Gen2Balance: Generative Balancing for Long-Tailed Video Action Recognition
Pith reviewed 2026-06-26 10:25 UTC · model grok-4.3
The pith
Gen2Balance augments long-tailed video datasets with text-to-video generated clips and two-stage training to raise accuracy on rare actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
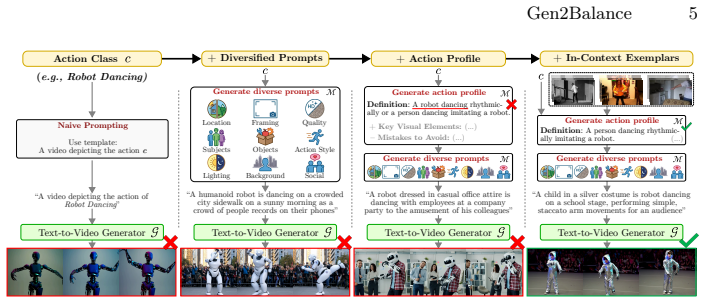
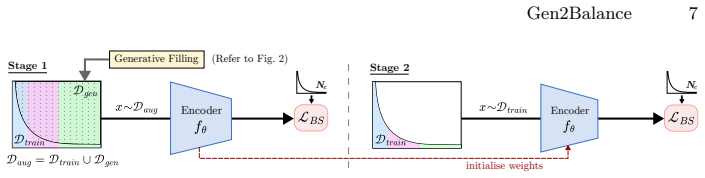
Gen2Balance converts an imbalanced training set into a balanced combination of real and generated video clips by conditioning a text-to-video generative model on diverse text prompts grounded in action profiles and training exemplars. A two-stage training strategy mitigates domain shift between real and synthetic data and produces higher recognition accuracy on long-tailed video benchmarks.
What carries the argument
Two-stage training on a balanced mixture of real videos and synthetic clips generated by a text-to-video model conditioned on action profiles and exemplars.
Load-bearing premise
The text-to-video generative model produces clips that are sufficiently realistic, diverse, and action-relevant that the two-stage training can mitigate any domain shift between real and synthetic data without introducing new biases or artifacts that degrade performance.
What would settle it
If adding the generated clips to the training set produces lower accuracy on the tail classes than training on the real data alone, the central claim would be falsified.
Figures




read the original abstract
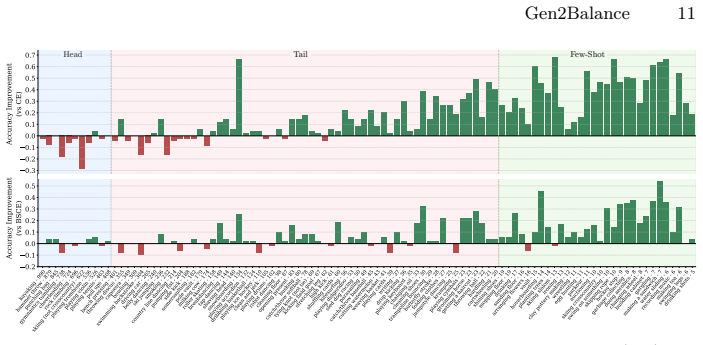
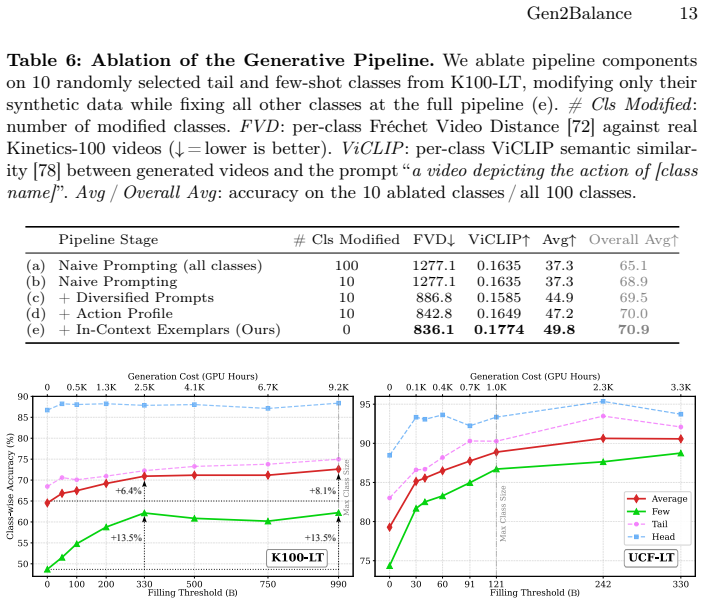
We address the problem of training on long-tailed data for video action recognition. We propose to augment the training set using a text-to-video generative model, conditioned on diverse text prompts grounded in action profiles and training exemplars. Our approach, called Gen2Balance, converts an imbalanced training set into a balanced combination of real and generated video clips. To effectively learn from such data, we employ a two-stage training strategy that mitigates domain shift and yields significant improvements. We evaluate on long-tailed versions of standard benchmarks: UCF-101 (UCF-LT) and a 100-class subset of Kinetics (K100-LT) selected to prioritise temporally challenging actions. Gen2Balance improves accuracy over the strongest baselines for long-tailed learning by 5.1% and 7.0% on the respective datasets. On rare actions from the RareAct dataset (e.g., cut keyboard), Gen2Balance improves accuracy by 31.9%, demonstrating effectiveness for scarce actions. By varying the amount of synthetic data added, we show that partial balancing already achieves 79% of the performance gains at 27% of the compute cost on K100-LT, highlighting the practical scalability of Gen2Balance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Gen2Balance to address long-tailed video action recognition by augmenting imbalanced training sets with synthetic video clips generated via a text-to-video model conditioned on diverse text prompts derived from action profiles and training exemplars. The method converts the data into a balanced real+synthetic mixture and applies a two-stage training strategy to mitigate domain shift. Evaluations on long-tailed versions of UCF-101 (UCF-LT) and a 100-class Kinetics subset (K100-LT) report accuracy gains of 5.1% and 7.0% over the strongest long-tailed learning baselines, with a 31.9% improvement on rare actions from the RareAct dataset. Partial balancing is shown to achieve 79% of the gains at 27% of the compute cost on K100-LT.
Significance. If the empirical claims hold after verification of generated data quality and ablations, the work would be significant for demonstrating a scalable use of generative models to balance video datasets, particularly benefiting rare and temporally complex actions. The efficiency result on partial balancing provides a practical contribution that could influence data augmentation strategies in imbalanced computer vision tasks.
major comments (3)
- [Abstract] Abstract: The headline gains (5.1% UCF-LT, 7.0% K100-LT, 31.9% rare actions) are attributed to balancing via generated clips and two-stage training, yet no quantitative evidence on generated clip quality (e.g., video FID, human ratings, or classification accuracy on synthetic data alone) is supplied; this is load-bearing because poor realism or semantic mismatch would invalidate attribution of improvements to balancing rather than artifacts or negative transfer.
- [Abstract] Abstract: No ablation is described that isolates the two-stage training component from simply adding synthetic samples; without this, it is impossible to confirm that the procedure mitigates domain shift without introducing new biases, which directly supports the central claim that the full pipeline is required for the reported gains.
- [Abstract] Abstract: Details on baseline implementations (e.g., exact long-tailed methods, backbones, and hyper-parameters), the precise generative conditioning procedure, and statistical significance of the improvements are absent, preventing verification that the gains are reproducible and fairly compared to prior work.
minor comments (2)
- [Abstract] Abstract: The term 'action profiles' is introduced without a brief definition or example, which would aid clarity for readers unfamiliar with the conditioning approach.
- [Abstract] Abstract: The efficiency claim ('79% of the performance gains at 27% of the compute cost') references a specific experiment but does not point to the corresponding figure or table, reducing traceability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that additional evidence and details are needed to strengthen the claims and will incorporate them in the revision. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline gains (5.1% UCF-LT, 7.0% K100-LT, 31.9% rare actions) are attributed to balancing via generated clips and two-stage training, yet no quantitative evidence on generated clip quality (e.g., video FID, human ratings, or classification accuracy on synthetic data alone) is supplied; this is load-bearing because poor realism or semantic mismatch would invalidate attribution of improvements to balancing rather than artifacts or negative transfer.
Authors: We agree that quantitative validation of generated clip quality is essential to attribute gains to balancing. In the revised manuscript we will add video FID scores (comparing synthetic to real videos), human ratings on realism and semantic fidelity, and classification accuracy when training a model on synthetic data alone. These additions will directly address concerns about realism and semantic match. revision: yes
-
Referee: [Abstract] Abstract: No ablation is described that isolates the two-stage training component from simply adding synthetic samples; without this, it is impossible to confirm that the procedure mitigates domain shift without introducing new biases, which directly supports the central claim that the full pipeline is required for the reported gains.
Authors: We acknowledge that an explicit ablation separating the two-stage training from naive addition of synthetic samples is required. We will add this ablation in the revision, reporting performance when synthetic samples are added with and without the two-stage procedure, to isolate its contribution to mitigating domain shift. revision: yes
-
Referee: [Abstract] Abstract: Details on baseline implementations (e.g., exact long-tailed methods, backbones, and hyper-parameters), the precise generative conditioning procedure, and statistical significance of the improvements are absent, preventing verification that the gains are reproducible and fairly compared to prior work.
Authors: We will expand the experimental section to include full details on baseline implementations (specific long-tailed methods, backbones, and hyper-parameters), the exact text-prompt conditioning procedure used for generation, and statistical significance via mean and standard deviation over multiple random seeds. revision: yes
Circularity Check
No circularity: empirical performance claims on held-out sets with no derivations
full rationale
The paper presents Gen2Balance, an empirical method that augments long-tailed video datasets with synthetic clips from a text-to-video model and uses two-stage training. All reported results are accuracy improvements on held-out test sets (UCF-LT, K100-LT, RareAct). No equations, mathematical derivations, or self-referential definitions are present in the abstract or described method. The central claims are falsifiable empirical measurements rather than reductions to fitted inputs or self-citations. This is a standard empirical ML paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A text-to-video generative model conditioned on action profiles and training exemplars can produce videos that improve recognition of rare classes when mixed with real data.
Reference graph
Works this paper leans on
-
[1]
In: ICLR (2023)
Ahn, S., Ko, J., Yun, S.Y.: CUDA: Curriculum of data augmentation for long-tailed recognition. In: ICLR (2023)
2023
-
[2]
In: CVPR (2022)
Alshammari, S., Wang, Y.X., Ramanan, D., Kong, S.: Long-tailed recognition via weight balancing. In: CVPR (2022)
2022
-
[3]
arXiv preprint (2025)
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al.: V-JEPA 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint (2025)
2025
-
[4]
TMLR (2023)
Azizi, S., Kornblith, S., Saharia, C., Norouzi, M., Fleet, D.J.: Synthetic data from diffusion models improves imagenet classification. TMLR (2023)
2023
-
[5]
arXiv preprint (2025)
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-VL technical report. arXiv preprint (2025)
2025
-
[6]
In: ICCV (2021)
Bain, M., Nagrani, A., Varol, G., Zisserman, A.: Frozen in time: A joint video and image encoder for end-to-end retrieval. In: ICCV (2021)
2021
-
[7]
In: ICLR (2026)
Bansal, H., Peng, C., Bitton, Y., Goldenberg, R., Grover, A., Chang, K.W.: VideoPhy-2:Achallengingaction-centricphysicalcommonsenseevaluationinvideo generation. In: ICLR (2026)
2026
-
[8]
In: ICCV (2021)
Cai, J., Wang, Y., Hwang, J.N.: ACE: Ally complementary experts for solving long-tailed recognition in one-shot. In: ICCV (2021)
2021
-
[9]
JAIR (2002)
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P.: SMOTE: synthetic minority over-sampling technique. JAIR (2002)
2002
-
[10]
In: ECCV (2020)
Chou, H.P., Chang, S.C., Pan, J.Y., Wei, W., Juan, D.C.: Remix: rebalanced mixup. In: ECCV (2020)
2020
-
[11]
arXiv preprint (2025)
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint (2025)
2025
-
[12]
In: CVPR (2019)
Cubuk, E.D., Zoph, B., Mane, D., Vasudevan, V., Le, Q.V.: AutoAugment: Learn- ing augmentation strategies from data. In: CVPR (2019)
2019
-
[13]
IEEE TPAMI (2022)
Cui, J., Liu, S., Tian, Z., Zhong, Z., Jia, J.: ResLT: Residual learning for long-tailed recognition. IEEE TPAMI (2022)
2022
-
[14]
In: CVPR (2019)
Cui, Y., Jia, M., Lin, T.Y., Song, Y., Belongie, S.: Class-balanced loss based on effective number of samples. In: CVPR (2019)
2019
-
[15]
IJCV (2022)
Damen, D., Doughty, H., Farinella, G.M., Furnari, A., Kazakos, E., Ma, J., Molti- santi, D., Munro, J., Perrett, T., Price, W., et al.: Rescaling egocentric vision: Collection, pipeline and challenges for EPIC-KITCHENS-100. IJCV (2022)
2022
-
[16]
In: CVPR (2021)
Deng, Z., Liu, H., Wang, Y., Wang, C., Yu, Z., Sun, X.: PML: Progressive margin loss for long-tailed age classification. In: CVPR (2021)
2021
-
[17]
In: CVPR (2023) 16 P
Du, F., Yang, P., Jia, Q., Nan, F., Chen, X., Yang, Y.: Global and local mix- ture consistency cumulative learning for long-tailed visual recognitions. In: CVPR (2023) 16 P. Gatti et al
2023
-
[18]
In: ICLR (2023)
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-Or, D.: An image is worth one word: Personalizing text-to-image gener- ation using textual inversion. In: ICLR (2023)
2023
-
[19]
Google Blog (May 2025),https://deepmind.google/models/veo/, accessed: 2026-02-17
Google DeepMind: Veo 3: Video generation with native audio. Google Blog (May 2025),https://deepmind.google/models/veo/, accessed: 2026-02-17
2025
-
[20]
something something
Goyal, R., Ebrahimi Kahou, S., Michalski, V., Materzynska, J., Westphal, S., Kim, H., Haenel, V., Fruend, I., Yianilos, P., Mueller-Freitag, M., et al.: The "something something" video database for learning and evaluating visual common sense. In: ICCV (2017)
2017
-
[21]
In: ICLR (2026)
Gu, J., Liu, X., Zeng, Y., Nagarajan, A., Zhu, F., Hong, D., Fan, Y., Yan, Q., Zhou, K., Liu, M.Y., et al.: PhyWorldBench: A comprehensive evaluation of physical realism in text-to-video models. In: ICLR (2026)
2026
-
[22]
In: CVPR (2019)
Gupta, A., Dollar, P., Girshick, R.: LVIS: A dataset for large vocabulary instance segmentation. In: CVPR (2019)
2019
-
[23]
In: ICLR (2024)
Hasegawa, N., Sato, I.: Exploring weight balancing on long-tailed recognition prob- lem. In: ICLR (2024)
2024
-
[24]
He, R., Sun, S., Yu, X., Xue, C., Zhang, W., Torr, P., Bai, S., QI, X.: Is synthetic data from generative models ready for image recognition? In: ICLR (2023)
2023
-
[25]
In: ICML (2025)
Hou, Y., Jia, Y.: A square peg in a square hole: Meta-expert for long-tailed semi- supervised learning. In: ICML (2025)
2025
-
[26]
IEEE TMM (2023)
Hu, Y., Gao, J., Xu, C.: Learning multi-expert distribution calibration for long- tailed video classification. IEEE TMM (2023)
2023
-
[27]
Multimedia Systems (2025)
Hu, Y., Zhang, Y., Zhang, L.: Long-tailed video recognition via majority-guided diffusion model. Multimedia Systems (2025)
2025
-
[28]
In: CVPR (2023)
Iscen, A., Fathi, A., Schmid, C.: Improving image recognition by retrieving from web-scale image-text data. In: CVPR (2023)
2023
-
[29]
In: CVPR (2020)
Jamal, M.A., Brown, M., Yang, M.H., Wang, L., Gong, B.: Rethinking class- balanced methods for long-tailed visual recognition from a domain adaptation perspective. In: CVPR (2020)
2020
-
[30]
Kang, B., Xie, S., Rohrbach, M., Yan, Z., Gordo, A., Feng, J., Kalantidis, Y.: Decouplingrepresentationandclassifierforlong-tailedrecognition.In:ICLR(2020)
2020
-
[31]
arXiv preprint (2017)
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., et al.: The kinetics human action video dataset. arXiv preprint (2017)
2017
-
[32]
1 Kontext: Flow matching for in-context image generation and editing in latent space
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., et al.: FLUX. 1 Kontext: Flow matching for in-context image generation and editing in latent space. arXiv preprint (2025)
2025
-
[33]
In: CVPR (2022)
Li, B., Yao, Y., Tan, J., Zhang, G., Yu, F., Lu, J., Luo, Y.: Equalized focal loss for dense long-tailed object detection. In: CVPR (2022)
2022
-
[34]
In: CVPR (2022)
Li, B., Han, Z., Li, H., Fu, H., Zhang, C.: Trustworthy long-tailed classification. In: CVPR (2022)
2022
-
[35]
In: CVPR (2022)
Li, M., Cheung, Y.m., Lu, Y.: Long-tailed visual recognition via gaussian clouded logit adjustment. In: CVPR (2022)
2022
-
[36]
In: AAAI (2024)
Li, M., Zhikai, H., Lu, Y., Lan, W., Cheung, Y.m., Huang, H.: Feature fusion from head to tail for long-tailed visual recognition. In: AAAI (2024)
2024
-
[37]
In: ECCV (2024)
Li, R., Feng, Z., Xu, T., Li, L., Wu, X.J., Awais, M., Atito, S., Kittler, J.: C2C: Component-to-compositionlearningforzero-shotcompositionalactionrecognition. In: ECCV (2024)
2024
-
[38]
In: IJCAI (2025) Gen2Balance 17
Li, W., Luo, D., Yang, D., Li, Z., Wang, W., Zhou, Y.: The role of video generation in enhancing data-limited action understanding. In: IJCAI (2025) Gen2Balance 17
2025
-
[39]
In: AAAI (2023)
Li, X., Xu, H.: MEID: mixture-of-experts with internal distillation for long-tailed video recognition. In: AAAI (2023)
2023
-
[40]
In: CVPR (2020)
Li, Y., Wang, T., Kang, B., Tang, S., Wang, C., Li, J., Feng, J.: Overcoming classifier imbalance for long-tail object detection with balanced group softmax. In: CVPR (2020)
2020
-
[41]
IJCV (2024)
Lin, J., Liu, Z., Wang, W., Wu, W., Wang, L.: VLG: General video recognition with web textual knowledge. IJCV (2024)
2024
-
[42]
In: ICCV (2017)
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: ICCV (2017)
2017
-
[43]
IEEE Transactions on Systems, Man, and Cybernetics (2008)
Liu, X.Y., Wu, J., Zhou, Z.H.: Exploratory undersampling for class-imbalance learning. IEEE Transactions on Systems, Man, and Cybernetics (2008)
2008
-
[44]
In: CVPR (2019)
Liu, Z., Miao, Z., Zhan, X., Wang, J., Gong, B., Yu, S.X.: Large-scale long-tailed recognition in an open world. In: CVPR (2019)
2019
-
[45]
In: CVPR (2022)
Long, A., Yin, W., Ajanthan, T., Nguyen, V., Purkait, P., Garg, R., Blair, A., Shen, C., Van den Hengel, A.: Retrieval augmented classification for long-tail visual recognition. In: CVPR (2022)
2022
-
[46]
In: ICLR (2021)
Menon, A.K., Jayasumana, S., Rawat, A.S., Jain, H., Veit, A., Kumar, S.: Long-tail learning via logit adjustment. In: ICLR (2021)
2021
-
[47]
Midjourney, Inc.: Midjourney.https://www.midjourney.com(2022), accessed: 2026-02-17
2022
-
[48]
arXiv preprint (2020)
Miech, A., Alayrac, J.B., Laptev, I., Sivic, J., Zisserman, A.: RareAct: A video dataset of unusual interactions. arXiv preprint (2020)
2020
-
[49]
In: AAAI (2023)
Moon, W., Seong, H.S., Heo, J.P.: Minority-oriented vicinity expansion with at- tentive aggregation for video long-tailed recognition. In: AAAI (2023)
2023
-
[50]
Motamed, S., Culp, L., Swersky, K., Jaini, P., Geirhos, R.: Do generative video models understand physical principles? In: WACV (2026)
2026
-
[51]
OpenAI Blog (Sep 2025),https://openai.com/index/ sora-2/, accessed: 2026-02-17
OpenAI: Sora 2 is here. OpenAI Blog (Sep 2025),https://openai.com/index/ sora-2/, accessed: 2026-02-17
2025
-
[52]
In: CVPR (2023)
Perrett, T., Sinha, S., Burghardt, T., Mirmehdi, M., Damen, D.: Use your head: Improving long-tail video recognition. In: CVPR (2023)
2023
-
[53]
Google Blog (The Keyword) (Nov 2025),https://blog.google/innovation-and-ai/products/nano-banana-pro/, accessed: 2026-02-17
Raisinghani, N.: Introducing Nano Banana Pro. Google Blog (The Keyword) (Nov 2025),https://blog.google/innovation-and-ai/products/nano-banana-pro/, accessed: 2026-02-17
2025
-
[54]
NeurIPS (2020)
Ren, J., Yu, C., Ma, X., Zhao, H., Yi, S., et al.: Balanced meta-softmax for long- tailed visual recognition. NeurIPS (2020)
2020
-
[55]
In: CVPR (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
2022
-
[56]
Runway Research (Dec 2025),https: //runwayml.com/research/introducing-runway-gen-4.5, accessed: 2026-02-17
Runway AI: Introducing Runway Gen-4.5. Runway Research (Dec 2025),https: //runwayml.com/research/introducing-runway-gen-4.5, accessed: 2026-02-17
2025
-
[57]
In: CVPR (2023)
Sariyildiz, M.B., Alahari, K., Larlus, D., Kalantidis, Y.: Fake it till you make it: Learning transferable representations from synthetic imagenet clones. In: CVPR (2023)
2023
-
[58]
In: WACV (2021)
Sevilla-Lara, L., Zha, S., Yan, Z., Goswami, V., Feiszli, M., Torresani, L.: Only time can tell: Discovering temporal data for temporal modeling. In: WACV (2021)
2021
-
[59]
In: NeurIPS (2024)
Shao, J., Zhu, K., Zhang, H., Wu, J.: DiffuLT: Diffusion for long-tail recognition without external knowledge. In: NeurIPS (2024)
2024
-
[60]
arXiv preprint (2023)
Shin, J., Kang, M., Park, J.: Fill-Up: Balancing long-tailed data with generative models. arXiv preprint (2023)
2023
-
[61]
NeurIPS (2019) 18 P
Shu, J., Xie, Q., Yi, L., Zhao, Q., Zhou, S., Xu, Z., Meng, D.: Meta-weight-net: Learning an explicit mapping for sample weighting. NeurIPS (2019) 18 P. Gatti et al
2019
-
[62]
In: CVPR (2025)
Sidhu, M., Chopra, H., Blume, A., Kim, J., Reddy, R.G., Ji, H.: Search and detect: Training-free long tail object detection via web-image retrieval. In: CVPR (2025)
2025
-
[63]
In: CVPR 2024 Workshop SyntaGen: Harnessing Generative Models for Synthetic Visual Datasets (2024)
Singh, K., Navaratnam, T., Holmer, J., Schaub-Meyer, S., Roth, S.: Is synthetic data all we need? benchmarking the robustness of models trained with synthetic images. In: CVPR 2024 Workshop SyntaGen: Harnessing Generative Models for Synthetic Visual Datasets (2024)
2024
-
[64]
arXiv preprint (2012)
Soomro, K., Zamir, A.R., Shah, M.: UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint (2012)
2012
-
[65]
In: ICLR (2025)
Sun, S., Lu, H., Li, J., Xie, Y., Li, T., Yang, X., Zhang, L., Yan, J.: Rethinking classifier re-training in long-tailed recognition: Label over-smooth can balance. In: ICLR (2025)
2025
-
[66]
In: CVPR (2021)
Tan, J., Lu, X., Zhang, G., Yin, C., Li, Q.: Equalization loss v2: A new gradient balance approach for long-tailed object detection. In: CVPR (2021)
2021
-
[67]
In: CVPR (2020)
Tan, J., Wang, C., Li, B., Li, Q., Ouyang, W., Yin, C., Yan, J.: Equalization loss for long-tailed object recognition. In: CVPR (2020)
2020
-
[68]
In: ICCV (2023)
Tao, Y., Sun, J., Yang, H., Chen, L., Wang, X., Yang, W., Du, D., Zheng, M.: Local and global logit adjustments for long-tailed learning. In: ICCV (2023)
2023
-
[69]
Thozhiyoor, V.V., Tripathi, S., Radhakrishnan, V.B., Bhattad, A.: Objects in gen- erated videos are slower than they appear: Models suffer sub-earth gravity and don’t know galileo’s principle... for now. In: CVPR Findings (2026)
2026
-
[70]
NeurIPS (2020)
Tian, J., Liu, Y.C., Glaser, N., Hsu, Y.C., Kira, Z.: Posterior re-calibration for imbalanced datasets. NeurIPS (2020)
2020
-
[71]
NeurIPS (2022)
Tong, Z., Song, Y., Wang, J., Wang, L.: VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. NeurIPS (2022)
2022
-
[72]
In: ICLR 2019 Workshop Deep Gen- erative Models for Highly Structured Data (2019)
Unterthiner, T., van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: FVD: A new metric for video generation. In: ICLR 2019 Workshop Deep Gen- erative Models for Highly Structured Data (2019)
2019
-
[73]
In: ICML (2019)
Verma, V., Lamb, A., Beckham, C., Najafi, A., Mitliagkas, I., Lopez-Paz, D., Ben- gio, Y.: Manifold mixup: Better representations by interpolating hidden states. In: ICML (2019)
2019
-
[74]
arXiv preprint (2025)
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: WAN: Open and advanced large-scale video generative models. arXiv preprint (2025)
2025
-
[75]
In: ICLR (2024)
Wang, B., Wang, P., Xu, W., Wang, X., Zhang, Y., Wang, K., Wang, Y.: Kill two birds with one stone: Rethinking data augmentation for deep long-tailed learning. In: ICLR (2024)
2024
-
[76]
In: NeurIPS (2024)
Wang, P., Zhao, Z., Wen, H., Wang, F., Wang, B., Zhang, Q., Wang, Y.: LLM- autoDA: Largelanguage model-drivenautomatic dataaugmentation forlong-tailed problems. In: NeurIPS (2024)
2024
-
[77]
In: ICLR (2020)
Wang, X., Lian, L., Miao, Z., Liu, Z., Yu, S.X.: Long-tailed recognition by routing diverse distribution-aware experts. In: ICLR (2020)
2020
-
[78]
In: ICLR (2024)
Wang, Y., He, Y., Li, Y., Li, K., Yu, J., Ma, X., Li, X., Chen, G., Chen, X., Wang, Y., et al.: InternVid: A large-scale video-text dataset for multimodal understanding and generation. In: ICLR (2024)
2024
-
[79]
arXiv preprint (2025)
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint (2025)
2025
-
[80]
In: CVPR (2021)
Wu, T., Liu, Z., Huang, Q., Wang, Y., Lin, D.: Adversarial robustness under long- tailed distribution. In: CVPR (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.