SeFi-Image: A Text-to-Image Foundation Model with Semantic-First Diffusion
Pith reviewed 2026-06-29 05:17 UTC · model grok-4.3
The pith
Semantic-first diffusion lets a 5B text-to-image model match or exceed prior models after training on only 10-20 percent of the usual compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
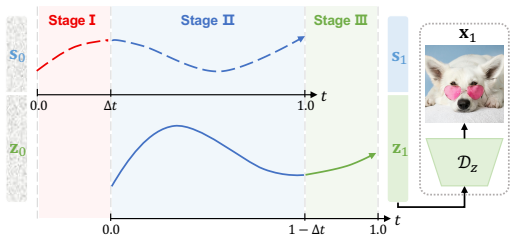
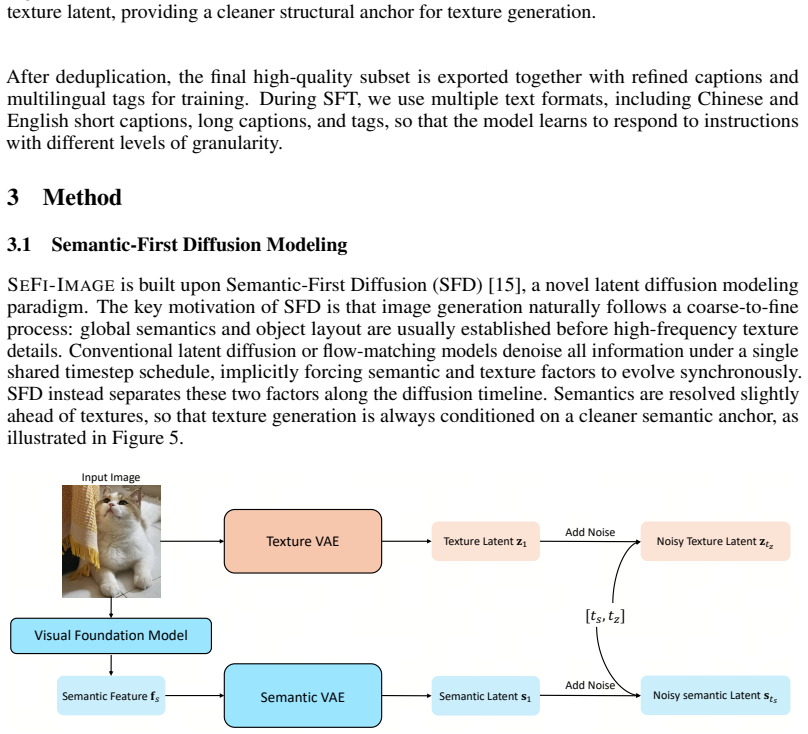
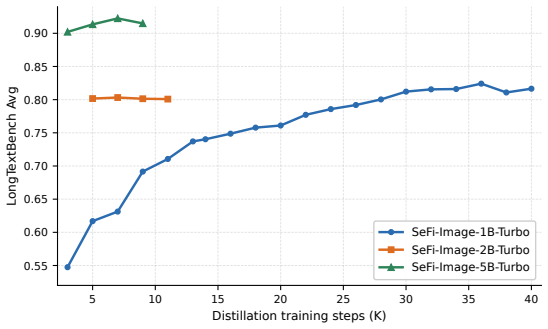
SeFi-Image is a text-to-image foundation model built on semantic-first diffusion, a latent diffusion paradigm that prioritizes semantic guidance. Instantiated at 1B, 2B, and 5B parameters, the 5B model was trained with 125K A800 GPU hours—roughly 10-20 percent of the compute used by Z-Image—yet produces results comparable or superior to Qwen-Image and Z-Image across standard benchmarks. Distilled DMD2 few-step variants are provided for each scale to support varied deployment constraints.
What carries the argument
semantic-first diffusion, a latent diffusion modeling paradigm that structures the generation process around semantic guidance to accelerate training and improve efficiency at scale.
If this is right
- Three model scales allow deployment choices matched to different compute budgets.
- DMD2-distilled few-step variants reduce inference latency while preserving the base performance.
- Public release of code and weights supplies ready-to-use options for text-to-image generation.
- The scaling study supplies data on how semantic guidance behaves as parameter count grows from 1B to 5B.
Where Pith is reading between the lines
- If the efficiency pattern holds, organizations with modest hardware budgets could train competitive text-to-image models without relying on the largest industrial clusters.
- The same semantic-first ordering might be tested on video or 3D generation to check whether the compute savings transfer to other modalities.
- Further work could measure exactly how much of the reported gain comes from the semantic ordering versus other training details such as data curation or optimizer choices.
Load-bearing premise
The efficiency and performance gains from semantic guidance will continue when the method is applied to large models on complex, high-resolution data rather than the small-scale simple datasets used in earlier tests.
What would settle it
Training an otherwise identical 5B model without the semantic-first component on the same 125K GPU-hour budget and showing that it matches or exceeds SeFi-Image on the reported benchmarks.
Figures










read the original abstract
Training image generation foundation models consumes substantial resources. Previous methods have attempted to leverage semantic guidance to accelerate the training process, yet their experiments were only conducted on simple datasets such as ImageNet, at low resolutions, and with small-scale models. In this paper, we propose SeFi-Image, a text-to-image foundation model built upon semantic-first diffusion, a novel latent diffusion modeling paradigm. We instantiate SeFi-Image at three model scales, 1B, 2B, and 5B parameters, enabling systematic study of scaling behavior and flexible deployment under varying compute budgets. Notably, our largest 5B model was trained with merely 125K A800 GPU hours, corresponding to roughly 10-20% of the training compute used by Z-Image. However, it achieves results comparable to or even superior to Qwen-Image and Z-Image. Despite this modest training compute, SeFi-Image achieves strong performance on a wide range of benchmarks, including GenEval, DPG, LongTextBench, OneIG, and CVTG-2K. Moreover, we provide DMD2-distilled few-step turbo variants for each model scale to accommodate diverse hardware constraints and latency requirements. We publicly release our code, weights and hope this work offers the community useful insights into semantic-guided diffusion modeling for T2I generation, while also providing practical and readily deployable model options.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SeFi-Image, a text-to-image foundation model based on semantic-first diffusion. It describes instantiating the approach at 1B, 2B, and 5B parameter scales, with the 5B model trained using only 125K A800 GPU hours (claimed 10-20% of Z-Image compute) while achieving comparable or superior results to Z-Image and Qwen-Image on benchmarks including GenEval, DPG, LongTextBench, OneIG, and CVTG-2K. The work also provides DMD2-distilled few-step variants and publicly releases code and weights.
Significance. If the efficiency and performance claims hold, the semantic-first diffusion paradigm could meaningfully reduce the compute required for high-quality T2I foundation models at billion-parameter scale. The explicit release of code, weights, and turbo variants is a concrete strength that supports reproducibility and deployment.
major comments (2)
- [Abstract] Abstract: the claim that the 5B model achieves results 'comparable to or even superior' to Z-Image and Qwen-Image with 10-20% of the training compute is load-bearing for the central contribution, yet the provided text supplies no scaling curves, ablations on semantic guidance at 5B scale, or quantitative comparison tables that would allow evaluation of whether the efficiency multiplier transfers from prior ImageNet experiments.
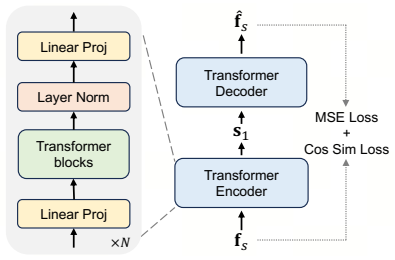
- [Abstract] Abstract: the manuscript states that prior semantic-guidance experiments were limited to ImageNet, low resolution, and small models, but presents the 5B T2I result as direct evidence of successful scaling without any description of the conditioning injection mechanism, loss formulation, or architecture diagram for the latent diffusion backbone at this scale.
minor comments (1)
- The abstract refers to a 'systematic study of scaling behavior' across the three model sizes but does not list the specific metrics or protocols used for that study.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on strengthening the abstract's support for the central claims. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the 5B model achieves results 'comparable to or even superior' to Z-Image and Qwen-Image with 10-20% of the training compute is load-bearing for the central contribution, yet the provided text supplies no scaling curves, ablations on semantic guidance at 5B scale, or quantitative comparison tables that would allow evaluation of whether the efficiency multiplier transfers from prior ImageNet experiments.
Authors: We agree the abstract is concise and will revise it to explicitly reference the benchmark results (GenEval, DPG, LongTextBench, OneIG, CVTG-2K) and scaling observations across 1B/2B/5B scales presented in Sections 4 and 5. The manuscript body contains the quantitative comparison tables. We will also add discussion clarifying how the efficiency gains observed at smaller scales transfer. However, dedicated scaling curves and 5B-scale ablations on the semantic guidance component were not performed. revision: partial
-
Referee: [Abstract] Abstract: the manuscript states that prior semantic-guidance experiments were limited to ImageNet, low resolution, and small models, but presents the 5B T2I result as direct evidence of successful scaling without any description of the conditioning injection mechanism, loss formulation, or architecture diagram for the latent diffusion backbone at this scale.
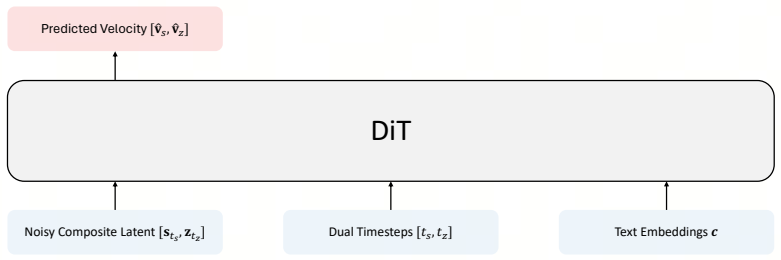
Authors: The abstract is high-level by design. Section 3 of the manuscript details the semantic-first diffusion paradigm, including the conditioning injection mechanism (semantic feature cross-attention), loss formulation, and the latent diffusion backbone architecture (with diagram in Figure 2), which applies at all scales including 5B. We will revise the abstract to include a concise reference to these elements. revision: yes
- We did not perform scaling curves or ablations on semantic guidance at the 5B scale, as these were outside the scope of the original experiments and additional runs at this scale are not feasible due to compute cost.
Circularity Check
No circularity: empirical efficiency claim stands on reported training outcomes without reduction to fitted inputs or self-citation chains.
full rationale
The paper's central claim is an empirical report of training a 5B-parameter model in 125K A800 GPU hours while matching or exceeding baselines on GenEval, DPG, and other benchmarks. The abstract introduces semantic-first diffusion as a novel paradigm but supplies no equations, scaling derivations, or self-citations that would make the efficiency multiplier equivalent to its inputs by construction. Prior semantic-guidance work is cited only as motivation for the new experiments; the 5B result is presented as a direct training outcome rather than a prediction derived from small-scale fits. No load-bearing step reduces to self-definition, fitted-input renaming, or imported uniqueness theorems. The derivation chain is therefore self-contained as an empirical demonstration.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[2]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InProceedings of the 41st Internatio...
2024
-
[3]
Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding, 2022
2022
-
[4]
Seedream 3.0 technical report, 2025
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, et al. Seedream 3.0 technical report, 2025
2025
-
[5]
Seedream 4.0: Toward next-generation multimodal image generation, 2025
Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, Xiaowen Jian, et al. Seedream 4.0: Toward next-generation multimodal image generation, 2025
2025
-
[6]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report, 2025
2025
-
[7]
Z-image: An efficient image generation foundation model with single-stream diffusion transformer, 2025
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Shijie Huang, Zhaohui Hou, Dengyang Jiang, Xin Jin, Liangchen Li, Zhen Li, Zhong-Yu Li, David Liu, Dongyang Liu, Junhan Shi, Qilong Wu, Feng Yu, Chi Zhang, Shifeng Zhang, and Shilin Zhou. Z-image: An efficient image generation foundation model with single-stream diffusion transformer, 2025
2025
-
[8]
Hunyuanimage 3.0 technical report, 2025
Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, Xinchi Deng, Ying Dong, Kipper Gong, Tianpeng Gu, Xiusen Gu, et al. Hunyuanimage 3.0 technical report, 2025
2025
-
[9]
Longcat-image technical report, 2025
Hanghang Ma, Haoxian Tan, Jiale Huang, Junqiang Wu, Jun-Yan He, Lishuai Gao, Songlin Xiao, Xiaoming Wei, Xiaoqi Ma, Xunliang Cai, Yayong Guan, and Jie Hu. Longcat-image technical report, 2025
2025
-
[10]
Diffusion transformers with representation autoencoders, 2025
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders, 2025
2025
-
[11]
Representation alignment for generation: Training diffusion transformers is easier than you think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. InInternational Conference on Learning Representations, 2025
2025
-
[12]
Reconstruction vs
Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming opti- mization dilemma in latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[13]
Boosting generative image modeling via joint image-feature synthesis.Advances in Neural Information Processing Systems, 38:16685–16714, 2026
Theodoros Kouzelis, Efstathios Karypidis, Ioannis Kakogeorgiou, Spyridon Gidaris, and Nikos Komodakis. Boosting generative image modeling via joint image-feature synthesis.Advances in Neural Information Processing Systems, 38:16685–16714, 2026
2026
-
[14]
Representation entanglement for gen- eration: Training diffusion transformers is much easier than you think.Advances in Neural Information Processing Systems, 38:7714–7743, 2026
Ge Wu, Shen Zhang, Ruijing Shi, Shanghua Gao, Zhenyuan Chen, Lei Wang, Zhaowei Chen, Hongcheng Gao, Yao Tang, Ming-Ming Cheng, et al. Representation entanglement for gen- eration: Training diffusion transformers is much easier than you think.Advances in Neural Information Processing Systems, 38:7714–7743, 2026
2026
-
[15]
Semantics lead the way: Harmonizing semantic and texture modeling with asynchronous latent diffusion, 2025
Yueming Pan, Ruoyu Feng, Qi Dai, Yuqi Wang, Wenfeng Lin, Mingyu Guo, Chong Luo, and Nanning Zheng. Semantics lead the way: Harmonizing semantic and texture modeling with asynchronous latent diffusion, 2025. 24
2025
-
[16]
GANs trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium. InAdvances in Neural Information Processing Systems, 2017
2017
-
[17]
Berg, and Li Fei-Fei
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet large scale visual recognition challenge.International Journal of Computer Vision, 115(3):211–252, 2015
2015
-
[18]
Shengbang Tong, Boyang Zheng, Ziteng Wang, Bingda Tang, Nanye Ma, Ellis Brown, Jihan Yang, Rob Fergus, Yann LeCun, and Saining Xie. Scaling text-to-image diffusion transformers with representation autoencoders.arXiv preprint arXiv:2601.16208, 2026
-
[19]
Minglei Shi, Haolin Wang, Borui Zhang, Wenzhao Zheng, Bohan Zeng, Ziyang Yuan, Xiaoshi Wu, Yuanxing Zhang, Huan Yang, Xintao Wang, et al. Svg-t2i: Scaling up text-to-image latent diffusion model without variational autoencoder.arXiv preprint arXiv:2512.11749, 2025
-
[20]
GenEval: An object-focused framework for evaluating text-to-image alignment, 2023
Dhruba Ghosh, Hanna Hajishirzi, and Ludwig Schmidt. GenEval: An object-focused framework for evaluating text-to-image alignment, 2023
2023
-
[21]
ELLA: Equip diffusion models with LLM for enhanced semantic alignment, 2024
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. ELLA: Equip diffusion models with LLM for enhanced semantic alignment, 2024
2024
-
[22]
X-Omni: Reinforcement learning makes discrete autoregressive image generative models great again, 2025
Zigang Geng, Yibing Wang, Yeyao Ma, Chen Li, Yongming Rao, Shuyang Gu, Zhao Zhong, Qinglin Lu, Han Hu, Xiaosong Zhang, Linus, and Di Wang. X-Omni: Reinforcement learning makes discrete autoregressive image generative models great again, 2025
2025
-
[23]
OneIG-Bench: Omni-dimensional nuanced evaluation for image generation, 2025
Jingjing Chang, Yixiao Fang, Peng Xing, Shuhan Wu, Wei Cheng, Rui Wang, Xianfang Zeng, Gang Yu, and Hai-Bao Chen. OneIG-Bench: Omni-dimensional nuanced evaluation for image generation, 2025
2025
-
[24]
Investigating text insulation and attention mechanisms for complex visual text generation, 2025
Ying Tai, Nikai Du, Rui Xie, Zhennan Chen, Qian Wang, Zhengkai Jiang, Kai Zhang, and Jian Yang. Investigating text insulation and attention mechanisms for complex visual text generation, 2025
2025
-
[25]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5
2026
-
[26]
Improving image generation with better captions, 2023
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, Wesam Manassra, Prafulla Dhariwal, Casey Chu, Yunxin Jiao, and Aditya Ramesh. Improving image generation with better captions, 2023. URL https://cdn.openai.com/papers/dall-e-3.pdf
2023
-
[27]
Lens: Rethinking Training Efficiency for Foundational Text-to-Image Models
Dong Chen, Fangyun Wei, Ziyu Wan, Dongdong Chen, Jiawei Zhang, Jinjing Zhao, Sirui Zhang, Yang Yue, Zhiyang Liang, Baining Guo, et al. Lens: Rethinking training efficiency for foundational text-to-image models.arXiv preprint arXiv:2605.21573, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Fine-T2I: An open, large-scale, and diverse dataset for high-quality T2I fine-tuning, 2026
Xu Ma, Yitian Zhang, Qihua Dong, and Yun Fu. Fine-T2I: An open, large-scale, and diverse dataset for high-quality T2I fine-tuning, 2026
2026
-
[29]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jégou, Julien Mairal, Patric...
2024
-
[30]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, et al. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[31]
FLUX.2: Frontier visual intelligence
Black Forest Labs. FLUX.2: Frontier visual intelligence. https://bfl.ai/blog/flux-2, 2025. 25
2025
-
[32]
FLUX.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. FLUX.https://github.com/black-forest-labs/flux, 2024
2024
-
[33]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[34]
Qwen3-VL technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, et al. Qwen3-VL technical report, 2025
2025
-
[35]
SVG: Latent diffusion model without variational autoencoder.arXiv:2510.15301, 2025
Minglei Shi, Haolin Wang, Wenzhao Zheng, Ziyang Yuan, Xiaoshi Wu, Xintao Wang, Pengfei Wan, Jie Zhou, and Jiwen Lu. Latent diffusion model without variational autoencoder, 2025. URLhttps://arxiv.org/abs/2510.15301
-
[36]
Qwen-Image-V AE-2.0 technical report, 2026
Zekai Zhang, Deqing Li, Kuan Cao, Yujia Wu, Chenfei Wu, Yu Wu, Liang Peng, Hao Meng, Jiahao Li, Jie Zhang, et al. Qwen-Image-V AE-2.0 technical report, 2026
2026
-
[37]
Kodak lossless true color image suite.http://r0k.us/graphics/ kodak/, 1993
Eastman Kodak Company. Kodak lossless true color image suite.http://r0k.us/graphics/ kodak/, 1993
1993
-
[38]
Bovik, Hamid R
Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. Image quality assessment: From error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4): 600–612, 2004
2004
-
[39]
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T. Freeman. Improved distribution matching distillation for fast image synthesis, 2024
2024
-
[40]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Awaking spatial intelligence in unified multimodal understanding and generation, 2026
Lin Song, Wenbo Li, Guoqing Ma, Wei Tang, Bo Wang, Yuan Zhang, Yijun Yang, Yicheng Xiao, Jianhui Liu, Yanbing Zhang, Guohui Zhang, Wenhu Zhang, Hang Xu, Nan Jiang, Xin Han, Haoze Sun, Maoquan Zhang, Haoyang Huang, and Nan Duan. Awaking spatial intelligence in unified multimodal understanding and generation, 2026
2026
-
[42]
CLIPScore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIPScore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021. 26 A Additional Related Work Foundational text-to-image models.Recent text-to-image foundation models have made substan...
2021
-
[43]
Produce: - short_caption: concise and high-signal - dense_caption: complete, specific, and concise
-
[44]
Cover the main subjects, main action or state, main scene, key spatial relations, reliable counts, and clearly visible attributes when important
-
[45]
short_caption must retain the core facts from dense_caption, especially the main subject, main action or state, main scene, and key count, OCR, or abnormal details when present
-
[46]
Use cautious wording when details are uncertain because of blur, occlusion, crop, low resolution, overexposure, or partial visibility
-
[47]
Use viewer perspective consistently for spatial relations such as left, right, top, bottom, front, and behind
-
[48]
dense_caption should be objective and natural, without marketing language, storytelling, or aesthetic praise
-
[49]
short_caption
If legible text exists in the image, put quoted visible text in double quotes. Output strict JSON only: { "short_caption": { "en": "...", "zh": "..." }, "dense_caption": { "en": "...", "zh": "..." } } B.2 SFT Metadata and Caption Prompts For supervised fine-tuning data, we use a two-stage VLM annotation workflow. The first prompt extracts structured metad...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.