Have You Ever Seen Them? Entity-level Membership Inference through Interrogating Large Language Models
Pith reviewed 2026-06-26 08:16 UTC · model grok-4.3
The pith
Large language models reveal whether they encountered information about specific entities during training when interrogated with targeted prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Entity-level membership inference is feasible in the label-only black-box setting because LLMs exhibit human-memory-like behavior, allowing inference of exposure to entity-related information by analyzing semantic features from responses generated under five interrogation strategies constructed from limited clues.
What carries the argument
Five interrogation strategies that construct prompts from limited entity clues, elicit entity-related responses from the LLM, and infer membership from semantic features among the generated texts.
If this is right
- Entity membership can be inferred without access to training samples or model internals.
- Models can be tested for exposure to real-world entities using only query-response interactions.
- The approach outperforms adapted sample-level baselines by 6.0%--17.5% in balanced accuracy.
- Feasibility depends on necessary and sufficient conditions related to clue, input, and model constraints.
- Semantic distinctions in responses reliably signal training data presence for person entities.
Where Pith is reading between the lines
- Similar interrogation could apply to non-person entities like organizations or events if semantic features generalize.
- This might inform regulations on training data transparency for LLMs.
- Testing the strategies on open-source models where membership is known could validate the approach further.
Load-bearing premise
Semantic features extracted from LLM responses to entity-related prompts will differ between entities whose information appeared in training data and those that did not.
What would settle it
Finding a set of person entities known to be absent from training data that produce the same semantic response patterns as known training entities under the interrogation strategies.
Figures


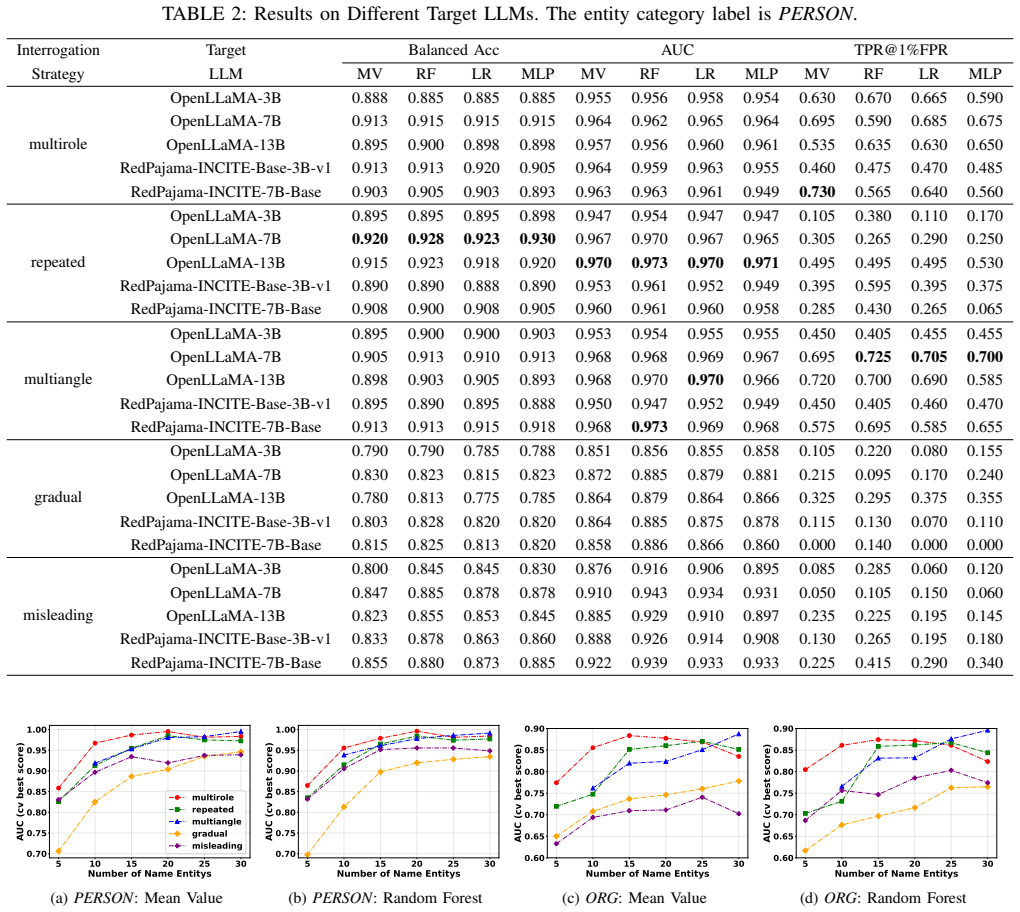
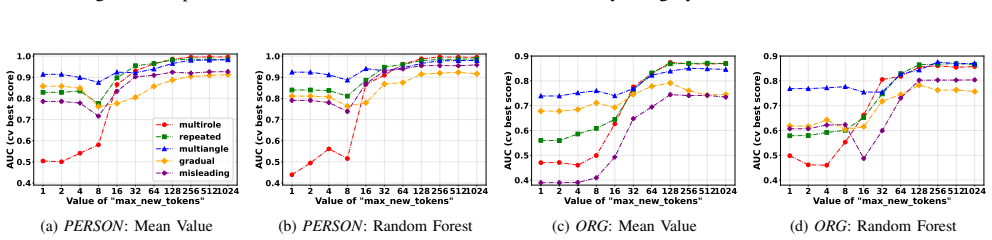

read the original abstract
Large Language Models (LLMs) raise growing concerns about privacy leakage and copyright compliance. Membership inference is a key tool for assessing such risks, but existing studies mainly focus on whether specific samples or sample-based data units are used for training. We argue that LLMs exhibit a human-memory-like behavior: an LLM may not memorize a specific sample verbatim, yet it can accumulate and reveal knowledge about a real-world entity from scattered mentions. This analogy motivates us to examine whether an LLM can be interrogated like a human interviewee to reveal its exposure to entity-related information. Motivated by this question, we propose entity-level membership inference, which determines whether information related to a target entity is used in LLM training. We study this task in the practical label-only black-box setting, where only generated texts are observable. We formalize the task under clue, input, and model constraints, establish the necessary and sufficient conditions for its feasibility, and instantiate five interrogation strategies based on this formalization. The strategies use limited entity clues to construct prompts, elicit entity-related responses, and infer membership from semantic features among the generated texts. We construct entity-level datasets and adapt state-of-the-art sample-level label-only methods to the entity-level setting as baselines. Experiments on person entities show that our methods achieve AUC up to 0.97 and bring gains of 6.0%--17.5% in Balanced Accuracy over the best adapted baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces entity-level membership inference as a task to determine whether information about a real-world entity appeared in an LLM's training data. It formalizes the task under clue, input, and model constraints in the label-only black-box setting, derives necessary and sufficient feasibility conditions, and instantiates five interrogation strategies that construct prompts from limited entity clues, elicit responses, and infer membership via semantic features in the generated text. On constructed datasets of person entities, the proposed methods report AUC values up to 0.97 and balanced-accuracy gains of 6.0%–17.5% over the best adapted sample-level baselines.
Significance. If the empirical distinction holds after controlling for external entity properties, the work would establish a practically relevant extension of membership inference that aligns with how LLMs accumulate scattered knowledge about entities rather than memorizing individual samples. The formalization of constraints and feasibility conditions, together with the concrete performance numbers on person entities, would constitute a useful contribution to privacy auditing of LLMs.
major comments (1)
- [Experiments] Dataset construction (Experiments section, abstract): the member vs. non-member split for person entities is not described as balanced on external properties such as web frequency, number of public mentions, or inherent prominence. Because the five interrogation strategies rely on semantic features extracted from generated responses, any systematic difference in response richness driven by entity popularity rather than training exposure would confound the reported AUC and accuracy gains, violating the necessary-and-sufficient feasibility conditions stated in the formalization.
minor comments (1)
- The abstract states that state-of-the-art sample-level methods are adapted as baselines, but the precise adaptation steps (e.g., how entity clues are mapped to sample-level prompts) are not summarized; a short paragraph or table clarifying the adaptation would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for this constructive comment on dataset construction. We address it directly below.
read point-by-point responses
-
Referee: [Experiments] Dataset construction (Experiments section, abstract): the member vs. non-member split for person entities is not described as balanced on external properties such as web frequency, number of public mentions, or inherent prominence. Because the five interrogation strategies rely on semantic features extracted from generated responses, any systematic difference in response richness driven by entity popularity rather than training exposure would confound the reported AUC and accuracy gains, violating the necessary-and-sufficient feasibility conditions stated in the formalization.
Authors: We agree that the member/non-member split must be balanced on external properties such as web frequency and prominence; otherwise semantic features could be confounded and the feasibility conditions would not hold. The manuscript does not describe such balancing. We will revise the Experiments section to detail the exact construction procedure (including sources and selection criteria), report balance statistics on the cited properties, and, if the current split is imbalanced, reconstruct the datasets to enforce balance before re-running the reported experiments. revision: yes
Circularity Check
No circularity: empirical results on held-out entity datasets
full rationale
The paper's core contribution consists of formalizing an entity-level membership inference task under explicit constraints, instantiating five interrogation strategies, constructing datasets, and reporting empirical AUC and balanced accuracy metrics against adapted baselines. No equations, derivations, or self-citations reduce the reported performance numbers to fitted parameters defined from the same data; the feasibility conditions and strategies are stated independently of the experimental outcomes. The analysis remains self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A review on large language models: Architectures, applications, taxonomies, open issues and challenges,
M. A. K. Raiaan, M. S. H. Mukta, K. Fatema, N. M. Fahad, S. Sakib, M. M. J. Mim, J. Ahmad, M. E. Ali, and S. Azam, “A review on large language models: Architectures, applications, taxonomies, open issues and challenges,”IEEE access, vol. 12, pp. 26 839–26 874, 2024
2024
-
[2]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi`ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskeveret al., “Language models are unsupervised multitask learners,”OpenAI blog, vol. 1, no. 8, p. 9, 2019
2019
-
[4]
Ex- tracting training data from large language models,
N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-V oss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingssonet al., “Ex- tracting training data from large language models,” in30th USENIX security symposium (USENIX Security 21), 2021, pp. 2633–2650
2021
-
[5]
Github copilot litigation,
Matthew Butterick and Joseph Saveri Law Firm, “Github copilot litigation,” GitHub Copilot Litigation Website, 2022. [Online]. Available: https://githubcopilotlitigation.com/
2022
-
[6]
More than 15,000 authors sign authors guild letter calling on ai industry leaders to protect writers,
A. Guild, “More than 15,000 authors sign authors guild letter calling on ai industry leaders to protect writers,” Authors Guild (Blog), 2023. [Online]. Available: https://authorsguild.org/news/thousands-sign-aut hors-guild-letter-calling-on-ai-industry-leaders-to-protect-writers/
2023
-
[7]
Sarah silverman is suing openai and meta for copyright infringement,
The Verge, “Sarah silverman is suing openai and meta for copyright infringement,” The Verge (Blog), 2023. [Online]. Available: https://www.theverge.com/2023/7/9/23788741/sarah-silverman-ope nai-meta-chatgpt-llama-copyright-infringement-chatbots-artificial-i ntelligence-ai
2023
-
[8]
The times sues openai and microsoft over a.i. use of copyrighted work,
The New York Times, “The times sues openai and microsoft over a.i. use of copyrighted work,”The New York Times, 2023. [Online]. Available: https://www.nytimes.com/2023/12/27/business/media/ne w-york-times-open-ai-microsoft-lawsuit.html
2023
-
[9]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Membership inference attacks against machine learning models,
R. Shokri, M. Stronati, C. Song, and V . Shmatikov, “Membership inference attacks against machine learning models,” in2017 IEEE symposium on security and privacy (SP). IEEE, 2017, pp. 3–18
2017
-
[12]
Membership inference attacks from first principles,
N. Carlini, S. Chien, M. Nasr, S. Song, A. Terzis, and F. Tramer, “Membership inference attacks from first principles,” in2022 IEEE symposium on security and privacy (SP). IEEE, 2022, pp. 1897– 1914
2022
-
[13]
Privacy risk in machine learning: Analyzing the connection to overfitting,
S. Yeom, I. Giacomelli, M. Fredrikson, and S. Jha, “Privacy risk in machine learning: Analyzing the connection to overfitting,” in2018 IEEE 31st computer security foundations symposium (CSF). IEEE, 2018, pp. 268–282
2018
-
[14]
Label-only membership inference attacks,
C. A. Choquette-Choo, F. Tramer, N. Carlini, and N. Papernot, “Label-only membership inference attacks,” inInternational confer- ence on machine learning. PMLR, 2021, pp. 1964–1974
2021
-
[15]
Membership inference attacks against language models via neighbourhood comparison,
J. Mattern, F. Mireshghallah, Z. Jin, B. Sch ¨olkopf, M. Sachan, and T. Berg-Kirkpatrick, “Membership inference attacks against language models via neighbourhood comparison,” inFindings of the Associ- ation for Computational Linguistics: ACL 2023, 2023, pp. 11 330– 11 343
2023
-
[16]
Auditing data provenance in text- generation models,
C. Song and V . Shmatikov, “Auditing data provenance in text- generation models,” inProceedings of the 25th ACM SIGKDD Inter- national Conference on Knowledge Discovery & Data Mining, 2019, pp. 196–206
2019
-
[17]
User inference attacks on large language models,
N. Kandpal, K. Pillutla, A. Oprea, P. Kairouz, C. A. Choquette-Choo, and Z. Xu, “User inference attacks on large language models,” in Proceedings of the 2024 conference on empirical methods in natural language processing, 2024, pp. 18 238–18 265
2024
-
[18]
Dataset inference for self-supervised models,
A. Dziedzic, H. Duan, M. A. Kaleem, N. Dhawan, J. Guan, Y . Cattan, F. Boenisch, and N. Papernot, “Dataset inference for self-supervised models,”Advances in Neural Information Processing Systems, vol. 35, pp. 12 058–12 070, 2022
2022
-
[19]
Llm dataset inference: Did you train on my dataset?
P. Maini, H. Jia, N. Papernot, and A. Dziedzic, “Llm dataset inference: Did you train on my dataset?”Advances in Neural Information Processing Systems, vol. 37, pp. 124 069–124 092, 2024
2024
-
[20]
Property existence inference against generative models,
L. Wang, J. Wang, J. Wan, L. Long, Z. Yang, and Z. Qin, “Property existence inference against generative models,” in33rd USENIX Security Symposium (USENIX Security 24), 2024, pp. 2423–2440
2024
-
[21]
Do membership inference attacks work on large language models?
M. Duan, A. Suri, N. Mireshghallah, S. Min, W. Shi, L. Zettlemoyer, Y . Tsvetkov, Y . Choi, D. Evans, and H. Hajishirzi, “Do membership inference attacks work on large language models?”arXiv preprint arXiv:2402.07841, 2024
-
[22]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gem- ini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Pythia: A suite for analyzing large language models across train- ing and scaling,
S. Biderman, H. Schoelkopf, Q. G. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raffet al., “Pythia: A suite for analyzing large language models across train- ing and scaling,” inInternational conference on machine learning. PMLR, 2023, pp. 2397–2430
2023
-
[24]
Transformers: State- of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowiczet al., “Transformers: State- of-the-art natural language processing,” inProceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, 2020, pp. 38–45
2020
-
[25]
A contrastive framework for neural text generation,
Y . Su, T. Lan, Y . Wang, D. Yogatama, L. Kong, and N. Collier, “A contrastive framework for neural text generation,”Advances in Neural Information Processing Systems, vol. 35, pp. 21 548–21 561, 2022
2022
-
[26]
The curious case of neural text degeneration,
A. Holtzman, J. Buys, L. Du, M. Forbes, and Y . Choi, “The curious case of neural text degeneration,” inInternational Conference on Learning Representations, 2020
2020
-
[27]
Assessing privacy risks in language models: A case study on sum- marization tasks,
R. Tang, G. Lueck, R. Quispe, H. Inan, J. Kulkarni, and X. Hu, “Assessing privacy risks in language models: A case study on sum- marization tasks,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 15 406–15 418
2023
-
[28]
Towards{Label-Only}membership inference attack against pre-trained large language models,
Y . He, B. Li, L. Liu, Z. Ba, W. Dong, Y . Li, Z. Qin, K. Ren, and C. Chen, “Towards{Label-Only}membership inference attack against pre-trained large language models,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 1609–1628
2025
-
[29]
In-context probing for membership inference in fine-tuned language models,
Z. Lu, H. Chi, N. Baracaldo, S. R. Kadhe, Y . Jeon, and L. Yu, “In-context probing for membership inference in fine-tuned language models,” inProceedings of the 33rd Network and Distributed System Security Symposium (NDSS 2026), San Diego, CA, USA, February, 2026
2026
-
[30]
Shepherd and A
E. Shepherd and A. Griffiths,Investigative interviewing: The conver- sation management approach. Oxford University Press, 2021
2021
-
[31]
Bull,Investigative interviewing
R. Bull,Investigative interviewing. Springer Science & Business Media, 2014
2014
-
[32]
The scharff technique: On how to effectively elicit intelligence from human sources,
P. A. Granhag, S. M. Kleinman, and S. Oleszkiewicz, “The scharff technique: On how to effectively elicit intelligence from human sources,”International Journal of Intelligence and CounterIntelli- gence, vol. 29, no. 1, pp. 132–150, 2016
2016
-
[33]
The cognitive interview: A meta-analytic review and study space analysis of the past 25 years
A. Memon, C. A. Meissner, and J. Fraser, “The cognitive interview: A meta-analytic review and study space analysis of the past 25 years.” Psychology, public policy, and law, vol. 16, no. 4, p. 340, 2010
2010
-
[34]
Strategic use of evidence during investigative interviews: The state of the science,
M. Hartwig, P. A. Granhag, and T. Luke, “Strategic use of evidence during investigative interviews: The state of the science,”Credibility assessment, pp. 1–36, 2014
2014
-
[35]
M. E. Lamb, Y . Orbach, I. Hershkowitz, P. W. Esplin, and D. Horowitz, “A structured forensic interview protocol improves the quality and informativeness of investigative interviews with children: A review of research using the nichd investigative interview protocol,” Child abuse & neglect, vol. 31, no. 11-12, pp. 1201–1231, 2007
2007
-
[36]
Inbau, J
F. Inbau, J. Buckley, and B. Jayne,Criminal interrogation and confessions. Jones & Bartlett Publishers, 2013
2013
-
[37]
Membership inference attacks against{Vision-Language}models,
Y . Hu, Z. Li, Z. Liu, Y . Zhang, Z. Qin, K. Ren, and C. Chen, “Membership inference attacks against{Vision-Language}models,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 1589–1608
2025
-
[38]
Investigative interviewing witness guide,
New Zealand Police, “Investigative interviewing witness guide,” Proactively released by New Zealand Police. [Online]. Available: ht tps://fyi.org.nz/request/21325/response/80666/attach/html/3/Harris%2 0JA%20IR%2001%2022%2037549%20signed%20response.pdf.html
2001
-
[39]
Investigative interviewing witness guide flashcards,
Brainscape, “Investigative interviewing witness guide flashcards,” Brainscape flashcards. [Online]. Available: https://www.brainscape.c om/flashcards/investigative-interviewing-witness-guide-4681473/pac ks/6928724
-
[40]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qinet al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,”ACM Transactions on Information Systems, vol. 43, no. 2, pp. 1–55, 2025
2025
-
[41]
Neural architectures for named entity recognition,
G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, and C. Dyer, “Neural architectures for named entity recognition,” in Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies, 2016, pp. 260–270
2016
-
[42]
A survey on deep learning for named entity recognition,
J. Li, A. Sun, J. Han, and C. Li, “A survey on deep learning for named entity recognition,”IEEE transactions on knowledge and data engineering, vol. 34, no. 1, pp. 50–70, 2020
2020
-
[43]
Did the neurons read your book? document-level membership inference for large language models,
M. Meeus, S. Jain, M. Rei, and Y .-A. de Montjoye, “Did the neurons read your book? document-level membership inference for large language models,” in33rd USENIX Security Symposium (USENIX Security 24), 2024, pp. 2369–2385
2024
-
[44]
Redpajama: an open dataset for training large language models,
M. Weber, D. Y . Fu, Q. Anthony, Y . Oren, S. Adams, A. Alexandrov, X. Lyu, H. Nguyen, X. Yao, V . Adamset al., “Redpajama: an open dataset for training large language models,”Advances in neural information processing systems, vol. 37, pp. 116 462–116 492, 2024
2024
-
[45]
Wikipedia: The free encyclopedia,
Wikimedia Foundation, “Wikipedia: The free encyclopedia,” Wikime- dia Foundation, 2001. [Online]. Available: https://www.wikipedia.org/
2001
-
[46]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020
2020
-
[47]
Github: Where the world builds software,
GitHub, “Github: Where the world builds software,” GitHub, Inc.,
-
[48]
Available: https://github.com/
[Online]. Available: https://github.com/
-
[49]
Project gutenberg: Free ebooks,
Project Gutenberg Literary Archive Foundation, “Project gutenberg: Free ebooks,” Project Gutenberg, 1971. [Online]. Available: https://www.gutenberg.org/
1971
-
[50]
These 183,000 books are fueling the biggest fight in publishing and tech,
A. Reisner, “These 183,000 books are fueling the biggest fight in publishing and tech,”The Atlantic, vol. 25, 2023
2023
-
[51]
The battle over books3 could change ai forever,
K. Knibbs, “The battle over books3 could change ai forever,”Wired, September, 2023
2023
-
[52]
spacy: Industrial-strength natural language processing,
Explosion AI, “spacy: Industrial-strength natural language processing,” Explosion AI, 2015. [Online]. Available: https://spacy.io/
2015
-
[53]
Diving into robocall content with{SnorCall},
S. Prasad, T. Dunlap, A. Ross, and B. Reaves, “Diving into robocall content with{SnorCall},” in32nd USENIX Security Symposium (USENIX Security 23), 2023, pp. 427–444
2023
-
[54]
Principled and automated ap- proach for investigating{AR/VR}attacks,
M. Shoaib, A. Suh, and W. U. Hassan, “Principled and automated ap- proach for investigating{AR/VR}attacks,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 4325–4344
2025
-
[55]
Skillpov: Towards accessible and effective privacy notice for amazon alexa skills
J. Yan, S. Liao, M. Aldeen, L. Xing, D. Yao, L. Cheng, and V . Tech, “Skillpov: Towards accessible and effective privacy notice for amazon alexa skills.” inNDSS, 2025
2025
-
[56]
No way to sign out? unpacking{Non-Compliance}with google play’s app account deletion requirements,
J. Yan, S. Liao, J. Ma, M. Aldeen, S. Kumar, and L. Cheng, “No way to sign out? unpacking{Non-Compliance}with google play’s app account deletion requirements,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 3277–3296
2025
-
[57]
Openllama: An open reproduction of llama,
X. Geng and H. Liu, “Openllama: An open reproduction of llama,” 2023
2023
-
[58]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 confer- ence on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), 2019, pp. 3982–3992
2019
-
[59]
Membership inference attacks against in-context learning,
R. Wen, Z. Li, M. Backes, and Y . Zhang, “Membership inference attacks against in-context learning,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Secu- rity, 2024, pp. 3481–3495
2024
-
[60]
Fantasti- cally ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity,
Y . Lu, M. Bartolo, A. Moore, S. Riedel, and P. Stenetorp, “Fantasti- cally ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 8086–8098
2022
-
[61]
Principal components analysis (pca),
A. Ma ´ckiewicz and W. Ratajczak, “Principal components analysis (pca),”Computers & Geosciences, vol. 19, no. 3, pp. 303–342, 1993
1993
-
[62]
Visualizing data using t-sne
L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.” Journal of machine learning research, vol. 9, no. 11, 2008
2008
-
[63]
Mem- guard: Defending against black-box membership inference attacks via adversarial examples,
J. Jia, A. Salem, M. Backes, Y . Zhang, and N. Z. Gong, “Mem- guard: Defending against black-box membership inference attacks via adversarial examples,” inProceedings of the 2019 ACM SIGSAC conference on computer and communications security, 2019, pp. 259– 274
2019
-
[64]
Deep learning with differential privacy,
M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” inProceedings of the 2016 ACM SIGSAC conference on computer and communications security, 2016, pp. 308–318
2016
-
[65]
Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning,
M. Nasr, R. Shokri, and A. Houmansadr, “Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning,” in2019 IEEE symposium on security and privacy (SP). IEEE, 2019, pp. 739– 753
2019
-
[66]
White-box vs black-box: Bayes optimal strategies for member- ship inference,
A. Sablayrolles, M. Douze, C. Schmid, Y . Ollivier, and H. J ´egou, “White-box vs black-box: Bayes optimal strategies for member- ship inference,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 5558–5567
2019
-
[67]
Stolen memories: Leveraging model memorization for calibrated{White-Box}membership inference,
K. Leino and M. Fredrikson, “Stolen memories: Leveraging model memorization for calibrated{White-Box}membership inference,” in 29th USENIX security symposium (USENIX Security 20), 2020, pp. 1605–1622
2020
-
[68]
Was my data used for training? membership inference in open-source llms via neural activations,
X. Tan, H. Luan, M. Luo, Z. Yu, J. Dai, X. Sun, and P. Chen, “Was my data used for training? membership inference in open-source llms via neural activations,” inProceedings of the 33rd Network and Distributed System Security Symposium (NDSS 2026), San Diego, CA, USA, February, 2026
2026
-
[69]
A. Salem, Y . Zhang, M. Humbert, P. Berrang, M. Fritz, and M. Backes, “Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models,”arXiv preprint arXiv:1806.01246, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[70]
On the importance of difficulty calibration in membership inference attacks,
L. Watson, C. Guo, G. Cormode, and A. Sablayrolles, “On the importance of difficulty calibration in membership inference attacks,” arXiv preprint arXiv:2111.08440, 2021
-
[71]
Membership inference attacks by exploiting loss trajectory,
Y . Liu, Z. Zhao, M. Backes, and Y . Zhang, “Membership inference attacks by exploiting loss trajectory,” inProceedings of the 2022 ACM SIGSAC conference on computer and communications security, 2022, pp. 2085–2098
2022
-
[72]
Enhanced membership inference attacks against machine learning models,
J. Ye, A. Maddi, S. K. Murakonda, V . Bindschaedler, and R. Shokri, “Enhanced membership inference attacks against machine learning models,” inProceedings of the 2022 ACM SIGSAC conference on computer and communications security, 2022, pp. 3093–3106
2022
-
[73]
Is difficulty calibration all we need? towards more practical membership inference attacks,
Y . He, B. Li, Y . Wang, M. Yang, J. Wang, H. Hu, and X. Zhao, “Is difficulty calibration all we need? towards more practical membership inference attacks,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 1226–1240
2024
-
[74]
Detecting pretraining data from large language models,
W. Shi, A. Ajith, M. Xia, Y . Huang, D. Liu, T. Blevins, D. Chen, and L. Zettlemoyer, “Detecting pretraining data from large language models,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 51 826–51 843
2024
-
[75]
Min-k%++: Improved baseline for pre-training data detection from large language models,
J. Zhang, J. Sun, E. Yeats, Y . Ouyang, M. Kuo, J. Zhang, H. Yang, and H. Li, “Min-k%++: Improved baseline for pre-training data detection from large language models,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 64 845–64 862
2025
-
[76]
Gemini api documentation,
Google, “Gemini api documentation,” Google AI for Developers,
-
[77]
Available: https://ai.google.dev/
[Online]. Available: https://ai.google.dev/
-
[78]
Claude api documentation,
Anthropic, “Claude api documentation,” Anthropic Documentation,
-
[79]
Available: https://docs.anthropic.com/
[Online]. Available: https://docs.anthropic.com/
-
[80]
Mistral api documentation,
Mistral AI, “Mistral api documentation,” Mistral AI Documentation,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.