MapReason-OSM: Can Vision-Language Models Make Graph-Verifiable Mobility Decisions from Street Maps ?
Pith reviewed 2026-06-26 11:06 UTC · model grok-4.3
The pith
Vision-language models succeed at simple map routing but fail at graph cost reasoning and cross-scale consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
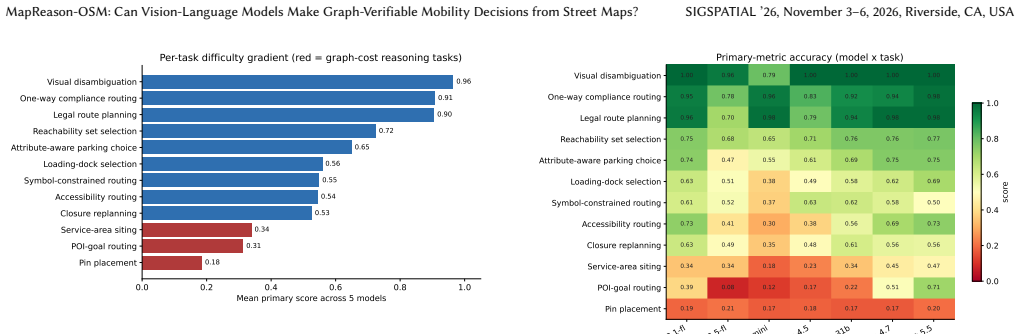
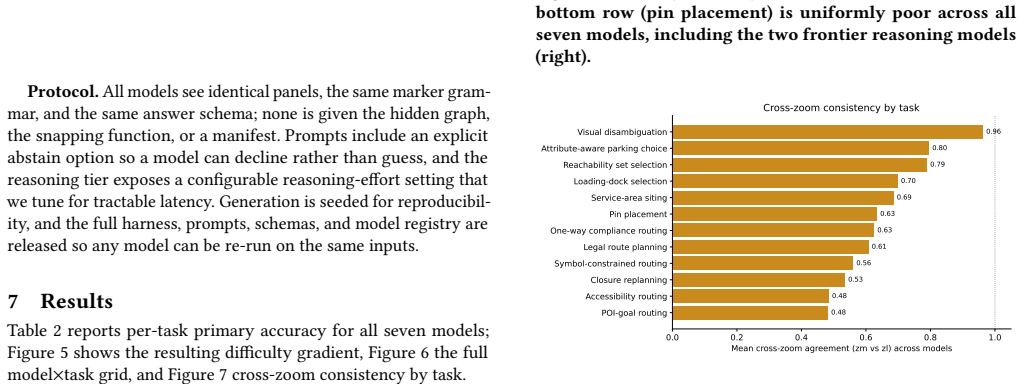
Across seven VLMs, models read maps and route simply but fail at graph cost reasoning, with single-facility pin placement near chance even for frontier reasoning models, and are frequently scale-inconsistent.
What carries the argument
The MapReason-OSM benchmark and evaluation harness that pairs rendered map panels with hidden street graphs and exact oracles to score decisions for graph validity.
If this is right
- VLMs manage basic routing from maps but cannot reliably optimize single-facility locations that require minimizing distances on the hidden street graph.
- Model outputs are frequently inconsistent when the same location is shown at different aligned zoom scales.
- Decisions can be evaluated for validity, legality, optimality, and constraint satisfaction by snapping to the graph.
- The released benchmark and deterministic generator enable repeated testing of new models on the same verifiable tasks.
Where Pith is reading between the lines
- Pure visual input may be insufficient for VLMs to perform quantitative cost reasoning on networks, suggesting a need for explicit graph augmentation.
- Scale inconsistency implies that current models lack a stable internal metric representation of map space.
- The benchmark could be extended to measure how performance changes when models receive auxiliary graph data as text alongside the image.
Load-bearing premise
The self-rendered panels with consistent marker grammar and the chosen set of 12 tasks faithfully capture the core challenges of real-world mobility decisions without introducing rendering artifacts or task-specific biases.
What would settle it
A model that places single facilities at graph-optimal locations at rates well above chance across instances while producing consistent answers at both zoom scales would contradict the reported failures.
Figures



read the original abstract
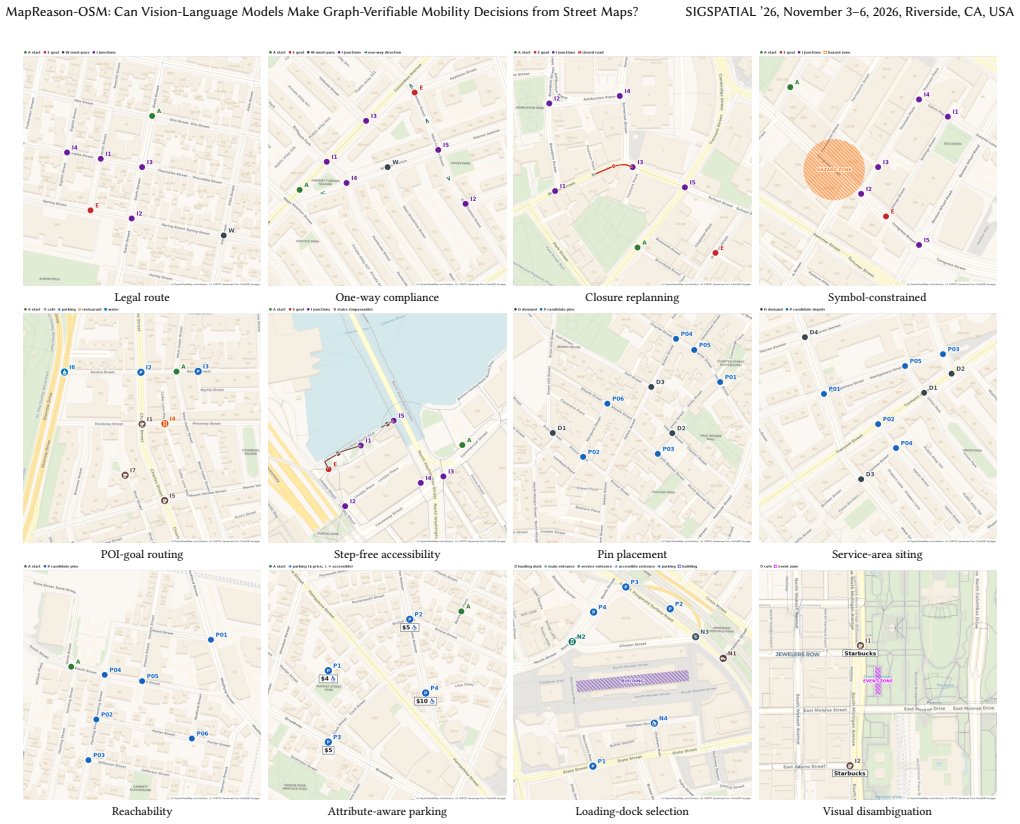
Vision-language models (VLMs) are increasingly used to read maps for logistics, delivery, and accessible navigation, where the output is an actionable decision (a route, a pin, a parking choice) that must respect the road network. Yet most map benchmarks grade free text or multiple-choice answers that cannot be verified against the underlying graph. We present MapReason-OSM, a benchmark and evaluation harness for graph-verifiable mobility decisions on self-rendered OpenStreetMap panels. We render fixed-style maps for ten U.S. downtowns at two aligned zoom scales, overlay a consistent marker grammar, and pair each panel with a hidden street graph and exact oracles, yielding 6,000 instances (12,000 panels across the two zooms) over 12 routing, facility-location, and visual disambiguation tasks. Models return structured decisions that we snap back to the graph and score for validity, legality, optimality, and constraint satisfaction, plus cross-zoom consistency. Across seven VLMs, models read maps and route simply but fail at graph cost reasoning (single-facility pin placement is near chance even for frontier reasoning models), and are frequently scale-inconsistent. We release the benchmark, harness, and deterministic generator. Code and data: https://github.com/Vi-Sri/mapreason-osm
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MapReason-OSM, a benchmark and evaluation harness for graph-verifiable mobility decisions by VLMs on self-rendered OpenStreetMap panels. It generates 6,000 instances (12,000 panels) across 12 tasks involving routing, facility location, and visual disambiguation for ten U.S. downtowns at two aligned zoom scales, using a consistent marker grammar, hidden street graphs, and exact oracles. Models produce structured outputs that are snapped back to the graph and scored on validity, legality, optimality, and constraint satisfaction, plus cross-zoom consistency. Results across seven VLMs indicate success on simple routing but near-chance performance on graph-cost reasoning (e.g., single-facility pin placement) and frequent scale inconsistency. The benchmark, harness, and deterministic generator are released.
Significance. If the benchmark faithfully isolates graph-cost deficits without rendering or task artifacts, the work would provide a reproducible, verifiable testbed for VLM limitations in real-world mobility applications such as logistics and navigation. The release of code, data, and generator supports reproducibility and future extensions, which is a clear strength.
major comments (2)
- [Abstract] Abstract and setup description: The central claim that VLMs 'fail at graph cost reasoning' (near-chance single-facility placement, scale inconsistency) rests on the 12 tasks and self-rendered panels with fixed marker grammar being faithful proxies for real mobility decisions. However, no controls are reported to rule out systematic artifacts (e.g., human baseline on identical panels, comparison to non-rendered graph input, or ablation of marker consistency/zoom alignment), so the performance gap could be an artifact of the harness rather than a genuine limitation in cost reasoning.
- [Abstract] Abstract: The evaluation protocol and headline results are stated, but without details on task definitions, oracle implementation, statistical testing, or error analysis, the soundness of the reported failures cannot be verified from the provided description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on MapReason-OSM. We address each major comment below and indicate planned revisions to strengthen the manuscript while preserving its core contribution as a reproducible, graph-verifiable benchmark.
read point-by-point responses
-
Referee: [Abstract] Abstract and setup description: The central claim that VLMs 'fail at graph cost reasoning' (near-chance single-facility placement, scale inconsistency) rests on the 12 tasks and self-rendered panels with fixed marker grammar being faithful proxies for real mobility decisions. However, no controls are reported to rule out systematic artifacts (e.g., human baseline on identical panels, comparison to non-rendered graph input, or ablation of marker consistency/zoom alignment), so the performance gap could be an artifact of the harness rather than a genuine limitation in cost reasoning.
Authors: We agree that explicit controls such as human baselines, graph-only (non-rendered) comparisons, and marker/zoom ablations would further isolate whether the observed deficits are due to VLM limitations in cost reasoning versus harness artifacts. The current work prioritizes exact, oracle-driven scoring against hidden street graphs to ensure verifiability, and the released deterministic generator is explicitly designed to support such extensions by others. In revision we will add a dedicated Limitations and Future Work subsection that discusses these potential artifacts, reports preliminary qualitative observations on marker consistency, and outlines protocols for human baselines and non-rendered ablations. We maintain that the near-chance results on single-facility placement are unlikely to be purely artifactual given the tasks' direct dependence on graph distances and constraints, but we accept that additional controls are needed to strengthen this interpretation. revision: partial
-
Referee: [Abstract] Abstract: The evaluation protocol and headline results are stated, but without details on task definitions, oracle implementation, statistical testing, or error analysis, the soundness of the reported failures cannot be verified from the provided description.
Authors: The abstract is intentionally concise. The full manuscript already contains: task definitions and marker grammar in Section 3, oracle construction and snapping procedure in Section 4, statistical testing (model-wise and zoom-wise comparisons with significance) in Section 5, and per-task error breakdowns in the same section. To improve verifiability from the abstract alone we will expand the abstract by one sentence summarizing the evaluation protocol and add a pointer to the open-source harness. We will also ensure the methods section includes a concise table of the 12 tasks with their constraint types and oracle metrics. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential predictions
full rationale
The paper is an empirical benchmark release evaluating VLMs on 12 tasks using self-rendered OSM panels, hidden graphs, and oracles. No mathematical derivations, fitted parameters, predictions, or uniqueness theorems are present. Claims rest on experimental results (e.g., near-chance performance on facility placement) rather than any reduction to inputs by construction. Self-citations are absent from the provided text, and the evaluation harness is externally verifiable via released code. This matches the default non-circular case for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Jun- yang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL: A Versatile Vision- Language Model for Understanding, Localization, Text Reading, and Beyond. arXiv:2308.12966 [cs.CV]
Pith/arXiv arXiv 2023
-
[2]
Prabin Bhandari, Antonios Anastasopoulos, and Dieter Pfoser. 2024. Urban Mobility Assessment Using LLMs. InProceedings of the 32nd ACM International Conference on Advances in Geographic Information Systems (SIGSPATIAL ’24). https://doi.org/10.1145/3678717.3691221
-
[3]
Geoff Boeing. 2017. OSMnx: New Methods for Acquiring, Constructing, Ana- lyzing, and Visualizing Complex Street Networks.Computers, Environment and Urban Systems65 (2017), 126–139. https://doi.org/10.1016/j.compenvurbsys.2017. 05.004
-
[4]
Nicholas Bolten and Anat Caspi. 2019. Towards Routine, City-Scale Accessibility Metrics: Graph Theoretic Interpretations of Pedestrian Access Using Personal- ized Pedestrian Network Analysis. InProceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems
2019
-
[5]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14455–14465
2024
-
[6]
Richard Church and Charles ReVelle. 1974. The Maximal Covering Location Problem.Papers in Regional Science32, 1 (1974), 101–118. https://doi.org/10. 1111/j.1435-5597.1974.tb00902.x
arXiv 1974
-
[7]
Mahir Labib Dihan et al. 2025. MapEval: A Map-Based Evaluation of Geo-Spatial Reasoning in Foundation Models. InProceedings of the 42nd International Confer- ence on Machine Learning (ICML)
2025
-
[8]
A note on two problems in connexion with graphs
Edsger W. Dijkstra. 1959. A Note on Two Problems in Connexion with Graphs. Numer. Math.1, 1 (1959), 269–271. https://doi.org/10.1007/BF01386390
-
[9]
Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. 2024. Talk Like a Graph: Encoding Graphs for Large Language Models. InThe Twelfth International Con- ference on Learning Representations (ICLR)
2024
-
[10]
Sicheng Feng, Song Wang, Shuyi Ouyang, Lingdong Kong, Zikai Song, Jianke Zhu, Huan Wang, and Xinchao Wang. 2026. ReasonMap: Towards Fine-Grained Visual Reasoning from Transit Maps. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2026
-
[11]
and Ma, Wei-Chiu and Krishna, Ranjay , title =
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, and Ranjay Krishna. 2024. BLINK: Multimodal Large Language Models Can See but Not Perceive. InComputer Vision – ECCV 2024 (Lecture Notes in Computer Science, Vol. 15081). Springer, 148–166. https: //doi.org/10.1007/978-3-031-73337-6_9
-
[12]
Gemini Team, Google. 2023. Gemini: A Family of Highly Capable Multimodal Models. arXiv:2312.11805 [cs.CL]
Pith/arXiv arXiv 2023
-
[13]
S. L. Hakimi. 1964. Optimum Locations of Switching Centers and the Absolute Centers and Medians of a Graph.Operations Research12, 3 (1964), 450–459. https://doi.org/10.1287/opre.12.3.450
-
[14]
Michael Held and Richard M. Karp. 1962. A Dynamic Programming Approach to Sequencing Problems.J. Soc. Indust. Appl. Math.10, 1 (1962), 196–210. https: //doi.org/10.1137/0110015
-
[15]
Varvara Krechetova and Denis Kochedykov. 2025. GeoBenchX: Benchmark- ing LLMs in Agent Solving Multistep Geospatial Tasks. InProceedings of the 1st ACM SIGSPATIAL International Workshop on Geospatial Generative Agents (GeoGenAgent ’25). https://doi.org/10.1145/3764915.3770721
-
[16]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023. Evaluating Object Hallucination in Large Vision-Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP). 292–305
2023
-
[17]
Zekun Li, Malcolm Grossman, Eric Qasemi, Mihir Kulkarni, Muhao Chen, and Yao-Yi Chiang. 2025. MapQA: Open-domain Geospatial Question Answering on Map Data. InProceedings of the 33rd ACM International Conference on Advances in Geographic Information Systems (SIGSPATIAL ’25)
2025
-
[18]
Fangyu Liu, Guy Emerson, and Nigel Collier. 2023. Visual Spatial Reasoning. Transactions of the Association for Computational Linguistics11 (2023), 635–651. https://doi.org/10.1162/tacl_a_00566
-
[19]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruc- tion Tuning. InAdvances in Neural Information Processing Systems (NeurIPS). MapReason-OSM: Can Vision-Language Models Make Graph-Verifiable Mobility Decisions from Street Maps? SIGSPATIAL ’26, November 3–6, 2026, Riverside, CA, USA
2023
-
[20]
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. 2024. MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts. In The Twelfth International Conference on Learning Representations (ICLR)
2024
-
[21]
Lobell, and Stefano Ermon
Rohin Manvi, Samar Khanna, Marshall Burke, David B. Lobell, and Stefano Ermon
-
[22]
InProceedings of the 41st International Conference on Machine Learning (ICML)
Large Language Models are Geographically Biased. InProceedings of the 41st International Conference on Machine Learning (ICML)
-
[23]
Lobell, and Stefano Ermon
Rohin Manvi, Samar Khanna, Gengchen Mai, Marshall Burke, David B. Lobell, and Stefano Ermon. 2024. GeoLLM: Extracting Geospatial Knowledge from Large Language Models. InThe Twelfth International Conference on Learning Representations (ICLR)
2024
-
[24]
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. 2022. ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning. InFindings of the Association for Computational Linguistics: ACL 2022. 2263–2279
2022
-
[25]
Minesh Mathew, Dimosthenis Karatzas, and C. V. Jawahar. 2021. DocVQA: A Dataset for VQA on Document Images. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). 2200–2209
2021
-
[26]
OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
Pith/arXiv arXiv 2023
-
[27]
OpenStreetMap contributors. 2017. OpenStreetMap. https://www.openstreetmap. org
2017
-
[28]
Jonathan Roberts, Timo Lüddecke, Sowmen Das, Kai Han, and Samuel Al- banie. 2023. GPT4GEO: How a Language Model Sees the World’s Geography. arXiv:2306.00020 [cs.CL]
arXiv 2023
-
[29]
Ziqiao Shang, Lingyue Ge, Yang Chen, Shi-Yu Tian, Zhenyu Huang, Wenbo Fu, Yu- Feng Li, and Lan-Zhe Guo. 2026. MapTab: Are MLLMs Ready for Multi-Criteria Route Planning in Heterogeneous Graphs? arXiv:2602.18600 [cs.CV]
Pith/arXiv arXiv 2026
-
[30]
Zhiheng Song, Jingshuai Zhang, Chuan Qin, Chao Wang, Chao Chen, Longfei Xu, Kaikui Liu, Xiangxiang Chu, and Hengshu Zhu. 2026. MobilityBench: A Bench- mark for Evaluating Route-Planning Agents in Real-World Mobility Scenarios. arXiv:2602.22638 [cs.AI] KDD 2026
Pith/arXiv arXiv 2026
-
[31]
Huy Quang Ung, Guillaume Habault, Yasutaka Nishimura, Hao Niu, Roberto Legaspi, Tomoki Oya, Ryoichi Kojima, Masato Taya, Chihiro Ono, Atsunori Mi- namikawa, and Yan Liu. 2025. CartoMapQA: A Fundamental Benchmark Dataset Evaluating Vision-Language Models on Cartographic Map Understanding. In Proceedings of the 33rd ACM International Conference on Advances ...
2025
-
[32]
Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. 2023. Can Language Models Solve Graph Problems in Natural Language?. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[33]
Shuo Xing et al. 2025. Can Large Vision Language Models Read Maps Like a Human? arXiv:2503.14607 [cs.CV] MapBench
arXiv 2025
-
[34]
Liuchang Xu, Shuo Zhao, Qingming Lin, Luyao Chen, Qianqian Luo, Sensen Wu, Xinyue Ye, Hailin Feng, and Zhenhong Du. 2024. Evaluating Large Language Mod- els on Spatial Tasks: A Multi-Task Benchmarking Study. arXiv:2408.14438 [cs.CL]
arXiv 2024
-
[35]
Yufei Xu, Gulam Kibria, and Srinivas Peeta. 2025. Agentic LLM Framework for Generating Spatial Intelligence to Support Decision-Making in Smart Cities. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Geospatial Generative Agents (GeoGenAgent ’25). https://doi.org/10.1145/3764924.3770899
-
[36]
Jin Y. Yen. 1971. Finding the K Shortest Loopless Paths in a Network.Management Science17, 11 (1971), 712–716. https://doi.org/10.1287/mnsc.17.11.712
-
[37]
Du Yin, Hao Xue, Arian Prabowo, Shuang Ao, and Flora Salim. 2025. XXLTraffic: Expanding and Extremely Long Traffic Forecasting beyond Test Adaptation. In Proceedings of the 33rd ACM International Conference on Advances in Geographic Information Systems (SIGSPATIAL ’25). https://doi.org/10.1145/3748636.3762762
-
[38]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. 2024. MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark f...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.