Provably Efficient Policy-Reward Co-Pretraining for Adversarial Imitation Learning
Pith reviewed 2026-06-26 12:31 UTC · model grok-4.3
The pith
CoPT-AIL proves that co-pretraining policy and reward via behavioral cloning tightens the imitation gap bound in adversarial imitation learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
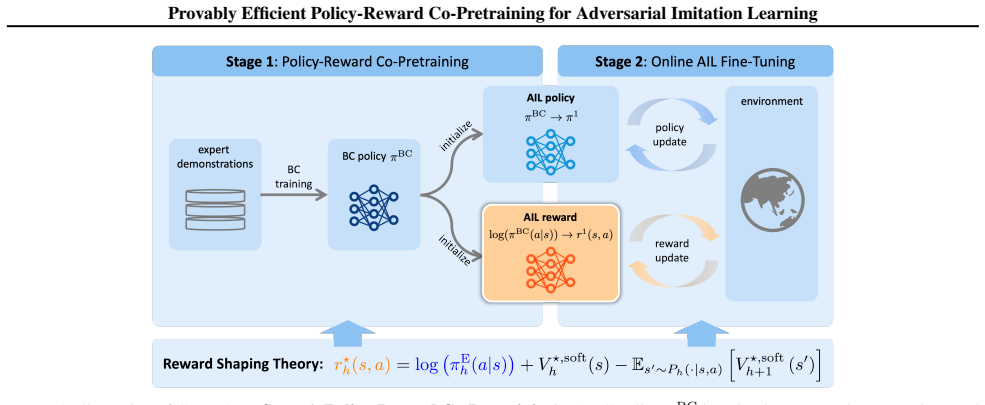
Through reward shaping analysis, the paper establishes a connection between expert policies and shaping rewards that allows a single BC procedure to pretrain both policy and reward. CoPT-AIL then achieves an improved imitation gap bound over standard AIL, providing the first theoretical guarantee for pretraining benefits in AIL.
What carries the argument
The reward shaping analysis that reveals a fundamental connection between expert policies and shaping rewards, enabling the single BC co-pretraining procedure.
Load-bearing premise
Reward error is the dominant source of suboptimality after policy pretraining alone, and expert policies connect directly to shaping rewards in a way that justifies joint pretraining via one BC step.
What would settle it
An experiment or calculation showing that the imitation gap bound under CoPT-AIL is no tighter than under standard AIL, or that reward error does not remain the leading source of suboptimality after policy pretraining.
Figures
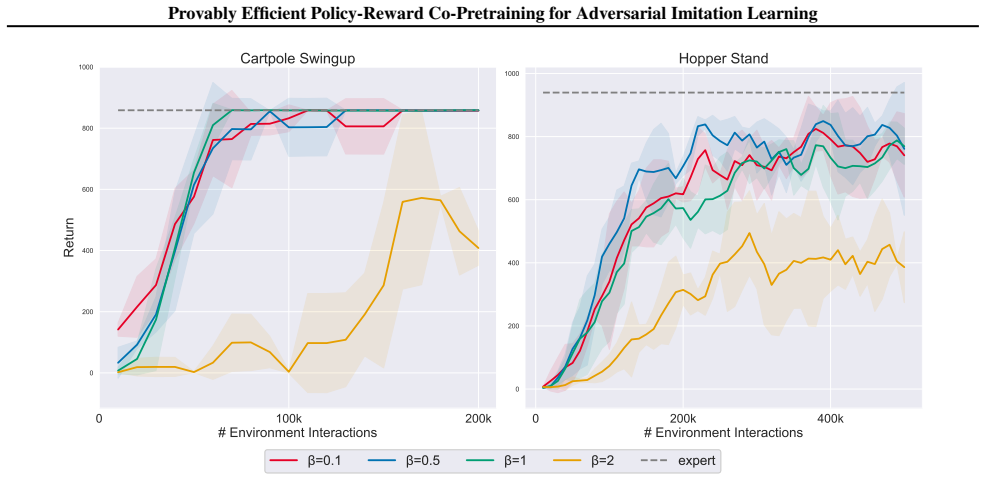
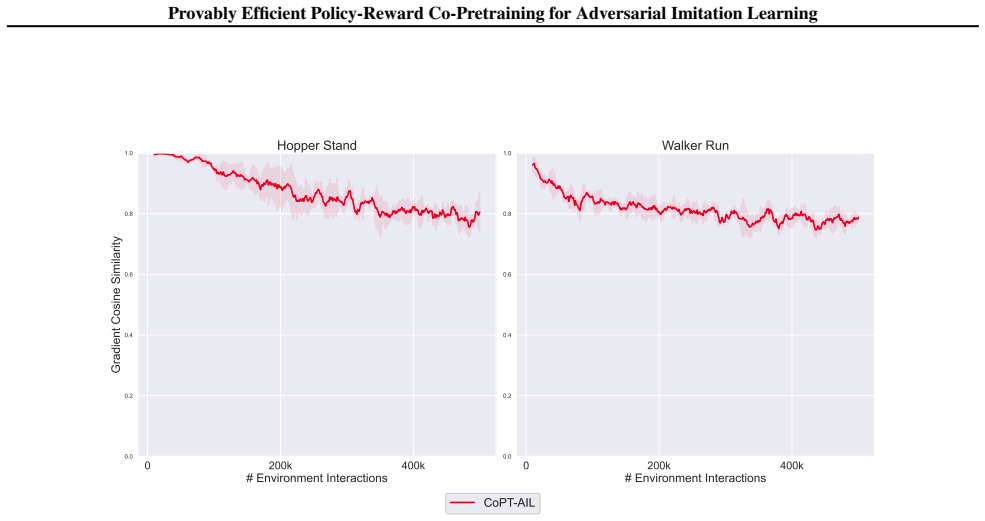
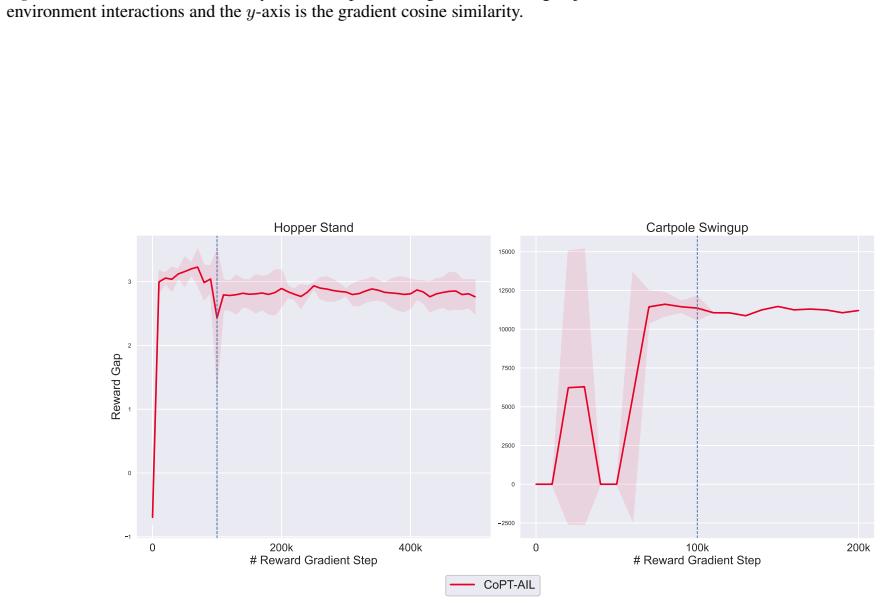
read the original abstract
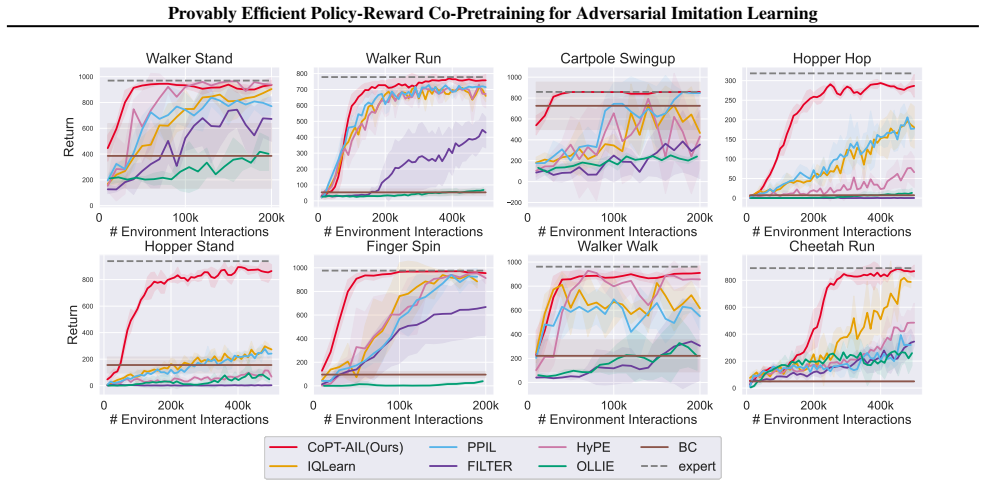
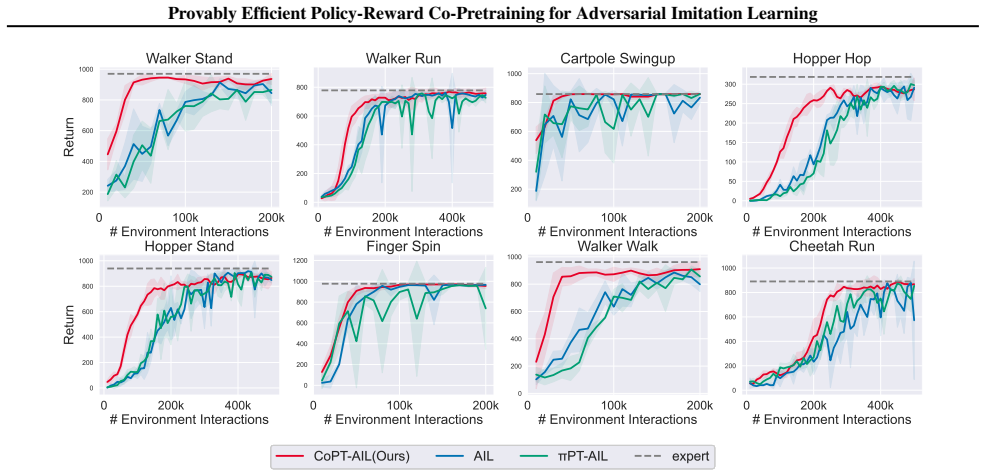
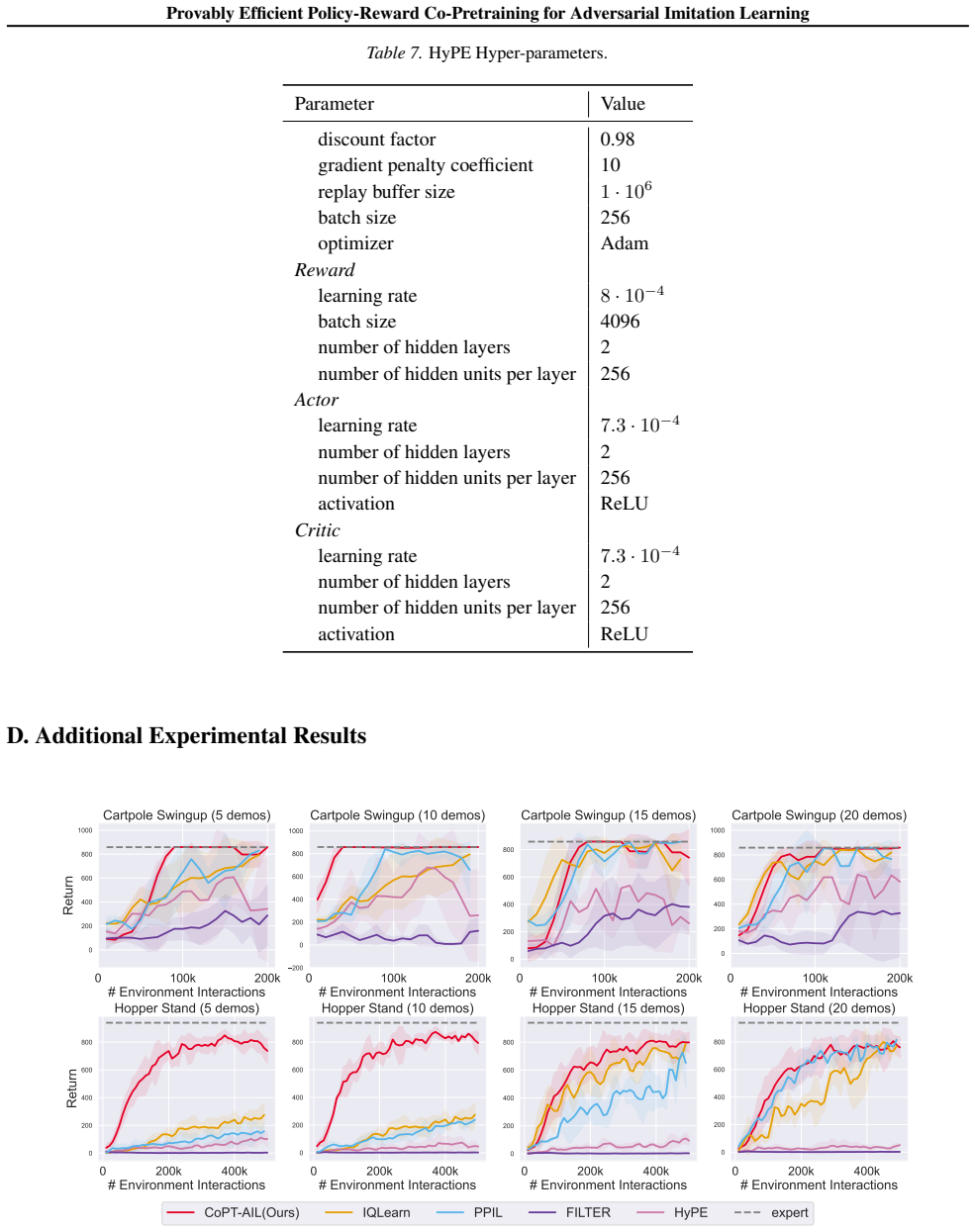
Adversarial imitation learning (AIL) achieves high-quality imitation compared to behavioral cloning (BC), but demands substantial online environment interaction. Recent empirical work has explored initializing AIL algorithms with BC pretrained policies to address this limitation, yet a rigorous theoretical understanding of pretraining's role in AIL remains elusive. This paper provides a systematic theoretical analysis and introduces principled pretraining algorithms for accelerating AIL. We begin by analyzing AIL with policy pretraining alone, identifying reward error as the dominant source of suboptimality. This reveals a critical and previously overlooked gap: the absence of reward pretraining. Motivated by this finding, we develop a principled policy-reward co-pretraining approach grounded in a reward shaping analysis. Our analysis uncovers a fundamental connection between expert policies and shaping rewards, which naturally gives rise to CoPT-AIL, an approach that jointly pretrains both policy and reward through a single BC procedure. We prove that CoPT-AIL achieves an improved imitation gap bound over standard AIL, establishing the first theoretical guarantee for the benefits of pretraining in AIL. Experimental results confirm CoPT-AIL's superior performance over existing AIL methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes AIL with policy pretraining alone and identifies reward error as the dominant suboptimality term via a decomposition. It then invokes a fundamental connection between expert policies and shaping rewards to motivate CoPT-AIL, a method that performs joint policy-reward pretraining via a single BC run. The central result is a proof that CoPT-AIL yields a strictly improved imitation-gap bound relative to standard AIL, claimed as the first theoretical guarantee for pretraining benefits in AIL; experiments are reported to support the claim.
Significance. If the improved bound holds under the stated conditions, the work supplies the first rigorous justification for why and how pretraining accelerates AIL, directly addressing the sample-efficiency bottleneck. The reduction of two pretraining objectives to a single BC procedure is a clean algorithmic contribution that could be adopted in practice.
major comments (3)
- [Suboptimality decomposition after policy pretraining] The suboptimality decomposition after policy pretraining (the section analyzing AIL with policy pretraining alone) asserts that reward error is the leading term, yet the manuscript provides no explicit quantitative comparison of the remaining terms (e.g., via concrete bounds or a numerical example) that would confirm dominance outside the abstract claim.
- [Reward shaping analysis and CoPT-AIL derivation] The reward-shaping analysis invokes a 'fundamental connection' between expert policies and shaping rewards to license the single-BC co-pretraining procedure. The manuscript does not state the precise conditions (deterministic expert, exact recovery of the potential function, etc.) under which this connection holds; without those restrictions the subsequent proof that CoPT-AIL tightens the imitation gap does not go through in the claimed generality.
- [Main imitation-gap theorem] The improved imitation-gap theorem (the main theoretical result) is stated relative to standard AIL, but the proof sketch does not explicitly track how the co-pretrained reward reduces the reward-error term that was identified as dominant; a direct comparison of the two bounds with the same constants would be required to establish the improvement.
minor comments (2)
- Notation for the shaping reward and the BC objective should be unified across the analysis and algorithm sections to avoid ambiguity when the same symbols appear in both the decomposition and the CoPT-AIL definition.
- [Experiments] The experimental section should report the precise pretraining data size and the number of environment steps used by the baseline AIL methods so that the claimed sample-efficiency gain can be directly verified.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Suboptimality decomposition after policy pretraining] The suboptimality decomposition after policy pretraining (the section analyzing AIL with policy pretraining alone) asserts that reward error is the leading term, yet the manuscript provides no explicit quantitative comparison of the remaining terms (e.g., via concrete bounds or a numerical example) that would confirm dominance outside the abstract claim.
Authors: We agree that an explicit quantitative comparison would strengthen the presentation. The revised manuscript will add a numerical example (with concrete parameter values) demonstrating the relative scale of the reward-error term versus the remaining terms in the decomposition. revision: yes
-
Referee: [Reward shaping analysis and CoPT-AIL derivation] The reward-shaping analysis invokes a 'fundamental connection' between expert policies and shaping rewards to license the single-BC co-pretraining procedure. The manuscript does not state the precise conditions (deterministic expert, exact recovery of the potential function, etc.) under which this connection holds; without those restrictions the subsequent proof that CoPT-AIL tightens the imitation gap does not go through in the claimed generality.
Authors: The derivation relies on a deterministic expert and exact recovery of the potential function from the expert policy via behavioral cloning. The revised manuscript will explicitly list these assumptions at the start of the reward-shaping section and discuss the resulting scope of the guarantee. revision: yes
-
Referee: [Main imitation-gap theorem] The improved imitation-gap theorem (the main theoretical result) is stated relative to standard AIL, but the proof sketch does not explicitly track how the co-pretrained reward reduces the reward-error term that was identified as dominant; a direct comparison of the two bounds with the same constants would be required to establish the improvement.
Authors: The existing proof shows the reduction occurs through the co-pretrained reward, but we concur that a direct side-by-side comparison using identical constants would improve clarity. The revised version will insert an explicit corollary that juxtaposes the two imitation-gap bounds term by term. revision: yes
Circularity Check
No circularity: theoretical proof presented as independent of pretraining inputs
full rationale
The abstract and provided excerpts describe a derivation that begins with an analysis of AIL with policy pretraining, identifies reward error as dominant, uncovers a fundamental connection via reward shaping, and then proves an improved imitation gap bound for CoPT-AIL. No equations, fitted parameters, or self-citations are quoted that reduce the central claim or the 'fundamental connection' to the inputs by construction. The proof is framed as establishing a new theoretical guarantee rather than renaming or fitting existing quantities. The derivation is therefore self-contained against external benchmarks with no load-bearing reductions visible.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ng , booktitle =
Pieter Abbeel and Andrew Y. Ng , booktitle =. Exploration and apprenticeship learning in reinforcement learning , year =
-
[2]
Model-Based Relative Entropy Stochastic Search , year =
Abbas Abdolmaleki and Rudolf Lioutikov and Jan Peters and Nuno Lau and Lu. Model-Based Relative Entropy Stochastic Search , year =. Advances in Neural Information Processing Systems 28 , pages =
-
[3]
Stochastic Variance Reduction for Policy Gradient Estimation , volume =
Tianbing Xu and Qiang Liu and Jian Peng , journal =. Stochastic Variance Reduction for Policy Gradient Estimation , volume =
-
[4]
Foster and Daniel J
Alekh Agarwal and Dean P. Foster and Daniel J. Hsu and Sham M. Kakade and Alexander Rakhlin , journal =. Stochastic Convex Optimization with Bandit Feedback , volume =
-
[5]
Optimal Algorithms for Online Convex Optimization with Multi-Point Bandit Feedback , year =
Alekh Agarwal and Ofer Dekel and Lin Xiao , booktitle =. Optimal Algorithms for Online Convex Optimization with Multi-Point Bandit Feedback , year =
-
[6]
Kakade and Jason D
Alekh Agarwal and Sham M. Kakade and Jason D. Lee and Gaurav Mahajan , booktitle =. Optimality and Approximation with Policy Gradient Methods in Markov Decision Processes , year =
-
[7]
, author=
Competing in the Dark: An Efficient Algorithm for Bandit Linear Optimization. , author=. Proceedings of the 21st Annual Conference on Learning Theory , pages=
-
[8]
Analysis of Thompson Sampling for the Multi-armed Bandit Problem , year =
Shipra Agrawal and Navin Goyal , booktitle =. Analysis of Thompson Sampling for the Multi-armed Bandit Problem , year =
-
[9]
Near-Optimal Regret Bounds for Thompson Sampling , volume =
Shipra Agrawal and Navin Goyal , journal =. Near-Optimal Regret Bounds for Thompson Sampling , volume =
-
[10]
Optimistic posterior sampling for reinforcement learning: worst-case regret bounds , year =
Shipra Agrawal and Randy Jia , booktitle =. Optimistic posterior sampling for reinforcement learning: worst-case regret bounds , year =
-
[11]
Advances in Neural Information Processing Systems 34 , pages=
Bellman eluder dimension: New rich classes of rl problems, and sample-efficient algorithms , author=. Advances in Neural Information Processing Systems 34 , pages=
-
[12]
Improved Worst-Case Regret Bounds for Randomized Least-Squares Value Iteration , year =
Priyank Agrawal and Jinglin Chen and Nan Jiang , booktitle =. Improved Worst-Case Regret Bounds for Randomized Least-Squares Value Iteration , year =
-
[13]
Simulation optimization: a review of algorithms and applications , volume =
Amaran, Satyajith and Sahinidis, Nikolaos V and Sharda, Bikram and Bury, Scott J , journal =. Simulation optimization: a review of algorithms and applications , volume =
-
[14]
First-Order Methods in Optimization , year =
Beck, Amir , publisher =. First-Order Methods in Optimization , year =
-
[15]
Hindsight Experience Replay , year =
Marcin Andrychowicz and Dwight Crow and Alex Ray and Jonas Schneider and Rachel Fong and Peter Welinder and Bob McGrew and Josh Tobin and Pieter Abbeel and Wojciech Zaremba , booktitle =. Hindsight Experience Replay , year =
-
[16]
Implicit Regularization in Deep Matrix Factorization , year =
Sanjeev Arora and Nadav Cohen and Wei Hu and Yuping Luo , booktitle =. Implicit Regularization in Deep Matrix Factorization , year =
-
[17]
Arag´on Artacho and Michel H
Francisco J. Arag´on Artacho and Michel H. Geoffroy , journal =. Characterization of Metric Regularity of Subdifferentials , volume =
-
[18]
Derivative-free and blackbox optimization , year =
Audet, Charles and Hare, Warren , publisher =. Derivative-free and blackbox optimization , year =
-
[19]
Derivative-
Audet, Charles and Hare, Warren , publisher =. Derivative-
-
[20]
Finite-time Analysis of the Multiarmed Bandit Problem , volume =
Peter Auer and Nicol. Finite-time Analysis of the Multiarmed Bandit Problem , volume =. Machine Learning , number =
-
[21]
Gambling in a rigged casino: The adversarial multi-armed bandit problem , volume =
Peter Auer and Nicol. Gambling in a rigged casino: The adversarial multi-armed bandit problem , volume =. Electronic Colloquium on Computational Complexity , number =
-
[22]
A restart
Anne Auger and Nikolaus Hansen , booktitle =. A restart
-
[23]
Model-Based Reinforcement Learning with Value-Targeted Regression , year =
Alex Ayoub and Zeyu Jia and Csaba Szepesv. Model-Based Reinforcement Learning with Value-Targeted Regression , year =. Proceedings of the 37th International Conference on Machine Learning , pages =
-
[24]
Minimax Regret Bounds for Reinforcement Learning , year =
Mohammad Gheshlaghi Azar and Ian Osband and R. Minimax Regret Bounds for Reinforcement Learning , year =. Proceedings of the 34th International Conference on Machine Learning , pages =
-
[25]
Mohammad Gheshlaghi Azar and R. Minimax. Machine Learning , number =
-
[26]
Efficient exploration through bayesian deep q-networks , year =
Azizzadenesheli, Kamyar and Brunskill, Emma and Anandkumar, Animashree , booktitle =. Efficient exploration through bayesian deep q-networks , year =
-
[27]
CoRR , title =
Reza Babanezhad and Mohamed Osama Ahmed and Alim Virani and Mark Schmidt and Jakub Konecn. CoRR , title =
-
[28]
Principled Exploration via Optimistic Bootstrapping and Backward Induction , year =
Chenjia Bai and Lingxiao Wang and Lei Han and Jianye Hao and Animesh Garg and Peng Liu and Zhaoran Wang , booktitle =. Principled Exploration via Optimistic Bootstrapping and Backward Induction , year =
-
[29]
Zeroth-order (Non)-Convex Stochastic Optimization via Conditional Gradient and Gradient Updates , year =
Krishnakumar Balasubramanian and Saeed Ghadimi , booktitle =. Zeroth-order (Non)-Convex Stochastic Optimization via Conditional Gradient and Gradient Updates , year =
-
[30]
Bandit Algorithms , year =
Tor Lattimore and Csaba Szepesvári , publisher =. Bandit Algorithms , year =
-
[31]
Bartlett and Varsha Dani and Thomas P
Peter L. Bartlett and Varsha Dani and Thomas P. Hayes and Sham M. Kakade and Alexander Rakhlin and Ambuj Tewari , booktitle =. High-Probability Regret Bounds for Bandit Online Linear Optimization , year =
-
[32]
Mirror descent and nonlinear projected subgradient methods for convex optimization , volume =
Amir Beck and Marc Teboulle , journal =. Mirror descent and nonlinear projected subgradient methods for convex optimization , volume =
-
[33]
Bellemare and Yavar Naddaf and Joel Veness and Michael Bowling , journal =
Marc G. Bellemare and Yavar Naddaf and Joel Veness and Michael Bowling , journal =. The Arcade Learning Environment: An Evaluation Platform for General Agents , volume =
-
[34]
Bellemare and Sriram Srinivasan and Georg Ostrovski and Tom Schaul and David Saxton and R
Marc G. Bellemare and Sriram Srinivasan and Georg Ostrovski and Tom Schaul and David Saxton and R. Unifying Count-Based Exploration and Intrinsic Motivation , year =. Advances in Neural Information Processing Systems 29 , pages =
-
[35]
Bellemare and Will Dabney and R
Marc G. Bellemare and Will Dabney and R. A Distributional Perspective on Reinforcement Learning , year =. Proceedings of the 34th International Conference on Machine Learning , pages =
-
[36]
Mixed equilibria and dynamical systems arising from fictitious play in perturbed games , volume =
Bena. Mixed equilibria and dynamical systems arising from fictitious play in perturbed games , volume =. Games and Economic Behavior , number =
-
[37]
A theoretical and empirical comparison of gradient approximations in derivative-free optimization , volume =
Berahas, Albert S and Cao, Liyuan and Choromanski, Krzysztof and Scheinberg, Katya , journal =. A theoretical and empirical comparison of gradient approximations in derivative-free optimization , volume =
-
[38]
Bertsekas , publisher =
Dimitri P. Bertsekas , publisher =. Convex
-
[39]
Bertsekas , journal =
Dimitri P. Bertsekas , journal =. Incremental Gradient, Subgradient, and Proximal Methods for Convex Optimization:
-
[40]
Bertsekas , publisher =
Dimitri P. Bertsekas , publisher =. Nonlinear Programming , year =
-
[41]
What Doubling Tricks Can and Can't Do for Multi-Armed Bandits , volume =
Lilian Besson and Emilie Kaufmann , journal =. What Doubling Tricks Can and Can't Do for Multi-Armed Bandits , volume =
-
[42]
On the Linear Convergence of Policy Gradient Methods for Finite MDPs , year =
Jalaj Bhandari and Daniel Russo , booktitle =. On the Linear Convergence of Policy Gradient Methods for Finite MDPs , year =
-
[43]
Convex Analysis and Nonlinear Optimization: Theory and Examples , year =
Borwein, Jonathan and Lewis, Adrian S , publisher =. Convex Analysis and Nonlinear Optimization: Theory and Examples , year =
-
[44]
Optimization Methods for Large-Scale Machine Learning , volume =
L. Optimization Methods for Large-Scale Machine Learning , volume =
-
[45]
Convex optimization , year =
Boyd, Stephen and Boyd, Stephen P and Vandenberghe, Lieven , publisher =. Convex optimization , year =
-
[46]
Brafman and Moshe Tennenholtz , journal =
Ronen I. Brafman and Moshe Tennenholtz , journal =
-
[47]
Openai gym , volume =
Brockman, Greg and Cheung, Vicki and Pettersson, Ludwig and Schneider, Jonas and Schulman, John and Tang, Jie and Zaremba, Wojciech , journal =. Openai gym , volume =
-
[48]
Convex Optimization: Algorithms and Complexity , volume =
S. Convex Optimization: Algorithms and Complexity , volume =. Foundations and Trends in Machine Learning , number =
-
[49]
Storkey and Trevor Darrell and Alexei A
Yuri Burda and Harrison Edwards and Deepak Pathak and Amos J. Storkey and Trevor Darrell and Alexei A. Efros , booktitle =. Large-Scale Study of Curiosity-Driven Learning , year =
-
[50]
Storkey and Oleg Klimov , booktitle =
Yuri Burda and Harrison Edwards and Amos J. Storkey and Oleg Klimov , booktitle =. Exploration by random network distillation , year =
-
[51]
Weak sharp minima in mathematical programming , volume =
Burke, James V and Ferris, Michael C , journal =. Weak sharp minima in mathematical programming , volume =
-
[52]
On the Global Convergence of Imitation Learning:
Qi Cai and Mingyi Hong and Yongxin Chen and Zhaoran Wang , journal =. On the Global Convergence of Imitation Learning:
-
[53]
Provably Efficient Exploration in Policy Optimization , year =
Qi Cai and Zhuoran Yang and Chi Jin and Zhaoran Wang , booktitle =. Provably Efficient Exploration in Policy Optimization , year =
-
[54]
Emmanuel J. Cand. Robust principal component analysis? , volume =. Journal of the
-
[55]
E. J. Phase Retrieval via Wirtinger Flow: Theory and Algorithms , volume =
-
[56]
Prediction, Learning, and Games , year =
Cesa-Bianchi, Nicolo and Lugosi, G. Prediction, Learning, and Games , year =
-
[57]
Parrilo and Alan S
Venkat Chandrasekaran and Sujay Sanghavi and Pablo A. Parrilo and Alan S. Willsky , journal =. Rank-Sparsity Incoherence for Matrix Decomposition , volume =
-
[58]
Learning to Search Better than Your Teacher , year =
Kai. Learning to Search Better than Your Teacher , year =. Proceedings of the 32nd International Conference on Machine Learning , pages =
-
[59]
Principled Weight Initialization for Hypernetworks , year =
Oscar Chang and Lampros Flokas and Hod Lipson , booktitle =. Principled Weight Initialization for Hypernetworks , year =
-
[60]
An Empirical Evaluation of Thompson Sampling , year =
Olivier Chapelle and Lihong Li , booktitle =. An Empirical Evaluation of Thompson Sampling , year =
-
[61]
Low-rank matrix recovery with composite optimization: good conditioning and rapid convergence , year =
Charisopoulos, Vasileios and Chen, Yudong and Davis, Damek and D. Low-rank matrix recovery with composite optimization: good conditioning and rapid convergence , year =. Foundations of Computational Mathematics , pages =
-
[62]
Goldsmith , journal =
Yuxin Chen and Yuejie Chi and Andrea J. Goldsmith , journal =. Exact and Stable Covariance Estimation From Quadratic Sampling via Convex Programming , volume =
-
[63]
Generative Adversarial User Model for Reinforcement Learning Based Recommendation System , year =
Xinshi Chen and Shuang Li and Hui Li and Shaohua Jiang and Yuan Qi and Le Song , booktitle =. Generative Adversarial User Model for Reinforcement Learning Based Recommendation System , year =
-
[64]
An Accelerated
Yuwen Chen and Antonio Orvieto and Aur. An Accelerated. Proceedings of the 37th International Conference on Machine Learning , pages =
-
[65]
On Computation and Generalization of Generative Adversarial Imitation Learning , year =
Yizhou Wang and Tianyi Liu and Zhuoran Yang and Xingguo Li and Zhaoran Wang and Tuo Zhao , booktitle =. On Computation and Generalization of Generative Adversarial Imitation Learning , year =
-
[66]
Policy Improvement via Imitation of Multiple Oracles , year =
Cheng, Ching-An and Kolobov, Andrey and Agarwal, Alekh , journal =. Policy Improvement via Imitation of Multiple Oracles , year =
-
[67]
Reward-Free Exploration for Reinforcement Learning , year =
Chi Jin and Akshay Krishnamurthy and Max Simchowitz and Tiancheng Yu , booktitle =. Reward-Free Exploration for Reinforcement Learning , year =
-
[68]
Conn and Katya Scheinberg and Lu
Andrew R. Conn and Katya Scheinberg and Lu. Introduction to Derivative-Free Optimization , year =
-
[69]
Theoretical statistics , year =
Cox, David Roxbee and Hinkley, David Victor , publisher =. Theoretical statistics , year =
-
[70]
Processing Networks: Fluid Models and Stability , year =
Dai, JG and Harrison, J Michael , publisher =. Processing Networks: Fluid Models and Stability , year =
-
[71]
Unifying
Christoph Dann and Tor Lattimore and Emma Brunskill , booktitle =. Unifying
-
[72]
Search-based structured prediction , volume =
Daum. Search-based structured prediction , volume =. Machine Learning , number =
-
[73]
MacPhee and Courtney Paquette , journal =
Damek Davis and Dmitriy Drusvyatskiy and Kellie J. MacPhee and Courtney Paquette , journal =. Subgradient Methods for Sharp Weakly Convex Functions , volume =
-
[74]
Stochastic algorithms with geometric step decay converge linearly on sharp functions , volume =
Damek Davis and Dmitriy Drusvyatskiy and Vasileios Charisopoulos , journal =. Stochastic algorithms with geometric step decay converge linearly on sharp functions , volume =
-
[75]
Stochastic Model-Based Minimization of Weakly Convex Functions , volume =
Damek Davis and Dmitriy Drusvyatskiy , journal =. Stochastic Model-Based Minimization of Weakly Convex Functions , volume =
-
[76]
Generative Adversarial Imitation Learning with Neural Networks: Global Optimality and Convergence Rate , volume =
Yufeng Zhang and Qi Cai and Zhuoran Yang and Zhaoran Wang , journal =. Generative Adversarial Imitation Learning with Neural Networks: Global Optimality and Convergence Rate , volume =
-
[77]
Coordinated Exploration in Concurrent Reinforcement Learning , year =
Maria Dimakopoulou and Benjamin Van Roy , booktitle =. Coordinated Exploration in Concurrent Reinforcement Learning , year =
-
[78]
The proximal point method revisited , volume =
Drusvyatskiy, Dmitriy , journal =. The proximal point method revisited , volume =
-
[79]
John Quan and Georg Ostrovski , howpublished =
-
[80]
Lewis , journal =
Dmitriy Drusvyatskiy and Adrian S. Lewis , journal =. Error Bounds, Quadratic Growth, and Linear Convergence of Proximal Methods , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.