Learning at the Right Pace: Adaptive Data Scheduling Improves LLM Reinforcement Learning
Pith reviewed 2026-06-26 11:06 UTC · model grok-4.3
The pith
Adaptive Data Scheduling improves LLM reinforcement learning accuracy by replacing uniform sampling with semantic cluster adaptation and policy-boundary selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
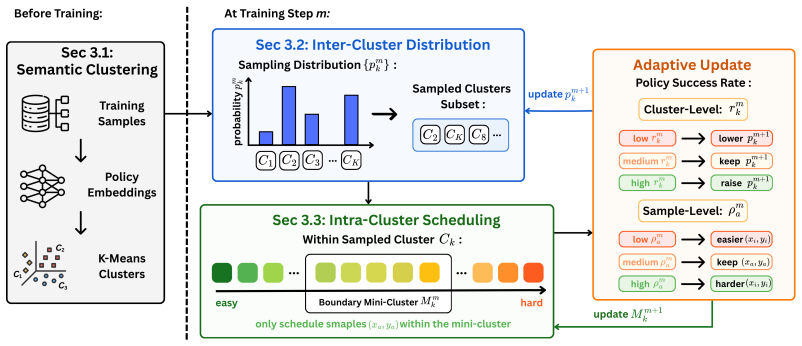
ADS is a dual-level data scheduling framework for RL post-training that organizes training samples according to semantic patterns, maintains an adaptive inter-cluster distribution to solidify training progress, and performs intra-cluster scheduling to continuously sample policy-boundary samples that provide informative relative advantages.
What carries the argument
Adaptive Data Scheduling (ADS), the dual-level framework with adaptive inter-cluster distribution over semantic clusters and intra-cluster policy-boundary sample selection.
If this is right
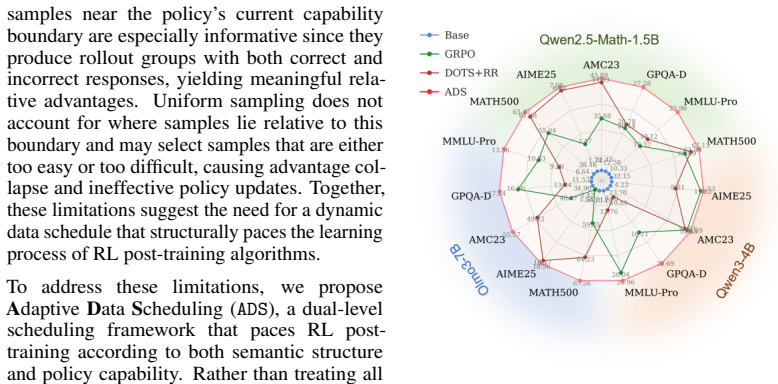
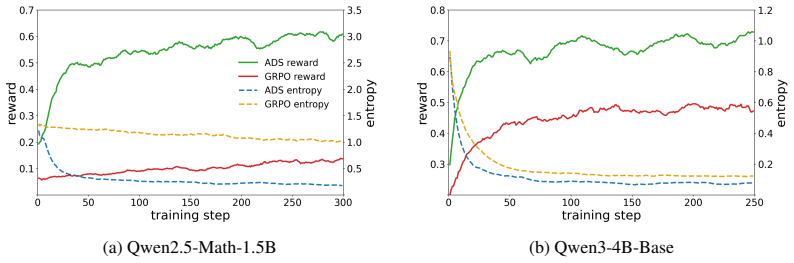
- ADS achieves a 5.2% average accuracy improvement over GRPO across three LLMs and seven benchmarks.
- ADS improves RL methods with different objective designs, indicating it functions as a general strategy.
- The framework replaces uniform sampling that ignores semantic structure and changing policy capability.
Where Pith is reading between the lines
- If boundary selection increases advantage estimate variance, the approach might extend to non-LLM RL tasks with noisy rewards.
- Layering ADS on top of existing difficulty-based curricula could produce additive gains by combining semantic and capability signals.
- Checking whether cluster assignments stay stable over long training runs would reveal how often reclustering is needed.
Load-bearing premise
Semantic clustering of the training data together with policy-boundary sample selection within clusters supplies informative relative advantages without introducing harmful selection bias or reducing data diversity.
What would settle it
An ablation where the adaptive inter-cluster distribution or the intra-cluster boundary selection is replaced by uniform sampling, checking whether the reported accuracy gain over GRPO disappears.
Figures


read the original abstract
Large Language Models (LLMs) achieve remarkable reasoning capabilities through reinforcement learning (RL) post-training. However, existing RL post-training commonly relies on uniform data sampling, which ignores the semantic structure of the training data and the changing capability of the training policy. To address these limitations, we propose Adaptive Data Scheduling (ADS), a dual-level data scheduling framework for pacing RL post-training that replaces uniform sampling with an adaptive distribution over semantic clusters and policy-boundary sample selection. At the cluster level, ADS organizes samples according to semantic patterns and maintains an adaptive inter-cluster distribution to solidify current training progress. At the sample level, ADS performs intra-cluster scheduling to continuously sample policy-boundary samples, which provides informative relative advantages. Experimental results across three LLMs and seven reasoning benchmarks demonstrate that ADS improves average accuracy by 5.2% over Group Relative Policy Optimization (GRPO). Notably, ADS consistently improves RL methods with different objective designs, highlighting its potential as a general data scheduling strategy for LLM RL post-training. The source code is available at: https://github.com/Richard-zrx/ADS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Adaptive Data Scheduling (ADS), a dual-level data scheduling framework for LLM RL post-training. At the cluster level, training samples are organized by semantic patterns with an adaptive inter-cluster distribution; at the sample level, intra-cluster selection targets policy-boundary samples to supply informative relative advantages. Experiments across three LLMs and seven reasoning benchmarks report a 5.2% average accuracy improvement over GRPO, with consistent gains when combined with other RL objectives. Source code is released.
Significance. If the reported gains hold under scrutiny, the work supplies a practical, general-purpose scheduling strategy that can be layered on existing RL objectives without altering their core formulations. The dual-level design directly targets the limitations of uniform sampling, and the public code release supports reproducibility and extension by the community.
major comments (2)
- [§4] §4 (Experiments): the central 5.2% average lift is reported without per-benchmark variance, number of random seeds, or statistical significance tests; this makes it difficult to assess whether the improvement is robust or could be explained by run-to-run variation.
- [§3.2] §3.2 (Intra-cluster scheduling): the definition of 'policy-boundary samples' relies on an unspecified threshold or ranking criterion within each cluster; without an explicit formula or pseudocode, it is unclear whether the selection rule is fixed before training or depends on quantities computed from the current policy in a way that could introduce selection bias.
minor comments (3)
- [Abstract, §1] The abstract and §1 state that ADS 'consistently improves RL methods with different objective designs,' but the main results focus on GRPO; a dedicated table or subsection comparing at least two additional objectives (e.g., PPO, DPO) would clarify the generality claim.
- [Figure 2] Figure 2 (or equivalent cluster visualization) would benefit from a caption that explicitly states the embedding model and clustering algorithm used to form the semantic clusters.
- [Abstract] The GitHub link is provided, but the manuscript does not include a brief description of the released artifacts (e.g., which scripts reproduce the main table).
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. We address each major comment below and will incorporate clarifications and additional details in the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the central 5.2% average lift is reported without per-benchmark variance, number of random seeds, or statistical significance tests; this makes it difficult to assess whether the improvement is robust or could be explained by run-to-run variation.
Authors: We agree that variance, seed counts, and significance testing would strengthen the presentation. In the revised manuscript we will report results from multiple random seeds, include per-benchmark standard deviations, and add statistical significance tests (e.g., paired t-tests against GRPO) for the 5.2% average improvement and per-benchmark gains. revision: yes
-
Referee: [§3.2] §3.2 (Intra-cluster scheduling): the definition of 'policy-boundary samples' relies on an unspecified threshold or ranking criterion within each cluster; without an explicit formula or pseudocode, it is unclear whether the selection rule is fixed before training or depends on quantities computed from the current policy in a way that could introduce selection bias.
Authors: The intra-cluster selection ranks samples by their advantage magnitude under the current policy, preferentially choosing those whose advantages lie closest to zero (the policy decision boundary). This ranking is recomputed each step from the latest policy estimates. We will insert an explicit formula together with pseudocode in the revised Section 3.2 to make the dynamic, policy-dependent criterion fully transparent. revision: yes
Circularity Check
No significant circularity; empirical method with external validation
full rationale
The paper introduces Adaptive Data Scheduling (ADS) as an empirical dual-level scheduling framework for LLM RL post-training, replacing uniform sampling with semantic clustering and policy-boundary selection. Gains are reported via direct comparison to external baselines (GRPO and other RL objectives) across three models and seven benchmarks, with code released. No equations, fitted parameters, or self-citations are used to derive the core claims; the central result (5.2% average accuracy lift) is measured against independent implementations and is externally falsifiable. The derivation chain is self-contained as a practical scheduling heuristic without reduction to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learn- ing from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learn- ing from self-generated mistakes. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openre...
2024
-
[3]
Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee F. Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng, Shane Arora,...
-
[5]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645(8081):633–638, 2025
2025
-
[6]
Curriculum re- inforcement learning via constrained optimal transport
Pascal Klink, Haoyi Yang, Carlo D’Eramo, Jan Peters, and Joni Pajarinen. Curriculum re- inforcement learning via constrained optimal transport. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato, editors, International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, Proceedi...
2022
-
[7]
Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay V . Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quanti- tative reasoning problems with language models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A....
2022
-
[8]
Numinamath
Jia LI, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu. Numinamath. [https://huggingface.co/AI-MO/NuminaMath-1.5](https://github.com/ project-numina/aimo-progress-prize/blob/main/report/nu...
2024
-
[9]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum? id=v8L0pN6EOi. 10
2024
-
[10]
Understanding r1-zero-like training: A critical perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. CoRR, abs/2503.20783,
-
[12]
Demystifying opd: Length inflation and stabilization strategies for large language models
Feng Luo, Yu-Neng Chuang, Guanchu Wang, Zicheng Xu, Xiaotian Han, Tianyi Zhang, and Vladimir Braverman. Demystifying opd: Length inflation and stabilization strategies for large language models. arXiv preprint arXiv:2604.08527, 2026
Pith/arXiv arXiv 2026
-
[14]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference ...
2023
-
[16]
Proximal policy optimization algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. CoRR, abs/1707.06347, 2017. URL http://arxiv.org/ abs/1707.06347
Pith/arXiv arXiv 2017
-
[17]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient RLHF framework. In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys 2025, Rotterdam, The Netherlands, 30 March 2025 - 3 April 2025, pages 1279–1297. ACM, 2025. doi: 10.1145/368...
-
[18]
Xinyu Tang, Zhenduo Zhang, Yurou Liu, Wayne Xin Zhao, Zujie Wen, Zhiqiang Zhang, and Jun Zhou
Yifan Sun, Jingyan Shen, Yibin Wang, Tianyu Chen, Zhendong Wang, Mingyuan Zhou, and Huan Zhang. Improving data efficiency for LLM reinforcement fine-tuning through difficulty- targeted online data selection and rollout replay. CoRR, abs/2506.05316, 2025. doi: 10.48550/ ARXIV .2506.05316. URLhttps://doi.org/10.48550/arXiv.2506.05316
-
[20]
Independent skill transfer for deep reinforcement learning
Qiangxing Tian, Guanchu Wang, Jinxin Liu, Donglin Wang, and Yachen Kang. Independent skill transfer for deep reinforcement learning. In Christian Bessiere, editor, Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, pages 2901–2907. ijcai.org, 2020. doi: 10.24963/IJCAI.2020/401. URL https://doi.org/10. 24...
-
[21]
Mind in society: The development of higher psychological processes, vol- ume 86
Lev S Vygotsky. Mind in society: The development of higher psychological processes, vol- ume 86. Harvard university press, 1978
1978
-
[22]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela ...
2024
-
[29]
American invitational mathematics examination (aime) 2024, 2024
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024, 2024
2024
-
[30]
American invitational mathematics examination (aime) 2025, 2025
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2025, 2025
2025
-
[31]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization. CoRR, abs/2507.18071, 2025. doi: 10.48550/ARXIV .2507.18071. URL https: //doi.org/10.48550/arXiv.2507.18071. A Related Work RL for Post-Training.Reinforcement learning has be...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.