CVSBench: A Comprehensive Benchmark for Cross-view Spatial Reasoning and Dreaming
Pith reviewed 2026-06-26 10:52 UTC · model grok-4.3
The pith
VLMs struggle with cross-view spatial reasoning but gain substantially from 3D scene imagination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
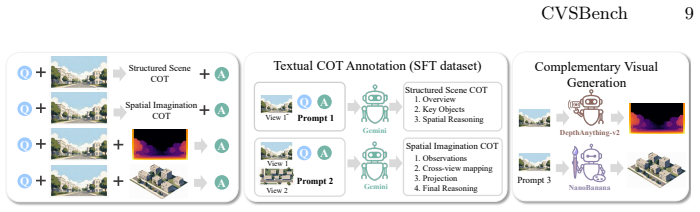
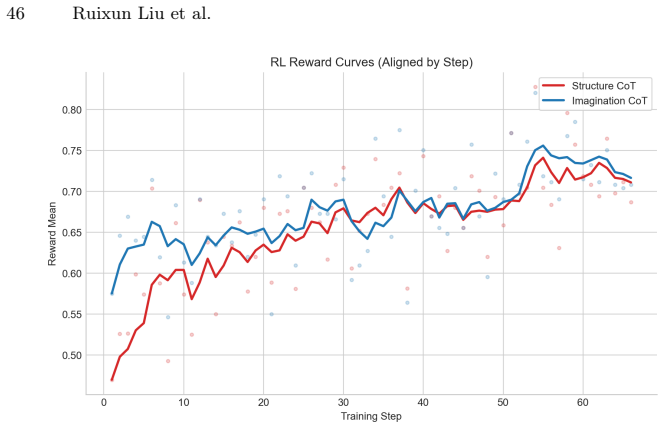
Advanced VLMs fail to maintain object-level and layout consistency when reasoning across satellite-street viewpoint changes. Language-only reasoning yields only marginal improvements, whereas a 3D scene imagination pipeline that supplies visual spatial representations produces substantial gains on cross-view VQA, grounding, and viewpoint identification tasks. The work therefore concludes that explicit visual-spatial representations are necessary for robust spatial cognition in these models.
What carries the argument
The 3D scene imagination pipeline that converts input views into explicit visual spatial representations for downstream reasoning.
If this is right
- Language-only reasoning is insufficient for maintaining consistency across drastic viewpoint changes.
- Explicit visual-spatial representations improve performance on object-level and layout tasks.
- Spatially grounded reasoning and cognitive map inputs are promising directions for closing the gap with human performance.
- The benchmark enables controlled, systematic measurement of progress on cross-view abilities.
Where Pith is reading between the lines
- The same 3D imagination step could be tested on other multi-view domains such as indoor navigation or robotics.
- Models that integrate 3D reconstruction as a default module may show broader gains on any task requiring viewpoint invariance.
- Repeated use of the benchmark over time would track whether the field is moving toward visual-spatial representations.
Load-bearing premise
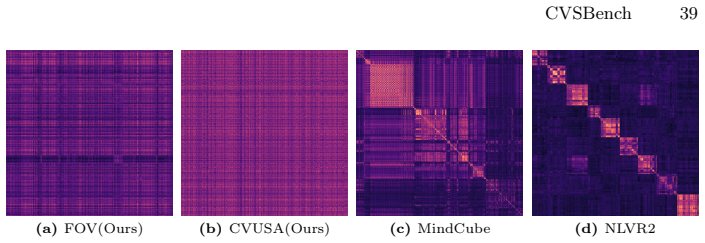
The satellite-street scene pairs and tasks in CVSBench form a valid and unbiased measure of cross-view spatial reasoning abilities.
What would settle it
A VLM that reaches high accuracy on the benchmark's cross-view VQA and grounding tasks without using any 3D scene imagination or other visual spatial input would falsify the necessity claim.
Figures










read the original abstract
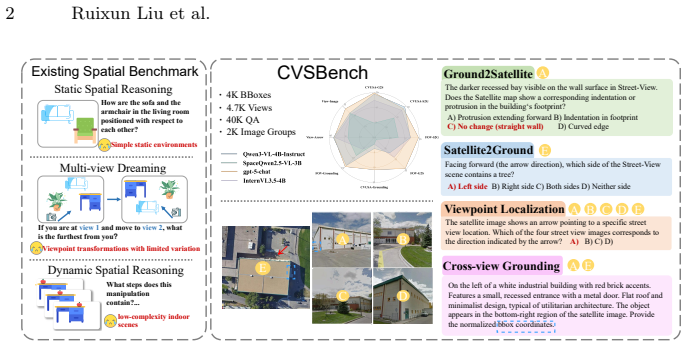
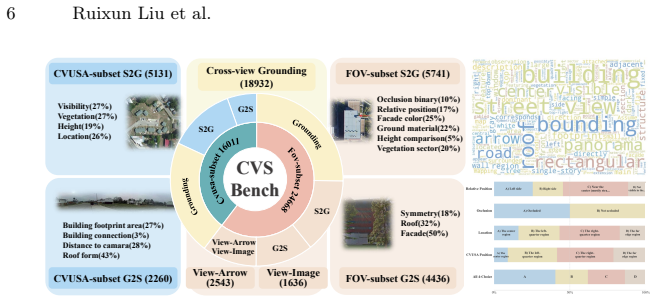
Humans can effortlessly reason about scenes across different viewpoints, yet it remains unclear whether Vision-Language Models (VLMs) possess similar cross-view spatial abilities. Satellite-street scene pairs, with their complex contexts and extreme viewpoint variations, provide an ideal testbed. Motivated by this, we introduce CVSBench, a large-scale benchmark for evaluating cross-view spatial reasoning through satellite-street pairs. This benchmark supports multiple tasks, including cross-view VQA, cross-view grounding, and viewpoint identification. CVSBench comprises 3,297 cross-view image groups with 9,468 object-level annotations and 40,679 question-answer (QA) pairs, enabling systematic and controlled evaluation of cross-view spatial reasoning. Extensive evaluations reveal that advanced VLMs struggle to maintain object-level and layout consistency under drastic viewpoint changes. To bridge this gap towards human-like spatial cognition, we investigate two categories of approaches: spatially grounded reasoning and the incorporation of cognitive map inputs. Our findings demonstrate that language-only reasoning yields marginal improvements, while incorporating visual spatial imagination via a 3D scene imagination pipeline substantially improves cross-view reasoning. These results highlight the necessity of explicit visual-spatial representations for robust spatial cognition in VLMs. Our data and code are released at https://huggingface.co/datasets/zlyzlyzly/CVSBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CVSBench, a benchmark using 3,297 satellite-street image groups, 9,468 object annotations, and 40,679 QA pairs to evaluate cross-view spatial reasoning in VLMs via tasks such as cross-view VQA, grounding, and viewpoint identification. Evaluations show VLMs struggle with consistency under viewpoint changes; language-only approaches yield marginal gains while a 3D scene imagination pipeline yields substantial improvements, supporting the conclusion that explicit visual-spatial representations are required for robust spatial cognition. The dataset and code are released.
Significance. If the benchmark tasks require genuine viewpoint-invariant spatial understanding rather than non-spatial patterns, the work would be significant for identifying VLM limitations in spatial reasoning and motivating visual imagination mechanisms, with the public release aiding reproducibility and follow-on research.
major comments (1)
- [Abstract] Abstract: The central claim that the 3D scene imagination pipeline 'substantially improves cross-view reasoning' (and thus demonstrates necessity of explicit visual-spatial representations) rests on CVSBench tasks genuinely measuring cross-view spatial abilities. However, the provided description of the 3,297 image groups and 40,679 QA pairs does not specify controls or validation against non-spatial shortcuts such as object co-occurrence statistics, lighting correlations, or phrasing patterns that could differ systematically by view type.
Simulated Author's Rebuttal
We thank the referee for this constructive comment on the abstract and the underlying validity of the benchmark. We agree that stronger documentation of controls against non-spatial shortcuts is needed to support the central claims and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the 3D scene imagination pipeline 'substantially improves cross-view reasoning' (and thus demonstrates necessity of explicit visual-spatial representations) rests on CVSBench tasks genuinely measuring cross-view spatial abilities. However, the provided description of the 3,297 image groups and 40,679 QA pairs does not specify controls or validation against non-spatial shortcuts such as object co-occurrence statistics, lighting correlations, or phrasing patterns that could differ systematically by view type.
Authors: We acknowledge that the manuscript does not currently provide explicit validation or controls against the listed non-spatial shortcuts. In the revised version we will add a dedicated subsection under 'Benchmark Construction' that details the QA generation protocol: questions were authored to require explicit cross-view object correspondence and layout reasoning (e.g., relative positioning, occlusion, and scale changes that are viewpoint-specific), with multiple annotators and automated checks to avoid view-dependent phrasing or lighting cues. We will also report an ablation in which non-spatial cues are randomized while preserving spatial relations, showing that model accuracy drops substantially, indicating reliance on spatial rather than statistical shortcuts. These additions will directly support the claim that CVSBench measures genuine cross-view spatial abilities. revision: yes
Circularity Check
No circularity: benchmark and empirical results are independent of self-referential fitting
full rationale
The paper introduces CVSBench as a new dataset with satellite-street pairs, annotations, and QA tasks, then reports empirical evaluations of VLMs with and without 3D imagination pipelines. No equations, parameter fittings, or derivations are present. Benchmark construction and performance comparisons do not reduce to self-definitions, fitted inputs renamed as predictions, or load-bearing self-citations. The central claim rests on experimental outcomes that remain falsifiable against external models and data splits, making the work self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems35, 23716– 23736 (2022) 4
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022) 4
2022
-
[2]
In: arxiv (2025) 10
An, X., Xie, Y., Yang, K., et al.: Llava-onevision-1.5: Fully open framework for democratized multimodal training. In: arxiv (2025) 10
2025
-
[3]
In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Azuma, D., Miyanishi, T., Kurita, S., Kawanabe, M.: Scanqa: 3d question answer- ing for spatial scene understanding. In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19129–19139 (2022) 2, 4
2022
-
[4]
arXiv preprint arXiv:2511.21631 (2025) 1, 4, 10, 11
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025) 1, 4, 10, 11
Pith/arXiv arXiv 2025
-
[5]
arXiv preprint arXiv:2502.13923 (2025) 1, 10
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., et al.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 1, 10
Pith/arXiv arXiv 2025
-
[6]
International Research in Geographical and environmental education28(4), 262–280 (2019) 2, 4, 9
Bednarz, R., Lee, J.: What improves spatial thinking? evidence from the spatial thinking abilities test. International Research in Geographical and environmental education28(4), 262–280 (2019) 2, 4, 9
2019
-
[7]
arXiv preprint arXiv:2308.06595 (2023) 7
Bitton, Y., Bansal, H., Hessel, J., Shao, R., Zhu, W., Awadalla, A., Gardner, J., Taori, R., Schmidt, L.: Visit-bench: A benchmark for vision-language instruction following inspired by real-world use. arXiv preprint arXiv:2308.06595 (2023) 7
arXiv 2023
-
[8]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Cai, W., Ponomarenko, I., Yuan, J., Li, X., Yang, W., Dong, H., Zhao, B.: Spa- tialbot: Precise spatial understanding with vision language models. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 9490–9498. IEEE (2025) 10
2025
-
[9]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Chen, B., Xu, Z., Kirmani, S., Ichter, B., Sadigh, D., Guibas, L., Xia, F.: Spa- tialvlm: Endowing vision-language models with spatial reasoning capabilities. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 14455–14465 (2024) 1, 3, 4, 10
2024
-
[10]
Advances in Neural Information Processing Systems37, 135062–135093 (2024) 1, 3, 4, 7
Cheng, A.C., Yin, H., Fu, Y., Guo, Q., Yang, R., Kautz, J., Wang, X., Liu, S.: Spatialrgpt: Grounded spatial reasoning in vision-language models. Advances in Neural Information Processing Systems37, 135062–135093 (2024) 1, 3, 4, 7
2024
-
[11]
arXiv preprint arXiv:2507.06261 (2025) 1, 6, 8, 9
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025) 1, 6, 8, 9
Pith/arXiv arXiv 2025
-
[12]
Advances in neural information processing systems36, 49250–49267 (2023) 4 16 Ruixun Liu et al
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in neural information processing systems36, 49250–49267 (2023) 4 16 Ruixun Liu et al
2023
-
[13]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ding,X.,Han,J.,Xu,H.,Liang,X.,Zhang,W.,Li,X.:Holisticautonomousdriving understanding by bird’s-eye-view injected multi-modal large models. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13668–13677 (2024) 2
2024
-
[14]
arXiv preprint arXiv:2306.13394 (2023) 4, 7
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., et al.: Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394 (2023) 4, 7
Pith/arXiv arXiv 2023
-
[15]
In: European Conference on Computer Vision
Fu, X., Hu, Y., Li, B., Feng, Y., Wang, H., Lin, X., Roth, D., Smith, N.A., Ma, W.C., Krishna, R.: Blink: Multimodal large language models can see but not per- ceive. In: European Conference on Computer Vision. pp. 148–166. Springer (2024) 4, 7
2024
-
[16]
arXiv preprint arXiv:2509.06266 (2025) 2
Gholami, M., Rezaei, A., Weimin, Z., Mao, S., Zhou, S., Zhang, Y., Akbari, M.: Spatial reasoning with vision-language models in ego-centric multi-view scenes. arXiv preprint arXiv:2509.06266 (2025) 2
arXiv 2025
-
[17]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., et al.: Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14375–14385 (2024) 4
2024
-
[18]
Advances in Neural Information Processing Systems36, 20482–20494 (2023) 4
Hong, Y., Zhen, H., Chen, P., Zheng, S., Du, Y., Chen, Z., Gan, C.: 3d-llm: In- jecting the 3d world into large language models. Advances in Neural Information Processing Systems36, 20482–20494 (2023) 4
2023
-
[19]
ISPRS Journal of Photogrammetry and Remote Sensing224, 272–286 (2025) 5, 7
Hu, Y., Yuan, J., Wen, C., Lu, X., Liu, Y., Li, X.: Rsgpt: A remote sensing vision language model and benchmark. ISPRS Journal of Photogrammetry and Remote Sensing224, 272–286 (2025) 5, 7
2025
-
[20]
arXiv preprint arXiv:2410.21276 (2024) 1, 4, 10
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024) 1, 4, 10
Pith/arXiv arXiv 2024
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ji, Y., Tan, H., Shi, J., Hao, X., Zhang, Y., Zhang, H., Wang, P., Zhao, M., Mu, Y., An, P., et al.: Robobrain: A unified brain model for robotic manipulation from abstract to concrete. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1724–1734 (2025) 2, 4
2025
-
[22]
arXiv preprint arXiv:2506.03135 (2025) 2, 4, 7
Jia, M., Qi, Z., Zhang, S., Zhang, W., Yu, X., He, J., Wang, H., Yi, L.: Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models. arXiv preprint arXiv:2506.03135 (2025) 2, 4, 7
arXiv 2025
-
[23]
Cognitive science4(1), 71–115 (1980) 4
Johnson-Laird, P.N.: Mental models in cognitive science. Cognitive science4(1), 71–115 (1980) 4
1980
-
[24]
49–54 (2025) 10
Khandoga, M., Kostiuk, Y., Polishko, A., Kozlov, K., Filipchuk, Y., Kiulian, A.: Framing the language: Fine-tuning gemma 3 for manipulation detection pp. 49–54 (2025) 10
2025
-
[25]
arXiv preprint arXiv:2406.09246 (2024) 5
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024) 5
Pith/arXiv arXiv 2024
-
[26]
Kuckreja, K., Danish, M.S., Naseer, M., Das, A., Khan, S., Khan, F.S.: Geochat: Grounded large vision-language model for remote sensing (2023) 10
2023
-
[27]
Journal of geography111(1), 15–26 (2012) 4, 9
Lee, J., Bednarz, R.: Components of spatial thinking: Evidence from a spatial thinking ability test. Journal of geography111(1), 15–26 (2012) 4, 9
2012
-
[28]
Lee, P.Y., Je, J., Park, C., Uy, M.A., Guibas, L., Sung, M.: Perspective-aware reasoninginvision-languagemodelsviamentalimagerysimulation.In:Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9241–9251 (2025) 2, 3, 4 CVSBench 17
2025
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, B., Ge, Y., Ge, Y., Wang, G., Wang, R., Zhang, R., Shan, Y.: Seed- bench: Benchmarking multimodal large language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13299– 13308 (2024) 7
2024
-
[30]
arXiv preprint arXiv:2505.21500 (2025) 2
Li, D., Li, H., Wang, Z., Yan, Y., Zhang, H., Chen, S., Hou, G., Jiang, S., Zhang, W., Shen, Y., et al.: Viewspatial-bench: Evaluating multi-perspective spatial local- ization in vision-language models. arXiv preprint arXiv:2505.21500 (2025) 2
arXiv 2025
-
[31]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023) 4
2023
-
[32]
Advances in Neural Information Processing Systems37, 3229–3242 (2024) 5, 7
Li, X., Ding, J., Elhoseiny, M.: Vrsbench: A versatile vision-language benchmark dataset for remote sensing image understanding. Advances in Neural Information Processing Systems37, 3229–3242 (2024) 5, 7
2024
-
[33]
In: Proceedings of the 2023 conference on empirical methods in natural language processing
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.R.: Evaluating object hal- lucination in large vision-language models. In: Proceedings of the 2023 conference on empirical methods in natural language processing. pp. 292–305 (2023) 4
2023
-
[34]
2: Pushing the frontier of open large language models (2025) 10
Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., et al.: Deepseek-v3. 2: Pushing the frontier of open large language models (2025) 10
2025
-
[35]
Transactions of the Association for Computational Linguistics11, 635–651 (2023) 1, 4, 7
Liu, F., Emerson, G., Collier, N.: Visual spatial reasoning. Transactions of the Association for Computational Linguistics11, 635–651 (2023) 1, 4, 7
2023
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tun- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024) 4
2024
-
[37]
Advances in neural information processing systems36, 34892–34916 (2023) 4
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023) 4
2023
-
[38]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? In: European conference on computer vision. pp. 216–233. Springer (2024) 7
2024
-
[39]
IEEE Transactions on Geoscience and Remote Sensing 58(12), 8555–8566 (2020) 5, 7
Lobry, S., Marcos, D., Murray, J., Tuia, D.: Rsvqa: Visual question answering for remote sensing data. IEEE Transactions on Geoscience and Remote Sensing 58(12), 8555–8566 (2020) 5, 7
2020
-
[40]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ma, W., Chen, H., Zhang, G., Chou, Y.C., Chen, J., de Melo, C., Yuille, A.: 3dsr- bench: A comprehensive 3d spatial reasoning benchmark. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6924–6934 (2025) 4, 7
2025
-
[41]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Mitra, C., Huang, B., Darrell, T., Herzig, R.: Compositional chain-of-thought prompting for large multimodal models. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 14420–14431 (2024) 4
2024
-
[42]
In: European Conference on Computer Vision
Muhtar, D., Li, Z., Gu, F., Zhang, X., Xiao, P.: Lhrs-bot: Empowering remote sens- ing with vgi-enhanced large multimodal language model. In: European Conference on Computer Vision. pp. 440–457. Springer (2024) 5, 7
2024
-
[43]
In: Studying visual and spatial reasoning for design creativity, pp
Newcombe, N.S., Shipley, T.F.: Thinking about spatial thinking: New typology, new assessments. In: Studying visual and spatial reasoning for design creativity, pp. 179–192. Springer (2014) 2, 4, 9
2014
-
[44]
Ramakrishnan, S.K., Wijmans, E., Kraehenbuehl, P., Koltun, V.: Does spatial cognition emerge in frontier models? arXiv preprint arXiv:2410.06468 (2024) 4
arXiv 2024
-
[45]
arXiv preprint arXiv:2402.03300 (2024) 9 18 Ruixun Liu et al
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024) 9 18 Ruixun Liu et al
Pith/arXiv arXiv 2024
-
[46]
arXiv preprint arXiv:2601.03267 (2025) 10
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025) 10
Pith/arXiv arXiv 2025
-
[47]
In: European Conference on Computer Vision
Szymańska, E., Dusmanu, M., Buurlage, J.W., Rad, M., Pollefeys, M.: Space3d- bench: Spatial 3d question answering benchmark. In: European Conference on Computer Vision. pp. 68–85. Springer (2024) 2
2024
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Toker, A., Zhou, Q., Maximov, M., Leal-Taixé, L.: Coming down to earth: Satellite- to-street view synthesis for geo-localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6488–6497 (2021) 2, 5
2021
-
[49]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tong, S., Liu, Z., Zhai, Y., Ma, Y., LeCun, Y., Xie, S.: Eyes wide shut? exploring the visual shortcomings of multimodal llms. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9568–9578 (2024) 4
2024
-
[50]
arXiv preprint arXiv:2409.12191 (2024) 4
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024) 4
Pith/arXiv arXiv 2024
-
[51]
5: Advancing open-source multimodal models in versatility, reasoning, and efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025) 1, 10
Pith/arXiv arXiv 2025
-
[52]
Wang, Y., Liu, Z., Wang, Z., Hu, H., Liu, P., Rao, Y.: Geovista: Web-augmented agenticvisualreasoningforgeolocalization.arXivpreprintarXiv:2511.15705(2025) 2, 5
arXiv 2025
-
[53]
arXiv preprint arXiv:2308.08769 (2023) 4
Wang, Z., Huang, H., Zhao, Y., Zhang, Z., Zhao, Z.: Chat-3d: Data-efficiently tuning large language model for universal dialogue of 3d scenes. arXiv preprint arXiv:2308.08769 (2023) 4
arXiv 2023
-
[54]
In: Proceedings of the IEEE International Conference on Com- puter Vision
Workman, S., Souvenir, R., Jacobs, N.: Wide-area image geolocalization with aerial reference imagery. In: Proceedings of the IEEE International Conference on Com- puter Vision. pp. 3961–3969 (2015) 6
2015
-
[55]
arXiv preprint arXiv:2505.23747 (2025) 4
Wu, D., Liu, F., Hung, Y.H., Duan, Y.: Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence. arXiv preprint arXiv:2505.23747 (2025) 4
Pith/arXiv arXiv 2025
-
[56]
Wu, J., Guan, J., Feng, K., Liu, Q., Wu, S., Wang, L., Wu, W., Tan, T.: Reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing (2025) 10
2025
-
[57]
Advances in Neural Information Processing Systems37, 90277–90317 (2024) 3
Wu, W., Mao, S., Zhang, Y., Xia, Y., Dong, L., Cui, L., Wei, F.: Mind’s eye of llms: visualization-of-thought elicits spatial reasoning in large language models. Advances in Neural Information Processing Systems37, 90277–90317 (2024) 3
2024
-
[58]
arXiv preprint arXiv:2601.14339 (2026) 5
Xu, H., Hu, Y., Zhu, Z., Gao, C., Wang, Z., Rao, J., Lu, W., Li, W., Yin, Q., Li, Y.: Citycube: Benchmarking cross-view spatial reasoning on vision-language models in urban environments. arXiv preprint arXiv:2601.14339 (2026) 5
arXiv 2026
-
[59]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xu,Y.,Zhu,L.,Yang,Y.:Mc-bench:Abenchmarkformulti-contextvisualground- ing in the era of mllms. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17675–17687 (2025) 7
2025
-
[60]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Yang, J., Yang, S., Gupta, A.W., Han, R., Fei-Fei, L., Xie, S.: Thinking in space: How multimodal large language models see, remember, and recall spaces. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 10632– 10643 (2025) 2, 4, 7
2025
-
[61]
Advances in Neural Information Processing Systems37, 21875–21911 (2024) 9
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. Advances in Neural Information Processing Systems37, 21875–21911 (2024) 9
2024
-
[62]
arXiv preprint arXiv:2506.17218 (2025) 3 CVSBench 19
Yang, Z., Yu, X., Chen, D., Shen, M., Gan, C.: Machine mental imagery: Empower multimodal reasoning with latent visual tokens. arXiv preprint arXiv:2506.17218 (2025) 3 CVSBench 19
Pith/arXiv arXiv 2025
-
[63]
In: Structural Priors for Vision Workshop at ICCV’25 (2025) 2, 4, 7
Yin, B., Wang, Q., Zhang, P., Zhang, J., Wang, K., Wang, Z., Zhang, J., Chan- drasegaran, K., Liu, H., Krishna, R., et al.: Spatial mental modeling from limited views. In: Structural Priors for Vision Workshop at ICCV’25 (2025) 2, 4, 7
2025
-
[64]
arXiv preprint arXiv:2509.18905 (2025) 1, 2, 4, 7
Yu, S., Chen, Y., Ju, H., Jia, L., Zhang, F., Huang, S., Wu, Y., Cui, R., Ran, B., Zhang, Z., et al.: How far are vlms from visual spatial intelligence? a benchmark- driven perspective. arXiv preprint arXiv:2509.18905 (2025) 1, 2, 4, 7
arXiv 2025
-
[65]
arXiv preprint arXiv:2406.10721 (2024) 5
Yuan, W., Duan, J., Blukis, V., Pumacay, W., Krishna, R., Murali, A., Mousavian, A., Fox, D.: Robopoint: A vision-language model for spatial affordance prediction for robotics. arXiv preprint arXiv:2406.10721 (2024) 5
arXiv 2024
-
[66]
IEEE transactions on geoscience and remote sensing 61, 1–13 (2023) 5, 7
Zhan, Y., Xiong, Z., Yuan, Y.: Rsvg: Exploring data and models for visual ground- ing on remote sensing data. IEEE transactions on geoscience and remote sensing 61, 1–13 (2023) 5, 7
2023
-
[67]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, L., Zhai, X., Zhao, Z., Zong, Y., Wen, X., Zhao, B.: What if the tv was off? examining counterfactual reasoning abilities of multi-modal language mod- els. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21853–21862 (2024) 3
2024
-
[68]
arXiv preprint arXiv:2302.00923 (2023) 4
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., Smola, A.: Multimodal chain- of-thought reasoning in language models. arXiv preprint arXiv:2302.00923 (2023) 4
Pith/arXiv arXiv 2023
-
[69]
In: Proceedings of the 28th ACM interna- tional conference on Multimedia
Zheng, Z., Wei, Y., Yang, Y.: University-1652: A multi-view multi-source bench- mark for drone-based geo-localization. In: Proceedings of the 28th ACM interna- tional conference on Multimedia. pp. 1395–1403 (2020) 6
2020
-
[70]
arXiv preprint arXiv:2409.18125 (2024) 5
Zhu, C., Wang, T., Zhang, W., Pang, J., Liu, X.: Llava-3d: A simple yet effective pathway to empowering lmms with 3d-awareness. arXiv preprint arXiv:2409.18125 (2024) 5
arXiv 2024
-
[71]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhu, S., Yang, T., Chen, C.: Vigor: Cross-view image geo-localization beyond one- to-one retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3640–3649 (2021) 2, 5
2021
-
[72]
sample_id
Zhu, Z., Wang, X., Li, Y., Zhang, Z., Ma, X., Chen, Y., Jia, B., Liang, W., Yu, Q., Deng, Z., et al.: Move to understand a 3d scene: Bridging visual grounding and exploration for efficient and versatile embodied navigation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8120–8132 (2025) 2 20 Ruixun Liu et al. A Dataset Co...
2025
-
[73]
distance_to_camera
“distance_to_camera” 2) “building_footprint_area” 3) “build- ing_connection” 4) “roof_form” ========================================= QUESTION COUNT Generate EXACTLY 3 questions per image pair. If distance/area cannot meet EXTREME-ONLY rule -> do NOT force them. Use roof_form and/or building_connection instead. ========================================= MU...
-
[74]
========================================= CATEGORY RULES
vegetation_sector 2) occlusion_binary 3) relative_position 4) height_comparison 5) facade_color 6) ground_material ========================================= TARGET DEFINITION REQUIREMENT (CRITICAL) Every target MUST be: - clearly identifiable in satellite - uniquely disam- biguated using satellite-only cues such as: distance to camera, alignment with the ...
-
[75]
What is the domi- nant vegetation type in the [sector] along the arrow direction?
vegetation_sector (4 options) Question template: “What is the domi- nant vegetation type in the [sector] along the arrow direction?” Options EXACTLY: A) Trees B) Shrubs / bushes C) Grass / lawn D) No obvious vegetation
-
[76]
Is [satellite- defined target] occluded in Street-View?
occlusion_binary (2 options ONLY) Question template: “Is [satellite- defined target] occluded in Street-View?” Options EXACTLY: A) Oc- cluded (blocked) B) Not occluded (clear view)
-
[77]
Facing forward (the arrow direction), where does [satellite-defined target] appear in Street-View?
relative_position (4 options) Question template EXACTLY: “Facing forward (the arrow direction), where does [satellite-defined target] appear in Street-View?” Options EXACTLY: A) Left side B) Right side C) Near the center (mostly straight ahead) D) Not visible in the forward view
-
[78]
Com- pare the heights of (1) [Building A defined by satellite geometry] and (2) [Building B defined by satellite geometry]. Which is taller in Street- View?
height_comparison (4 options, STRICT) Question template: “Com- pare the heights of (1) [Building A defined by satellite geometry] and (2) [Building B defined by satellite geometry]. Which is taller in Street- View?” Options EXACTLY: A) The first building is taller B) The second building is taller C) They are about the same height D) Only one of them is vi...
-
[79]
What is the domi- nant ground material in the forward sector along the arrow direction?
ground_material (4 options) Question template: “What is the domi- nant ground material in the forward sector along the arrow direction?” Options EXACTLY: A) Asphalt B) Concrete C) Grass D) Bare soil / dirt ========================================= FINAL VALIDITY CHECK (MANDATORY) For EACH question verify ALL: 1) Target is uniquely localizable using satell...
-
[80]
I stand at the satellite center and face the TOP of the satellite image
Correct answer is determined by checking Street-View. 4) Street-View clearly confirms the correct option. If ANY check fails -> DISCARD that question. 30 Ruixun Liu et al. S2G-CVUSA Prompt.The CVUSA S2G prompt uses the same general logic as the FOV version, but replaces the observation-arrow geometry with a fixed panorama mapping centered at the satellite...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.