HiL-ResRL: A Model-Agnostic Finetuning Adapter via Human-in-the-loop Residual Reinforcement Learning
Pith reviewed 2026-06-26 08:42 UTC · model grok-4.3
The pith
A residual policy trained on VLA actions with human guidance corrects imitation errors and reaches over 95% success in 1.5 hours of real-robot training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
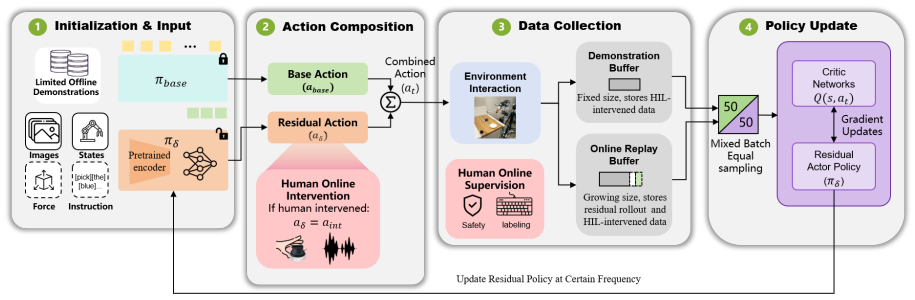
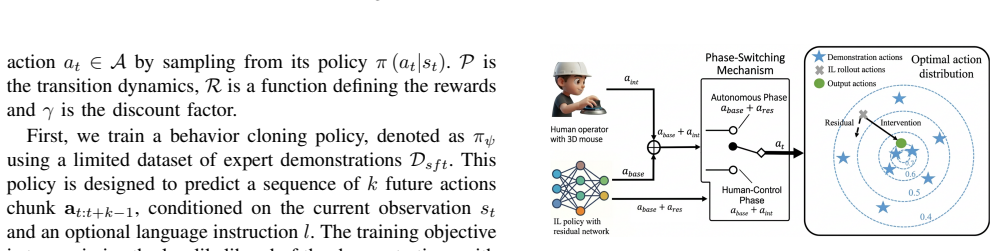
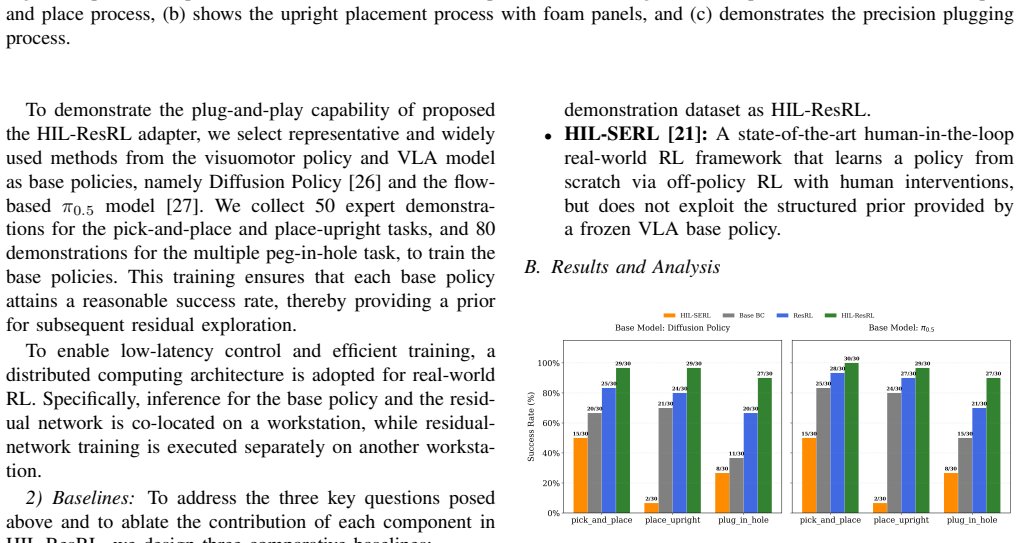
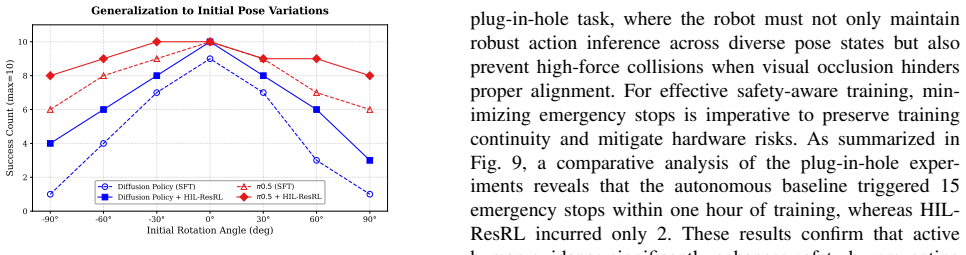
By treating VLA-generated actions as a unified interface, a residual policy can be trained to rectify suboptimal actions and address distributional shift. Human-in-the-loop guidance ensures safe exploration and efficient training. This model-agnostic approach works across diverse VLA models and delivers over 95 percent average success rate on real robots after 1.5 hours of online RL fine-tuning.
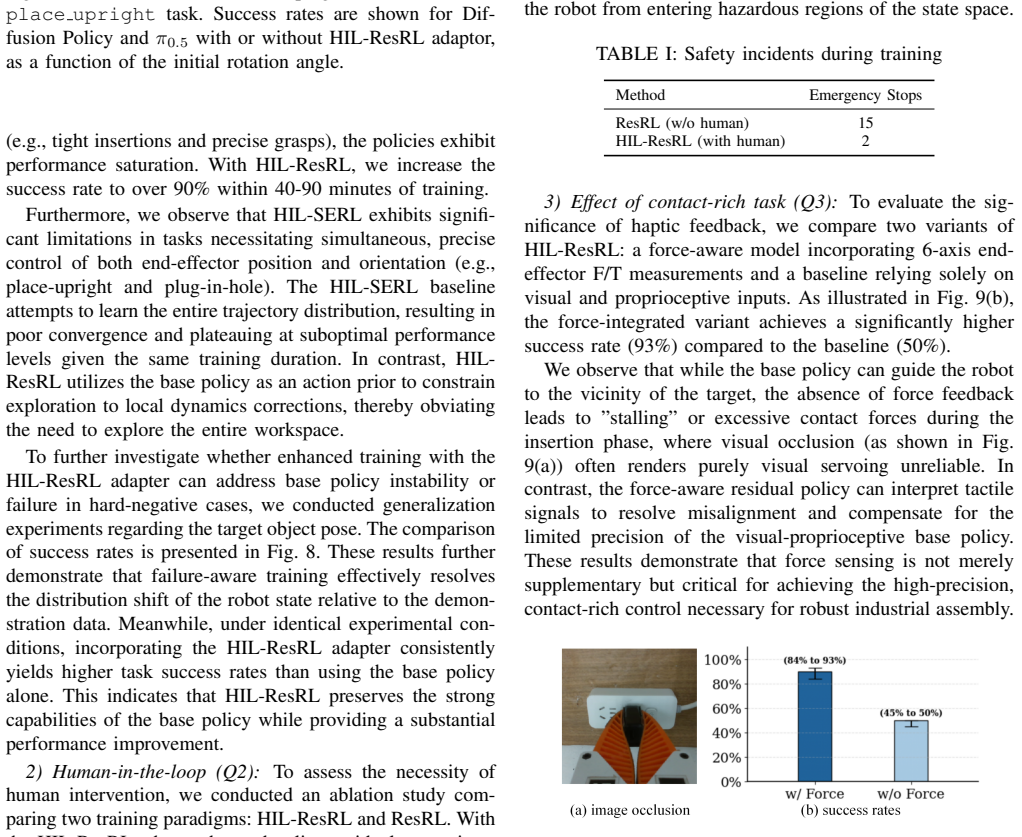
What carries the argument
Residual policy trained on VLA-generated actions as a unified interface, with human-in-the-loop guidance for safe real-world RL.
If this is right
- Any VLA model can be fine-tuned without architecture-specific constraints or retraining from scratch.
- Compounding errors and distributional shift from pure behavior cloning are directly mitigated by the residual correction.
- Real-world industrial deployment of imitation-learned policies becomes feasible with short online training times.
- Human guidance during RL keeps exploration safe while accelerating convergence.
Where Pith is reading between the lines
- The same residual-adapter pattern could be tested on non-VLA imitation methods that also suffer from distributional shift.
- If the adapter works across many VLAs, it may lower the cost of collecting large demonstration datasets for each new robot task.
- Remote or simulated human guidance could be substituted to scale the approach beyond physical co-presence.
Load-bearing premise
VLA-generated actions form a unified interface on which a residual policy can be trained to correct errors without depending on the specific VLA architecture.
What would settle it
Testing the same tasks on a new VLA model and finding that the residual adapter produces no measurable improvement or still requires far longer than 1.5 hours to reach high success rates.
Figures




read the original abstract
Recent advancements in generative imitation learning have significantly propelled the field of robotic manipulation. However, the majority of existing models rely heavily on Behavior Cloning (BC), a paradigm that suffers from compounding errors and distributional shift. Consequently, the efficacy of these models in practical industrial deployments remains limited. To address these challenges, we introduce a novel, plug-and-play fine-tuning pipeline designed to facilitate the robust deployment of Vision-Language-Action (VLA) models in real-world environments. In contrast to contemporary reinforcement learning (RL) fine-tuning strategies, which are often constrained by specific model architectures, our proposed framework is model-agnostic and adaptable to a diverse range of VLA models. We conceptualize VLA-generated actions as a unified interface, upon which we train a residual policy. This policy is designed to rectify suboptimal actions and address the distributional shift inherent in imitation learning. Additionally, we incorporate human-in-the-loop guidance to ensure safe exploration and maximize training efficiency. We conduct experiments directly in real-world robotic settings. The results demonstrate that within only 1.5 hour of real-world online RL training, the average success rate exceeds 95% on real robots. Our work presents a practical solution for deploying behavior cloning models in industrial scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HiL-ResRL, a plug-and-play, model-agnostic fine-tuning pipeline for Vision-Language-Action (VLA) models in robotic manipulation. It trains a residual policy via human-in-the-loop residual reinforcement learning on top of VLA-generated actions to correct suboptimal behaviors and distributional shift from behavior cloning, claiming that this yields an average success rate exceeding 95% after only 1.5 hours of real-world online RL training on physical robots.
Significance. If the empirical claims are substantiated with proper controls, the work would offer a practical contribution to deploying imitation-learned policies in industrial robotics by providing an architecture-independent adapter that addresses compounding errors without requiring per-VLA modifications.
major comments (2)
- [Abstract] Abstract: The central claim that 'the average success rate exceeds 95%' after 1.5 hours of real-world training is presented without any reference to the number of trials, task definitions, baselines, variance (error bars), or statistical tests, rendering the headline result impossible to evaluate against the reader's weakest assumption about the unified VLA action interface.
- [Method] Method (conceptual description of the residual policy): The assertion that VLA-generated actions form a 'unified interface' enabling a truly model-agnostic residual learner is load-bearing for the model-agnostic claim, yet the manuscript provides no explicit experiments demonstrating that the identical residual architecture, observation space, action scaling, and hyperparameters were held fixed while swapping VLA backbones (e.g., diffusion vs. autoregressive).
minor comments (1)
- [Abstract] The abstract and method description would benefit from a short table or paragraph explicitly listing the VLA models tested and the exact residual policy input/output dimensions to make the 'plug-and-play' claim concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below, indicating where revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the average success rate exceeds 95%' after 1.5 hours of real-world training is presented without any reference to the number of trials, task definitions, baselines, variance (error bars), or statistical tests, rendering the headline result impossible to evaluate against the reader's weakest assumption about the unified VLA action interface.
Authors: We agree that the abstract would benefit from additional context to allow readers to better evaluate the result. The body of the manuscript details the experimental protocol, including task definitions, number of trials, and observed variance. In the revised version, we will expand the abstract to briefly reference these elements (e.g., number of tasks and trials) and point to the Experiments section for full details on baselines and statistical reporting. revision: yes
-
Referee: [Method] Method (conceptual description of the residual policy): The assertion that VLA-generated actions form a 'unified interface' enabling a truly model-agnostic residual learner is load-bearing for the model-agnostic claim, yet the manuscript provides no explicit experiments demonstrating that the identical residual architecture, observation space, action scaling, and hyperparameters were held fixed while swapping VLA backbones (e.g., diffusion vs. autoregressive).
Authors: The model-agnostic property follows from the design decision to treat VLA outputs as a standardized action interface (normalized end-effector or joint velocities) that any VLA can produce. The residual policy architecture, observation space, and hyperparameters are therefore independent of the specific VLA backbone. While the current experiments demonstrate the approach with one VLA, we will add a clarifying paragraph in the Method section explaining this interface standardization and its implications for agnosticism, along with a note on cross-VLA validation as future work. revision: partial
Circularity Check
No circularity; empirical pipeline with independent real-world results
full rationale
The paper presents a plug-and-play residual RL fine-tuning method for VLA models, conceptualizing VLA actions as a unified interface for training a residual policy. No equations, derivations, or fitted parameters are described that reduce the central claim to inputs by construction. The headline result (exceeding 95% success after 1.5 hours of real-world training) is reported as an experimental outcome, not a statistical prediction forced by subset fitting or self-definition. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The method is self-contained as a practical adapter with human-in-the-loop safety, evaluated directly on robots without reducing to renamed known results or author-prior assumptions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Openvla: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “Openvla: An open-source vision-language-action model,” in Conference on Robot Learning, 2024
2024
-
[2]
π0: A vision-language-action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky, “π0: A vision-language-action flow model for general robot control,”
-
[3]
Available: https://arxiv.org/abs/2410.24164
[Online]. Available: https://arxiv.org/abs/2410.24164
-
[4]
Combating the compounding-error problem with a multi-step model,
K. Asadi, D. Misra, S. Kim, and M. L. Littman, “Combating the compounding-error problem with a multi-step model,” 2019. [Online]. Available: https://arxiv.org/abs/1905.13320
Pith/arXiv arXiv 2019
-
[5]
Steering your generalists: Improving robotic foundation models via value guidance,
M. Nakamoto, O. Mees, A. Kumar, and S. Levine, “Steering your generalists: Improving robotic foundation models via value guidance,”
-
[6]
Available: https://arxiv.org/abs/2410.13816
[Online]. Available: https://arxiv.org/abs/2410.13816
-
[7]
What matters in learning from large-scale datasets for robot manipulation,
V . Saxena, M. Bronars, N. R. Arachchige, K. Wang, W. C. Shin, S. Nasiriany, A. Mandlekar, and D. Xu, “What matters in learning from large-scale datasets for robot manipulation,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[8]
Sim-and-real co- training: A simple recipe for vision-based robotic manipulation,
A. Maddukuri, Z. Jiang, L. Y . Chen, S. Nasiriany, Y . Xie, Y . Fang, W. Huang, Z. Wang, Z. Xu, N. Chernyadev,et al., “Sim-and-real co- training: A simple recipe for vision-based robotic manipulation,”arXiv preprint arXiv:2503.24361, 2025
arXiv 2025
-
[9]
Reinforcement learning with action chunking,
Q. Li, Z. Zhou, and S. Levine, “Reinforcement learning with action chunking,” 2025. [Online]. Available: https://arxiv.org/abs/2507.07969
Pith/arXiv arXiv 2025
-
[10]
What can rl bring to vla generalization? an empirical study,
J. Liu, F. Gao, B. Wei, X. Chen, Q. Liao, Y . Wu, C. Yu, and Y . Wang, “What can rl bring to vla generalization? an empirical study,” 2026. [Online]. Available: https://arxiv.org/abs/2505.19789
arXiv 2026
-
[11]
Grape: Generalizing robot policy via preference alignment,
Z. Zhang, K. Zheng, Z. Chen, J. Jang, Y . Li, S. Han, C. Wang, M. Ding, D. Fox, and H. Yao, “Grape: Generalizing robot policy via preference alignment,” 2025. [Online]. Available: https://arxiv.org/abs/2411.19309
arXiv 2025
-
[12]
Simplevla-rl: Scaling vla training via reinforcement learning,
H. Li, Y . Zuo, J. Yu, Y . Zhang, Z. Yang, K. Zhang, X. Zhu, Y . Zhang, T. Chen, G. Cui, D. Wang, D. Luo, Y . Fan, Y . Sun, J. Zeng, J. Pang, S. Zhang, Y . Wang, Y . Mu, B. Zhou, and N. Ding, “Simplevla-rl: Scaling vla training via reinforcement learning,” 2025. [Online]. Available: https://arxiv.org/abs/2509.09674
Pith/arXiv arXiv 2025
-
[13]
π ∗ 0.6: a vla that learns from experience,
Physical Intelligence Team et al., “π ∗ 0.6: a vla that learns from experience,” 2025. [Online]. Available: https://arxiv.org/abs/2511. 14759
2025
-
[14]
Policy decorator: Model-agnostic online refinement for large policy model,
X. Yuan, T. Mu, S. Tao, Y . Fang, M. Zhang, and H. Su, “Policy decorator: Model-agnostic online refinement for large policy model,”
-
[15]
Available: https://arxiv.org/abs/2412.13630
[Online]. Available: https://arxiv.org/abs/2412.13630
-
[16]
Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills,
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbab, C. Pan, Z. Yi, G. Qu, K. Kitani, J. Hodgins, L. J. Fan, Y . Zhu, C. Liu, and G. Shi, “Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills,”
-
[17]
Available: https://arxiv.org/abs/2502.01143
[Online]. Available: https://arxiv.org/abs/2502.01143
-
[18]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition. IEEE, 2016, pp. 770–778
2016
-
[19]
Transic: Sim-to-real policy transfer by learning from online correction,
Y . Jiang, C. Wang, R. Zhang, J. Wu, and L. Fei-Fei, “Transic: Sim-to-real policy transfer by learning from online correction,” 2024. [Online]. Available: https://arxiv.org/abs/2405.10315
arXiv 2024
-
[20]
Compliant residual dagger: Improving real-world contact-rich manipulation with human corrections,
X. Xu, Y . Hou, C. Xin, Z. Liu, and S. Song, “Compliant residual dagger: Improving real-world contact-rich manipulation with human corrections,” 2025. [Online]. Available: https://arxiv.org/abs/2506. 16685
2025
-
[21]
Residual off-policy rl for finetuning behavior cloning policies,
L. Ankile, Z. Jiang, R. Duan, G. Shi, P. Abbeel, and A. Nagabandi, “Residual off-policy rl for finetuning behavior cloning policies,”
-
[22]
Available: https://arxiv.org/abs/2509.19301
[Online]. Available: https://arxiv.org/abs/2509.19301
-
[23]
Self-improving vision-language-action models with data generation via residual rl,
W. Xiao, H. Lin, A. Peng, H. Xue, T. He, Y . Xie, F. Hu, J. Wu, Z. Luo, L. J. Fan, G. Shi, and Y . Zhu, “Self-improving vision-language-action models with data generation via residual rl,”
-
[24]
Available: https://arxiv.org/abs/2511.00091
[Online]. Available: https://arxiv.org/abs/2511.00091
-
[25]
From imitation to refinement-residual rl for precise assembly,
L. Ankile, A. Simeonov, I. Shenfeld, M. Torne, and P. Agrawal, “From imitation to refinement-residual rl for precise assembly,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 01–08
2025
-
[26]
Serl: A software suite for sample- efficient robotic reinforcement learning,
J. Luo, Z. Hu, C. Xu, Y . L. Tan, J. Berg, A. Sharma, S. Schaal, C. Finn, A. Gupta, and S. Levine, “Serl: A software suite for sample- efficient robotic reinforcement learning,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 16 961–16 969
2024
-
[27]
Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,
J. Luo, C. Xu, J. Wu, and S. Levine, “Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,”Science Robotics, vol. 10, no. 105, p. eads5033, 2025
2025
-
[28]
Conrft: A reinforced fine-tuning method for vla models via consistency policy,
Y . Chen, S. Tian, S. Liu, Y . Zhou, H. Li, and D. Zhao, “Conrft: A reinforced fine-tuning method for vla models via consistency policy,” inProceedings of Robotics: Science and Systems, RSS 2025, Los Angeles, CA, USA, Jun 21-25, 2025, 2025
2025
-
[29]
A vision-language-action-critic model for robotic real-world reinforcement learning,
S. Zhai, Q. Zhang, T. Zhang, F. Huang, H. Zhang, M. Zhou, S. Zhang, L. Liu, S. Lin, and J. Pang, “A vision-language-action-critic model for robotic real-world reinforcement learning,” 2025. [Online]. Available: https://arxiv.org/abs/2509.15937
arXiv 2025
-
[30]
Rl-100: Performant robotic manipulation with real-world reinforcement learning,
K. Lei, H. Li, D. Yu, Z. Wei, L. Guo, Z. Jiang, Z. Wang, S. Liang, and H. Xu, “Rl-100: Performant robotic manipulation with real-world reinforcement learning,” 2025. [Online]. Available: https://arxiv.org/abs/2510.14830
arXiv 2025
-
[31]
Gr-rl: Going dexterous and precise for long-horizon robotic manipulation,
Y . Li, X. Ma, J. Xu, Y . Cui, Z. Cui, Z. Han, L. Huang, T. Kong, Y . Liu, H. Niu, W. Peng, J. Qiao, Z. Ren, H. Shi, Z. Su, J. Tian, Y . Xiao, S. Zhang, L. Zheng, H. Li, and Y . Wu, “Gr-rl: Going dexterous and precise for long-horizon robotic manipulation,” 2025. [Online]. Available: https://arxiv.org/abs/2512.01801
arXiv 2025
-
[32]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” in Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[33]
π 0.5: a vision-language-action model with open-world generalization,
Physical Intelligence Team et al., “π 0.5: a vision-language-action model with open-world generalization,” 2025. [Online]. Available: https://arxiv.org/abs/2504.16054
Pith/arXiv arXiv 2025
-
[34]
Efficient online reinforcement learning with offline data,
P. J. Ball, L. Smith, I. Kostrikov, and S. Levine, “Efficient online reinforcement learning with offline data,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 1577–1594
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.