CLI-Universe: Towards Verifiable Task Synthesis Engine for Terminal Agents
Pith reviewed 2026-06-26 08:40 UTC · model grok-4.3
The pith
CLI-Universe builds terminal-agent tasks through taxonomy sampling, real-world grounding, and strict executable verification to produce data that raises a 32B model to 33.4% on Terminal-Bench 2.0.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
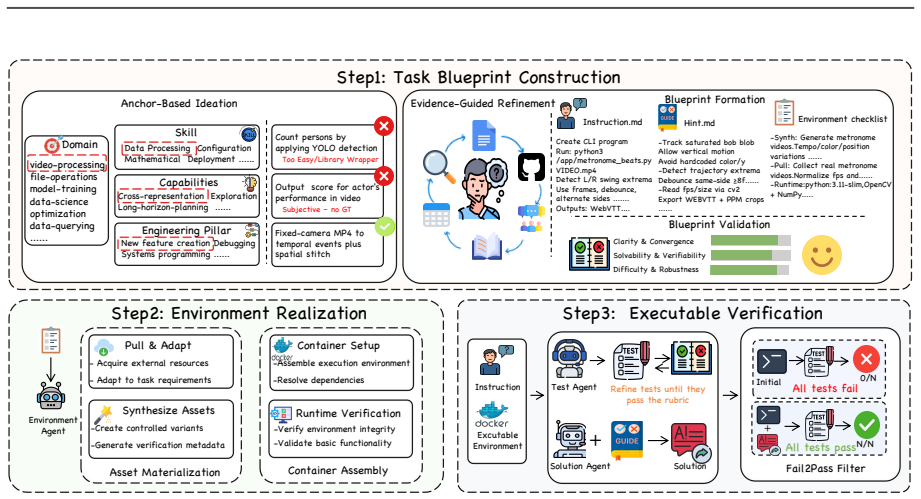
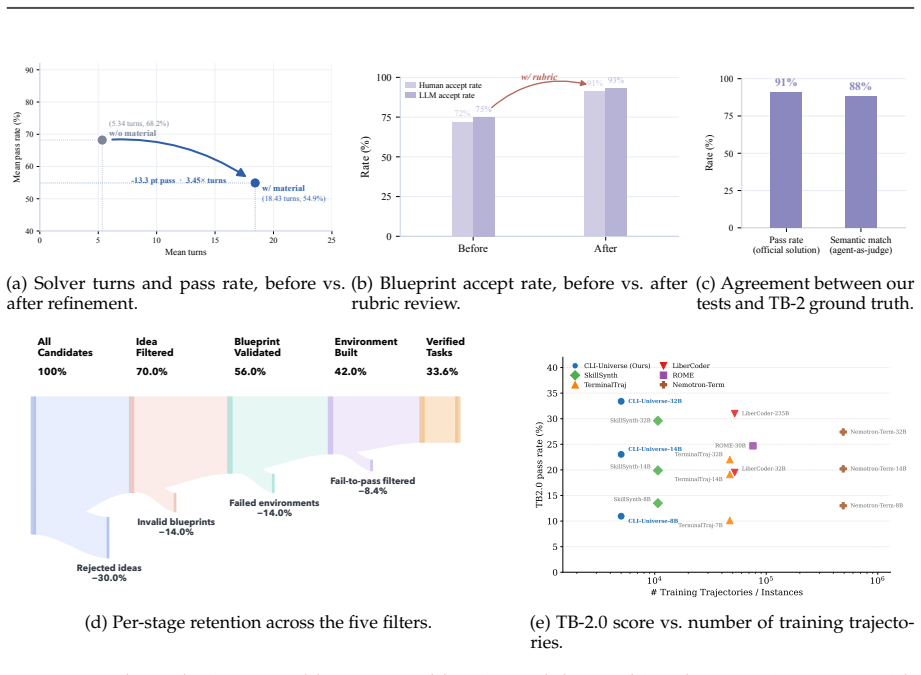
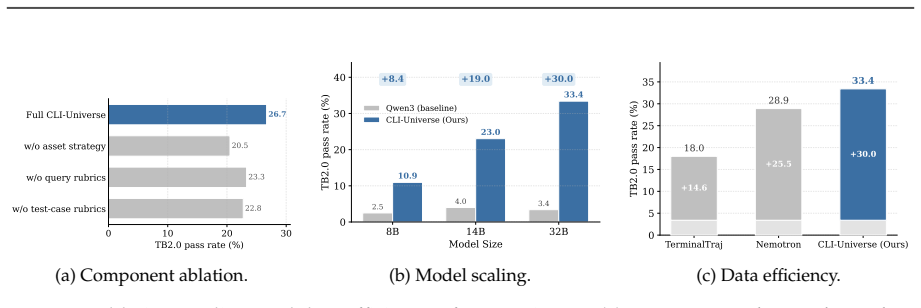
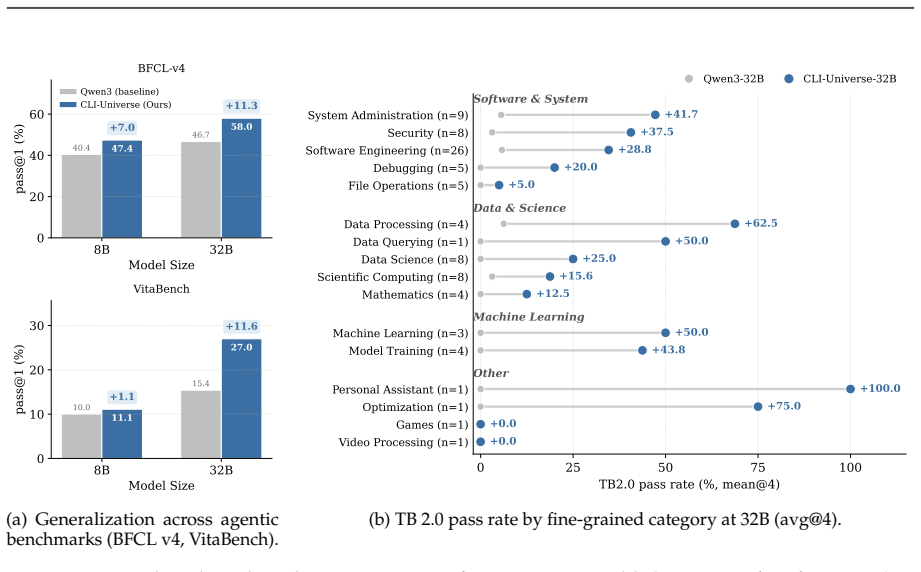
CLI-Universe constructs tasks by first sampling combinations across domain, skill type, capability, and engineering pillar, then grounding each via evidence-guided research over real technical sources; validated blueprints are turned into Dockerized environments and passed through a multi-stage verification pipeline of rubric-gated test construction, hint-conditional filtering, and strict fail-to-pass checking, after which only about one-third of candidates remain. Fine-tuning Qwen3-32B on the distilled CLI-Universe-6K set reaches 33.4% on Terminal-Bench 2.0, setting a new state-of-the-art for open-source models at or below 32B parameters while outperforming several larger models.
What carries the argument
The multi-stage executable verification pipeline (rubric-gated test construction, hint-conditional filtering, and strict fail-to-pass checking) that retains only tasks that are genuine, verifiable, and non-trivially challenging.
If this is right
- High-fidelity, execution-verified tasks can replace larger volumes of lower-quality synthetic data for terminal-agent training.
- Models at or below 32B parameters can reach or exceed the performance of models an order of magnitude larger when trained on the filtered data.
- Roughly two-thirds of candidate tasks must be discarded to achieve the reported quality threshold.
- The same synthesis engine can be scaled by increasing the number of retained trajectories while preserving the verification criteria.
Where Pith is reading between the lines
- The taxonomy-plus-verification pattern could be applied to other agent domains such as web navigation or code repositories to test whether similar data-efficiency gains appear.
- If the strict fail-to-pass check is the dominant contributor, relaxing it while keeping the other stages should measurably reduce downstream benchmark scores.
- Open release of the verification pipeline itself would allow independent groups to generate comparable datasets without access to the original authors' infrastructure.
Load-bearing premise
The verification pipeline produces tasks whose learning signals are genuinely stronger than those from prior synthesis methods.
What would settle it
A control dataset of equal size and surface diversity, synthesized without the multi-stage verification pipeline, produces equal or higher Terminal-Bench 2.0 scores when used to fine-tune the same 32B model.
Figures
read the original abstract
While recent LLM-based terminal agents have demonstrated promising capabilities, the scarcity of high-quality, executable training data remains a critical bottleneck. Existing synthesis pipelines typically scale by retrofitting surface-level artifacts into tasks, frequently yielding ambiguous instructions, shallow execution paths, and brittle tests that provide weak learning signals. To overcome this, we introduce CLI-Universe, a principled synthesis engine that constructs terminal-agent tasks. CLI-Universe generates candidate tasks by sampling combinations across a multi-dimensional capability taxonomy (domain, skill type, capability, and engineering pillar), then grounds each candidate through evidence-guided deep research over real-world technical materials. To ensure rigorous supervision, validated blueprints are instantiated into Dockerized environments and subjected to a multi-stage executable verification pipeline featuring rubric-gated test construction, hint-conditional filtering, and strict fail-to-pass checking. Across the full pipeline, from candidate generation to verification, approximately two-thirds of candidates are discarded, retaining only those that are genuine, verifiable, and non-trivially challenging. To validate our framework, we instantiate a highly distilled dataset of 6,000 trajectories called CLI-Universe-6K. Remarkably, fine-tuning Qwen3-32B on CLI-Universe-6K achieves 33.4% on Terminal-Bench 2.0. This sets a new state-of-the-art for models trained on open-source data at or below 32B parameters, and outperforms several models an order of magnitude larger, demonstrating the profound data efficiency of structured, high-fidelity synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLI-Universe, a synthesis engine for terminal-agent tasks. It samples candidates from a multi-dimensional capability taxonomy (domain, skill type, capability, engineering pillar), grounds them via evidence-guided research on real-world materials, and applies a multi-stage executable verification pipeline (rubric-gated test construction, hint-conditional filtering, strict fail-to-pass checking). Approximately two-thirds of candidates are discarded to retain genuine, verifiable, non-trivial tasks, yielding the CLI-Universe-6K dataset of 6,000 trajectories. Fine-tuning Qwen3-32B on this dataset is reported to achieve 33.4% on Terminal-Bench 2.0, claimed as a new SOTA for open-source models at or below 32B parameters that outperforms several larger models.
Significance. If the multi-stage verification pipeline can be shown to produce measurably stronger supervision signals than prior synthesis approaches, the work would offer a significant contribution to scalable, high-fidelity task generation for LLM agents, directly addressing the data bottleneck with verifiable and challenging examples. The reported data efficiency of a 6K-trajectory dataset enabling competitive performance would be noteworthy if the pipeline's role is isolated.
major comments (2)
- [Abstract] Abstract: The headline result that fine-tuning Qwen3-32B on CLI-Universe-6K yields 33.4% on Terminal-Bench 2.0 is presented as evidence for the synthesis engine, yet no ablation or control experiment compares performance against a 6K-trajectory dataset constructed without the full verification pipeline (e.g., omitting rubric-gated tests or strict fail-to-pass checking). This is load-bearing for the central claim that the two-thirds discard rate and multi-stage filtering produce superior learning signals.
- [Experiments] Experiments (implied by performance reporting): No direct comparison is described to prior terminal-task synthesis baselines evaluated on the same Terminal-Bench 2.0 benchmark, nor are error bars, statistical tests, or a breakdown of failure modes among discarded candidates provided. Without these, attribution of the SOTA result specifically to the proposed pipeline rather than dataset size or curation effort remains unsupported.
minor comments (2)
- The multi-dimensional capability taxonomy is described at a high level but would benefit from an explicit table or diagram enumerating the dimensions and example combinations to improve reproducibility.
- [Abstract] The abstract references 'Terminal-Bench 2.0' without a citation or brief description of the benchmark tasks and evaluation protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical isolation of the verification pipeline's contributions. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result that fine-tuning Qwen3-32B on CLI-Universe-6K yields 33.4% on Terminal-Bench 2.0 is presented as evidence for the synthesis engine, yet no ablation or control experiment compares performance against a 6K-trajectory dataset constructed without the full verification pipeline (e.g., omitting rubric-gated tests or strict fail-to-pass checking). This is load-bearing for the central claim that the two-thirds discard rate and multi-stage filtering produce superior learning signals.
Authors: We agree that a direct ablation isolating the full verification pipeline against an unfiltered 6K-trajectory control would more conclusively attribute performance gains to the multi-stage filtering. The manuscript relies on the observed two-thirds discard rate and the resulting 33.4% benchmark score as indirect indicators of task quality. We cannot retroactively generate and evaluate an equivalent-scale unverified dataset without the pipeline, as the verification steps are required to produce executable tasks. In revision we will add an explicit limitations paragraph in the experiments section acknowledging this gap and discussing the practical difficulties of such a control. revision: partial
-
Referee: [Experiments] Experiments (implied by performance reporting): No direct comparison is described to prior terminal-task synthesis baselines evaluated on the same Terminal-Bench 2.0 benchmark, nor are error bars, statistical tests, or a breakdown of failure modes among discarded candidates provided. Without these, attribution of the SOTA result specifically to the proposed pipeline rather than dataset size or curation effort remains unsupported.
Authors: Terminal-Bench 2.0 is a recent benchmark, so most prior synthesis methods lack published numbers on it; we will add a comparison table against any available open-source results on this exact benchmark. We will also report error bars from repeated fine-tuning runs (subject to compute availability) and include statistical significance where applicable. For discarded candidates we will expand the appendix with a categorized breakdown of failure modes drawn from our verification logs. These additions will be incorporated in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical benchmark result on external test set
full rationale
The paper reports an empirical outcome: fine-tuning Qwen3-32B on the constructed CLI-Universe-6K dataset yields 33.4% on Terminal-Bench 2.0. This is a direct measurement against an external benchmark rather than a derived quantity obtained by fitting parameters to a subset of the same data or by self-referential definition. No equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text that would reduce the reported score to an internal construction. The multi-stage verification pipeline is described as a filtering process whose value is asserted via the external performance number; the absence of an ablation does not constitute circularity under the defined criteria.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A multi-dimensional capability taxonomy (domain, skill type, capability, engineering pillar) is sufficient to generate representative terminal-agent tasks.
- domain assumption Evidence-guided deep research over real-world technical materials produces accurate task blueprints.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2407.16741. Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu...
-
[2]
URLhttps://arxiv.org/abs/2601.11868. Siwei Wu, Yizhi Li, Yuyang Song, Wei Zhang, Yang Wang, Riza Batista-Navarro, Xian Yang, Mingjie Tang, Bryan Dai, Jian Yang, and Chenghua Lin. Large-scale terminal agentic trajectory generation from dockerized environments,
-
[3]
Renjie Pi, Grace Lam, Mohammad Shoeybi, Pooya Jannaty, Bryan Catanzaro, and Wei Ping
URLhttps://arxiv.org/abs/2602.01244. Renjie Pi, Grace Lam, Mohammad Shoeybi, Pooya Jannaty, Bryan Catanzaro, and Wei Ping. On data engineering for scaling llm terminal capabilities,
-
[4]
URLhttps://arxiv.org/abs/2602.21193. Zhiyuan Fan, Tinghao Yu, Yuanjun Cai, Jiangtao Guan, Yun Yang, Dingxin Hu, Jiang Zhou, Xing Wu, Zhuo Han, Feng Zhang, and Lilin Wang. Toward scalable terminal task synthesis via skill graphs,
-
[5]
Kanishk Gandhi, Shivam Garg, Noah D
URLhttps://arxiv.org/abs/2604.25727. Kanishk Gandhi, Shivam Garg, Noah D. Goodman, and Dimitris Papailiopoulos. Endless terminals: Scaling rl environments for terminal agents,
-
[6]
Yusong Lin, Haiyang Wang, Shuzhe Wu, Lue Fan, Feiyang Pan, Sanyuan Zhao, and Dandan Tu
URLhttps://arxiv.org/abs/2601.16443. Yusong Lin, Haiyang Wang, Shuzhe Wu, Lue Fan, Feiyang Pan, Sanyuan Zhao, and Dandan Tu. Cli-gym: Scalable cli task generation via agentic environment inversion,
-
[7]
URL https://arxiv.org/abs/ 2602.10999. 10 Kaijie Zhu, Yuzhou Nie, Yijiang Li, Yiming Huang, Jialian Wu, Jiang Liu, Ximeng Sun, Zhenfei Yin, Lun Wang, Zicheng Liu, Emad Barsoum, William Yang Wang, and Wenbo Guo. Termigen: High-fidelity environment and robust trajectory synthesis for terminal agents,
-
[8]
URL https://arxiv.org/abs/ 2602.07274. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang...
-
[9]
URL https://arxiv.org/abs/2505.09388. Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large language models. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maha...
-
[10]
URLhttps://arxiv.org/abs/2509.26490. John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering,
-
[11]
URL https://arxiv.org/abs/2405.15793. Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?,
-
[12]
Kimi Team, Yifan Bai, Yiping Bao, Y
URL https://arxiv.org/abs/2310.06770. Kimi Team, Yifan Bai, Yiping Bao, Y. Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Ch...
-
[13]
URLhttps://arxiv.org/abs/2507.20534. Anthropic. The claude model card. https://docs.anthropic.com/en/docs/about-claude/models, 2025b. 11 Google DeepMind. Gemini model thinking updates, march
-
[14]
https: //blog.google/innovation-and-ai/models-and-research/google-deepmind/ gemini-model-thinking-updates-march-2025/,
2025
-
[15]
URLhttps://arxiv.org/abs/2602.15763. MiniMax, Aili Chen, Aonian Li, Baichuan Zhou, Bangwei Gong, Binyang Jiang, Boji Dan, Changqing Yu, Chao Wang, Cheng Ma, Cheng Zhong, Cheng Zhu, Chengjun Xiao, Chengyi Yang, Chengyu Du, Chenyang Zhang, Chi Zhang, Chuangyi Huang, Chunhao Zhang, Chunhui Du, Chunyu Zhao, Congchao Guo, Da Chen, Deming Ding, Dianjun Sun, Don...
-
[16]
URL https://arxiv.org/abs/2605.26494. Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, Zeyao Ma, Kashun Shum, Xuwu Wang, Jinxi Wei, Jiaxi Yang, Jiajun Zhang, Lei Zhang, Zongmeng Zhang, Wenting Zhao, and Fan Zhou. Qwen3-coder-next technical report,
-
[17]
URLhttps://arxiv.org/abs/2603.00729. 12 DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence. https:// huggingface.co/deepseek-ai/DeepSeek-V4-Pro,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.