Hybrid Compression: Integrating Pruning and Quantization for Optimized Neural Networks
Pith reviewed 2026-06-26 08:54 UTC · model grok-4.3
The pith
A two-phase method applies pruning and quantization then routes multiple compressed models with mixture of experts to reduce CNN size and compute with little accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that pruning and quantization in the first phase, followed by mixture of experts routing among the resulting moderately sized compressed models in the second phase, produces CNNs that show substantial reductions in FLOPs and parameters with only a negligible accuracy drop on several benchmark datasets.
What carries the argument
The two-phase process in which pruning and quantization first generate multiple compressed expert models and mixture of experts routing then selects among them at inference time.
If this is right
- Parameters and floating-point operations fall by large factors compared with the original model.
- Accuracy on the tested benchmark datasets stays within a negligible margin of the uncompressed baseline.
- Inference remains efficient because each expert stays moderately sized.
- The method applies across multiple CNN architectures evaluated in the experiments.
Where Pith is reading between the lines
- The same routing idea could be tested on transformer architectures if the experts are created by the same pruning and quantization steps.
- Hardware-specific tuning of the number of experts might further improve the speed-accuracy trade-off on particular edge chips.
- Combining this hybrid scheme with distillation could produce even smaller models while keeping the two-phase structure intact.
Load-bearing premise
The mixture of experts routing among the pruned and quantized models will recover enough accuracy to offset any added inference cost.
What would settle it
An experiment on a standard CNN benchmark that shows the mixture of experts phase either fails to restore accuracy or raises inference latency enough to erase the savings from the first phase would falsify the central claim.
Figures
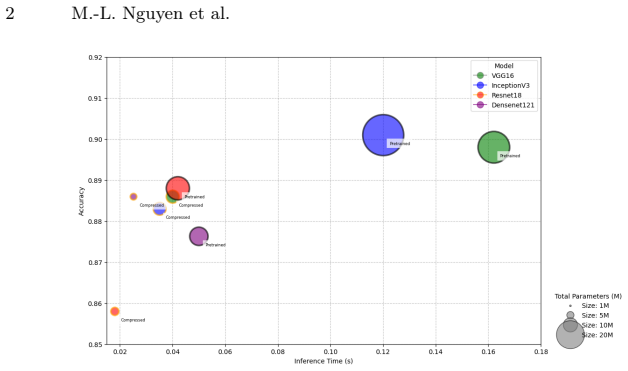
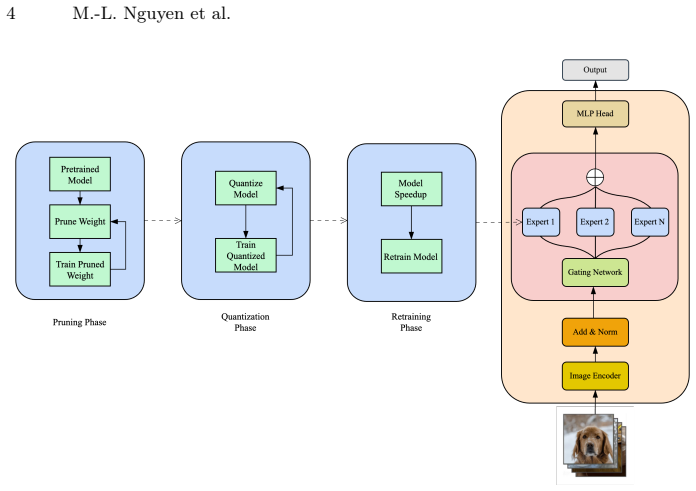
read the original abstract
Deep neural networks have witnessed remarkable advancements in recent years and have become integral to various applications. However, alongside these developments, training and deployment of neural network models on embedding and edge devices face significant challenges due to limited memory and computational resources. These problems can be addressed with deep neural network compression, which involves a trade-off between model size and performance. In this paper, we propose a novel method for model compression through two phases. First, we utilize model compression techniques, such as pruning and quantization, to significantly reduce the model size. Then, we use Mixture of Experts to route the previously compressed models to enhance performance while maintaining a balance in inference efficiency. MoEs consist of multiple expert models (i.e., compressed models) that are moderately sized and deliver stable performance. Experimental results on several benchmark datasets show that our method successfully compresses CNN models which achieves substantial reductions in FLOPs and parameters with a negligible accuracy drop.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a two-phase hybrid compression method for CNNs. Phase 1 applies pruning and quantization to reduce model size. Phase 2 routes multiple resulting compressed models via Mixture of Experts (MoE) to recover performance while claiming to preserve inference efficiency. The central claim, stated in the abstract, is that the approach delivers substantial FLOPs and parameter reductions with only a negligible accuracy drop on benchmark datasets.
Significance. If the efficiency and accuracy claims were demonstrated with explicit overhead accounting and quantitative results, the work could provide a practical route to edge deployment of compressed CNNs by combining standard compression with MoE-based recovery. The current manuscript, however, supplies no such evidence, limiting its potential contribution.
major comments (2)
- [Abstract] Abstract: the efficiency claim that MoE routing 'maintain[s] a balance in inference efficiency' after pruning+quantization is load-bearing for the central claim but is unsupported. No accounting is given for router computation, gating cost, or possible multi-expert activation; standard MoE overhead could offset the reported FLOPs savings, yet the abstract asserts the balance without evidence or latency/FLOPs numbers that include routing.
- [Abstract] Abstract: the claim of 'substantial reductions in FLOPs and parameters with a negligible accuracy drop' is presented without any numerical results, baselines, pruning ratios, bit-widths, number of experts, routing details, datasets, or error bars. This absence makes the central empirical claim impossible to evaluate.
minor comments (1)
- [Abstract] Abstract contains a grammatical error: 'compresses CNN models which achieves' should be rephrased (e.g., 'compresses CNN models and achieves').
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the two major comments point-by-point below and will make the requested changes to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the efficiency claim that MoE routing 'maintain[s] a balance in inference efficiency' after pruning+quantization is load-bearing for the central claim but is unsupported. No accounting is given for router computation, gating cost, or possible multi-expert activation; standard MoE overhead could offset the reported FLOPs savings, yet the abstract asserts the balance without evidence or latency/FLOPs numbers that include routing.
Authors: We agree that the abstract would benefit from explicit support for the efficiency claim. In the revised manuscript we will add a sentence to the abstract stating that total inference FLOPs (including the lightweight router and top-1 expert activation) remain substantially lower than the uncompressed baseline; we will also insert a short paragraph in Section 3.2 that details the router architecture, its parameter/FLOP count, and the measured end-to-end latency on the target hardware. These numbers are already computed in our experimental pipeline and will be reported. revision: yes
-
Referee: [Abstract] Abstract: the claim of 'substantial reductions in FLOPs and parameters with a negligible accuracy drop' is presented without any numerical results, baselines, pruning ratios, bit-widths, number of experts, routing details, datasets, or error bars. This absence makes the central empirical claim impossible to evaluate.
Authors: We accept the referee’s observation. The current abstract is too terse. In the revision we will replace the final sentence with a concise quantitative summary that includes the achieved FLOPs reduction, parameter reduction, accuracy change (with standard deviation), pruning ratio, quantization bit-width, number of experts, routing strategy, and the primary datasets. Corresponding tables and error-bar plots already exist in the experimental section and will be referenced from the abstract. revision: yes
Circularity Check
No circularity: empirical claims with no derivation chain or fitted inputs
full rationale
The manuscript describes a two-phase empirical procedure (pruning+quantization followed by MoE routing of compressed models) and reports benchmark results showing FLOPs/parameter reduction with negligible accuracy drop. No equations, parameter-fitting steps, uniqueness theorems, or self-citations appear in the supplied text. The central claim is therefore an experimental outcome rather than a quantity derived from its own inputs by construction. This is the normal non-finding for a methods paper lacking a mathematical derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural network intelligence.https://github.com/microsoft/nni(2020)
2020
-
[2]
arXiv preprint arXiv:1901.08584 (2019)
Arora, S., Du, S.S., Hu, W., Li, Z., Wang, R.: Fine-grained analysis of optimization and generalization for overparameterized two-layer neural networks. arXiv preprint arXiv:1901.08584 (2019)
Pith/arXiv arXiv 1901
-
[3]
IEEE35(1), 126–136 (2018)
Cheng, Y., Wang, D., Zhou, P., Zhang, T.: Model compression and acceleration for deep neural networks: The principles, progress, and challenges. IEEE35(1), 126–136 (2018)
2018
-
[4]
arXiv preprint arXiv:1602.02830 (2016)
Courbariaux,M.,Hubara,I.,Soudry,D.,El-Yaniv,R.,Bengio,Y.:Binarizedneural networks: Training deep neural networks with weights and activations constrained to+ 1 or-1. arXiv preprint arXiv:1602.02830 (2016)
Pith/arXiv arXiv 2016
-
[5]
Doe, J., Smith, J.: Bloodmnist dataset (2022), version 1.0
2022
-
[6]
In: Proceedings of NIPS (2017)
Dong, X., Chen, S., Pan, S.: Learning to prune deep neural networks via layer-wise optimal brain surgeon. In: Proceedings of NIPS (2017)
2017
-
[7]
In: ICLR (2014) Hybrid Compression for Optimized Neural Networks 11
Eigen, D., Ranzato, M., Sutskever, I.: Learning factored representations in a deep mixture of experts. In: ICLR (2014) Hybrid Compression for Optimized Neural Networks 11
2014
-
[8]
In: ICLR (2019)
Frankle, J., Carbin, M.: The lottery ticket hypothesis: Finding sparse, trainable neural networks. In: ICLR (2019)
2019
-
[9]
In: Proceed- ings of NIPS (2017)
Girdhar, R., Ramanan, D.: Attentional pooling for action recognition. In: Proceed- ings of NIPS (2017)
2017
-
[10]
In: ICLR
Han, S., Mao, H., Dally, W.J.: Deep compression: Compressing deep neural net- works with pruning, trained quantization, and huffman coding. In: ICLR. pp. 199– 203 (2016)
2016
-
[11]
In: NIPS (2015)
Han, S., Pool, J., Tran, J., Dally, W.: Learning both weights and connections for efficient neural network. In: NIPS (2015)
2015
-
[12]
In: IEEE (1993)
Hassibi, B., Stork, D.G., Wolff, G.J.: Optimal brain surgeon and general network pruning. In: IEEE (1993)
1993
-
[13]
IEEE Access6(2018)
Hatcher, W.G., Yu, W.: A survey of deep learning: Platforms, applications and emerging research trends. IEEE Access6(2018)
2018
-
[14]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018)
2018
-
[15]
arXiv preprint arXiv:1712.05877 (2017)
Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., Adam, H., Kalenichenko,D.:Quantizationandtrainingofneuralnetworksforefficientinteger- arithmetic-only inference. arXiv preprint arXiv:1712.05877 (2017)
Pith/arXiv arXiv 2017
-
[16]
Neural Computation3(1) (1991)
Jacobs, R.A., Jordan, M.I., Nowlan, S.J., Hinton, G.E.: Adaptive mixtures of local experts. Neural Computation3(1) (1991)
1991
-
[17]
arXiv preprint arXiv:2401.04088 (2024)
Jiang, A.Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D.S., Casas, D.d.l., Hanna, E.B., Bressand, F., et al.: Mixtral of experts. arXiv preprint arXiv:2401.04088 (2024)
Pith/arXiv arXiv 2024
-
[18]
Krizhevsky, A.: Learning multiple layers of features from tiny images (2009)
2009
-
[19]
IEEE86(11), 2278–2324 (1998)
Lecun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. IEEE86(11), 2278–2324 (1998)
1998
-
[20]
Li, H., Kadav, A., Durdanovic, I., Samet, H., Graf, H.P.: Pruning filters for efficient convnets. ArXivabs/1608.08710(2016)
Pith/arXiv arXiv 2016
-
[21]
Neurocomputing461, 370–403 (2021)
Liang, T., Glossner, J., Wang, L., Shi, S., Zhang, X.: Pruning and quantization for deep neural network acceleration: A survey. Neurocomputing461, 370–403 (2021)
2021
-
[22]
IEEE Access (2024)
Liao, H., Murah, M.Z., Hasan, M.K., Aman, A.H.M., Fang, J., Hu, X., Khan, A.U.R.: A survey of deep learning technologies for intrusion detection in internet of things. IEEE Access (2024)
2024
-
[23]
Microsoft: Nni automl toolkit.https://nni.readthedocs.io/en/latest/(2021)
2021
-
[24]
arXiv preprint arXiv:2004.10568 (2020)
Nagel,M.,Amjad,R.A.,vanBaalen,M.,Louizos,C.,Blankevoort,T.:Upordown? adaptive rounding for post-training quantization. arXiv preprint arXiv:2004.10568 (2020)
arXiv 2004
-
[25]
arXiv preprint arXiv:1701.06538 (2017)
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., Dean, J.: Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538 (2017)
Pith/arXiv arXiv 2017
-
[26]
Tanaka, H., Kunin, D., Yamins, D.L.K., Ganguli, S.: Pruning neural networks without any data by iteratively conserving synaptic flow
-
[27]
In: PMLR (2020)
Wang, X., Yu, F., Dunlap, L., Ma, Y.A., Wang, R., Mirhoseini, A., Darrell, T., Gonzalez, J.E.: Deep mixture of experts via shallow embedding. In: PMLR (2020)
2020
-
[28]
arXiv preprint arXiv:1606.06160 (2016)
Zhou, S., Wu, Y., Ni, Z., Zhou, X., Wen, H., Zou, Y.: Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv preprint arXiv:1606.06160 (2016)
Pith/arXiv arXiv 2016
-
[29]
Zhu, M.H., Gupta, S.: To prune, or not to prune: exploring the efficacy of pruning for model compression (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.