Target-Aware Linear Regression Under Distribution Shift
Pith reviewed 2026-06-26 07:58 UTC · model grok-4.3
The pith
When target marginals are known, a two-stage linear regression estimator nearly matches the hybrid benchmark's accuracy in high signal-to-noise regimes at almost no extra cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
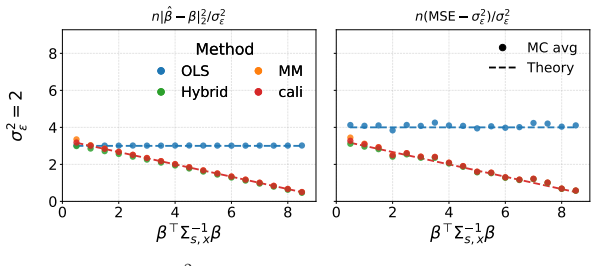
The central claim is that the two-stage estimator, formed by ordinary least squares followed by a calibration step that enforces the known target marginals, attains asymptotic mean squared error that nearly equals the hybrid-loss benchmark in the high signal-to-noise regime while remaining computationally comparable to standard least squares.
What carries the argument
The hybrid-loss estimator that jointly incorporates source data and the known target marginal distributions of both covariates and response through a combined objective.
If this is right
- Closed-form asymptotic mean squared error formulas enable direct analytic comparison among the hybrid, moment-matching, and two-stage estimators.
- The two-stage estimator recovers near-benchmark accuracy in high signal-to-noise settings without solving the full nonlinear program.
- The constrained moment-matching estimator can be used when exact moment constraints are required and computational budget permits.
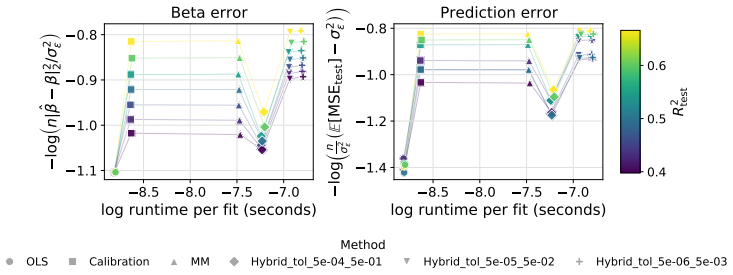
- Monte Carlo results across three controlled shift regimes supply concrete guidance on estimator selection based on signal strength and shift type.
Where Pith is reading between the lines
- The same two-stage structure may be worth testing when target marginals must be estimated from limited data rather than known exactly.
- The asymptotic comparisons suggest that the computational advantage of the two-stage method grows with problem size.
- Similar calibration-after-fitting ideas could be examined for regression models beyond the linear case under the same stability assumption.
Load-bearing premise
The conditional mean of the response given the covariates remains unchanged between the source and target distributions.
What would settle it
An experiment in which the conditional expectation E[Y|X] is deliberately altered between source and target; the target-aware estimators would then lose their advantage and could perform no better than ordinary least squares.
Figures


read the original abstract
Distribution shift between training and deployment is a pervasive challenge for modern AI systems. In many cases, the target marginals of covariates and response are known or specified through population-level observations, boundary conditions, properties of simulator configurations, or alignment-time distributional constraints. Such knowledge may provide valuable side information for regression estimation. We study this problem in the multivariate linear regression setting with a stable conditional mean $E[Y\mid X]$ across source and target, and identify the hybrid-loss estimator, which jointly incorporates both target marginals, as a benchmark target-aware estimator. Its direct computation, however, requires solving a coupled nonlinear optimization that is expensive at scale. Our main contribution is to develop and evaluate two computationally tractable alternatives: a constrained moment-matching estimator and a two-stage estimator that augments ordinary least squares with a calibration step. For all three estimators, we derive and compare closed-form asymptotic mean squared errors, yielding conditions under which the tractable alternatives match or closely approximate the hybrid benchmark, and regimes in which they do not. Monte Carlo experiments across three controlled shift regimes validate the theoretical results, investigate the accuracy-runtime tradeoffs among the three estimators, and translate into guidance on estimator choice. In particular, the two-stage estimator nearly matches the hybrid benchmark in the high signal-to-noise regime at essentially no additional cost, providing theoretical grounding for empirical observations in nonlinear settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops target-aware estimators for multivariate linear regression under distribution shift when target marginals of X and Y are known and E[Y|X] is stable. It defines a hybrid-loss estimator as the benchmark that jointly uses both marginals, then introduces a constrained moment-matching estimator and a two-stage estimator (OLS followed by calibration) as tractable alternatives. Closed-form asymptotic MSE expressions are derived for all three under moment conditions, yielding regimes where the alternatives match or approximate the hybrid; Monte Carlo experiments across three shift regimes validate the asymptotics and compare accuracy-runtime tradeoffs, with the conclusion that the two-stage estimator nearly matches the hybrid in high SNR at negligible extra cost.
Significance. The closed-form asymptotic MSE derivations and direct Monte Carlo validation across controlled regimes provide concrete, falsifiable comparisons among estimators and practical guidance on when each is preferable, which is a strength if the derivations are correct.
major comments (1)
- [Abstract] Abstract: the claim that the results provide 'theoretical grounding for empirical observations in nonlinear settings' is unsupported. All derivations of the hybrid, moment-matching, and two-stage estimators, the asymptotic MSE expressions, the definitions of the shift regimes, and the Monte Carlo experiments are performed exclusively under the linear model with stable E[Y|X]; no argument, approximation, or extension is given showing why the high-SNR near-equivalence or negligible cost would hold when the regression function is nonlinear and misspecification interacts with marginal correction.
minor comments (1)
- The moment conditions underlying the asymptotic expansions (e.g., for the two-stage calibration step) are referenced but not stated explicitly; adding them would improve reproducibility of the closed-form results.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting an overstatement in the abstract. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the results provide 'theoretical grounding for empirical observations in nonlinear settings' is unsupported. All derivations of the hybrid, moment-matching, and two-stage estimators, the asymptotic MSE expressions, the definitions of the shift regimes, and the Monte Carlo experiments are performed exclusively under the linear model with stable E[Y|X]; no argument, approximation, or extension is given showing why the high-SNR near-equivalence or negligible cost would hold when the regression function is nonlinear and misspecification interacts with marginal correction.
Authors: We agree that the claim is unsupported. The entire analysis (estimators, asymptotic MSE derivations, shift regimes, and simulations) is confined to the linear model with invariant E[Y|X]. No approximation, extension, or argument is provided for nonlinear regression functions or for how misspecification would interact with the marginal corrections. We will remove the sentence "providing theoretical grounding for empirical observations in nonlinear settings" from the abstract (and any similar phrasing elsewhere) so that the stated contributions accurately reflect the linear setting studied. revision: yes
Circularity Check
No circularity in asymptotic derivations
full rationale
The paper explicitly defines the hybrid-loss, moment-matching, and two-stage estimators under the linear model with stable E[Y|X], then derives their closed-form asymptotic MSE expressions directly from those definitions plus standard moment conditions and regularity assumptions. No step reduces a claimed prediction to a fitted parameter by construction, invokes self-citation as load-bearing justification, or renames an input as an output. The Monte Carlo experiments serve only as validation of the derived expressions, and the remark on nonlinear settings is presented as interpretive context rather than a formal result within the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The conditional expectation E[Y | X] is the same in source and target distributions.
Reference graph
Works this paper leans on
-
[1]
A theory of learning from different domains.Machine Learning, 79(1–2):151–175, 2010
Shai Ben-David, John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman Vaughan. A theory of learning from different domains.Machine Learning, 79(1–2):151–175, 2010
2010
-
[2]
Augmented balancing weights as linear regression.Journal of the Royal Statistical Society Series B: Statistical Methodology, page qkaf019, 2025
David Bruns-Smith, Oliver Dukes, Avi Feller, and Elizabeth L Ogburn. Augmented balancing weights as linear regression.Journal of the Royal Statistical Society Series B: Statistical Methodology, page qkaf019, 2025
2025
-
[3]
Efficient and adaptive linear regression in semi- supervised settings
Abhishek Chakrabortty and Tianxi Cai. Efficient and adaptive linear regression in semi- supervised settings. 2018
2018
-
[4]
Semiparametric efficiency in GMM models with auxiliary data.The Annals of Statistics, 36(2):808–843, 2008
Xiaohong Chen, Han Hong, and Alessandro Tarozzi. Semiparametric efficiency in GMM models with auxiliary data.The Annals of Statistics, 36(2):808–843, 2008
2008
-
[5]
Deville and särndal’s calibration: revisiting a 25-years-old successful optimization problem.Test, 28(4):1033–1065, 2019
Denis Devaud and Yves Tillé. Deville and särndal’s calibration: revisiting a 25-years-old successful optimization problem.Test, 28(4):1033–1065, 2019
2019
-
[6]
Calibration estimators in survey sampling.Journal of the American Statistical Association, 87(418):376–382, 1992
Jean-Claude Deville and Carl-Erik Särndal. Calibration estimators in survey sampling.Journal of the American Statistical Association, 87(418):376–382, 1992
1992
-
[7]
Stein’s estimation rule and its competitors—an empirical bayes approach.Journal of the American Statistical Association, 68(341):117–130, 1973
Bradley Efron and Carl Morris. Stein’s estimation rule and its competitors—an empirical bayes approach.Journal of the American Statistical Association, 68(341):117–130, 1973
1973
-
[8]
User-defined event sampling and uncertainty quantification in diffusion models for physical dynamical systems
Marc Anton Finzi, Anudhyan Boral, Andrew Gordon Wilson, Fei Sha, and Leonardo Zepeda- Núñez. User-defined event sampling and uncertainty quantification in diffusion models for physical dynamical systems. InInternational Conference on Machine Learning, pages 10136– 10152. PMLR, 2023
2023
-
[9]
Noniterative adjustment to regression estimators with population-based auxiliary information for semiparametric models.Biometrics, 79(1):140–150, 2023
Fei Gao and KCG Chan. Noniterative adjustment to regression estimators with population-based auxiliary information for semiparametric models.Biometrics, 79(1):140–150, 2023
2023
-
[10]
Quantifying errors in observationally based estimates of ocean carbon sink variability.Global Biogeochemical Cycles, 35(4):e2020GB006788, 2021
Lucas Gloege, Galen A McKinley, Peter Landschützer, Amanda R Fay, Thomas L Frölicher, John C Fyfe, Tatiana Ilyina, Steve Jones, Nicole S Lovenduski, Keith B Rodgers, et al. Quantifying errors in observationally based estimates of ocean carbon sink variability.Global Biogeochemical Cycles, 35(4):e2020GB006788, 2021
2021
-
[11]
Empirical likelihood estimation using auxiliary summary information with different covariate distributions.Statistica Sinica, 29(3):1321–1342, 2019
Peisong Han and Jerald F Lawless. Empirical likelihood estimation using auxiliary summary information with different covariate distributions.Statistica Sinica, 29(3):1321–1342, 2019
2019
-
[12]
Improving prediction of linear regression models by integrating external information from heterogeneous populations: James–stein estimators.Biometrics, 80(3):ujae072, 2024
Peisong Han, Haoyue Li, Sung Kyun Park, Bhramar Mukherjee, and Jeremy MG Taylor. Improving prediction of linear regression models by integrating external information from heterogeneous populations: James–stein estimators.Biometrics, 80(3):ujae072, 2024
2024
-
[13]
Large sample properties of generalized method of moments estimators
Lars Peter Hansen. Large sample properties of generalized method of moments estimators. Econometrica, 50(4):1029–1054, 1982
1982
-
[14]
Augmented minimax linear estimation.The Annals of Statistics, 49(6):3206–3227, 2021
David A Hirshberg and Stefan Wager. Augmented minimax linear estimation.The Annals of Statistics, 49(6):3206–3227, 2021
2021
-
[15]
Zhewen Hou, Jiajin Sun, Subashree Venkatasubramanian, Peter Jin, Shuolin Li, and Tian Zheng. Calibrating geophysical predictions under constrained probabilistic distributions.arXiv preprint arXiv:2512.03081, 2025
arXiv 2025
-
[16]
One-step estimators for over-identified generalized method of moments models.The Review of Economic Studies, 64(3):359–383, 1997
Guido W Imbens. One-step estimators for over-identified generalized method of moments models.The Review of Economic Studies, 64(3):359–383, 1997
1997
-
[17]
Wiley, 1980
George G Judge, William E Griffiths, R Carter Hill, and Tsoung-Chao Lee.The Theory and Practice of Econometrics. Wiley, 1980
1980
-
[18]
Jennifer E Kay, Clara Deser, A Phillips, A Mai, Cecile Hannay, Gary Strand, Julie Michelle Arblaster, SC Bates, Gokhan Danabasoglu, James Edwards, et al. The community earth system model (cesm) large ensemble project: A community resource for studying climate change in the presence of internal climate variability.Bulletin of the American Meteorological So...
2015
-
[19]
A kernelized stein discrepancy for goodness-of-fit tests
Qiang Liu, Jason Lee, and Michael Jordan. A kernelized stein discrepancy for goodness-of-fit tests. InInternational Conference on Machine Learning, pages 276–284. PMLR, 2016
2016
-
[20]
Nearest neighbor sampling for covariate shift adaptation.Journal of Machine Learning Research, 25(410):1–42, 2024
François Portier, Lionel Truquet, and Ikko Yamane. Nearest neighbor sampling for covariate shift adaptation.Journal of Machine Learning Research, 25(410):1–42, 2024
2024
-
[21]
Empirical likelihood and general estimating equations.The Annals of Statistics, 22(1):300–325, 1994
Jin Qin and Jerry Lawless. Empirical likelihood and general estimating equations.The Annals of Statistics, 22(1):300–325, 1994
1994
-
[22]
The calibration approach in survey theory and practice.Survey methodology, 33(2):99–119, 2007
Carl-Erik Särndal. The calibration approach in survey theory and practice.Survey methodology, 33(2):99–119, 2007
2007
-
[23]
Improving predictive inference under covariate shift by weighting the log-likelihood function.Journal of Statistical Planning and Inference, 90(2):227–244, 2000
Hidetoshi Shimodaira. Improving predictive inference under covariate shift by weighting the log-likelihood function.Journal of Statistical Planning and Inference, 90(2):227–244, 2000
2000
-
[24]
Inadmissibility of the usual estimator for the mean of a multivariate normal distribution
Charles Stein. Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. InProceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, volume 3, pages 197–207. University of California Press, 1956
1956
-
[25]
Low-dimensional density ratio estimation for covariate shift correction
Petar Stojanov, Mingming Gong, Jaime Carbonell, and Kun Zhang. Low-dimensional density ratio estimation for covariate shift correction. InInternational Conference on Artificial Intelligence and Statistics, pages 3449–3458. PMLR, 2019
2019
-
[26]
Regularized calibrated estimation of propensity scores with model misspecification and high-dimensional data.Biometrika, 107(1):137–158, 2020
Zhiqiang Tan. Regularized calibrated estimation of propensity scores with model misspecification and high-dimensional data.Biometrika, 107(1):137–158, 2020
2020
-
[27]
Wasserstein distributional learning via majorization-minimization
Chengliang Tang, Nathan Lenssen, Ying Wei, and Tian Zheng. Wasserstein distributional learning via majorization-minimization. InInternational Conference on Artificial Intelligence and Statistics, pages 10703–10731. PMLR, 2023
2023
-
[28]
Adaptive learning of density ratios in RKHS.Journal of Machine Learning Research, 24(395):1–28, 2023
Werner Zellinger, Stefan Kindermann, and Sergei V Pereverzyev. Adaptive learning of density ratios in RKHS.Journal of Machine Learning Research, 24(395):1–28, 2023
2023
-
[29]
Pi-vae: Physics-informed variational auto-encoder for stochastic differential equations.Computer Methods in Applied Mechanics and Engineering, 403:115664, 2023
Weiheng Zhong and Hadi Meidani. Pi-vae: Physics-informed variational auto-encoder for stochastic differential equations.Computer Methods in Applied Mechanics and Engineering, 403:115664, 2023. 11 Supplement We use the notation from Section 3 throughout: Qs =E( ˜X ˜X ⊤), Qs|k = Σ s,x + (µs,x −µ k,x)(µs,x −µ k,x)⊤, vσβ = Σ k,xβ, κ=v ⊤ σβ Q−1 s|kvσβ , χ=v ⊤ ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.