MetaPS: Adaptive Programmatic Strategy Selection for Market Agents
Pith reviewed 2026-06-26 11:04 UTC · model grok-4.3
The pith
MetaPS trains models on simulation rollouts to select from a library of code-based market strategies instead of generating actions directly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
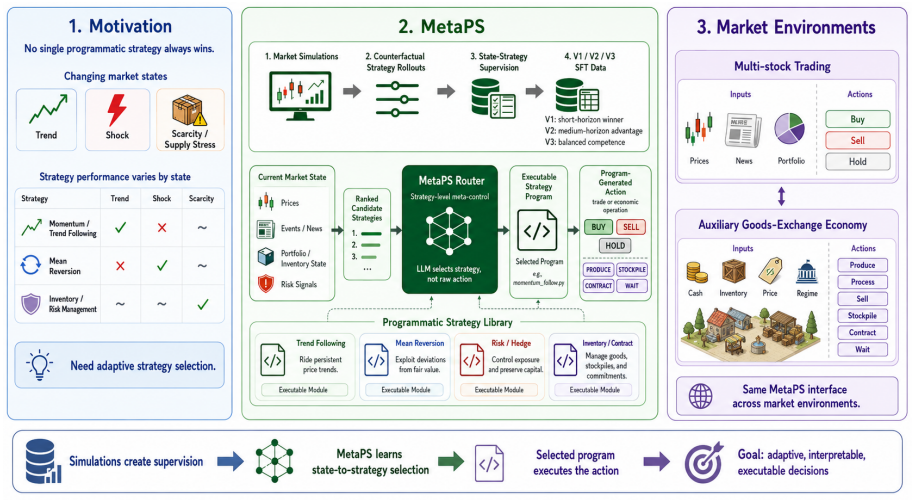
MetaPS converts simulation rollouts of candidate strategy programs into supervised training data that teaches a model to map market states to the program expected to yield better future outcomes; after training, the model selects a program from the library using only the live state, and the selected program produces the final action without further simulation queries.
What carries the argument
A simulation-guided supervised fine-tuning loop that labels state-strategy pairs by their measured performance in backtested or simulated markets.
If this is right
- Compact fine-tuned models can exceed the trading performance of larger prompted API models in the tested settings.
- The final agent remains fully executable as code and produces human-readable strategy selections.
- Training data can be generated at scale from any market simulator without requiring human labels.
- The same selection mechanism can be applied to any domain that supplies a library of programmatic policies.
Where Pith is reading between the lines
- If the simulation-to-reality gap proves small, the approach could reduce reliance on very large models for sequential decision tasks.
- Extending the method to non-stationary environments would require periodic re-simulation to refresh the training labels.
Load-bearing premise
Performance rankings observed when strategies are rolled out in simulation will continue to hold when the selected strategy runs in the real market environment.
What would settle it
Deploy the trained MetaPS selector and a direct-decision baseline in the same live market for a fixed period and compare realized returns under identical conditions.
Figures

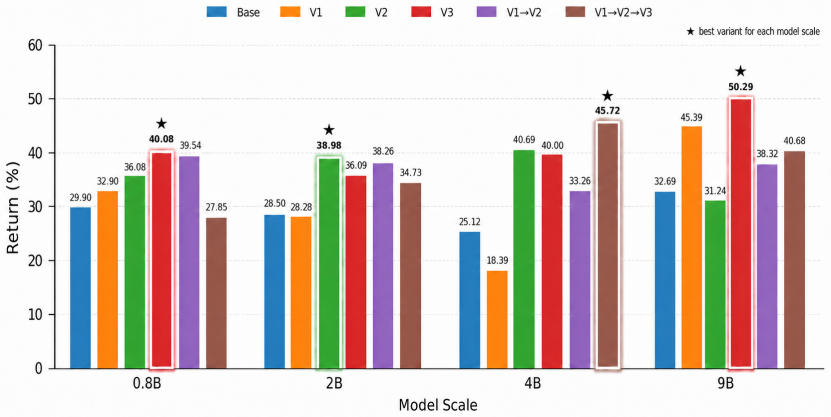
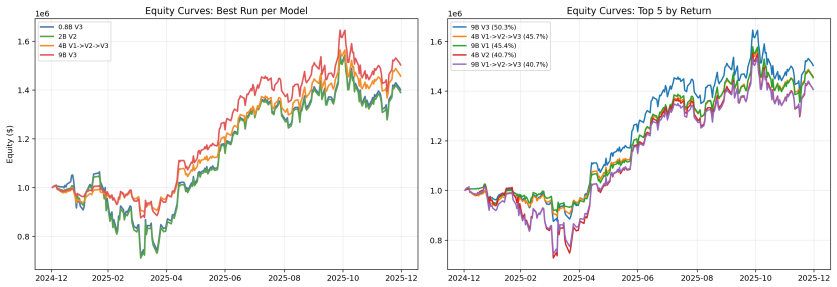
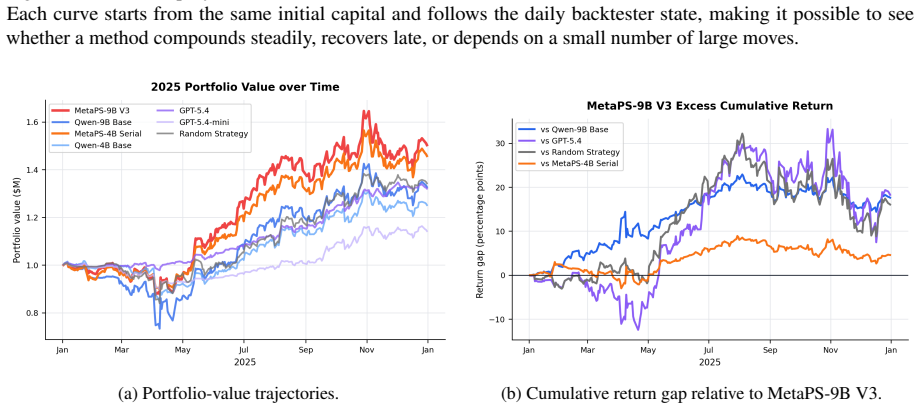
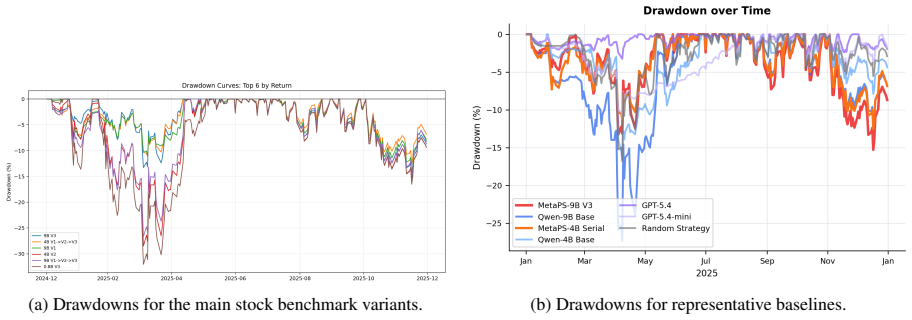
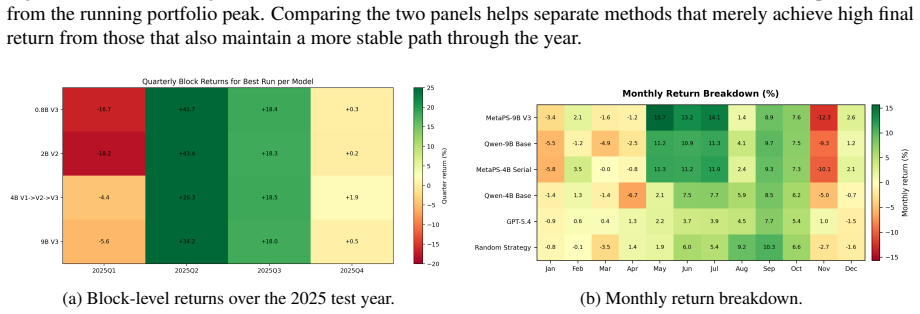
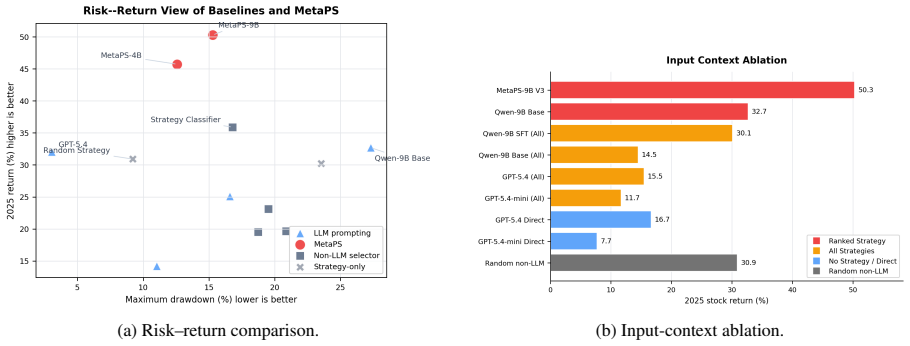
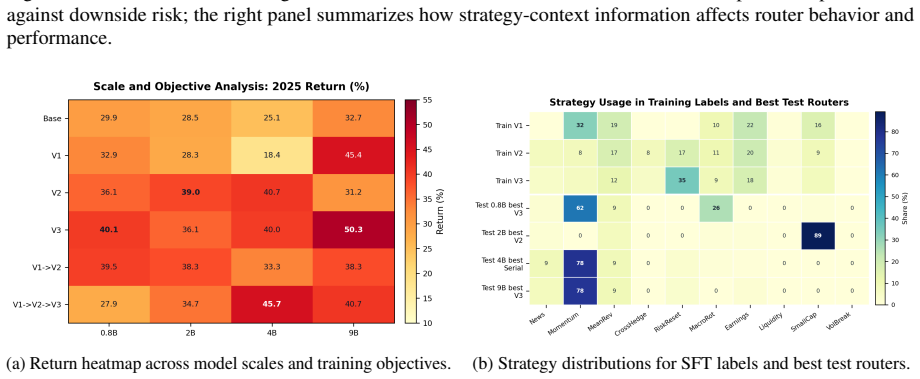

read the original abstract
No single market strategy always wins: momentum, mean reversion, risk control,and event-driven rules can each succeed or fail as market conditions change.Rather than asking large language models to directly generate market actions,we study an executable decision paradigm where an agent selects from a library of programmatic strategies, each implemented as a code module mapping market observations to actions.We propose \textbf{MetaPS}, a simulation-guided framework for adaptive programmatic strategy selection. MetaPS rolls out candidate strategies in simulated or backtested markets, identifies states where particular strategies lead to better future outcomes, and converts these state--strategy pairs into supervised fine-tuning data. During inference, the simulator is no longer queried: MetaPS observes only the current market state and candidate strategy context, selects a suitable strategy program, and the selected program produces the final action. Experiments on multi-stock trading and a controlled goods-exchange sandbox show that MetaPS consistently improves across model scales from 0.8B to 9B parameters. It outperforms fixed-strategy baselines, direct decision-making agents, and prompted API-based LLM agents; in several settings, compact fine-tuned models even surpass stronger API models. These results demonstrate that market simulations can provide scalable and targeted supervision for learning adaptive, interpretable, and executable strategy selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MetaPS, a simulation-guided framework in which candidate programmatic strategies (implemented as code modules) are rolled out in simulated or backtested markets to generate state–strategy pairs; these pairs are used as supervised fine-tuning data for a selector model that, at inference time, maps observed market states to a chosen strategy program without further simulator queries. Experiments on multi-stock trading and a goods-exchange sandbox are reported to show consistent gains across model scales (0.8B–9B parameters), outperforming fixed-strategy baselines, direct decision-making agents, and prompted API-based LLM agents.
Significance. If the reported gains are robust, the approach offers a concrete method for obtaining targeted, scalable supervision from market simulators while preserving interpretability through executable strategy modules. This could be useful for domains where direct LLM decision-making is brittle and where programmatic policies are preferred for auditability.
major comments (2)
- [Abstract] Abstract: the central claim that MetaPS 'consistently improves across model scales' and that 'compact fine-tuned models even surpass stronger API models' is stated without any numerical results, confidence intervals, dataset sizes, number of trials, or exclusion criteria, preventing verification of the magnitude or statistical reliability of the gains.
- [Experiments section] Experiments on multi-stock trading and goods-exchange sandbox: all reported performance numbers are obtained inside the identical simulators used to generate the supervised fine-tuning data; no ablation or transfer experiment tests whether the learned state-to-strategy mapping or the relative ranking of strategy returns remains stable under unmodeled deployment dynamics (variable slippage, liquidity shocks, regime shifts). This assumption is load-bearing for any claim that the method produces deployable market agents.
minor comments (1)
- [Abstract] Abstract: missing space in 'risk control,and event-driven'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that MetaPS 'consistently improves across model scales' and that 'compact fine-tuned models even surpass stronger API models' is stated without any numerical results, confidence intervals, dataset sizes, number of trials, or exclusion criteria, preventing verification of the magnitude or statistical reliability of the gains.
Authors: We agree that the abstract would benefit from quantitative support. In the revised manuscript we will add specific performance deltas (e.g., average return improvements across the 0.8B–9B scale), the number of evaluation trials, and a brief note on the evaluation protocol so that the magnitude and reliability of the reported gains can be assessed directly from the abstract. revision: yes
-
Referee: [Experiments section] Experiments on multi-stock trading and goods-exchange sandbox: all reported performance numbers are obtained inside the identical simulators used to generate the supervised fine-tuning data; no ablation or transfer experiment tests whether the learned state-to-strategy mapping or the relative ranking of strategy returns remains stable under unmodeled deployment dynamics (variable slippage, liquidity shocks, regime shifts). This assumption is load-bearing for any claim that the method produces deployable market agents.
Authors: The referee correctly notes that all reported results are obtained inside the simulators used for data generation. The current work evaluates the simulation-guided training pipeline itself rather than claiming out-of-distribution robustness; we therefore do not present transfer experiments. In revision we will add an explicit Limitations paragraph that states this scope limitation and the load-bearing nature of the in-simulator assumption, while preserving the paper’s focus on the proposed training method. revision: partial
Circularity Check
No circularity in claimed results or derivation
full rationale
The paper presents an empirical framework that generates supervised training data from strategy rollouts inside simulators and then measures selector performance inside the same simulators. No equations, fitted parameters renamed as predictions, or self-citation chains are present that would make any reported gain equivalent to its inputs by construction. The central claim is a standard machine-learning outcome (improved selection policy on held-out simulation episodes) rather than a tautological reduction, so the result remains self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Forty-second International Conference on Machine Learning , year=
The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models , author=. Forty-second International Conference on Machine Learning , year=
-
[2]
arXiv preprint arXiv:2406.19314 , volume=
Livebench: A challenging, contamination-free llm benchmark , author=. arXiv preprint arXiv:2406.19314 , volume=
-
[3]
arXiv preprint arXiv:2509.25140 , year=
Reasoningbank: Scaling agent self-evolving with reasoning memory , author=. arXiv preprint arXiv:2509.25140 , year=
-
[4]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[5]
Forty-second International Conference on Machine Learning , year=
Multi-agent Architecture Search via Agentic Supernet , author=. Forty-second International Conference on Machine Learning , year=
-
[6]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[7]
2024 , month = may, howpublished =
OpenAI , title =. 2024 , month = may, howpublished =
2024
-
[8]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[9]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[10]
arXiv preprint arXiv:2503.05244 , year=
Writingbench: A comprehensive benchmark for generative writing , author=. arXiv preprint arXiv:2503.05244 , year=
-
[11]
arXiv preprint arXiv:2108.07732 , year=
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[12]
International Conference on Learning Representations , year=
Neural Architecture Search with Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[13]
International conference on machine learning , pages=
Efficient neural architecture search via parameters sharing , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[14]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[15]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[16]
arXiv preprint arXiv:2408.06195 , year=
Mutual reasoning makes smaller llms stronger problem-solvers , author=. arXiv preprint arXiv:2408.06195 , year=
-
[17]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[18]
Proceedings of the AAAI conference on artificial intelligence , volume=
Graph of thoughts: Solving elaborate problems with large language models , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[19]
arXiv preprint arXiv:2308.10379 , year=
Algorithm of thoughts: Enhancing exploration of ideas in large language models , author=. arXiv preprint arXiv:2308.10379 , year=
-
[20]
Self-refine: Iterative refinement with self-feedback, 2023 , author=. URL https://arxiv. org/abs/2303.17651 , year=
Pith/arXiv arXiv 2023
-
[21]
arXiv preprint arXiv:2305.11738 , year=
Critic: Large language models can self-correct with tool-interactive critiquing , author=. arXiv preprint arXiv:2305.11738 , year=
-
[22]
Reflexion: Language agents with verbal reinforcement learning, 2023 , author=. URL https://arxiv. org/abs/2303.11366 , volume=
Pith/arXiv arXiv 2023
-
[23]
arXiv preprint arXiv:2506.11442 , year=
ReVeal: Self-Evolving Code Agents via Iterative Generation-Verification , author=. arXiv preprint arXiv:2506.11442 , year=
-
[24]
arXiv preprint arXiv:2310.06117 , year=
Take a step back: Evoking reasoning via abstraction in large language models , author=. arXiv preprint arXiv:2310.06117 , year=
-
[25]
Findings of the association for computational linguistics: ACL 2024 , pages=
Chain-of-verification reduces hallucination in large language models , author=. Findings of the association for computational linguistics: ACL 2024 , pages=
2024
-
[26]
arXiv preprint arXiv:2307.15337 , year=
Skeleton-of-thought: Prompting llms for efficient parallel generation , author=. arXiv preprint arXiv:2307.15337 , year=
-
[27]
arXiv preprint arXiv:2308.04371 , year=
Cumulative reasoning with large language models , author=. arXiv preprint arXiv:2308.04371 , year=
-
[28]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Deal: Decoding-time alignment for large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[29]
The eleventh international conference on learning representations , year=
Large language models are human-level prompt engineers , author=. The eleventh international conference on learning representations , year=
-
[30]
The Twelfth International Conference on Learning Representations , year=
Large language models as optimizers , author=. The Twelfth International Conference on Learning Representations , year=
-
[31]
arXiv preprint arXiv:2306.07863 , year=
Synapse: Trajectory-as-exemplar prompting with memory for computer control , author=. arXiv preprint arXiv:2306.07863 , year=
-
[32]
arXiv preprint arXiv:2502.12018 , year=
Atom of thoughts for markov llm test-time scaling , author=. arXiv preprint arXiv:2502.12018 , year=
-
[33]
arXiv preprint arXiv:2509.26062 , year=
DyFlow: Dynamic Workflow Framework for Agentic Reasoning , author=. arXiv preprint arXiv:2509.26062 , year=
-
[34]
arXiv preprint arXiv:2507.19457 , year=
Gepa: Reflective prompt evolution can outperform reinforcement learning , author=. arXiv preprint arXiv:2507.19457 , year=
-
[35]
arXiv preprint arXiv:2305.04091 , year=
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models , author=. arXiv preprint arXiv:2305.04091 , year=
-
[36]
arXiv preprint arXiv:2304.11477 , year=
Llm+ p: Empowering large language models with optimal planning proficiency , author=. arXiv preprint arXiv:2304.11477 , year=
-
[37]
arXiv preprint arXiv:2205.10625 , year=
Least-to-most prompting enables complex reasoning in large language models , author=. arXiv preprint arXiv:2205.10625 , year=
-
[38]
Advances in Neural Information Processing Systems , volume=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Advances in Neural Information Processing Systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
arXiv preprint arXiv:2205.12255 , year=
Talm: Tool augmented language models , author=. arXiv preprint arXiv:2205.12255 , year=
-
[41]
Easytool: Enhancing llm-based agents with concise tool instruction , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[42]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Calc-x and calcformers: Empowering arithmetical chain-of-thought through interaction with symbolic systems , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[43]
Advances in Neural Information Processing Systems , volume=
Chameleon: Plug-and-play compositional reasoning with large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
arXiv preprint arXiv:2504.19413 , year=
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
-
[45]
arXiv preprint arXiv:2508.06433 , year=
Memp: Exploring agent procedural memory , author=. arXiv preprint arXiv:2508.06433 , year=
-
[46]
arXiv preprint arXiv:2512.10696 , year=
Remember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution , author=. arXiv preprint arXiv:2512.10696 , year=
-
[47]
, author=
MemGPT: Towards LLMs as Operating Systems. , author=. 2023 , publisher=
2023
-
[48]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[49]
arXiv preprint arXiv:2506.07398 , year=
G-Memory: Tracing Hierarchical Memory for Multi-Agent Systems , author=. arXiv preprint arXiv:2506.07398 , year=
-
[50]
Advances in Neural Information Processing Systems , volume=
Hipporag: Neurobiologically inspired long-term memory for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
arXiv preprint arXiv:2507.22925 , year=
Hierarchical memory for high-efficiency long-term reasoning in llm agents , author=. arXiv preprint arXiv:2507.22925 , year=
-
[52]
arXiv preprint arXiv:2407.04363 , year=
Arigraph: Learning knowledge graph world models with episodic memory for llm agents , author=. arXiv preprint arXiv:2407.04363 , year=
-
[53]
arXiv preprint arXiv:2305.13304 , year=
Recurrentgpt: Interactive generation of (arbitrarily) long text , author=. arXiv preprint arXiv:2305.13304 , year=
-
[54]
2022 , publisher=
Memprompt: Memory-assisted prompt editing with user feedback , author=. 2022 , publisher=
2022
-
[55]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Memorybank: Enhancing large language models with long-term memory , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[56]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =
From Implicit Exploration to Structured Reasoning: Guideline and Refinement for LLMs , author =. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =
2025
-
[57]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =
FinHEAR: Human Expertise and Adaptive Risk-Aware Temporal Reasoning for Financial Decision-Making , author =. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =
2025
-
[58]
IEEE Transactions on Big Data , year=
Finmem: A performance-enhanced llm trading agent with layered memory and character design , author=. IEEE Transactions on Big Data , year=
-
[59]
arXiv preprint arXiv:2506.17288 , year=
SlimRAG: Retrieval without Graphs via Entity-Aware Context Selection , author=. arXiv preprint arXiv:2506.17288 , year=
-
[60]
arXiv preprint arXiv:2410.05779 , year=
Lightrag: Simple and fast retrieval-augmented generation , author=. arXiv preprint arXiv:2410.05779 , year=
-
[61]
arXiv preprint arXiv:2404.16130 , year=
From local to global: A graph rag approach to query-focused summarization , author=. arXiv preprint arXiv:2404.16130 , year=
-
[62]
arXiv preprint arXiv:2506.07820 , year=
Guideline Forest: Experience-Induced Multi-Guideline Reasoning with Stepwise Aggregation , author=. arXiv preprint arXiv:2506.07820 , year=
-
[63]
arXiv preprint arXiv:2306.03901 , year=
Chatdb: Augmenting llms with databases as their symbolic memory , author=. arXiv preprint arXiv:2306.03901 , year=
-
[64]
arXiv preprint arXiv:2508.08997 , year=
Intrinsic Memory Agents: Heterogeneous Multi-Agent LLM Systems through Structured Contextual Memory , author=. arXiv preprint arXiv:2508.08997 , year=
-
[65]
Textgrad: Automatic" differentiation" via text , author=. arXiv preprint arXiv:2406.07496 , year=
-
[66]
arXiv preprint arXiv:2310.03714 , year=
Dspy: Compiling declarative language model calls into self-improving pipelines , author=. arXiv preprint arXiv:2310.03714 , year=
-
[67]
Advances in neural information processing systems , volume=
Adaplanner: Adaptive planning from feedback with language models , author=. Advances in neural information processing systems , volume=
-
[68]
Automatic prompt optimization with" gradient descent" and beam search , author=. arXiv preprint arXiv:2305.03495 , year=
-
[69]
arXiv preprint arXiv:2408.08435 , year=
Automated design of agentic systems , author=. arXiv preprint arXiv:2408.08435 , year=
-
[70]
arXiv preprint arXiv:2410.10762 , year=
Aflow: Automating agentic workflow generation , author=. arXiv preprint arXiv:2410.10762 , year=
-
[71]
arXiv preprint arXiv:2508.08053 , year=
AdaptFlow: Adaptive Workflow Optimization via Meta-Learning , author=. arXiv preprint arXiv:2508.08053 , year=
-
[72]
arXiv preprint arXiv:2403.02502 , year=
Trial and error: Exploration-based trajectory optimization for llm agents , author=. arXiv preprint arXiv:2403.02502 , year=
-
[73]
arXiv preprint arXiv:2409.07429 , year=
Agent workflow memory , author=. arXiv preprint arXiv:2409.07429 , year=
-
[74]
arXiv preprint arXiv:2406.11176 , year=
Watch every step! llm agent learning via iterative step-level process refinement , author=. arXiv preprint arXiv:2406.11176 , year=
-
[75]
arXiv preprint arXiv:2310.10134 , year=
Clin: A continually learning language agent for rapid task adaptation and generalization , author=. arXiv preprint arXiv:2310.10134 , year=
-
[76]
arXiv preprint arXiv:2305.16291 , year=
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
-
[77]
arXiv preprint arXiv:2309.17428 , year=
Craft: Customizing llms by creating and retrieving from specialized toolsets , author=. arXiv preprint arXiv:2309.17428 , year=
-
[78]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Llm agents making agent tools , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[79]
arXiv preprint arXiv:2511.10395 , year=
AgentEvolver: Towards Efficient Self-Evolving Agent System , author=. arXiv preprint arXiv:2511.10395 , year=
-
[80]
arXiv preprint arXiv:2511.14460 , year=
Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning , author=. arXiv preprint arXiv:2511.14460 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.