FedOT: Ownership Verification and Leakage Tracing via Watermarks for Federated LDMs
Pith reviewed 2026-06-26 09:15 UTC · model grok-4.3
The pith
FedOT embeds chunked watermarks tied to a latent transformation so that ownership can be verified and leaks traced to specific clients in federated latent diffusion models while VAE swaps destroy usability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
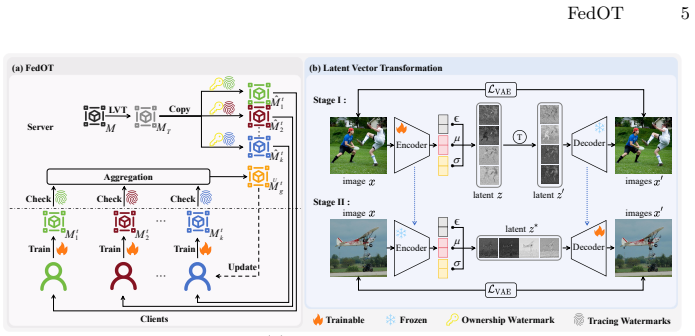
The central claim is that a chunked watermark combined with Latent Vector Transformation creates the first practical system for both ownership verification and client-specific leakage tracing in federated LDMs; the transformation strengthens the link between VAE and U-Net latent spaces so that decoder replacement necessarily degrades generated image quality to the point the model becomes unusable.
What carries the argument
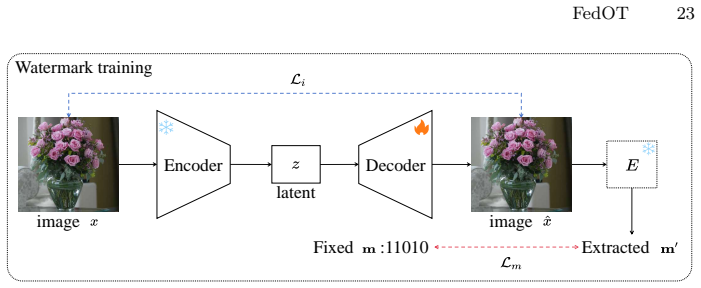
The chunked watermark (first segment for ownership verification, second for client identification) together with Latent Vector Transformation (LVT), which modifies the original VAE latent distribution to create a non-removable dependence on the U-Net.
If this is right
- The first watermark chunk enables standard ownership verification across all clients.
- The second watermark chunk allows identification of the exact client responsible for any leaked copy.
- LVT prevents simple VAE replacement attacks by tying latent spaces so tightly that removal destroys model utility.
- The overall scheme works inside the federated training loop without requiring changes to the core diffusion training process.
Where Pith is reading between the lines
- If LVT-style binding proves robust, similar latent-space tying could be applied to protect other components shared in federated generative pipelines.
- The chunked design suggests a general pattern for multi-purpose watermarks where verification and attribution are separated into independent segments.
- Adoption would require federated protocols to include watermark extraction steps during model distribution audits.
Load-bearing premise
Replacing the VAE after LVT has been applied will always produce unusable image quality rather than allowing a clean swap that keeps the model functional while removing the watermark.
What would settle it
Train a FedOT-protected LDM, replace its VAE with an unmodified clean decoder, generate a set of images, and measure both perceptual quality metrics and watermark detection accuracy; high quality with absent watermark falsifies the protection claim.
Figures







read the original abstract
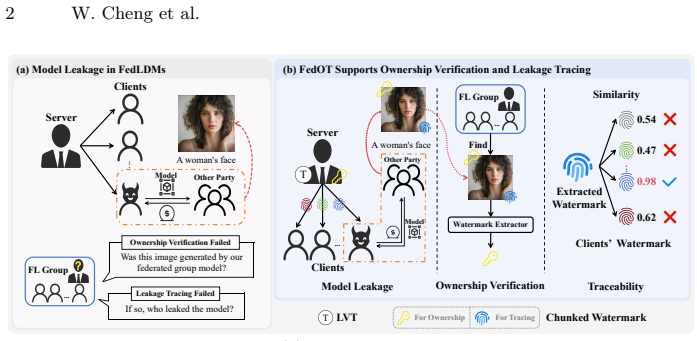
Training Latent Diffusion Models (LDMs) within Federated Learning (FL) has attracted increasing attention due to its ability to combine the powerful generative capacity of LDMs with the privacy-preserving properties of FL. However, FL requires sharing the global model with multiple participants, which risks unauthorized model distribution or resale by malicious clients. While an intuitive approach is to adopt existing VAE-based watermarking techniques for LDMs in FL, this strategy falls short in addressing such threats due to two fundamental challenges: (1) Existing methods support ownership verification but lack the ability to trace model leakage to a specific malicious client; (2) VAE-based watermarks are vulnerable, as they can be removed simply by replacing the decoder with a clean counterpart. In this paper, we propose FedOT, the first framework for ownership verification and leakage tracing in federated LDMs. Specifically, to address the first challenge, we design a chunked watermark, where the first part is for ownership verification, and the second part is used for client identification. Furthermore, to overcome the second challenge and secure the model against VAE replacement attack, we introduce Latent Vector Transformation (LVT), which strengthens the connection between the VAE and U-Net latent spaces by modifying the original latent distribution of the VAE. Consequently, any attempt to replace the VAE for watermark removal leads to significant image quality degradation, making the LDM model unusable. Extensive experiments demonstrate that FedOT achieves superior performance in both ownership verification and traceability. Project page: https://spyzixuan.github.io/FedOT/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FedOT, the first framework for ownership verification and leakage tracing in federated LDMs. It uses a chunked watermark (first part for ownership verification, second for client identification) and introduces Latent Vector Transformation (LVT) to modify the VAE latent distribution and strengthen its link to the U-Net, such that replacing the VAE to remove the watermark necessarily causes significant image quality degradation and renders the model unusable. The authors claim that extensive experiments show superior performance in verification and traceability.
Significance. If the LVT security property holds, the work would provide a practical defense against model leakage in federated generative model training, a setting where sharing the global model creates clear IP risks. The chunked watermark design usefully combines verification with traceability in multi-client FL without requiring separate mechanisms.
major comments (2)
- [Abstract] Abstract: The central security claim that 'any attempt to replace the VAE for watermark removal leads to significant image quality degradation, making the LDM model unusable' is presented as a direct consequence of LVT but without any analysis, equations, or experiments showing that the transformation is non-invertible or that joint fine-tuning of the U-Net with a clean VAE cannot recover both watermark removal and generation quality. This is the load-bearing assumption for the security guarantee.
- [Abstract] Abstract: The assertion of 'superior performance in both ownership verification and traceability' via 'extensive experiments' is unsupported by any reported metrics, baselines, attack implementations, or controls, preventing assessment of the empirical claims.
minor comments (1)
- The abstract would be strengthened by including at least summary quantitative results (e.g., verification accuracy, traceability success rates, FID degradation under attack) to allow readers to gauge the strength of the performance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires expansion to substantiate its claims and will revise the manuscript to include the requested analysis, equations, and detailed experimental reporting.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central security claim that 'any attempt to replace the VAE for watermark removal leads to significant image quality degradation, making the LDM model unusable' is presented as a direct consequence of LVT but without any analysis, equations, or experiments showing that the transformation is non-invertible or that joint fine-tuning of the U-Net with a clean VAE cannot recover both watermark removal and generation quality. This is the load-bearing assumption for the security guarantee.
Authors: We acknowledge the abstract presents the LVT security property concisely. The full manuscript describes LVT in Section 3.2 and reports quality degradation under VAE replacement in Section 4.3. To strengthen the claim, we will add a formal definition of the latent distribution shift induced by LVT, a brief invertibility argument, and new experiments evaluating joint fine-tuning of U-Net with a clean VAE in the revised version. revision: yes
-
Referee: [Abstract] Abstract: The assertion of 'superior performance in both ownership verification and traceability' via 'extensive experiments' is unsupported by any reported metrics, baselines, attack implementations, or controls, preventing assessment of the empirical claims.
Authors: We will revise the abstract to reference specific quantitative results and ensure the experiments section (currently Section 4) explicitly tabulates all metrics, comparison baselines, attack implementations, and control settings so that the superiority claims can be directly evaluated. revision: yes
Circularity Check
No circularity: new construction without reductions to inputs or self-citations
full rationale
The paper presents FedOT as an original framework introducing chunked watermarks and Latent Vector Transformation (LVT) to link VAE and U-Net spaces. The abstract asserts that LVT modification causes degradation on VAE replacement, but this is framed as a design consequence rather than derived from equations, fitted parameters, or prior self-citations. No load-bearing steps reduce by construction to inputs; the method is a novel proposal with experimental validation claimed, not a renaming or self-referential definition. The derivation chain is self-contained as an engineering construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2211.01324 (2022)
Balaji, Y., Nah, S., Huang, X., Vahdat, A., Song, J., Zhang, Q., Kreis, K., Ait- tala, M., Aila, T., Laine, S., et al.: ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers. arXiv preprint arXiv:2211.01324 (2022)
Pith/arXiv arXiv 2022
-
[2]
In: CVPR (2023)
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: CVPR (2023)
2023
-
[3]
arXiv preprint arXiv:1802.07228 (2018)
Brundage, M., Avin, S., Clark, J., Toner, H., Eckersley, P., Garfinkel, B., Dafoe, A., Scharre, P., Zeitzoff, T., Filar, B., et al.: The malicious use of artificial intelligence: Forecasting, prevention, and mitigation. arXiv preprint arXiv:1802.07228 (2018)
arXiv 2018
-
[4]
ACM Computing Surveys (2025)
Cao, Y., Li, S., Liu, Y., Yan, Z., Dai, Y., Yu, P., Sun, L.: A survey of ai-generated content (aigc). ACM Computing Surveys (2025)
2025
-
[5]
In: ICML (2025)
Ci, H., Song, Y., Yang, P., Xie, J., Shou, M.Z.: Wmadapter: Adding watermark control to latent diffusion models. In: ICML (2025)
2025
-
[6]
Morgan Kaufmann (2007)
Cox, I., Miller, M., Bloom, J., Fridrich, J., Kalker, T.: Digital watermarking and steganography. Morgan Kaufmann (2007)
2007
-
[7]
In: ICML (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: ICML (2024)
2024
-
[8]
In: CVPR (2021)
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: CVPR (2021)
2021
-
[9]
In: USENIX Security (2020)
Fang, M., Cao, X., Jia, J., Gong, N.: Local model poisoning attacks to{Byzantine- Robust}federated learning. In: USENIX Security (2020)
2020
-
[10]
In: IEEE Security and Privacy Workshops (2021)
Fereidooni, H., Marchal, S., Miettinen, M., Mirhoseini, A., Möllering, H., Nguyen, T.D., Rieger, P., Sadeghi, A.R., Schneider, T., Yalame, H., et al.: Safelearn: Se- cure aggregation for private federated learning. In: IEEE Security and Privacy Workshops (2021)
2021
-
[11]
In: ICCV (2023)
Fernandez, P., Couairon, G., Jégou, H., Douze, M., Furon, T.: The stable signature: Rooting watermarks in latent diffusion models. In: ICCV (2023)
2023
-
[12]
arXiv preprint arXiv:1808.04866 (2018)
Fung, C., Yoon, C.J., Beschastnikh, I.: Mitigating sybils in federated learning poi- soning. arXiv preprint arXiv:1808.04866 (2018)
arXiv 2018
-
[13]
In: CVPR (2025)
Gan, Y., Miao, J., Wang, Y., Yang, Y.: Silence is golden: Leveraging adversarial examples to nullify audio control in ldm-based talking-head generation. In: CVPR (2025)
2025
-
[14]
In: NeurIPS (2024)
Gan, Y., Miao, J., Yang, Y.: Datastealing: Steal data from diffusion models in federated learning with multiple trojans. In: NeurIPS (2024)
2024
-
[15]
In: CVPR (2022)
Gu, S., Chen, D., Bao, J., Wen, F., Zhang, B., Chen, D., Yuan, L., Guo, B.: Vector quantized diffusion model for text-to-image synthesis. In: CVPR (2022)
2022
-
[16]
In: ICCV (2023)
Han, L., Li, Y., Zhang, H., Milanfar, P., Metaxas, D., Yang, F.: Svdiff: Compact parameter space for diffusion fine-tuning. In: ICCV (2023)
2023
-
[17]
In: NeurIPS (2017) 16 W
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. In: NeurIPS (2017) 16 W. Cheng et al
2017
-
[18]
In: NeurIPS (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS (2020)
2020
-
[19]
In: NeurIPS (2022)
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. In: NeurIPS (2022)
2022
-
[20]
In: ICLR (2025)
Hu, R., Zhang, J., Li, Y., Li, J., Guo, Q., Qiu, H., Zhang, T.: Videoshield: Regu- lating diffusion-based video generation models via watermarking. In: ICLR (2025)
2025
-
[21]
In: MMM (2026)
Jia, H., Zhao, N., Xu, Y., Zhu, L., Yang, Y.: Gas: Geometry-appearance synergy for consistent video customization. In: MMM (2026)
2026
-
[22]
In: ECCV (2016)
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: ECCV (2016)
2016
-
[23]
In: ICLR (2014)
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. In: ICLR (2014)
2014
-
[24]
The Annals of Math- ematical Statistics (1951)
Kullback, S., Leibler, R.A.: On information and sufficiency. The Annals of Math- ematical Statistics (1951)
1951
-
[25]
In: International Conference on Machine Learning, Big Data, Cloud and Parallel Com- puting (2019)
Lambora, A., Gupta, K., Chopra, K.: Genetic algorithm-a literature review. In: International Conference on Machine Learning, Big Data, Cloud and Parallel Com- puting (2019)
2019
-
[26]
arXiv preprint arXiv:2405.02696 (2024)
Lei, L., Gai, K., Yu, J., Zhu, L.: Diffusetrace: A transparent and flexible water- marking scheme for latent diffusion model. arXiv preprint arXiv:2405.02696 (2024)
arXiv 2024
-
[27]
IEEE TPAMI (2022)
Li, B., Fan, L., Gu, H., Li, J., Yang, Q.: Fedipr: Ownership verification for federated deep neural network models. IEEE TPAMI (2022)
2022
-
[28]
IEEE TCSVT (2024)
Li, D., Xie, W., Wang, Z., Lu, Y., Li, Y., Fang, L.: Feddiff: Diffusion model driven federated learning for multi-modal and multi-clients. IEEE TCSVT (2024)
2024
-
[29]
In: ECCV (2014)
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: ECCV (2014)
2014
-
[30]
In: CVPR (2025)
Liu, G., Cao, S., Qian, Z., Zhang, X., Li, S., Peng, W.: Watermarking one for all: A robust watermarking scheme against partial image theft. In: CVPR (2025)
2025
-
[31]
In: ECCV (2024)
Liu, X., Guan, X., Wu, Y., Miao, J.: Iterative ensemble training with anti-gradient control for mitigating memorization in diffusion models. In: ECCV (2024)
2024
-
[32]
Liu, X., Shao, S., Yang, Y., Wu, K., Yang, W., Fang, H.: Secure federated learning modelverification:Aclient-sidebackdoortriggeredwatermarkingscheme.In:IEEE International Conference on Systems, Man, and Cybernetics (2021)
2021
-
[33]
In: ACM MM (2024)
Ma, Z., Jia, G., Qi, B., Zhou, B.: Safe-sd: Safe and traceable stable diffusion with text prompt trigger for invisible generative watermarking. In: ACM MM (2024)
2024
-
[34]
In: AISTATS (2017)
McMahan, B., Moore, E., Ramage, D., Hampson, S.: Communication-efficient learning of deep networks from decentralized data. In: AISTATS (2017)
2017
-
[35]
In: ECCV (2024)
Min, R., Li, S., Chen, H., Cheng, M.: A watermark-conditioned diffusion model for ip protection. In: ECCV (2024)
2024
-
[36]
arXiv preprint arXiv:2405.07925 (2024)
Morafah, M., Reisser, M., Lin, B., Louizos, C.: Stable diffusion-based data augmen- tation for federated learning with non-iid data. arXiv preprint arXiv:2405.07925 (2024)
arXiv 2024
-
[37]
In: CVPR (2025)
Morita, R., Frolov, S., Moser, B.B., Shirakawa, T., Watanabe, K., Dengel, A., Zhou, J.: Tkg-dm: Training-free chroma key content generation diffusion model. In: CVPR (2025)
2025
-
[38]
In: ICML (2022)
Nichol, A., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., Chen, M.: Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In: ICML (2022)
2022
-
[39]
PNAS (2022)
Nightingale, S.J., Farid, H.: Ai-synthesized faces are indistinguishable from real faces and more trustworthy. PNAS (2022)
2022
-
[40]
In: ICLR (2024) FedOT 17
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. In: ICLR (2024) FedOT 17
2024
-
[41]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[42]
arXiv preprint arXiv:2204.06125 (2022)
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022)
Pith/arXiv arXiv 2022
-
[43]
In: CVPR (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
2022
-
[44]
In: MICCAI (2015)
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: MICCAI (2015)
2015
-
[45]
In: CVPR (2023)
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. In: CVPR (2023)
2023
-
[46]
arXiv preprint arXiv:2111.02114 (2021)
Schuhmann, C., Vencu, R., Beaumont, R., Kaczmarczyk, R., Mullis, C., Katta, A., Coombes,T.,Jitsev,J.,Komatsuzaki,A.:Laion-400m:Opendatasetofclip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114 (2021)
Pith/arXiv arXiv 2021
-
[47]
IEEE TDSC (2024)
Shao, S., Yang, W., Gu, H., Qin, Z., Fan, L., Yang, Q.: Fedtracker: Furnishing ownership verification and traceability for federated learning model. IEEE TDSC (2024)
2024
-
[48]
In: NeurIPS (2023)
Somepalli, G., Singla, V., Goldblum, M., Geiping, J., Goldstein, T.: Understanding and mitigating copying in diffusion models. In: NeurIPS (2023)
2023
-
[49]
In: ICLR (2021)
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: ICLR (2021)
2021
-
[50]
In: WWW (2024)
Stanley Jothiraj, F.V., Mashhadi, A.: Phoenix: A federated generative diffusion model. In: WWW (2024)
2024
-
[51]
In: International Symposium on Reliable Distributed Systems (2021)
Tekgul, B.G., Xia, Y., Marchal, S., Asokan, N.: Waffle: Watermarking in federated learning. In: International Symposium on Reliable Distributed Systems (2021)
2021
-
[52]
In: AAAI (2025)
Tian, Z., Quan, R., Ma, F., Zhan, K., Yang, Y.: Brainguard: Privacy-preserving multisubject image reconstructions from brain activities. In: AAAI (2025)
2025
-
[53]
IEEE TIP (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE TIP (2004)
2004
-
[54]
In: CVPR (2025)
Wang, Z., Guo, J., Zhu, J., Li, Y., Huang, H., Chen, M., Tu, Z.: Sleepermark: Towards robust watermark against fine-tuning text-to-image diffusion models. In: CVPR (2025)
2025
-
[55]
In: NeurIPS (2023)
Wen, Y., Kirchenbauer, J., Geiping, J., Goldstein, T.: Tree-rings watermarks: In- visible fingerprints for diffusion images. In: NeurIPS (2023)
2023
-
[56]
In: CVPR (2026)
Xia, C., Ma, F., Quan, R., Xu, Y., Zhan, K., Yang, Y.: Echoes of ownership: Adversarial-guided dual injection for copyright protection in mllms. In: CVPR (2026)
2026
-
[57]
IEEE TII (2022)
Xiao, X., Tang, Z., Li, C., Xiao, B., Li, K.: Sca: Sybil-based collusion attacks of iiot data poisoning in federated learning. IEEE TII (2022)
2022
-
[58]
In: ACM MM (2024)
Xu, Y., Zhu, L., Yang, Y.: Gg-editor: Locally editing 3d avatars with multimodal large language model guidance. In: ACM MM (2024)
2024
-
[59]
ACM TIST (2019)
Yang, Q., Liu, Y., Chen, T., Tong, Y.: Federated machine learning: Concept and applications. ACM TIST (2019)
2019
-
[60]
ACM TIST (2023)
Yang, W., Shao, S., Yang, Y., Liu, X., Liu, X., Xia, Z., Schaefer, G., Fang, H.: Watermarking in secure federated learning: A verification framework based on client-side backdooring. ACM TIST (2023)
2023
-
[61]
Frontiers of Infor- mation Technology & Electronic Engineering (2021) 18 W
Yang, Y., Zhuang, Y., Pan, Y.: Multiple knowledge representation for big data artificial intelligence: framework, applications, and case studies. Frontiers of Infor- mation Technology & Electronic Engineering (2021) 18 W. Cheng et al
2021
-
[62]
In: CVPR (2024)
Yang, Z., Zeng, K., Chen, K., Fang, H., Zhang, W., Yu, N.: Gaussian shading: Provable performance-lossless image watermarking for diffusion models. In: CVPR (2024)
2024
-
[63]
TACL (2014)
Young, P., Lai, A., Hodosh, M., Hockenmaier, J.: From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. TACL (2014)
2014
-
[64]
In: CVPR (2021)
Yu, N., Skripniuk, V., Abdelnabi, S., Fritz, M.: Artificial fingerprinting for gener- ative models: Rooting deepfake attribution in training data. In: CVPR (2021)
2021
-
[65]
In: ICCV (2023)
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: ICCV (2023)
2023
-
[66]
In: ICLR (2026)
Zhou, D., Li, M., Yang, Z., Lu, Y., Xu, Y., Wang, Z., Huang, Z., Yang, Y.: Bid- eDPO: Conditional image generation with simultaneous text and condition align- ment. In: ICLR (2026)
2026
-
[67]
In: ECCV (2018) FedOT 19 Appendix Table of Contents A Preliminaries
Zhu, J., Kaplan, R., Johnson, J., Fei-Fei, L.: Hidden: Hiding data with deep net- works. In: ECCV (2018) FedOT 19 Appendix Table of Contents A Preliminaries........................................................ 19 A.1 Federated LDMs and Threat Model ............................... 19 A.2 Local Training under FedOT ...................................... ...
2018
-
[68]
double negative recovery
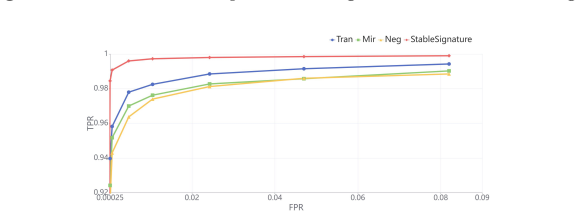
(21) The latter term is dominated by noise, which disrupts the local neighborhood structure of the latent space, making it difficult for the decoderDto learn a stable inverse mapping. Consequently, the decoder fails to accurately reconstruct the images, leading to a noticeable degradation in overall reconstruction quality. Translation and Mirror Transform...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.