial differential equations,
Z. Li, N. B. Kovachki, K. Azizzadenesheli, K. Bhattacharya, A. Stuart, A. Anandkumaret al., “Fourier neural operator for parametric partial differential equations,” inInternational Conference on Learning Repre- sentations (ICLR), 2021
2021
-
[2]
Neural operator: Learning maps between function spaces with applications to pdes,
N. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. Stu- art, and A. Anandkumar, “Neural operator: Learning maps between function spaces with applications to pdes,”Journal of Machine Learning Research, 2023
2023
-
[3]
Machine learning–accelerated computational fluid dynamics,
D. Kochkov, J. A. Smith, A. Alieva, Q. Wang, M. P. Brenner, and S. Hoyer, “Machine learning–accelerated computational fluid dynamics,” Proceedings of the National Academy of Sciences, 2021
2021
-
[4]
Learned coarse models for efficient turbulence simulation,
K. Stachenfeld, D. B. Fielding, D. Kochkov, M. Cranmer, T. Pfaff, J. Godwin, C. Cui, S. Ho, P. Battaglia, and A. Sanchez-Gonzalez, “Learned coarse models for efficient turbulence simulation,” inInter- national Conference on Learning Representations (ICLR), 2022
2022
-
[5]
Auto-encoding variational Bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational Bayes,” in International Conference on Learning Representations (ICLR), 2014
2014
-
[6]
Taming transformers for high- resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high- resolution image synthesis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 873–12 883
2021
-
[7]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[8]
Deep compression autoencoder for efficient high-resolution diffusion models,
J. Chen, H. Cai, J. Chen, E. Xie, S. Yang, H. Tang, M. Li, and S. Han, “Deep compression autoencoder for efficient high-resolution diffusion models,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 96 539–96 560
2025
-
[9]
Diffusion transformers with representation autoencoders,
B. Zheng, N. Ma, S. Tong, and S. Xie, “Diffusion transformers with representation autoencoders,”arXiv preprint arXiv:2510.11690, 2025
Pith/arXiv arXiv 2025
-
[10]
Wf- vae: Enhancing video vae by wavelet-driven energy flow for latent video diffusion model,
Z. Li, B. Lin, Y . Ye, L. Chen, X. Cheng, S. Yuan, and L. Yuan, “Wf- vae: Enhancing video vae by wavelet-driven energy flow for latent video diffusion model,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 17 778–17 788
2025
-
[11]
Cosmos world foundation model platform for physical ai,
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopad- hyay, Y . Chen, Y . Cui, Y . Dinget al., “Cosmos world foundation model platform for physical ai,”arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[12]
Ltx-video: Realtime video latent diffusion,
Y . HaCohen, N. Chiprut, B. Brazowski, D. Shalem, D. Moshe, E. Richardson, E. Levin, G. Shiran, N. Zabari, O. Gordon et al., “Ltx-video: Realtime video latent diffusion,”arXiv preprint arXiv:2501.00103, 2024
Pith/arXiv arXiv 2024
-
[13]
The structure of inhomogeneous turbulent flows,
J. L. Lumley, “The structure of inhomogeneous turbulent flows,”Atmo- spheric turbulence and radio wave propagation, pp. 166–178, 1967
1967
-
[14]
Turbulence and the dynamics of coherent structures. parts i-iii,
S. Lawrence, “Turbulence and the dynamics of coherent structures. parts i-iii,”Q Appl Math, vol. 46, no. 3, p. 561, 1987
1987
-
[15]
Orthonormal bases of compactly supported wavelets,
I. Daubechies, “Orthonormal bases of compactly supported wavelets,” Communications on pure and applied mathematics, vol. 41, no. 7, pp. 909–996, 1988
1988
-
[16]
Fixed-rate compressed floating-point arrays,
P. Lindstrom, “Fixed-rate compressed floating-point arrays,”IEEE trans- actions on visualization and computer graphics, vol. 20, no. 12, pp. 2674–2683, 2014
2014
-
[17]
Fast error-bounded lossy hpc data compression with sz,
S. Di and F. Cappello, “Fast error-bounded lossy hpc data compression with sz,” in2016 ieee international parallel and distributed processing symposium (ipdps). IEEE, 2016
2016
-
[18]
Multilevel tech- niques for compression and reduction of scientific data—the multivariate case,
M. Ainsworth, O. Tugluk, B. Whitney, and S. Klasky, “Multilevel tech- niques for compression and reduction of scientific data—the multivariate case,”SIAM Journal on Scientific Computing, 2019
2019
-
[19]
Tensor-train decomposition,
I. V . Oseledets, “Tensor-train decomposition,”SIAM Journal on Scien- tific Computing, vol. 33, no. 5, pp. 2295–2317, 2011
2011
-
[20]
The density-matrix renormalization group in the age of matrix product states,
U. Schollw ¨ock, “The density-matrix renormalization group in the age of matrix product states,”Annals of physics, vol. 326, no. 1, pp. 96–192, 2011
2011
-
[21]
The local structure of turbulence in incompressible viscous fluid for very large reynolds numbers,
A. N. Kolmogorov, “The local structure of turbulence in incompressible viscous fluid for very large reynolds numbers,”Proceedings of the Royal Society of London. Series A: Mathematical and Physical Sciences, vol. 434, no. 1890, pp. 9–13, 1991
1991
-
[22]
Turbulent flows,
S. B. Pope, “Turbulent flows,”Measurement Science and Technology, vol. 12, no. 11, pp. 2020–2021, 2001
2020
-
[23]
Flowrefiner: Flow matching-based iterative refinement for 3d turbulent flow simulation,
Y . Dai, Y . Sun, Y . Chen, S. Chen, X. Jia, and R. Yu, “Flowrefiner: Flow matching-based iterative refinement for 3d turbulent flow simulation,” 2026
2026
-
[24]
Pest: Physics-enhanced swin transformer for 3d turbulence simulation,
Y . Dai, S. Chen, X. Jia, P. Givi, and R. Yu, “Pest: Physics-enhanced swin transformer for 3d turbulence simulation,” 2026
2026
-
[25]
beta-V AE: Learning basic visual concepts with a constrained variational framework,
I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner, “beta-V AE: Learning basic visual concepts with a constrained variational framework,” inInternational Conference on Learning Representations, 2017
2017
-
[26]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete representation learning,” vol. 30, 2017
2017
-
[27]
Language- conditioned world modeling for visual navigation,
Y . Dong, F. Wu, Y . Dai, L. Kong, G. Chen, X. Zhu, Q. Hu, T. Wang, J. Garnica, F. Liu, S. Huang, Q. Dai, and Z.-Q. Cheng, “Language- conditioned world modeling for visual navigation,” 2026
2026
-
[28]
Learning nonlinear operators via deeponet based on the universal approximation theorem of operators,
L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis, “Learning nonlinear operators via deeponet based on the universal approximation theorem of operators,”Nature machine intelligence, 2021
2021
-
[29]
U-NO: U-shaped neural operators,
M. A. Rahman, Z. E. Ross, and K. Azizzadenesheli, “U-NO: U-shaped neural operators,”Transactions on Machine Learning Research, 2023
2023
-
[30]
Multiwavelet-based operator learning for differential equations,
G. Gupta, X. Xiao, and P. Bogdan, “Multiwavelet-based operator learning for differential equations,”Advances in neural information processing systems, 2021
2021
-
[31]
Au- toencoders in function space,
J. Bunker, M. Girolami, H. Lambley, A. M. Stuart, and T. Sullivan, “Au- toencoders in function space,”Journal of Machine Learning Research, vol. 26, no. 165, pp. 1–54, 2025
2025
-
[32]
Implicit neural representations with periodic activation functions,
V . Sitzmann, J. Martel, A. Bergman, D. Lindell, and G. Wetzstein, “Implicit neural representations with periodic activation functions,” Advances in neural information processing systems, 2020
2020
-
[33]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” inProceedings of the AAAI conference on artificial intelligence, 2018
2018
-
[34]
Conditional neural field for spatial dimension reduction of turbulence data: A comparison study,
J. Guo, P. Du, X. Fan, Y . Li, and J.-X. Wang, “Conditional neural field for spatial dimension reduction of turbulence data: A comparison study,” Physics of Fluids, vol. 38, no. 2, 2026
2026
-
[35]
Learning PDE solvers with physics and data: A unifying view of physics-informed neural networks and neural operators,
Y . Dai, S. Chen, Z. Wang, X. Jia, Y . Xie, V . Kumar, and R. Yu, “Learning PDE solvers with physics and data: A unifying view of physics-informed neural networks and neural operators,” 2026
2026
-
[36]
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations,
M. Raissi, P. Perdikaris, and G. E. Karniadakis, “Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations,” Journal of Computational physics, 2019
2019
-
[37]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, 2020
2020
-
[38]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023
2023
-
[39]
A physics-informed diffusion model for high-fidelity flow field reconstruction,
D. Shu, Z. Li, and A. B. Farimani, “A physics-informed diffusion model for high-fidelity flow field reconstruction,”Journal of Computational Physics, 2023
2023
-
[40]
Generative adversarial nets,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” Advances in neural information processing systems, 2014
2014
-
[41]
J. H. Lim and J. C. Ye, “Geometric gan,”arXiv preprint arXiv:1705.02894, 2017
Pith/arXiv arXiv 2017
-
[42]
Data exploration of turbulence simulations using a database cluster,
E. Perlman, R. Burns, Y . Li, and C. Meneveau, “Data exploration of turbulence simulations using a database cluster,” inProceedings of the 2007 ACM/IEEE Conference on Supercomputing, 2007, pp. 1–11
2007
-
[43]
A public turbulence database cluster and applications to study lagrangian evolution of velocity increments in turbulence,
Y . Li, E. Perlman, M. Wan, Y . Yang, C. Meneveau, R. Burns, S. Chen, A. Szalay, and G. Eyink, “A public turbulence database cluster and applications to study lagrangian evolution of velocity increments in turbulence,”Journal of Turbulence, no. 9, p. N31, 2008
2008
-
[44]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations, 2019
2019
-
[45]
Loss functions for image restoration with neural networks,
H. Zhao, O. Gallo, I. Frosio, and J. Kautz, “Loss functions for image restoration with neural networks,”IEEE Transactions on computational imaging, 2016
2016
-
[46]
Isl 2 physics informed loss always suitable for training physics informed neural network?
C. Wang, S. Li, D. He, and L. Wang, “Isl 2 physics informed loss always suitable for training physics informed neural network?”Advances in Neural Information Processing Systems, 2022
2022
-
[47]
Identifying and solving conditional image leakage in image-to-video diffusion model,
M. Zhao, H. Zhu, C. Xiang, K. Zheng, C. Li, and J. Zhu, “Identifying and solving conditional image leakage in image-to-video diffusion model,”Advances in Neural Information Processing Systems, 2024
2024
-
[48]
Skill scores based on the mean square error and their relationships to the correlation coefficient,
A. H. Murphy, “Skill scores based on the mean square error and their relationships to the correlation coefficient,”Monthly weather review, 1988
1988
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.