Adaptive Recurrent Message Passing for Test Time Computing on Graphs
Pith reviewed 2026-06-26 10:47 UTC · model grok-4.3
The pith
Step dependence is necessary and sufficient for adaptively convergent recurrent processes on graphs, enabling parameter-free test-time computing via AdaR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
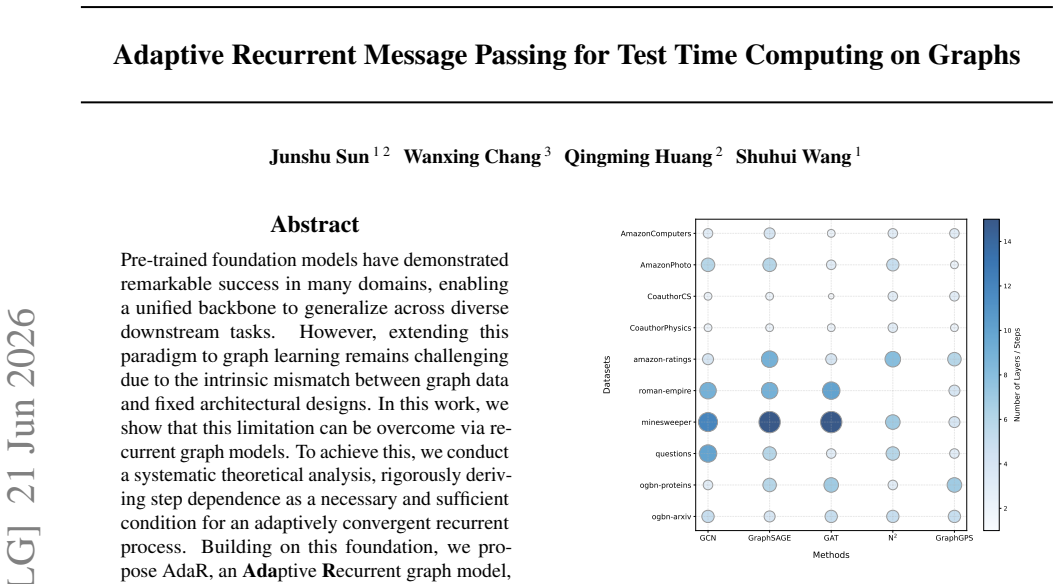
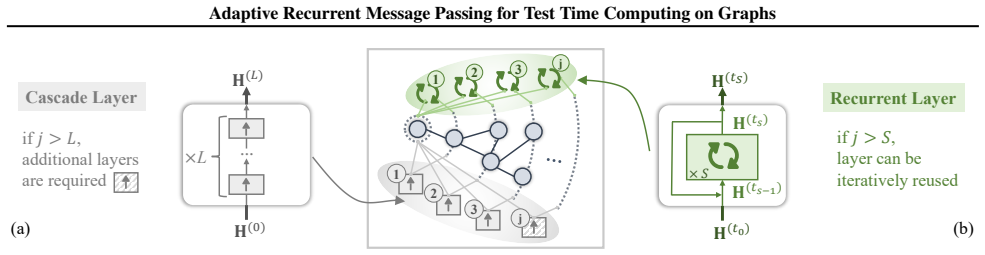
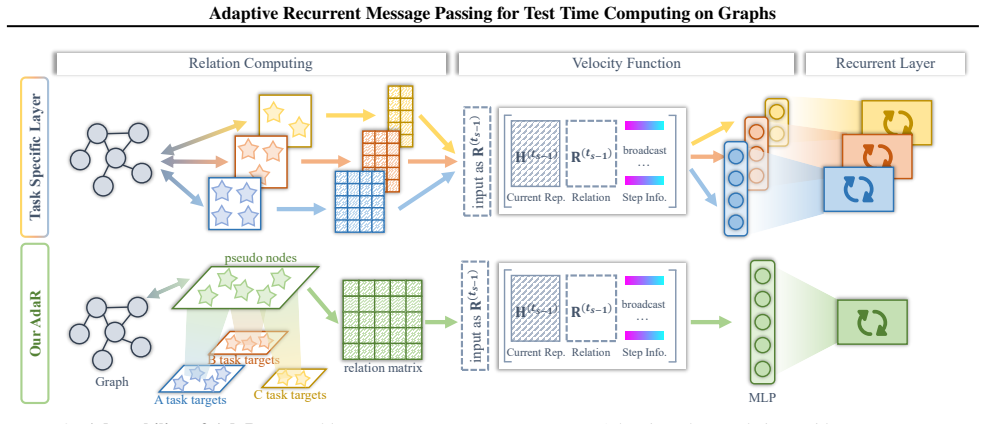
We rigorously derive step dependence as a necessary and sufficient condition for an adaptively convergent recurrent process. Building on this foundation, we propose AdaR, an Adaptive Recurrent graph model, empowering flexible test-time computing on various downstream tasks without changing model parameters. To enable adaptive inference, AdaR explicitly encodes normalized step information and representation-target relations into the recurrent updates. To ensure convergence of the recurrent process, AdaR employs gradient-based supervision signals that guide representation updates throughout the recurrence.
What carries the argument
Step dependence, the condition that makes an adaptively convergent recurrent process possible on graphs by tying update behavior to the current computation step.
If this is right
- AdaR performs test-time computing on graphs without altering its pre-trained parameters.
- The same model can be applied to both inductive and transductive downstream tasks.
- Recurrent message passing becomes viable for foundation-model-style generalization once step dependence is enforced.
- Gradient supervision during recurrence guarantees convergence without task-specific retraining.
Where Pith is reading between the lines
- Variable numbers of recurrence steps could be chosen at inference time to trade compute for accuracy on new graphs.
- The same step-dependence principle may transfer to recurrent architectures outside the graph domain.
Load-bearing premise
The recurrent process can be made to converge reliably by encoding normalized step information and representation-target relations together with gradient-based supervision signals.
What would settle it
Training or running AdaR without the normalized step-information encoding and observing whether the recurrent process still converges and adapts on standard graph benchmarks.
Figures

read the original abstract
Pre-trained foundation models have demonstrated remarkable success in many domains, enabling a unified backbone to generalize across diverse downstream tasks. However, extending this paradigm to graph learning remains challenging due to the intrinsic mismatch between graph data and fixed architectural designs. In this work, we show that this limitation can be overcome via recurrent graph models. To achieve this, we conduct a systematic theoretical analysis, rigorously deriving step dependence as a necessary and sufficient condition for an adaptively convergent recurrent process. Building on this foundation, we propose AdaR, an Adaptive Recurrent graph model, empowering flexible test-time computing on various downstream tasks without changing model parameters. To enable adaptive inference, AdaR explicitly encodes normalized step information and representation-target relations into the recurrent updates. To ensure convergence of the recurrent process, AdaR employs gradient-based supervision signals that guide representation updates throughout the recurrence. Empirical results demonstrate that AdaR consistently outperforms strong baselines in both inductive and transductive settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a systematic theoretical analysis derives step dependence as a necessary and sufficient condition for an adaptively convergent recurrent process on graphs. It proposes AdaR, an adaptive recurrent graph model that encodes normalized step information and representation-target relations into updates and uses gradient-based supervision to ensure convergence, thereby enabling parameter-free test-time computing; empirical results are said to show consistent outperformance over baselines in inductive and transductive settings.
Significance. If the derivation of necessity and sufficiency holds and the empirical results prove robust, the work could establish a principled mechanism for adaptive recurrence in graph models, addressing architectural mismatch with graph data via test-time adaptation without parameter changes. The focus on a formal condition for convergence would be a notable strength if rigorously established.
major comments (2)
- [Abstract] Abstract: the central claim that step dependence is necessary and sufficient for an adaptively convergent recurrent process is asserted without any definition of 'step dependence', formal theorem statement, assumptions, or proof sketch, rendering the derivation unevaluable for correctness or internal consistency.
- [Abstract] Abstract (AdaR design paragraph): the convergence guarantee is described only via design elements (normalized step encoding, representation-target relations, gradient supervision) with no equations, analysis, or conditions showing how these elements produce reliable convergence or exploit the claimed step-dependence property.
minor comments (1)
- [Abstract] Abstract lacks any mention of datasets, error bars, ablation controls, or statistical significance for the empirical superiority claims.
Simulated Author's Rebuttal
We thank the referee for highlighting issues with the clarity of our abstract. We agree that the abstract's brevity makes the central theoretical claim difficult to evaluate without additional context, and we will revise it to address both points while preserving its summary nature. The full definitions, theorems, equations, and proofs appear in Sections 3 and 4 of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that step dependence is necessary and sufficient for an adaptively convergent recurrent process is asserted without any definition of 'step dependence', formal theorem statement, assumptions, or proof sketch, rendering the derivation unevaluable for correctness or internal consistency.
Authors: We agree the abstract does not define 'step dependence' or include a theorem statement. 'Step dependence' is defined in Section 3 as the explicit encoding of normalized iteration count into the recurrent update function. Theorem 1 states that step dependence is necessary and sufficient for adaptive convergence of the recurrent process on graphs, under the assumptions of Lipschitz continuity of the update and bounded graph degree. The proof sketch (contraction mapping for sufficiency; counterexample construction for necessity) is also in Section 3. We will revise the abstract to include a one-sentence definition and reference to Theorem 1. revision: yes
-
Referee: [Abstract] Abstract (AdaR design paragraph): the convergence guarantee is described only via design elements (normalized step encoding, representation-target relations, gradient supervision) with no equations, analysis, or conditions showing how these elements produce reliable convergence or exploit the claimed step-dependence property.
Authors: We agree the abstract summarizes design elements without equations or explicit conditions. The normalized step encoding appears in Equation (4), the target-relation term in Equation (5), and gradient supervision in the loss of Equation (7). Section 4.2 analyzes how these components enforce the step-dependent contraction required by Theorem 1, yielding convergence to a fixed point independent of initialization. We will revise the abstract to add a brief clause stating the convergence condition derived from step dependence. revision: yes
Circularity Check
No circularity detected; asserted theoretical derivation not provided for inspection
full rationale
The paper asserts that a systematic theoretical analysis was conducted to derive step dependence as a necessary and sufficient condition for an adaptively convergent recurrent process, upon which AdaR is built. However, the provided text contains no equations, no formal definition of step dependence, no theorem statement, no assumptions, and no proof. The AdaR design is described only at the level of intent (encoding normalized step information, representation-target relations, and gradient supervision). No self-definitional, fitted-input, or self-citation patterns can be exhibited because the derivation chain itself is not visible. The central claim therefore cannot be reduced to its inputs by construction from the given material, making the derivation self-contained against external benchmarks by default.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Step dependence is necessary and sufficient for adaptive convergence of recurrent graph message passing
Reference graph
Works this paper leans on
-
[1]
Hu, Z., Li, Y ., Chen, Z., Wang, J., Liu, H., Lee, K., and Ding, K
Association for Computing Machinery. Hu, Z., Li, Y ., Chen, Z., Wang, J., Liu, H., Lee, K., and Ding, K. Let’s Ask GNN: Empowering Large Language Model for Graph In-Context Learning. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Findings of the Asso- ciation for Computational Linguistics: EMNLP 2024, pp. 1396–1409, Miami, Florida, USA,
2024
-
[2]
Can GNN be Good Adapter for LLMs? InProceedings of the ACM Web Conference 2024, pp
Huang, X., Han, K., Yang, Y ., Bao, D., Tao, Q., Chai, Z., and Zhu, Q. Can GNN be Good Adapter for LLMs? InProceedings of the ACM Web Conference 2024, pp. 893–904, New York, NY , USA,
2024
-
[3]
X., and Li, J
Li, Y ., Wang, P., Li, Z., Yu, J. X., and Li, J. ZeroG: Investi- gating Cross-dataset Zero-shot Transferability in Graphs. InACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 1725–1735, New York, NY , USA, 2024b. Association for Computing Machinery. Liu, H., Feng, J., Kong, L., Liang, N., Tao, D., Chen, Y ., and Zhang, M. One For All: Towa...
2023
-
[4]
Scarselli, F., Gori, M., Tsoi, A
ISSN 1941-0476. Scarselli, F., Gori, M., Tsoi, A. C., Hagenbuchner, M., and Monfardini, G. The Graph Neural Network Model.IEEE Transactions on Neural Networks, 20(1):61–80,
1941
-
[5]
Pitfalls of Graph Neural Network Evaluation
Shchur, O., Mumme, M., Bojchevski, A., and G¨unnemann, S. Pitfalls of Graph Neural Network Evaluation. arXiv:1811.05868 [cs, stat],
-
[6]
Re- lieving the Over-Aggregating Effect in Graph Transform- ers
Sun, J., Chang, W., Yang, C., Huang, Q., and Wang, S. Re- lieving the Over-Aggregating Effect in Graph Transform- ers. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025a. Sun, L., Huang, Z., Zhou, S., Wan, Q., Peng, H., and Yu, P. S. RiemannGFM: Learning a Graph Foundation Model from Structural Geometry. InTHE WEB CONFERE...
2025
-
[7]
Xia, L., Kao, B., and Huang, C
doi: 10.52202/079017-3412. Xia, L., Kao, B., and Huang, C. OpenGraph: Towards Open Graph Foundation Models. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 2365– 2379, Miami, Florida, USA,
-
[8]
Yu, X., Fang, Y ., Liu, Z., Wu, Y ., Wen, Z., Bo, J., Zhang, X., and Hoi, S. C. H. A Survey of Few-Shot Learning on Graphs: From Meta-Learning to Pre-Training and Prompt Learning, 2024a. Yu, X., Zhou, C., Fang, Y ., and Zhang, X. MultiGPrompt for Multi-Task Pre-Training and Prompting on Graphs. InProceedings of the ACM Web Conference 2024, pp. 515–526, Ne...
2024
-
[9]
(A14) By uniform approximation, the Lipschitz condition, and the triangle inequality, we obtain ∥es+1∥ ≤(1 +L H∆t)∥es∥+ε∆t+K 1∆t2,(A15) for some constantK 1 >0. Applying induction and usinge 0 = 0, we have ∥es+1∥ ≤(1 +L H∆t)s+1∥e0∥|{z} =0 + sX i=0 (1 +L H∆t)i(ε∆t+K 1∆t2) = (1 +L H∆t)s −1 LH∆t (ε∆t+K 1∆t2) = exp[sln(1 +L H∆t)]−1 LH (ε+K 1∆t) ≤ exp[sLH∆t]−1...
2024
-
[10]
Regarding implementations, pseudo nodes in AdaR are shared parameters for all graphs
or to enhance the cross-graph communication (Zhao et al., 2024), yet AdaR employs pseudo nodes to unify different targets. Regarding implementations, pseudo nodes in AdaR are shared parameters for all graphs. Conversely, pseudo nodes in previous works either cannot be jointly optimized with the overall framework or fail to transfer across tasks (Liu et al...
2024
-
[11]
In contrast, fixing the total time with T= 1 rescales ts to [0,1]
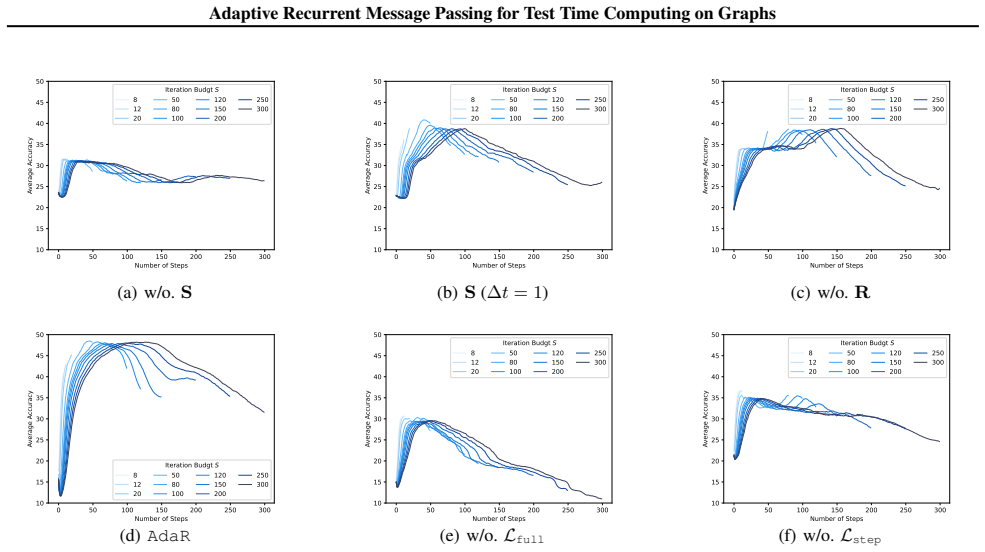
proportional to T and large embedding deviations. In contrast, fixing the total time with T= 1 rescales ts to [0,1] . Therefore, the maximum shift is bounded by the constant wk independent ofT, implying smaller embedding shifts. Empirical Analysis.To empirically validate our encoding strategy, we select the iteration budget from two distinct ranges, i.e.s...
2008
-
[12]
Specifically, CoauthorCS and CoauthorPhysics are derived from the Microsoft Academic Graph and model academic collaboration networks
and homophilic datasets (CoauthorCS, CoauthorPhysics, AmazonPhoto, and AmazonComputers) (Shchur et al., 2019). Specifically, CoauthorCS and CoauthorPhysics are derived from the Microsoft Academic Graph and model academic collaboration networks. AmazonComputers and AmazonPhoto are product co-purchase networks collected from Amazon. Questions is built from ...
2019
-
[13]
Models are selected based on the average performance on training datasets for the zero-shot setting, while based on validation sets for the transductive setting
For transductive experiments, the training epoch is set as 1,000 , the learning rate is set to 1×10 −3, the training iteration budget is selected from {2,4,8} , the test-time iteration budget is selected from {8,20,50,100,150,200,250,300} and the dropout probability is selected from {0,0.1,0.2,0.3} . Models are selected based on the average performance on...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.