Fixed RAG Compression Collapses Measured Reader Scaling
Pith reviewed 2026-06-26 12:29 UTC · model grok-4.3
The pith
Fixed RAG compression raises average accuracy while hiding upgrades in stronger readers and reversing model rankings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
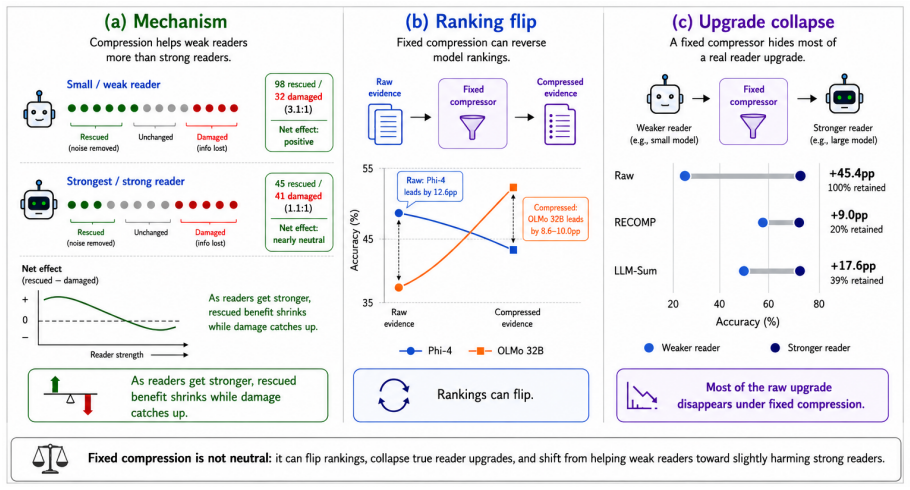
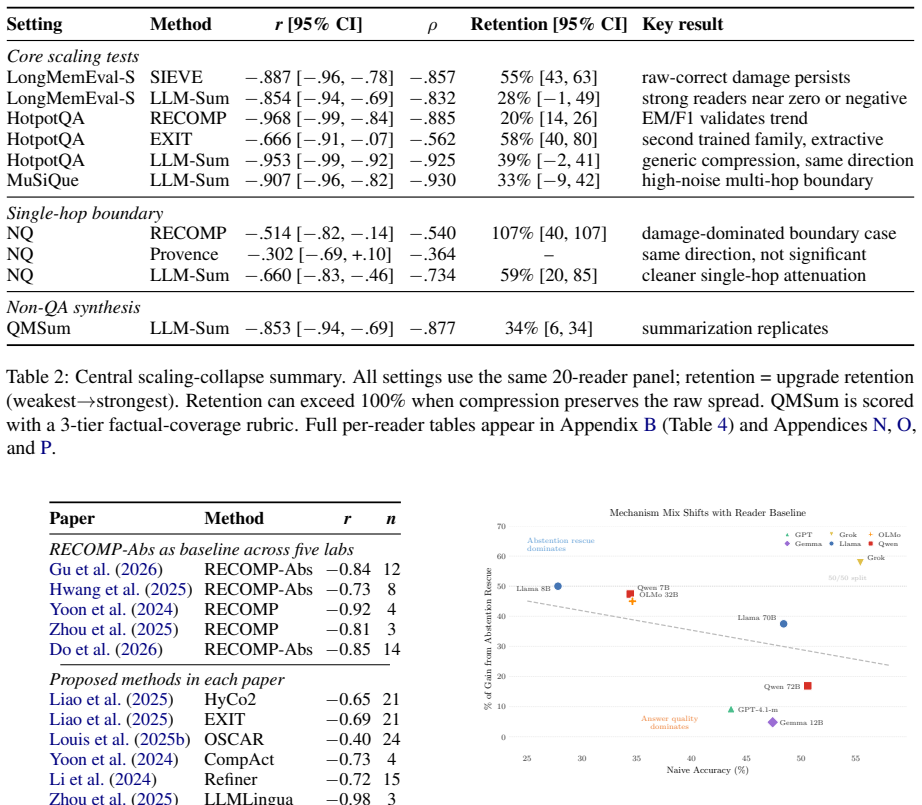
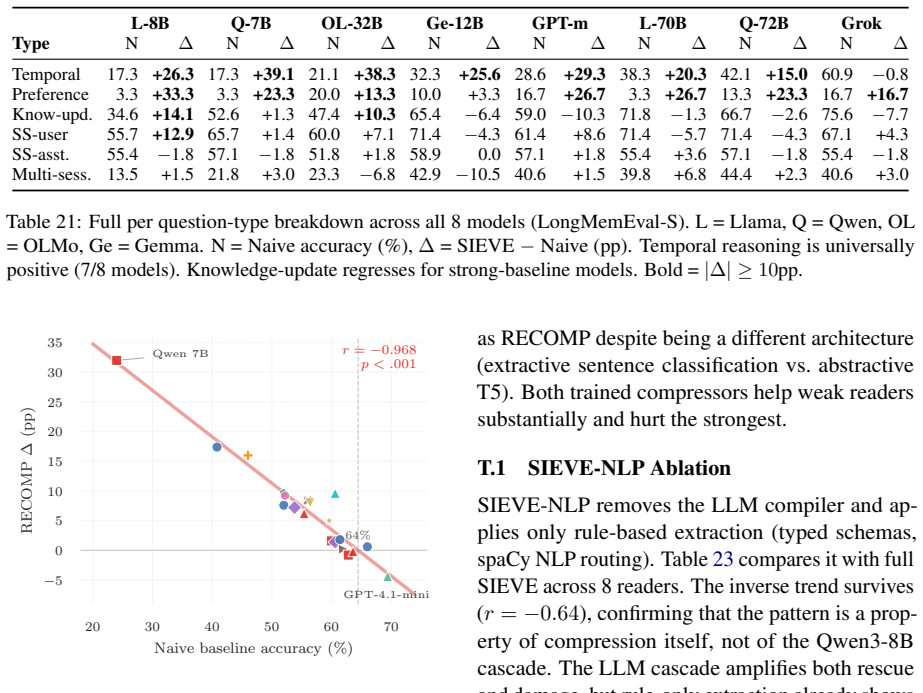
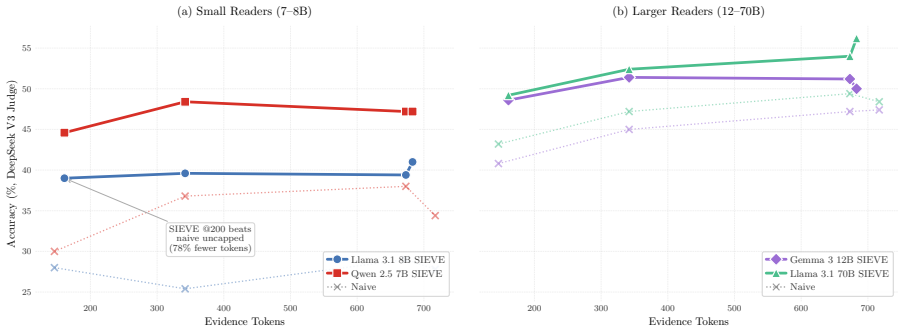
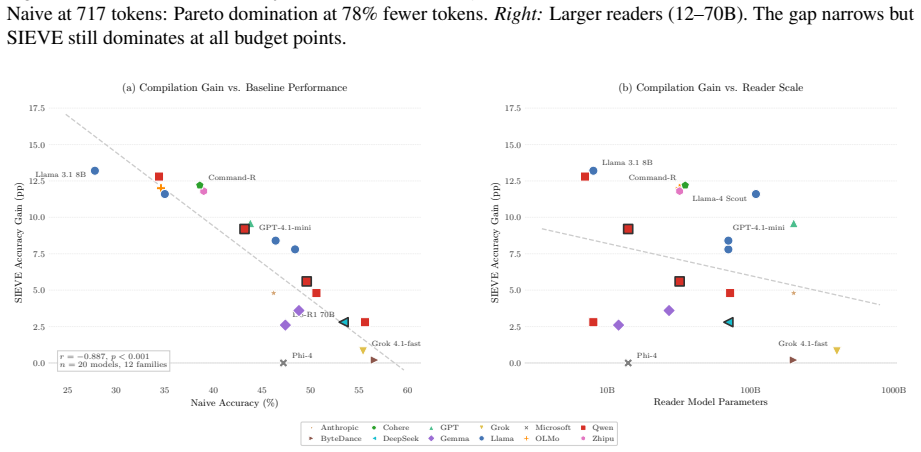
Fixed compression can raise average accuracy while hiding reader upgrades and reversing model rankings. Across 20 readers and ten domain-method settings over four QA benchmarks and one summarization benchmark, compression gain decreases with reader baseline (nine of ten settings significant, p < 0.05). Generic summarization flips 31% of pairwise model rankings on LongMemEval-S, and a fixed HotpotQA compressor hides 80% of the raw upgrade from Qwen 7B to GPT-4.1-mini. Two opposing forces explain this paradox: compression rescues weak readers by removing noise they cannot filter, and harms strong readers by dropping details they would have used.
What carries the argument
The interaction between fixed compression and reader baseline strength, driven by opposing effects of noise removal versus detail loss.
If this is right
- Compressor evaluations require multiple readers of differing baseline strengths rather than one or two fixed readers.
- A single fixed compressor can mask up to 80 percent of the performance difference between a 7B model and a stronger model.
- Generic summarization alone can reverse 31 percent of pairwise model rankings on long-context summarization tasks.
- Nine of ten domain-method combinations show statistically significant reduction in compression benefit as reader strength increases.
- The released ragscale toolkit makes it possible to audit any compressor against reader scaling with only three readers.
Where Pith is reading between the lines
- Compressor training objectives could incorporate reader strength as an explicit variable to reduce the penalty to strong readers.
- The same interaction may affect other fixed preprocessing steps such as chunking or rewriting in LLM pipelines.
- Re-measuring published RAG scaling curves with variable compression would likely change reported trends.
- Open release of per-transition compression data enables independent verification of the pattern on new models.
Load-bearing premise
The 20 readers span a meaningful range of baseline strengths and the tested compressors are representative of those used in prior work.
What would settle it
Re-run the scaling experiments with a fresh set of readers whose baselines cover a wide range and with a new fixed compressor, then test whether gain still decreases reliably with baseline strength.
Figures


read the original abstract
Retrieval-Augmented Generation (RAG) compression papers often evaluate a compressor on one to three readers and treat the compressed evidence layer as evaluation-neutral. We show this assumption is false: fixed compression can raise average accuracy while hiding reader upgrades and reversing model rankings. Across 20 readers and ten domain-method settings over four QA benchmarks and one summarization benchmark, compression gain decreases with reader baseline (nine of ten settings significant, p < 0.05). Generic summarization flips 31% of pairwise model rankings on LongMemEval-S, and a fixed HotpotQA compressor hides 80% of the raw upgrade from Qwen 7B to GPT-4.1-mini. Two opposing forces explain this paradox: compression rescues weak readers by removing noise they cannot filter, and harms strong readers by dropping details they would have used. The pattern appears across structured compilation, generic summarization, three trained compressor families, query-focused summarization, and an external audit of nine published compression papers. We release ragscale, a toolkit built on 177,000 row-level compression transitions, so any compression paper can audit reader scaling with three readers in one day.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript demonstrates that fixed RAG compression, while often increasing average accuracy, can conceal improvements from stronger reader models and reverse their rankings. Experiments with 20 readers across ten domain-method settings on four QA benchmarks and one summarization benchmark show that compression gain decreases with reader baseline accuracy, significant in nine of ten cases (p < 0.05). Specific examples include generic summarization flipping 31% of pairwise model rankings on LongMemEval-S and a fixed HotpotQA compressor hiding 80% of the upgrade from Qwen 7B to GPT-4.1-mini. The authors propose two opposing forces—noise removal benefiting weak readers and detail loss harming strong readers—and support this with an external audit of nine prior papers. They also release the ragscale toolkit based on 177,000 row-level transitions to facilitate such audits.
Significance. If these findings hold, the work is significant for the RAG and compression literature because it challenges the common practice of evaluating compressors on a small number of readers, potentially leading to misleading assessments of model scaling. The large scale of the experiments (20 readers, multiple benchmarks and compressor families), the identification of the interaction effect, the external audit, and the provision of a reproducible toolkit (ragscale) with 177k transitions are strengths that could encourage more robust evaluation practices in future work.
major comments (1)
- [§4.3] §4.3 (or equivalent results section): the 80% upgrade-hiding figure for the Qwen 7B to GPT-4.1-mini transition under the fixed HotpotQA compressor must include the exact arithmetic definition (e.g., (raw_upgrade - compressed_upgrade) / raw_upgrade) and the per-reader accuracy numbers used, because this quantity is load-bearing for the central claim that compression collapses measured scaling.
minor comments (3)
- [§3.1] The description of the 20 readers should explicitly list their sources (e.g., which are open-source checkpoints, which are API models) and any exclusion criteria applied, to allow readers to assess whether the baseline range is representative.
- All accuracy plots (e.g., Figure 3 or equivalent) should report error bars or confidence intervals; the current text states statistical significance but does not show variability measures that would let readers judge the practical magnitude of the interaction.
- [§5] The external audit of nine prior papers would benefit from a table listing the exact compressor, reader(s), and benchmark(s) used in each audited work, rather than a summary paragraph only.
Simulated Author's Rebuttal
We thank the referee for the constructive comment and for recognizing the significance of the scaling-collapse findings. We address the single major comment below and will make the requested changes in the revision.
read point-by-point responses
-
Referee: [§4.3] §4.3 (or equivalent results section): the 80% upgrade-hiding figure for the Qwen 7B to GPT-4.1-mini transition under the fixed HotpotQA compressor must include the exact arithmetic definition (e.g., (raw_upgrade - compressed_upgrade) / raw_upgrade) and the per-reader accuracy numbers used, because this quantity is load-bearing for the central claim that compression collapses measured scaling.
Authors: We agree that the exact definition and underlying numbers should be reported for transparency and verifiability. In the revised §4.3 we will state the upgrade-hiding percentage explicitly as (raw_upgrade − compressed_upgrade) / raw_upgrade, where raw_upgrade is the absolute accuracy difference between the two readers on the uncompressed HotpotQA evidence and compressed_upgrade is the corresponding difference on the fixed-compressor evidence. We will also include the four per-reader accuracy values (Qwen-7B uncompressed, Qwen-7B compressed, GPT-4.1-mini uncompressed, GPT-4.1-mini compressed) either in the main text or in a short footnote/table so that readers can recompute the 80 % figure directly. revision: yes
Circularity Check
No significant circularity
full rationale
This paper is an empirical measurement study reporting observed patterns in compression gains, ranking flips, and upgrade hiding across 20 readers, ten domain-method settings, and multiple benchmarks. No equations, derivations, or self-citations reduce any reported result to quantities fitted from the same data by construction, nor do they invoke uniqueness theorems or ansatzes from prior author work. The central claims rest on direct experimental measurements, statistical tests (p < 0.05), and an external audit of nine prior papers, making the analysis self-contained against external benchmarks rather than internally circular.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions for reporting statistical significance at p < 0.05
Reference graph
Works this paper leans on
-
[1]
2025 , url=
Wu, Di and Wang, Hongwei and Yu, Wenhao and Zhang, Yuwei and Chang, Kai-Wei and Yu, Dong , booktitle=. 2025 , url=
2025
-
[2]
and Salakhutdinov, Ruslan and Manning, Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William W. and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle=. 2018 , doi=
2018
-
[3]
Evaluating Very Long-Term Conversational Memory of
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei , booktitle=. Evaluating Very Long-Term Conversational Memory of. 2024 , url=
2024
-
[4]
Convomem Benchmark: Why Your First 150 Conversations Don't Need
Pakhomov, Egor and Nijkamp, Erik and Xiong, Caiming , journal=. Convomem Benchmark: Why Your First 150 Conversations Don't Need. 2025 , url=
2025
-
[5]
2024 , url=
Xu, Fangyuan and Shi, Weijia and Choi, Eunsol , booktitle=. 2024 , url=
2024
-
[6]
2024 , url=
Jiang, Huiqiang and Wu, Qianhui and Luo, Xufang and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , booktitle=. 2024 , url=
2024
-
[7]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Pan, Zhuoshi and Wu, Qianhui and Jiang, Huiqiang and Xia, Menglin and Luo, Xufang and Zhang, Jue and Lin, Qingwei and R. Findings of the Association for Computational Linguistics: ACL 2024 , pages=. 2024 , url=
2024
-
[8]
2024 , doi=
Zhao, Xinping and Li, Dongfang and Zhong, Yan and Hu, Boren and Chen, Yibin and Hu, Baotian and Zhang, Min , booktitle=. 2024 , doi=
2024
-
[9]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
Familiarity-Aware Evidence Compression for Retrieval-Augmented Generation , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=. 2025 , doi=
2025
-
[10]
Findings of the Association for Computational Linguistics: ACL 2025 , year=
Louis, Maxime and D. Findings of the Association for Computational Linguistics: ACL 2025 , year=
2025
-
[11]
2024 , url=
Cheng, Xin and Wang, Xun and Zhang, Xingxing and Ge, Tao and Chen, Si-Qing and Wei, Furu and Zhang, Huishuai and Zhao, Dongyan , booktitle=. 2024 , url=
2024
-
[12]
2024 , doi=
Yoon, Chanwoong and Lee, Taewhoo and Hwang, Hyeon and Jeong, Minbyul and Kang, Jaewoo , booktitle=. 2024 , doi=
2024
-
[13]
2026 , url=
Gu, Jia-Chen and Zhang, Junyi and Wu, Di and Li, Yuankai and Chang, Kai-Wei and Peng, Nanyun , booktitle=. 2026 , url=
2026
-
[14]
Proceedings of the ACM Web Conference 2026 , year=
Less is More: Compact Clue Selection for Efficient Retrieval-Augmented Generation Reasoning , author=. Proceedings of the ACM Web Conference 2026 , year=
2026
-
[15]
2025 , doi=
Jeong, Yeonseok and Kim, Jinsu and Lee, Dohyeon and Hwang, Seung-won , booktitle=. 2025 , doi=
2025
-
[16]
Enhancing
Guo, Shuyu and Zhang, Shuo and Ren, Zhaochun , booktitle=. Enhancing. 2025 , doi=
2025
-
[17]
2025 , doi=
Luo, Lvzhou and Cao, Yixuan and Luo, Ping , booktitle=. 2025 , doi=
2025
-
[18]
2025 , url=
Jin, Yiqiao and Sharma, Kartik and Rakesh, Vineeth and Dou, Yingtong and Pan, Menghai and Das, Mahashweta and Kumar, Srijan , journal=. 2025 , url=
2025
-
[19]
2025 , url=
Cui, Ziqiang and Weng, Yunpeng and Tang, Xing and Liu, Peiyang and Li, Shiwei and He, Bowei and Chen, Jiamin and Zhang, Yansen and He, Xiuqiang and Ma, Chen , journal=. 2025 , url=
2025
-
[20]
, booktitle=
Hwang, Taeho and Cho, Sukmin and Jeong, Soyeong and Song, Hoyun and Han, SeungYoon and Park, Jong C. , booktitle=. 2025 , url=
2025
-
[21]
2026 , url=
Zhang, Qianchi and Zhang, Hainan and Pang, Liang and Zheng, Hongwei and Zheng, Zhiming , booktitle=. 2026 , url=
2026
-
[22]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
2024
-
[23]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , pages=
Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , pages=. 2024 , url=
2024
-
[24]
Ning, Jingjie and Kong, Yibo and Long, Yunfan and Callan, Jamie , booktitle=. Less. 2026 , url=
2026
-
[25]
When Less is More: The
Guo, Ruishan and Liu, Yibing and Ma, Guoxin and Wang, Yan and Zhang, Yueyang and Xia, Long and Chen, Kecheng and Sun, Zhiyuan and Shi, Daiting , journal=. When Less is More: The. 2026 , url=
2026
-
[26]
2025 , url=
Zhang, Yong and Li, Heng and Huang, Yanwen and Cheng, Ning and Guo, Yang and Zhu, Yun and Wang, Yanmeng and Wang, Shaojun and Xiao, Jing , journal=. 2025 , url=
2025
-
[27]
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , booktitle=. Self-. 2024 , url=
2024
-
[28]
, booktitle=
Jeong, Soyeong and Baek, Jinheon and Cho, Sukmin and Hwang, Sung Ju and Park, Jong C. , booktitle=. Adaptive-. 2024 , url=
2024
-
[29]
2024 , url=
Yu, Yue and Ping, Wei and Liu, Zihan and Wang, Boxin and You, Jiaxuan and Zhang, Chao and Shoeybi, Mohammad and Catanzaro, Bryan , booktitle=. 2024 , url=
2024
-
[30]
Vicky and Qiu, Lili and Gao, Jianfeng , booktitle=
Pan, Zhuoshi and Wu, Qianhui and Jiang, Huiqiang and Luo, Xufang and Cheng, Hao and Li, Dongsheng and Yang, Yuqing and Lin, Chin-Yew and Zhao, H. Vicky and Qiu, Lili and Gao, Jianfeng , booktitle=. 2025 , url=
2025
-
[31]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year=
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year=
-
[32]
arXiv preprint arXiv:2311.08377 , year=
Learning to Filter Context for Retrieval-Augmented Generation , author=. arXiv preprint arXiv:2311.08377 , year=
-
[33]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Compressing Context to Enhance Inference Efficiency of Large Language Models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=. 2023 , url=
2023
-
[34]
2022 , url=
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish , journal=. 2022 , url=
2022
-
[35]
Transactions of the Association for Computational Linguistics , volume=
Natural Questions: A Benchmark for Question Answering Research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , url=
2019
-
[36]
2021 , doi=
Zhong, Ming and Yin, Da and Yu, Tao and Zaidi, Ahmad and Mutuma, Mutethia and Jha, Rahul and Awadallah, Ahmed Hassan and Celikyilmaz, Asli and Liu, Yang and Qiu, Xipeng and Radev, Dragomir , booktitle=. 2021 , doi=
2021
-
[37]
Transactions of the Association for Computational Linguistics , volume=
Lost in the Middle: How Language Models Use Long Contexts , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , doi=
2024
-
[38]
arXiv preprint arXiv:2508.19357 , year=
Context-Adaptive Synthesis and Compression for Enhanced Retrieval-Augmented Generation in Complex Domains , author=. arXiv preprint arXiv:2508.19357 , year=
-
[39]
Do, Thao and Tran, Dinh Phu and Vo, An and Kim, Seon Kwon and Kim, Daeyoung , journal=
-
[40]
arXiv preprint arXiv:2505.15774 , year=
Beyond Hard and Soft: Hybrid Context Compression for Balancing Local and Global Information Retention , author=. arXiv preprint arXiv:2505.15774 , year=
-
[41]
arXiv preprint arXiv:2504.07109 , year=
Louis, Maxime and Formal, Thibault and Dejean, Herv. arXiv preprint arXiv:2504.07109 , year=
-
[42]
Findings of the Association for Computational Linguistics: EMNLP 2024 , year=
Refiner: Restructure Retrieval Content Efficiently to Advance Question-Answering Capabilities , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , year=
2024
-
[43]
Proceedings of the International Conference on Learning Representations , year=
Provence: Efficient and Robust Context Pruning for Retrieval-Augmented Generation , author=. Proceedings of the International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.