Customizing Video Portraits via Identity-ActionDecoupling
Pith reviewed 2026-06-26 10:53 UTC · model grok-4.3
The pith
Identity-Action Decoupling isolates irrelevant features in face embeddings to produce text-controlled video portraits with consistent identity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
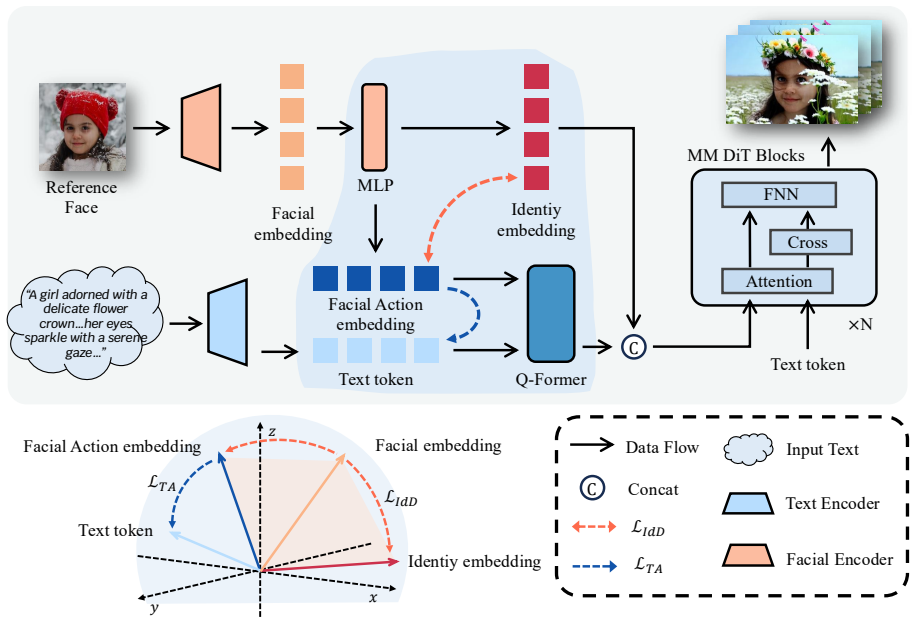
The central claim is that the Identity-Action Decoupling framework, together with the Identity Decoupling Loss and Text Alignment Loss, isolates ID-irrelevant information contained in the Facial embedding. This allows generated videos to maintain cross-temporal identity consistency and exhibit rich, controllable expressions and scene variations that closely match the input text, all without subject-specific fine-tuning.
What carries the argument
The Identity-Action Decoupling (IaD) framework that applies Identity Decoupling Loss and Text Alignment Loss to separate identity features from motion-related information.
If this is right
- Videos maintain the subject's identity consistently across all frames.
- Facial movements and expressions accurately follow the content of the text prompt.
- Rich variations in expressions and scenes are possible while identity stays fixed.
- No subject-specific fine-tuning is required for new reference images.
Where Pith is reading between the lines
- If the decoupling works, the same idea could be tested on other parts of the generation pipeline like background control.
- Neighbouring problems in audio-driven video or 3D portrait animation might benefit from similar separation of identity and motion.
- Users could experiment with the losses on open-source models to see if motion accuracy improves on their own prompts.
Load-bearing premise
The ID-irrelevant information in the facial embedding can be isolated and removed via the Identity Decoupling Loss and Text Alignment Loss so that the generated motion accurately follows the prompt.
What would settle it
Running the model on a reference image and a prompt describing a specific expression, then checking if the output video shows that expression or a different one unrelated to the prompt.
Figures


read the original abstract
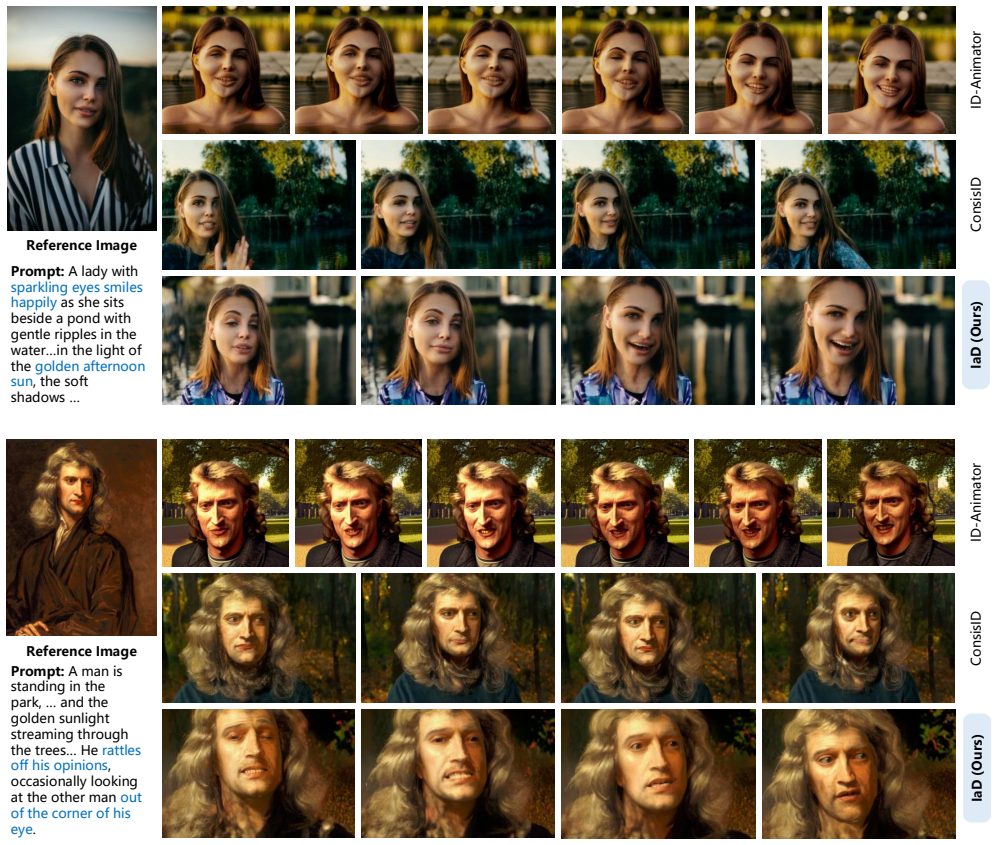
Identity-Preserving Text-to-Video Generation (IPT2V) seeks to synthesize a temporally coherent video from a reference image and a textual description, while simultaneously preserving the subject's identity and allowing fine-grained control over facial dynamics. Although recent methods such as ID-Animator and ConsisID inject identity features only at inference time, they ignored the ID-irrelevant information contained in Facial embedding, leading to monotonous or inaccurate facial movements that poorly follow the prompt. We introduce Identity-Action Decoupling (IaD) framework as well as two loss function Identity Decoupling Loss and Text Alignment Loss to solve this problem. Without any subject-specific fine-tuning, IaD yields videos that (1) maintain cross-temporal identity consistency and (2) exhibit rich, controllable expressions and scene variations that closely match the input text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Identity-Action Decoupling (IaD) framework for Identity-Preserving Text-to-Video Generation (IPT2V). It proposes Identity Decoupling Loss and Text Alignment Loss to remove ID-irrelevant information from facial embeddings, enabling videos that maintain cross-temporal identity consistency and exhibit rich, controllable expressions matching the input text, all without subject-specific fine-tuning.
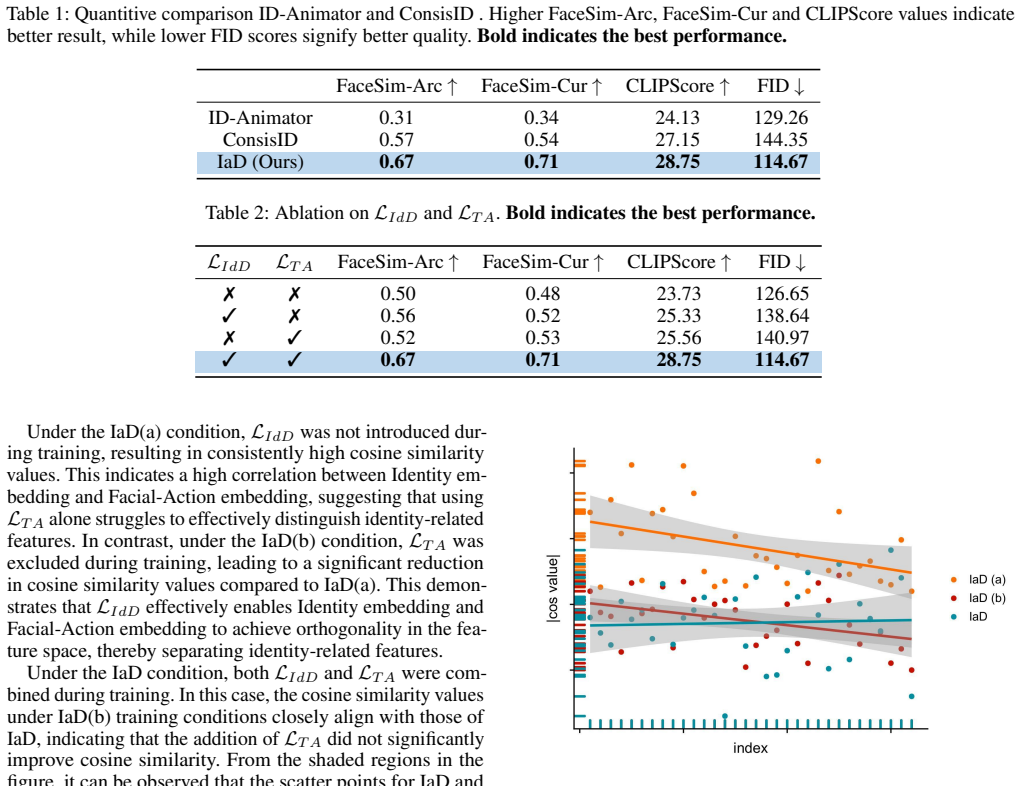
Significance. If the losses successfully isolate ID-irrelevant information as claimed, the framework could advance IPT2V by improving prompt adherence and controllability in a training-free manner. The manuscript provides no quantitative metrics, ablations, or implementation details to support this, so significance cannot be assessed from the given text.
major comments (2)
- [Abstract] Abstract: the claim that Identity Decoupling Loss and Text Alignment Loss isolate ID-irrelevant information from facial embeddings (enabling prompt-faithful motion) is presented without any loss formulations, derivations, or experimental evidence, making it impossible to verify whether the claimed performance is supported or reduces to quantities already fitted inside the paper.
- No equations, training details, ablation studies, or quantitative metrics are provided anywhere in the manuscript, so it is impossible to verify whether the data or derivations support the stated claims of cross-temporal identity consistency and rich expressions.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting the need for greater transparency in the presentation of our method. We address each point below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that Identity Decoupling Loss and Text Alignment Loss isolate ID-irrelevant information from facial embeddings (enabling prompt-faithful motion) is presented without any loss formulations, derivations, or experimental evidence, making it impossible to verify whether the claimed performance is supported or reduces to quantities already fitted inside the paper.
Authors: The body of the manuscript (Section 3.2) defines the Identity Decoupling Loss and Text Alignment Loss with explicit formulations and a short derivation showing separation of ID-irrelevant components. We will revise the abstract to include a one-sentence pointer to these equations and to the qualitative results in Section 4 that illustrate the effect on motion fidelity. revision: partial
-
Referee: [—] No equations, training details, ablation studies, or quantitative metrics are provided anywhere in the manuscript, so it is impossible to verify whether the data or derivations support the stated claims of cross-temporal identity consistency and rich expressions.
Authors: We agree that the current version lacks sufficient supporting material. In the revision we will insert the loss equations, add an implementation subsection with training details, include ablation studies on each loss term, and report quantitative metrics (identity cosine similarity over time and CLIP-based text-video alignment) to substantiate the claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces the IaD framework along with two explicitly new loss functions (Identity Decoupling Loss and Text Alignment Loss) to isolate ID-irrelevant information from facial embeddings. The central claims about cross-temporal identity consistency and prompt-faithful motion without subject-specific fine-tuning are presented as direct consequences of these design choices rather than any reduction to pre-fitted quantities, self-citations, or renamed empirical patterns. No equations or derivations in the provided abstract or claim structure equate outputs to inputs by construction, and external methods cited (ID-Animator, ConsisID) are distinct prior work. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Graphics (TOG) , volume=
Still-moving: Customized video generation without customized video data , author=. ACM Transactions on Graphics (TOG) , volume=. 2024 , publisher=
2024
-
[2]
arXiv preprint arXiv:2411.17440 , year=
Identity-Preserving Text-to-Video Generation by Frequency Decomposition , author=. arXiv preprint arXiv:2411.17440 , year=
-
[3]
arXiv preprint arXiv:2504.17816 , year=
Subject-driven Video Generation via Disentangled Identity and Motion , author=. arXiv preprint arXiv:2504.17816 , year=
-
[4]
arXiv preprint arXiv:2404.15275 , year=
Id-animator: Zero-shot identity-preserving human video generation , author=. arXiv preprint arXiv:2404.15275 , year=
-
[5]
arXiv preprint arXiv:2412.11638 , year=
IDProtector: An Adversarial Noise Encoder to Protect Against ID-Preserving Image Generation , author=. arXiv preprint arXiv:2412.11638 , year=
-
[6]
arXiv preprint arXiv:2411.17048 , year=
PersonalVideo: High ID-Fidelity Video Customization without Dynamic and Semantic Degradation , author=. arXiv preprint arXiv:2411.17048 , year=
-
[7]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
LIA: Latent Image Animator , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[8]
arXiv preprint arXiv:2410.20974 , year=
MovieCharacter: A Tuning-Free Framework for Controllable Character Video Synthesis , author=. arXiv preprint arXiv:2410.20974 , year=
-
[9]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[10]
arXiv preprint arXiv:2208.01618 , year=
An image is worth one word: Personalizing text-to-image generation using textual inversion , author=. arXiv preprint arXiv:2208.01618 , year=
-
[11]
arXiv preprint arXiv:2501.01790 , year=
Ingredients: Blending Custom Photos with Video Diffusion Transformers , author=. arXiv preprint arXiv:2501.01790 , year=
-
[12]
arXiv preprint arXiv:2503.10391 , year=
CINEMA: Coherent Multi-Subject Video Generation via MLLM-Based Guidance , author=. arXiv preprint arXiv:2503.10391 , year=
-
[13]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[14]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Towards open-set identity preserving face synthesis , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Identity preserving loss for learned image compression , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[16]
arXiv preprint arXiv:2401.07519 , year=
Instantid: Zero-shot identity-preserving generation in seconds , author=. arXiv preprint arXiv:2401.07519 , year=
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Portraitbooth: A versatile portrait model for fast identity-preserved personalization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[18]
arXiv preprint arXiv:2305.03374 , year=
Disenbooth: Identity-preserving disentangled tuning for subject-driven text-to-image generation , author=. arXiv preprint arXiv:2305.03374 , year=
-
[19]
arXiv preprint arXiv:2404.19427 , year=
Instantfamily: Masked attention for zero-shot multi-id image generation , author=. arXiv preprint arXiv:2404.19427 , year=
-
[20]
arXiv preprint arXiv:2308.06721 , year=
Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models , author=. arXiv preprint arXiv:2308.06721 , year=
-
[21]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[22]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Arcface: Additive angular margin loss for deep face recognition , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
DreamIdentity: enhanced editability for efficient face-identity preserved image generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[24]
European Conference on Computer Vision , pages=
Infinite-ID: Identity-preserved Personalization via ID-semantics Decoupling Paradigm , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Dreamvideo: Composing your dream videos with customized subject and motion , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[26]
European Conference on Computer Vision , pages=
Movideo: Motion-aware video generation with diffusion model , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[27]
Advances in Neural Information Processing Systems , volume=
Video diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[29]
arXiv preprint arXiv:2010.02502 , year=
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
Pith/arXiv arXiv 2010
-
[30]
Forty-first international conference on machine learning , year=
Scaling rectified flow transformers for high-resolution image synthesis , author=. Forty-first international conference on machine learning , year=
-
[31]
arXiv preprint arXiv:1807.03748 , year=
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
-
[32]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[33]
arXiv preprint arXiv:2408.06072 , year=
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer , author=. arXiv preprint arXiv:2408.06072 , year=
-
[34]
arXiv preprint arXiv:2205.15868 , year=
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers , author=. arXiv preprint arXiv:2205.15868 , year=
-
[35]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[36]
arXiv preprint arXiv:2104.08718 , year=
Clipscore: A reference-free evaluation metric for image captioning , author=. arXiv preprint arXiv:2104.08718 , year=
-
[37]
Advances in Neural Information Processing Systems , volume=
Lcgen: Mining in low-certainty generation for view-consistent text-to-3d , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Advances in Neural Information Processing Systems , volume=
Agentic RL scaling law: Spontaneous code execution for mathematical problem solving , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
arXiv preprint arXiv:2512.01311 , year=
CuES: A Curiosity-driven and Environment-grounded Synthesis Framework for Agentic RL , author=. arXiv preprint arXiv:2512.01311 , year=
-
[40]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Hi-ef: Benchmarking emotion forecasting in human-interaction , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[41]
arXiv preprint arXiv:2603.28489 , year=
Video Generation Models as World Models: Efficient Paradigms, Architectures and Algorithms , author=. arXiv preprint arXiv:2603.28489 , year=
-
[42]
arXiv preprint arXiv:2412.09844 , year=
Real-time identity defenses against malicious personalization of diffusion models , author=. arXiv preprint arXiv:2412.09844 , year=
-
[43]
2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Component-aware Unsupervised Logical Anomaly Generation for Industrial Anomaly Detection , author=. 2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2025 , organization=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.